




什么是schema
TuGraph作为强schema的图数据库,在插入数据之前要求数据一定归属于某个schema,即创建某个类型的点边模型之后,才可以插入数据,那么什么是schema呢?schema是一种约束和规定,它有两个方面的作用:
它规定了某个类型的点边拥有哪些属性,这些属性是什么类型的,属性是如何存储在磁盘中的,是否可以为空,它有多少定长的属性,多少变长的属性。
如何从一个点或边数据中解析出某个属性值等等功能。
总而言之,schema指导了如何根据磁盘中的一段二进制数据解析出某个点或边的属性内容和属性值,用于后续的计算。
TuGraph Schema
schema的定义
schema的定义具体表现为一种约束,它指定了一个点或者边有哪些属性,属性大小,以及如何排布。它的定义主要由如下类提供:
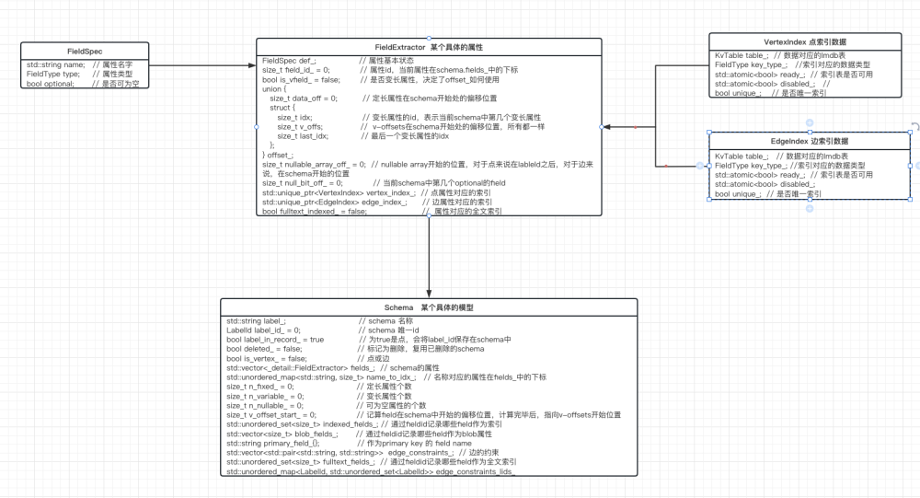
schema的应用
schema的应用具体表现为一种格式,它指定了一个点或边的数据(即点或边的属性值)如何存储在磁盘中。下文中所说的点或边的属性值的二进制即指磁盘中的点或边数据。
点的存储格式

点的存储格式一共包含如下几部分内容:
Label Id :schema的唯一标示,uint16_t类型,因此一个子图(即一个LightningGraph)中的点或边的个数不能超过65535个,超过将会无法区分。
Null-Array :值可以为空(即optional)类型的属性数组,每个optional的field占一位,以字节对齐,第一个optional的属性标记位于Null-Array第一字节的最后一位,第七个optional的属性标记位于Null-Array第一字节的最前面一位,用于指示某个点或边optional属性对应的数据是否为空。
Fixed-fields :定长属性列,属性值紧挨着保存,定长属性的长度确定,因此只要知道开始位置就可以正确取出内容,起始位置保存在FieldExtractor类的成员data_off中。
Variable-Offsets :变长属性偏移列表,记录变长属性开始的位置,变长属性通过当前属性开始位置和下一个属性开始位置的差值计算长度,通过开始位置和长度可以正确取出内容。
Variable-Data :变长属性内容列表,记录变长属性的值。
边的存储格式

边的存储格式一共包含如下几部分,LabelId作为key的一部分,因此不需要保存在数据中:
Null-Array :值可以为空(即optional)类型的属性数组,每个optional的field占一位,以字节对齐,第一个optional的属性标记位于Null-Array第一字节的最后一位,第七个optional的属性标记位于Null-Array第一字节的最前面一位,用于指示某个点或边optional属性对应的数据是否为空。
Fixed-fields :定长属性列,每种属性紧挨着保存,定长属性的长度确定,因此只要知道开始位置就可以正确取出内容,起始位置保存在FieldExtractor类的成员data_off中。
Variable-Offsets :变长属性偏移列表,记录变长属性开始的位置,变长属性通过当前属性开始位置和下一个属性开始位置的差值计算长度,通过开始位置和长度可以正确取出内容。
Variable-Data :变长属性内容列表,记录变长属性的值。
schema使用场景
通过schema可以将一段磁盘中的二进制数据解析成某种类型的点或边,可以获取点边属性,也可以将一些值拼接成某个类型的点或边属性的二进制值,存入磁盘中。
获取点索引
通过transaction类获取某个label_name对应点的schema,就可以通过schema获取到具体的索引信息:
Schema* schema =Transaction::curr_schema_->v_schema_manager->GetSchema(label_name);for (auto& fid : schema->indexed_fields_) {_detail::FieldExtractor* fe = schema->fields_[fid];VertexIndex* index = fe->vertex_index_;}
获取边索引
通过transaction类获取某个label_name对应边的schema,就可以通过schema获取到具体的索引信息:
Schema* schema =Transaction::curr_schema_->e_schema_manager->GetSchema(label_name);for (auto& fid : schema->indexed_fields_) {_detail::FieldExtractor* fe = schema->fields_[fid];VertexIndex* index = fe->edge_index_;}
解析LabelId
获取到一段代表点或边属性的二进制之后,通过读取前2字节就可以获取到label id:
char* p = value.Data(); // 表示一个点或边属性值的二进制形式LabelId id = *(uint16_t*) value;
解析定长属性
获取到一段代表点或边属性的二进制之后,通过如下方式可以获取到定长属性的值:
FieldExtractor fe = schema.fields_[schema.name_to_idx_.find(field_name).second];char* p = value.Data();// 通过起始位置 + 定长属性的偏移位置与属性长度可以获取属性值Type val = *((Type*)(p + fe.data_off));
解析变长属性
获取到一段代表点或边属性的二进制之后,通过如下方式可以获取到变长属性的值:
FieldExtractor fe = schema.fields_[schema.name_to_idx_.find(field_name).second];char* p = value.Data();// 通过起始位置 + fe.v_offs获取Variable-Offsets的位置,记为 pos// 通过pos + fe.idx * sizeof(int32_t)可以获取到指向该可变属性值的起始位置的指针Type val = *((Type*)(*(p + fe.v_offs + fe.idx * sizeof(int32_t))));
解析属性是否为optional
对于optional的属性,值可以为空,当值为空时,该属性将不会保存任何值。如何判断该属性值是否为空,需要借助于Null-Array:
FieldExtractor fe = schema.fields_[schema.name_to_idx_.find(field_name).second];char* p = value.Data();// 通过起始位置 + fe.nullable_array_off_可以得到Null-Array数组// 如果对应的位为1,则为空,否则不为空bool is_nul = (p + fe.nullable_array_off_)[fe.null_bit_off_]& (0x1 << (fe.null_bit_off_% 8));
如果你也喜欢TuGraph-DB,欢迎给我们 Star 鼓励哦!
GitHub👉https://github.com/TuGraph-family/tugraph-db

欢迎关注 TuGraph 代码仓库
· https://github.com/tugraph-family/tugraph-db
· https://github.com/tugraph-family/tugraph-analytics
· https://github.com/TuGraph-family/TuGraph-AntGraphLearning
