




一.简介
The Dataflow Model 是 Google Research 于2015年发表的一篇流式处理领域的有指导性意义的论文,它对数据集特征和相应的计算方式进行了归纳总结,并针对大规模/无边界/乱序数据集,提出一种可以平衡准确性/延迟/处理成本的数据模型。这篇论文的目的不在于解决目前流计算引擎无法解决的问题,而是提供一个灵活的通用数据模型,可以无缝地切合不同的应用场景。
二.CLC与CAP
CAP
In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed.(http://robertgreiner.com/2014/08/cap-theorem-revisited/)
简单翻译为:
在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
CLC
CAP 定理一直是设计分布式系统首要考虑的问题之一,而在流式处理领域 CAP 有了新的拓展,即 Correctness (准确性),Latency (延迟),Cost (成本),本文将其简称 CLC 。
Correctness 对应 CAP 定理的 Consistence 。如果说分布式存储的 Consistence 表示的是不同副本达到完全一致状态的时间窗口,Correctness 则是在固定的时间窗口内接受到的数据及其计算结果的正确程度(是否乱序,是否完整)。两者看起来似乎并没有很强的联系,但其实两者都是因为数据网络延迟而造成的系统状态落后于真实状态。不同点在于 Consistence 面向的数据源通常是分布式系统的内部节点,而 Correctness 面向的是系统外部的数据源,状态更加不可控。比如前者可以设置超时参数来控制数据的延迟在一个合理的范围,但后者由于数据源在系统外,可能会接受到严重滞后的数据,比如一个用户在野外游玩时的数据在其设备连上网络时一次性发送给服务器。
Latency 对应 CAP 定理的 Availability 。由于实时数据流是无边界的,我们不能假设在某个时间点数据会变得完整,更不能一直等待到那个时刻,因为实时数据流的价值就在于实时性,那时我们的计算结果将一文不值。
Cost 对应 CAP 定理的 Partition Tolerance 。Cost 指的是对于延迟数据的处理带来的额外成本,延迟的定义是事件对应的时间窗口已经关闭,需要修正历史计算结果。
三.核心
逻辑
流式计算/微批次或是批处理,它们要处理的问题都可以抽象为以下几个问题:
•What: 需要计算的结果数据是什么•Where: 计算的上下文环境是什么•When: 什么时候计算输出结果•How: 如何修正早期计算结果
针对这些问题,The Dataflow Model 分别提出了 windowing model , triggering model 和 incremental processing model 。值得注意的是,这些模型并不依赖物理引擎的具体实现,以允许系统设计者结合自己需求灵活集成其中的思想,以及在CLC三者中寻找平衡。
原语
常见的数据处理函数可以分为聚合函数与非聚合函数两大类。对于非聚合函数,每条数据都是独立的,计算引擎只需将它转换为下游需求的格式即可。而聚合类函数只能作用于有界数据集,所以我们需要将实时数据流切分为多个窗口(经常还伴随着分组),然后才可以将聚合函数应用到其上。
在 The Dataflow Model 论文中,计算引擎提供两个原语,ParDo和GroupByKey。ParDo负责执行用户函数,对数据流进行非聚合类的转换。如果Pardo作用于无边界数据集,那么它的输出仍是无边界数据集。而GroupByKey负责将数据进行分组,它会将所有相同key的数据收集到一起,然后再发至下游。显然由于缓存数据的特性,它会将无边界数据转换为有边界数据,但是它没办到单独做到这点,还需要和window函数配合使用。
通过核心原语,用户可以较为自由地描述计算过程,解答了What的问题。
四.窗口策略
除了常见的滑动窗口/翻滚窗口/会话窗口的分类,该论文提出了校准窗口与非校准窗口的区别,定义了基础的窗口操作以及如何基于这些操作来实现不同的Windowing策略。
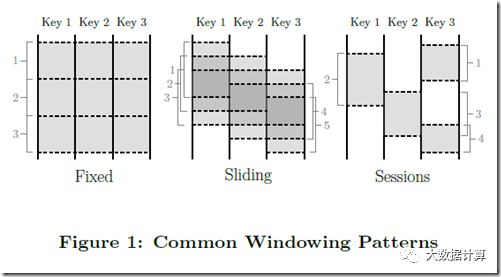
校准窗口指的是落在窗口对应时间范围内的所有数据都被用于该窗口的计算,比如金融市场常见的“前一天交易量”。而非校准窗口指的是只有落在窗口相应时间范围的数据的某一子集用于该窗口的计算,比如只计算某个key的数据。常见的窗口中,翻滚窗口和滑动窗口都属于校准窗口,而会话窗口属于非校准窗口,因为不同key的会话是独立的,只有时间相近且key相同的事件会落入同一会话窗口。
该论文在原语上提供了GroupByKey,支持聚合的系统经常会将其重新定义为粒度更细的GroupByByAndWindow。而论文中的操作实现对非校准窗口的支持,包含了两个关键的观点: 一是从模型简化的角度上,把所有的窗口策略都当做非对齐窗口,而底层实现来负责把对齐窗口作为一个特例进行优化;二是窗口操作可以被分隔为assignWindows和mergeWindows两个相关的操作。
assignWindows即为事件分配对于的窗口。细心的同学可以发现这里的Window是复数,是不是意味着可以为一个事件分配多个窗口?事实上的确如此,这里的分配操作更像是复制到窗口里,因此如果分配给多个窗口则会产生冗余。
mergeWindows即对多个窗口进行合并,通常的使用场景是滑动窗口(校准窗口)间的合并和会话窗口(非校准窗口)间的合并。
Windowing 策略描述了事件处理的上下文,即Where的问题。
五.数据并行与任务并行
Dataflow图的并行性可以通过多种方式利用。首先你可以将输入数据分组,让同一操作的多个任务并行任务在不同数据子集上,这种并行称为数据并行。数据并行非常有用,因为它能够将计算负载分配到多个节点上从而允许处理大规模的数据。再者,你可以让不同算子的任务(基于相同或不同的数据)并行计算,这种并行称为任务并行,更好的利用集群资源。
六.数据交换策略
数据交换策略定义如何将数据项分配给物理Dataflow图中的不同任务。这些策略可以由执行引擎根据算子的语义自动选择,也可由编程人员显示指定。
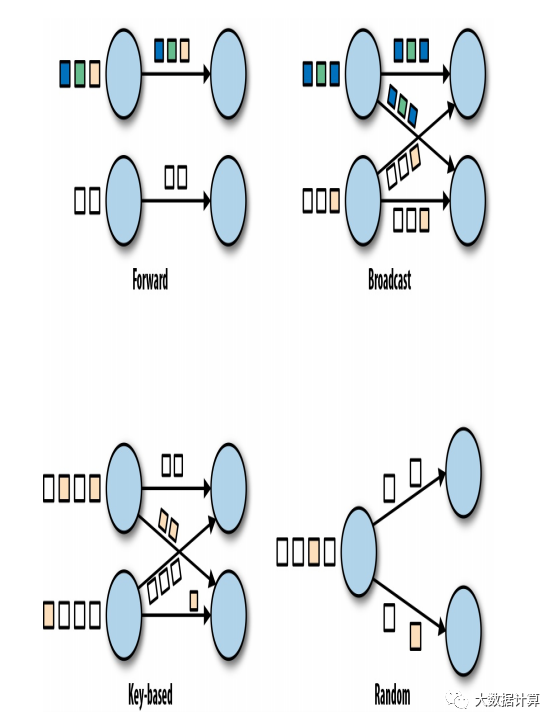
转发策略(forward strategy):在发送端任务和接收端任务之间一对一地进行数据传输。如果两端任务运行在同一物理机器上(通常由任务调度器决定),该交换策略可以避免网络传输。
广播策略(broadcast strategy):会把每个数据项发往下游算子的全部并行任务。该策略会把数据复制多份且涉及网络通信,因此代价十分昂贵。
基于键值策略(key-based strategy):根据某一键值属性对数据分区,并保证键值相同的数据项交由同一任务处理。
随机策略(random strategy):会将数据均匀分配至算子的所有任务,以实现计算任务的负载均衡。
参考
https://www.whitewood.me/2018/05/07/The-Dataflow-Model-%E8%AE%BA%E6%96%87%E6%80%BB%E7%BB%93/
《Stream Processing with Apache Flink》
