





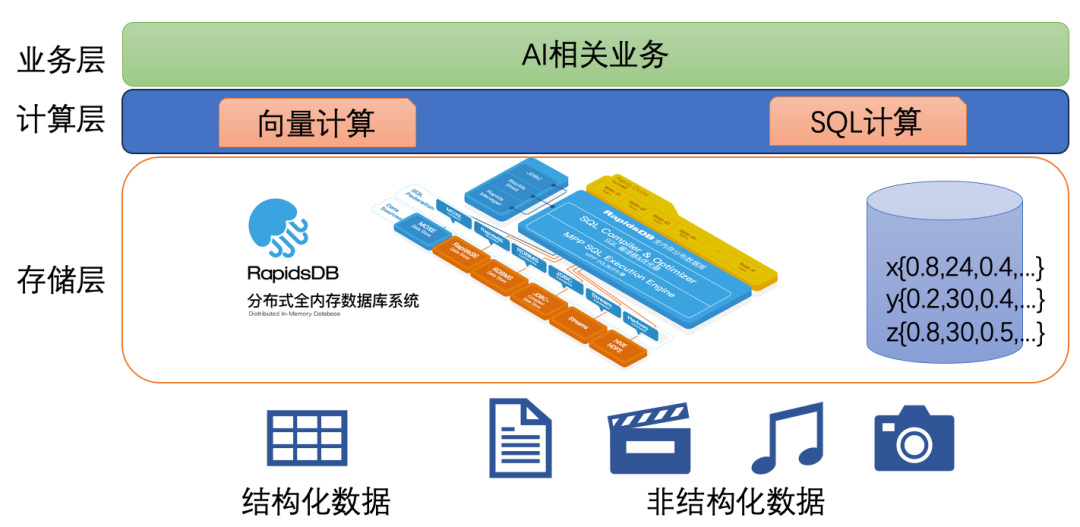
柏睿向量数据库技术架构
Rapids VectorDB基于RapidsDB实现高效安全的向量存储
助力构建强大的向量数据实时处理与分析能力
让向量数据资产管理与智能应用更简单、更经济
本期将重点介绍柏睿向量数据库基于柏睿分布式全内存数据库RapidsDB实现向量存储的创新实践。

Embedding (向量嵌入)通过将高维度的原始数据(如文字、图片、音频等)映射到低维度的向量空间,从而将半结构化、非结构化数据转化向量形式,其中每个向量元素通常代表特定的特征或属性。
向量数据类似于数字序列,这种类型的数据存储是传统数据库的强项。柏睿数据具有完全自主知识产权的新一代分布式全内存数据库RapidsDB在这方面具有显著优势。
因此,柏睿向量数据库Rapids VectorDB采用RapidsDB作为向量存储模块。基于成熟丰富的数据管理经验,RapidsDB可为高性能向量检索和相似性搜索提供灵活高效、安全可靠的向量存储服务。
Rapids VectorDB是一个高度可扩展的分布式系统,支持多节点并行计算,以提供极致性能的存储服务,支撑AI大模型等AI应用场景中大规模向量数据处理需求。
在默认情况下,当Rapids VectorDB集群中每创建一个存储节点,系统则为该存储节点上的每个CPU内核创建一个分区,以实现最大化的并行性。用户也可以在创建数据时,通过参数自定义该数据库将被分为多少个分区。
当业务增长过快产生资源瓶颈或性能瓶颈时,用户可以通过增加服务器的方式,进行动态扩容;也可以通过增加集群中的存储节点,以获得更多的数据分区,从而达到在不增加服务器负载的同时线性提升性能的目的。
同时使用成熟的SQL数据库技术均衡分散向量数据存储与计算,以提供更高的性能。
基于分布式数据存储,形成主副两个可用性组,存储节点以成对的配置模式在彼此之间共享数据副本。
某个存储节点出现故障时,其可根据需要自动进行故障转移,而集群不会离线。当主分区数据发生变化时,用户可通过平衡数据分区的指令来使副本分区的数据进行同步,从而确保主副分区数据的一致性和持续可用。
欢迎文末留言,与我们探讨关于向量数据库的技术原理、方法与实践!
下一期将分享柏睿向量数据库在向量计算方面的技术思考与实践。
推荐阅读



你的 在看 为智能数据算力点赞
