




一.aggregate 函数
Flink的AggregateFunction是一个基于中间计算结果状态进行增量计算的函数,由于是迭代计算方式,所以,在窗口处理过程中,不用缓存整个窗口数据,所以效率执行比较高。
该函数会将给定的聚合函数应用于每个窗口和键,对每个元素调用聚合函数,以递增方式聚合值,并将每个键和窗口的状态保持在一个累加器。
@PublicEvolving
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {
/**
* Creates a new accumulator, starting a new aggregate.
*
* <p>The new accumulator is typically meaningless unless a value is added
* via {@link #add(Object, Object)}.
*
* <p>The accumulator is the state of a running aggregation. When a program has multiple
* aggregates in progress (such as per key and window), the state (per key and window)
* is the size of the accumulator.
*
* @return A new accumulator, corresponding to an empty aggregate.
*/
ACC createAccumulator();
/**
* Adds the given input value to the given accumulator, returning the
* new accumulator value.
*
* <p>For efficiency, the input accumulator may be modified and returned.
*
* @param value The value to add
* @param accumulator The accumulator to add the value to
*/
ACC add(IN value, ACC accumulator);
/**
* Gets the result of the aggregation from the accumulator.
*
* @param accumulator The accumulator of the aggregation
* @return The final aggregation result.
*/
OUT getResult(ACC accumulator);
/**
* Merges two accumulators, returning an accumulator with the merged state.
*
* <p>This function may reuse any of the given accumulators as the target for the merge
* and return that. The assumption is that the given accumulators will not be used any
* more after having been passed to this function.
*
* @param a An accumulator to merge
* @param b Another accumulator to merge
*
* @return The accumulator with the merged state
*/
ACC merge(ACC a, ACC b);
}
ACC createAccumulator(); 迭代状态的初始值 ACC add(IN value, ACC accumulator); 每一条输入数据,和迭代数据如何迭代 ACC merge(ACC a, ACC b); 多个分区的迭代数据如何合并 OUT getResult(ACC accumulator); 返回数据,对最终的迭代数据如何处理,并返回结果。
val input:DataStream[(String, Int)] = …………
val result: DataStream[Double] = input.keyBy(_._1)
// 设置窗口为滑动窗口,使用事件时间,窗口大小1小时,滑动步长10秒
.window(SlidingEventTimeWindows.of(Time.hours(1), Time.seconds(10)))
.aggregate(new AggregateFunction[(String, Int), (Int, Int), Double] {
// 迭代的初始值
override def createAccumulator(): (Int, Int) = (0, 0)
// 每一个数据如何和迭代数据 迭代
override def add(value: (Int, Int), accumulator: (Int, Int)): (Int, Int) = (accumulator._1 + value._1, accumulator._2 + 1)
// 每个分区数据之间如何合并数据
override def merge(a: (Int, Int), b: (Int, Int)): (Int, Int) = (a._1 + b._1, a._2 + b._2)
})
// 返回结果
override def getResult(accumulator: (Int, Int)): Double = accumulator._1 / accumulator._2
给定迭代初始值 (0, 0)。元组 第一个记录分数,第二个记录数据条数 输入的数据,获取分数,累加到迭代值元组的第一个元素中,迭代值元组的第二个值记录条数加1 。 每一个分区迭代完毕后,各分区的迭代值合并成最终的迭代值 对最终的迭代处理,获取最终的输出结果。
二.示例
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @Classname WindowFunctionAggrectionTest
* @Description TODO
* @Date 2020/11/22 17:26
* @Created by limeng
* 从SocketSource接收数据,时间语义采用ProcessingTime,通过Flink 时间窗口以及aggregate方法统计用户在24小时内的平均消费金额。
*/
object WindowFunctionAggrectionTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setParallelism(1)
val socketData = env.socketTextStream("localhost",9999)
socketData.print("input: ")
import org.apache.flink.api.scala._
socketData.map(line=>{
ConsumerMess(line.split(",")(0).toInt, line.split(",")(1).toDouble)
}).keyBy(_.userId)
.timeWindow(Time.seconds(3))
.aggregate(new MyAggregrateFunction)
.print("output ")
env.execute("WindowFunctionAggrectionTest")
}
case class ConsumerMess(userId:Int, spend:Double)
class MyAggregrateFunction extends AggregateFunction[ConsumerMess, (Int, Double), Double]{
override def createAccumulator(): (Int, Double) = (0,0)
override def add(value: ConsumerMess, accumulator: (Int, Double)): (Int, Double) = {
(accumulator._1 + 1,accumulator._2+value.spend)
}
override def getResult(accumulator: (Int, Double)): Double = {
accumulator._2 / accumulator._1
}
override def merge(a: (Int, Double), b: (Int, Double)): (Int, Double) = {
(a._1+b._1 ,b._2 + a._2)
}
}
}
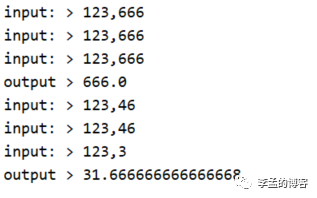
结果
参考
https://blog.csdn.net/duxu24/article/details/105746110
文章转载自李孟的博客,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
