





概述
这篇文章是基于 Kubernetes 的 master commitid: 8e8b6a01cf6bf55dea5e2e4f554597a95c82988a 写下的源码分析文档。
Kubernetes 作为一个资源管理平台,其中一个关键的组件是调度器,而调度的核心,是要将有限的资源利用最大化。调度在 Kubernetes 里面是 Kube-scheduler 组件实现的。Kube-scheduler 的主要逻辑在于,如何为集群中的每一个新创建的 Pod 或者没有被调度的 Pod 找到合适的节点。
带着问题出发
问题 1:
调度器如何平衡准确性和效率性?
准确性的话一般在业务处理里面会用到串行调度,对每一个 Pod 对象进行串行调度,等该对象调度完成再动下一个,但众所周知,一个 Pod 需要在节点上启动,绑定 IP 和磁盘等资源,如果单纯串行调度,是很难提高效率,符合业务需求,假设是并行调度的话,如何保证每一次调度决策的准确性?例如调度决策将同一个 Node 资源同时分配给两个不同的 Pod,可能会出现在绑定阶段的另外一个 Pod 会因为资源不足而无法创建该 Pod。
问题 2:
当出现 Kubernetes 集群 Node 节点数量非常大,例如 5000 个节点,调度器为一个 Pod 对象选择 Node 节点时候,是如何从这 5000 个节点中选出最优解?如若每一个 Pod 对象都轮询 5000 个节点,调度器在进行调度的时候如何提高做出决策的时间(优化)?
问题 3:
作为调度器,Kubernetes 的调度器应该提供一些比较公共的调度算法,但每个公司都有特定的调度需求,云厂商会有希望进行资源超卖之类的调度需求,作为使用者的企业或者个人应该如何扩展调度器实现定制化调度需求?
流程概述
Kubernetes 的调度器的一个总的调度流程:
用户在集群里面创建了一个新的 Pod 对象。 Pod 对象被加入到调度器的队列里面, 调度器从“调度器队列”中获取 Pod 对象。 首先在调度器经过一轮预选,选出符合该 Pod 对象资源要求的一组 Node 节点列表。 将符合 Pod 对象的 Node 节点列表再筛选一遍,在筛选环节根据亲和性或者资源均衡性等对 Node 节点列表进行打分,返回 Node 节点以及对应的分数。 选出最高分的节点 Node,异步进行绑定Volume,如果绑定环节失败,那么将解绑 Node 节点以及资源。 如果在 4 或者 5 失败,也就是无法选出符合 Pod 对象的 Node,那么进入抢占环节,挤兑低优先级的 Pod 对象去抢占 Node 节点。
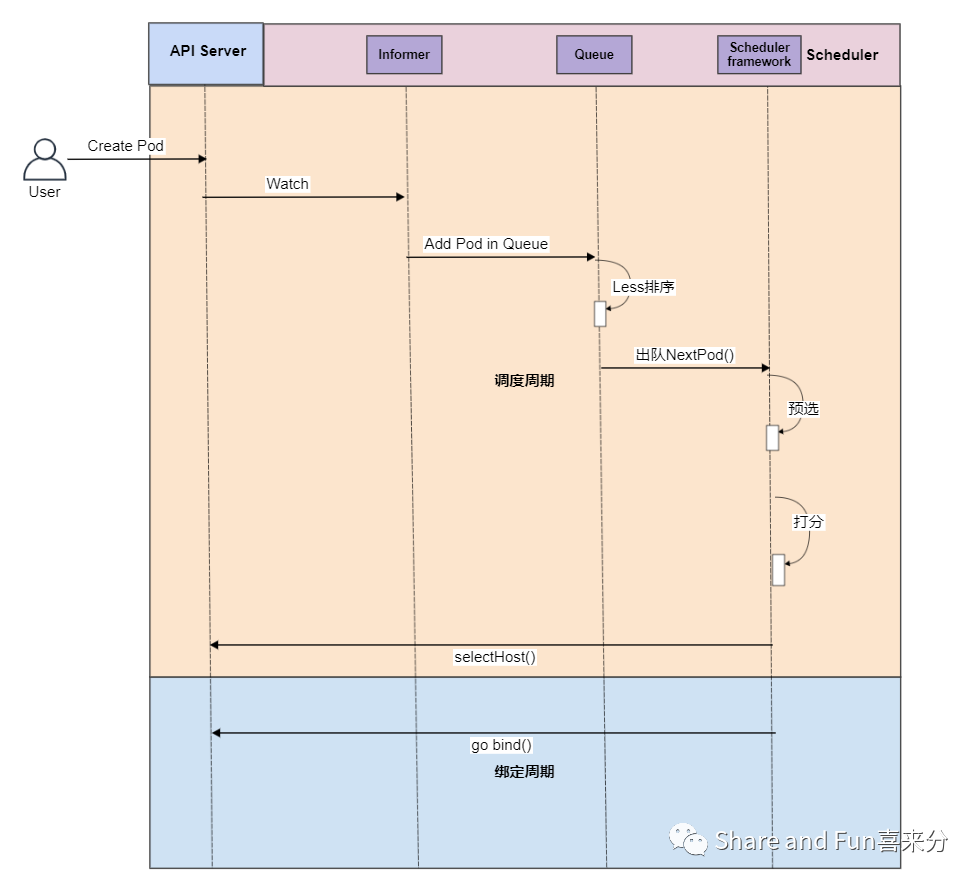
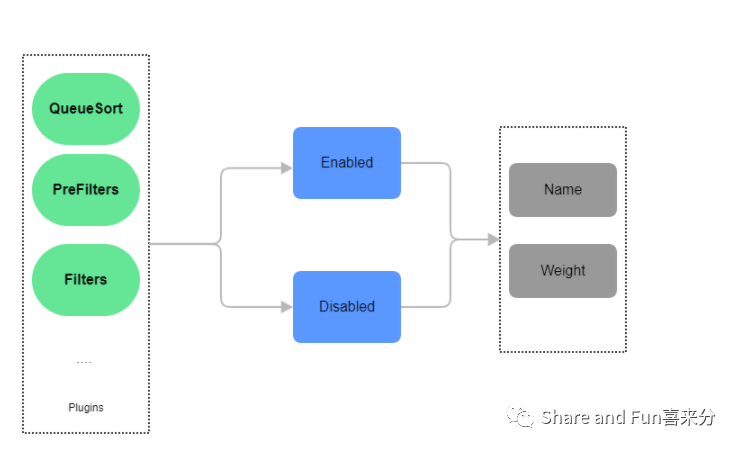
实际上,围绕着整个调度过程,在目前的 Kubernetes 版本中,Scheduler framework 在每一个调度阶段发挥着紧密的作用,Scheduler framework 把每一个阶段都做成一组插件。每一组插件都可以 Enabled 或者 Disabled。
在 Kubernetes v1.18 以及之后的版本里面,大部分的调度 plugins 都是默认 Enabled,用户也可以配置 Disable 某组插件,Plugin 都有一个名字和对应的权重。在每一个调度阶段提供了基于插件式的接口,这些插件实现了绝大部分的调度功能。
调度框架通过插件的机制去接受插件的结果,根据插件结果去继续下一个步骤或者停止调度,这种机制允许我们处理错误并且也可以与插件通信。
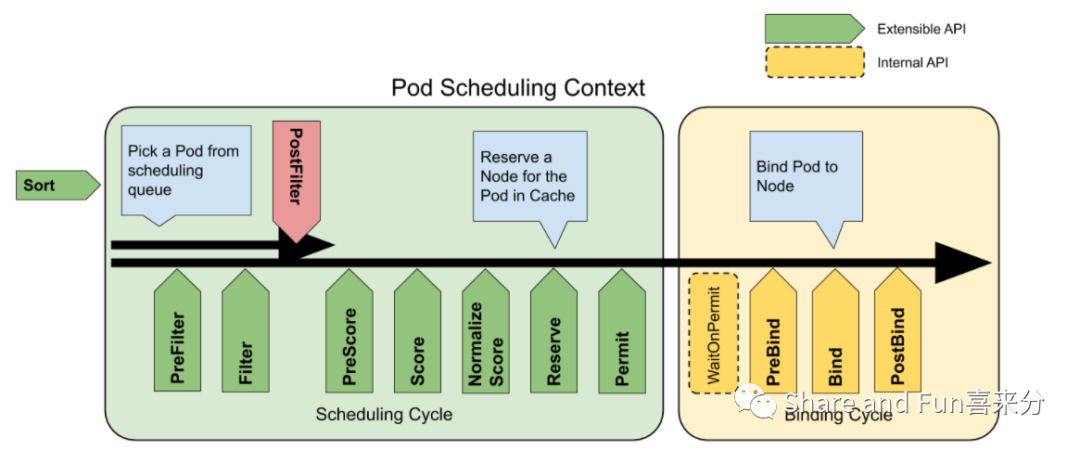
从下图可以看出,Scheduler framework 实现了两个阶段:调度周期和绑定周期。绿色所在箭头,Scheduler framework 都提供了扩展接口供用户扩展调度需求。接下来,我们会跟着一个 Pod 被调度的流程概述,详细分析在每一个阶段里面调度器的操作。
Step1: 新增 Pod
当我们往集群里面新增一个 Pod 对象的时候,Informer
的EventHandler
会触发将该 Pod 对象加入到调度器的 activeQ 调度队列中进行入队操作。
func addAllEventHandlers(...) {
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToSchedulingQueue,
UpdateFunc: sched.updatePodInSchedulingQueue,
DeleteFunc: sched.deletePodFromSchedulingQueue,
},
},
)
...
}
func (sched *Scheduler) addPodToSchedulingQueue(obj interface{}) {
pod := obj.(*v1.Pod)
if err := sched.SchedulingQueue.Add(pod); err != nil {...}
}
func (p *PriorityQueue) Add(pod *v1.Pod) error {
pInfo := p.newQueuedPodInfo(pod)
// 当新增一个Pod对象的时候,Eventhandler会将该Pod对象执行Add的操作,然后调用了activeQ.Add去把该Pod对象加到activeQ里面
if err := p.activeQ.Add(pInfo); err != nil {
return err
}
...
}
Step2: 入队
调度器是定时的从调度队列里面获取队头的一个 Pod 对象podInfo := sched.NextPod()
,也就是,每次只获取一个 Pod 对象,这个过程是阻塞的,当队列中不存在 Pod 对象的时候,sched.NextPod()
会处于等待状态。
在没有看源码之前,我个人想象中存放 Pod 的调度队列是使用 Channel 实现的,然后是直接就可以使用先进先出的功能,看了代码之后发现如果使用 Channel 的话是无法对已经进入队列里面的 Pod 对象进行排序,Kubernetes 设计的调度队列是让高优先级的排在队列的对头,低优先级的被排在队尾,设计成需要在队列里面排队是为了符合业务需求高优先级的 Pod 应用需要优先被得到调度处理。
在队列的最前面是最高优先级的 pod,队列里面是有使用对 Pod 进行排序的,那就是 Less 方法(见下方的代码), Less 是根据 Pod 的优先级来进行比较,也就是说,每次进入调度周期的时候,每取出一个 Pod,实际上都是取优先级最高的 Pod 先进行调度 (当优先级相等时,它使用 PodQueueInfo.timestamp)
这里使用了 Scheduler framework 的队列插件中提供的"Less(Pod1, Pod2)" 方法来实现。
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := pod.GetPodPriority(pInfo1.Pod)
p2 := pod.GetPodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}
而这个时候,调度器只是在操作一个 Pod 对象,让我们接下来继续看看,调度器是如何提高调度效率呢?
Step3: 预选
在预选里面,调用了numFeasibleNodesToFind
去寻找 Node 节点数量的函数,如果记得我们问题 2 里面,如果我们有 5000 个节点,那么调度器是查询所有节点吗?
答案是有一个叫percentageOfNodesToScore
的变量,接收从 0 到 100 之间的整数值,而且其默认值是通过集群的规模计算得来的。该变量是用来设置调度集群中节点的阈值。调优的时候我们应该根据我们的节点数量对这个值进行一个合理的设置。如果我们不指定,那么 Kubernetes 会使用公式计算一个比例:在 100 左右的节点数量取 50%,在 5000 左右的节点数量取 10%。
也就是说Kubernetes 调度是存在全局最优解和局部最优解两种解法,这取决于集群 Node 节点大小与percentageOfNodesToScore
值的设置。
func (g *genericScheduler) findNodesThatPassFilters(...) {
allNodes, err := g.nodeInfoSnapshot.NodeInfos().List()
numNodesToFind := g.numFeasibleNodesToFind(int32(len(allNodes)))
feasibleNodes := make([]*v1.Node, numNodesToFind)
checkNode := func(i int) {
// 我们从上一个调度周期中停止的地方开始检查节点
nodeInfo := allNodes[(g.nextStartNodeIndex+i)%len(allNodes)]
fits, status, err := PodPassesFiltersOnNode(ctx, prof.PreemptHandle(), state, pod, nodeInfo
...
}
// 并行对所有的Node进行检查
parallelize.Until(ctx, len(allNodes), checkNode)
processedNodes := int(feasibleNodesLen) + len(statuses)
g.nextStartNodeIndex = (g.nextStartNodeIndex + processedNodes) % len(allNodes)
// 一旦配置的可行节点数量达到,就停止搜索更多的节点
feasibleNodes = feasibleNodes[:feasibleNodesLen]
if err := errCh.ReceiveError(); err != nil {
statusCode = framework.Error
return nil, err
}
return feasibleNodes, nil
}
代码里面的g.nextStartNodeIndex
值得大家注意,打个比喻来说第一个 Pod 如果是使用了 1000 个节点(Node[0] 到 Node[999] )进行过滤,那么下一个 Pod 是从 Node[1000]开始取,这是从公平性出发去确保所有节点都有相同的机会跨 pods 进行检查。如果在一定比例的节点数量中,仍然没有找到符合条件的节点,那么进入抢占环节。
现在让我们看看在预选阶段,Scheduler framework 使用的预选插件检查汇总:
| 预选算法 | 描述 |
|---|---|
| nodeunschedulable | 检查 Node 是否可调度 |
| noderesources | 检查 Node 资源是否符合 Pod 的需求 |
| nodename | 检查 Pod.Spec.NodeName 是否符合目前的 Node 节点 |
| nodeports | 检查 Node 是否跟 Pod 需要暴露的端口有冲突 |
| nodeaffinity | 检查节点亲和性 |
| tainttoleration | 检查污点容忍性,例如节点 Node 带上某些污点标签,Pod 是否可以容忍 |
| nodevolumelimits | 检查 Node 的卷是否达到限制 |
| volumebinding | 检查卷的绑定情况 |
| volumezone | 检查卷所在的 Zone |
| interpodaffinity | Pod 的亲和性检查,例如需要调度的 Pod 跟节点上的 Pod 是否有 prefer 亲和性 |
需要被调度的 Pod 在经过预选环节,会返回一个经过过滤筛选符合需求的 Node 列表,
当列表长度<=0 意味着没有 Node 节点符合 Pod 的需求,不再进入打分环节,直接认为调度失败,进入 Step6
当列表长度=1 意味着只有一个 Node 节点符合 Pod 的需求,不再进入打分环节,把该 Node 进行 Step5 的绑定环节
当列表长度大于 2 会进入下方的打分环节。
Step4: 打分
在打分环节,仍然是使用了 Scheduler framework 的一组插件:评分插件。
评分插件用于对通过预选的阶段的所有 Node 进行排名,调度器将为每个节点都调用所有评分插件。对于每一个评分插件,Scheduler framework 都给与他们对应的权重 Weight,如下方代码所示。
当评分完成之后,调度器使用了数学公式:乘积,也就是节点在每一个评分插件得出的分数*权重,再把所有分数合并才是节点的最后分数。
// 代码位置`pkg/scheduler/algorithmprovider/registry.go`
Score: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
// 寻找资源使用率平衡的节点
{Name: noderesources.BalancedAllocationName, Weight: 1},
// 基于节点上是否下拉了运行Pod对象的镜像计算分数
{Name: imagelocality.Name, Weight: 1},
// 基于亲和性和反亲和性计算分数
{Name: interpodaffinity.Name, Weight: 1},
// 基于节点亲和性计算分数
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
// 基于污点和容忍度是否匹配分数
{Name: tainttoleration.Name, Weight: 1},
...
},
},
在打分环节完成之后会返回 NodeScoreList 的列表,调度器会selectHost
方法从返回结果中为 Pod 对象绑定一个 Node 节点。
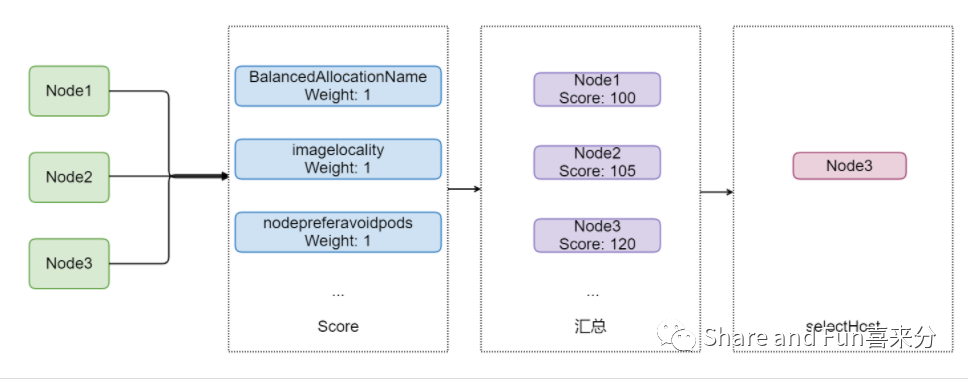
至此调度周期完成,调度器进入下一个周期:绑定周期。
Step5: 绑定
现在调度器进入了绑定周期,使用了 go rountine 异步去执行 bind 去把 Pod 对象与节点 Node 进行绑定,不需要等待 bind 完成就可以进行下一个 Pod 对象的调度。这也就是理解了,Kubernetes Scheduler 是选择串行调度去保证准确性的同时,然后以异步的方式去做绑定去提高效率。
如果绑定失败,调度器会自动执行回滚操作。
在绑定周期,实际上是为 Pod 对象进行绑定 Volume 的操作。而绑定周期里面,是可以细分成三个阶段的:
预绑定
预绑定插件用于执行 Pod 绑定前所需的任何工作。例如,一个预绑定插件可能需要提供卷并且在允许 Pod 运行在该节点之前将其挂载到目标节点上。
如果任何 PreBind 插件返回错误,则 Pod 将被拒绝并且返回到调度队列中被重新等待下一次调度。
绑定
绑定插件用于将 Pod 绑定到节点上。直到所有的 PreBind 插件都完成,绑定插件才会被调用。每个绑定插件按照配置顺序被调用。绑定插件可以选择是否处理指定的 Pod。如果绑定插件选择处理 Pod,剩余的绑定插件将被跳过。
func (b DefaultBinder) Bind(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) *framework.Status {
binding := &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: p.Namespace, Name: p.Name, UID: p.UID},
Target: v1.ObjectReference{Kind: "Node", Name: nodeName},
}
err := b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})
return nil
}
从代码里面我们可以看出,Bind
绑定实际上是通过调 ClientSet 去调 API Server 把 Pod 对象的 Node 信息加到 Pod 的 ObjectMeta, 如果在此刻发生 API Server 故障等,是会绑定失败的,一旦绑定失败,就会触发运行un-reserve
插件,去把之前预留给该 Pod 对象的资源释放。
绑定后
绑定插件用于将 Pod 绑定到节点上。直到所有的 PreBind 插件都完成,绑定插件才会被调用。每个绑定插件按照配置顺序被调用。绑定插件可以选择是否处理指定的 Pod。如果绑定插件选择处理 Pod,剩余的绑定插件将被跳过。
至此绑定周期完成。
Step6: 抢占
在上方我们提起到,当 Pod 对象在预选环节失败的时候,会进入抢占环节,企图抢占其他 Pod 对象的资源。这是从业务需求出发,我们希望我们优先级高的应用需要被调度成功。而抢占,仍然是作为 Scheduler framework 的一组插件:PostFilter
PostFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: defaultpreemption.Name},
},
},
抢占算法流程:
判断当前的 Pod 对象是否优先级比节点里面其他 Pod 对象优先级高,从而判断是否有资格抢占
从预选失败的节点尝试找到可以调度的候选节点列表
从候选节点列表中尝试找到能够抢占成功的节点列表
从经过 3 完成的节点里面中选择一个阶段用于最终被抢占,也就是被抢占节点
获取被抢占节点的所有 NominatedPods 列表
驱逐需要因为抢占而被删除的 Pod 的对象
附:扩展调度器
Kubernetes 调度器有三个扩展点:
Multiple scheduler: 需要用户自己实现一个调度器,开发成本比较大,允许与默认的调度器一起运行在 Kubernetes 集群中 Extender: 只有 Filter、Proritize、Preempt 和 Bind 这几个扩展点,是基于 HTTP/HTTPS 通过网络调用,会有一定的网络延时,并且由于 Extender 是独立运行的,不能使用 Scheduler Cache Scheduler framework
从上方整个流程可以看出,Scheduler framework 贯穿了调度器的每一个调度阶段, 他设计很多都值得我们参考,基于插件式的调度框架分层的将过滤和打分和抢占都做成不同层级别的插件,被编译进调度器中,我们可以扩展某个插件,并且不影响与上下游插件的通信。
