




Table of Contents
前言
说明
简介
Reactor 是一个基于 JVM 之上的异步应用基础库。为 Java 、Groovy 和其他 JVM 语言提供了构建基于事件和数据驱动应用的抽象库。Reactor 性能相当高,在最新的硬件平台上,使用无堵塞分发器每秒钟可处理 1500 万事件。
《Reactor 指南中文版》原文出自《Reactor Guide》,由多位网友在开源中国众包平台协作翻译完成,其中:
《Reactor 介绍》、《reactor 核心》由 @viemacs 翻译, @静怡芸香 校对;
《reactor-数据流》由 @leoxu 、@K6F 翻译及校对;
《reactor-总线》、《reactor-网络》、《扩展》由@K6F 翻译,@暖冰 校对。
反馈
对《Reactor 指南中文版》有任何反馈,欢迎在以下网址评论:
http://www.oschina.net/news/68445
特别说明
《Reactor 指南中文版》由开源中国组织翻译,转载请注明出处,未经许可不得为其它商业目的使用。
1
Reactor 介绍
Reactor 是一个基础库,可用它构建时效性流式数据应用,或者有低延迟和容错性要求的微/纳/皮级服务。
- 前言 Preface
TL;DR
什么是 Reactor?
现在你要了解下 Reactor,不妨在你喜欢的搜索引擎里输入 Reactive,Spring+Reactive,Asynchronous+Java 之类的关键词,或者直接输入 Reactor是什么货?。简单说,Reactor 是一个轻量级 JVM 基础库,帮助你的服务或应用高效,异步地传递消息。
"高效"是指什么?
- 消息从 A传递到 B 时,产生很少的内存垃圾,甚至不产生。
- 解决消费者处理消息的效率低于生产者时带来的溢出问题。
- 尽可能提供非阻塞异步流。
从经验可知(主要是 #rage 和 #drunk 的推特),异步编程很难,而像 JVM 这类提供众多可选参数的平台则尤其困难。 Reactor 旨在帮助大多数用例真正非阻塞地运行。我们提供的 API 比 JDK 的 java.util.concurrent 库低级原语更高效。Reactor 提供了下列功能的替代函数 (并建议不使用 JDK 原生语句):
- 阻塞等待:如 Future.get()
- 不安全的数据访问:如 ReentrantLock.lock()
- 异常冒泡:如 try…catch…finally
- 同步阻塞:如 synchronized{ }
- Wrapper 分配(GC 压力):如 new Wrapper(event)
当消息传递效率成为系统性能瓶颈的时候(10k msg/s,100k msg/s,1M...),非阻塞机制就显得尤为重要。 虽然这个有理论支持 (参见 Amdahl’s Law),但读起来太无聊了。我们举例说明,比如你用了个 Executor 方法:
private ExecutorService threadPool = Executors.newFixedThreadPool(8);
final List<T> batches = new ArrayList<T>();
Callable<T> t = new Callable<T>() { // *1
public T run() {
synchronized(batches) { // *2
T result = callDatabase(msg); // *3
batches.add(result);
return result;
}
}
};
Future<T> f = threadPool.submit(t); // *4
T result = f.get() // *5
- Callable 分配 -- 可能导致 GC 压力。
- 同步过程强制每个线程执行停-检查操作。
- 消息的消费可能比生产慢。
- 使用线程池(ThreadPool)将任务传递给目标线程 -- 通过 FutureTask 方式肯定会产生 GC 压力。
- 阻塞直至 callDatabase() 回调。
在这个简单的例子中,很容易指出为什么扩容是很有限的:
- 分配对象可能产生 GC 压力,特别是当任务运行时间过长。
- 每次 GC 暂停都会影响全局性能。
- 默认,队列是无界的,任务会因为数据库调用而堆积。
- 积压虽然不会直接导致内存泄漏,但会带来严重副作用:GC 暂停时要扫描更多的对象;有丢失重要数据位的风险;等等 …
- 典型链式队列节点分配时会产生大量内存压力。
- 阻塞回调容易产生恶性循环。
- 阻塞回调会降低消息生产者的效率。在实践中,任务提交后需要等待结果返回,此时流式过程几乎演变为同步的了。
- 会话过程抛出的任何带数据存储的异常都会以不受控的方式被传递给生产者,否定了任何通常在线程边界附近可用的容错性。
要实现完全非阻塞是很难办到的,尤其是在有着类似微服务架构这样时髦绰号的分布式系统的世界里。因此 Reactor 做了部分妥协,尝试利用最优的可用模式,使开发者觉得他们是在写异步纳米服务,而不是什么数学论文。
没有什么传播得比光快(除了绯闻和网红猫的视频),正如到了某个阶段,延迟是每一个系统到都要面对的实实在在的问题。为此:
Reactor 提供的框架可以帮助减轻应用中由延迟产生的副作用,只需要增加一点点开销:
- 使用了一些聪明的结构,通过启动预分配策略解决运行时分配问题;
- 通过确定信息传递主结构的边界,避免任务的无限堆叠;
- 采用主流的响应与事件驱动构架模式,提供包含反馈在内的非阻塞端对端流;
- 引入新的 Reactive Streams 标准,拒绝超过当前容量请求,从而保证限制结构的有效性;
- 在 IPC 上也使用了类似理念,提供对流控制友好的非阻塞 IO 驱动;
- 开放了帮助开发者们以零副作用方式组织他们代码的函数接口,借助这些函数来处理容错性和线程安全。
关于该项目
该项目始于 2012 年。 经过长时间的内部孵化,于 2013 年发布 Reactor 1.x 版本。 Reactor 1 在各种架构下都能成功部署,包括开源的(如 Meltdown)和商业的(如 Pivotal RTI)。2014年,我们开始与一些新兴的响应式数据流规范合作,重新设计并于 2015 年 4 月发布 Reactor 2.0 版本。响应式数据流规范填补了指派机制的最后一个缺口:传输过程中,数据设置多大,才不会触发线程边界问题
同时,随着响应式扩展日益普及,文档逐渐完善,我们也不断调整部分事件驱动和任务协作类 API。
Pivotal 不仅是 Spring 框架发起者,许多员工都曾是各种 Spring 代码核心贡献者;Pivotal 也资助着 Reactor,两名 Reactor 核心开发人员在 Pitoval 工作。我们提供 Reactor 到 Spring 的整合支持,以及部分 Spring 框架重要功能的支持,如 spring-messaging 的 STOMP 中继代理。尽管如此,我们并不强求使用 Reactor 用户必须采用 Spring。我们为"Reactive 大众"保留可嵌入工具箱。实际上,Reactor 仅仅致力于解决异步和函数调用问题。
Reactor 遵循 Apache 2.0 许可,可在 GitHub 上获取。
使用前提
- 使用 Reactor,Java 版本最低需要 Java 7。
- 若要充分发挥函数组件潜力,需要 Java 8 Lambdas 支持。
- 采用 Spring,Clojure 和 Groovy 扩展作为后备。
- JVM 支持非安全访问时 Reactor 可满负荷运行 (比如不是Android的情况)。
- 若没有访问非安全策略,基于环形缓冲区的所有特性都不起作用。
- Reactor 在 Maven Central 中以传统 JAR 格式打包,你可以用你所习惯的构建工具在任何 JVM 工程中安装该依赖。
构架总览
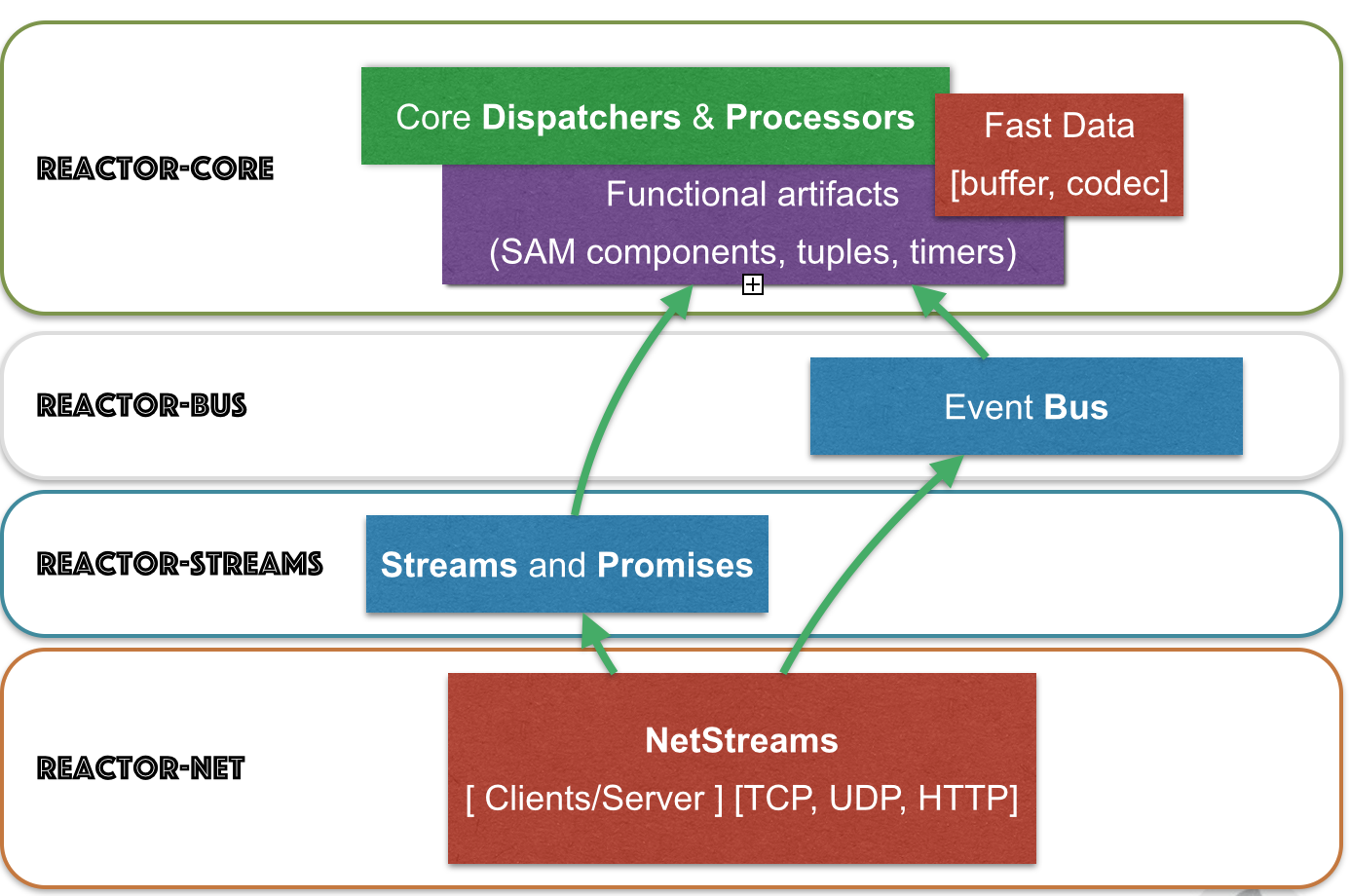
图 1. Reactor 2.0 主要模块
Reactor 代码库拆分成多个子模块,便于选择所需功能,不受其他功能代码块干扰。
下面举例说明,为实现异步目标,响应式技术和 Reactor 模块该如何搭配:
- Spring XD + Reactor-Net (Core/Stream): 使用 Reactor 作为 Sink/Source IO 驱动。
- Grails | Spring + Reactor-Stream (Core): 用 Stream 和 Promise 做后台处理。
- Spring Data + Reactor-Bus (Core): 发射数据库事件 (保存/删除/…)。
- Spring Integration Java DSL + Reactor Stream (Core): Spring 集成的微批量信息通道。
- RxJavaReactiveStreams + RxJava + Reactor-Core: 融合富结构与高效异步 IO 处理
- RxJavaReactiveStreams + RxJava + Reactor-Net (Core/Stream): 用 RxJava 做数据输入,异步 IO 驱动做传输。
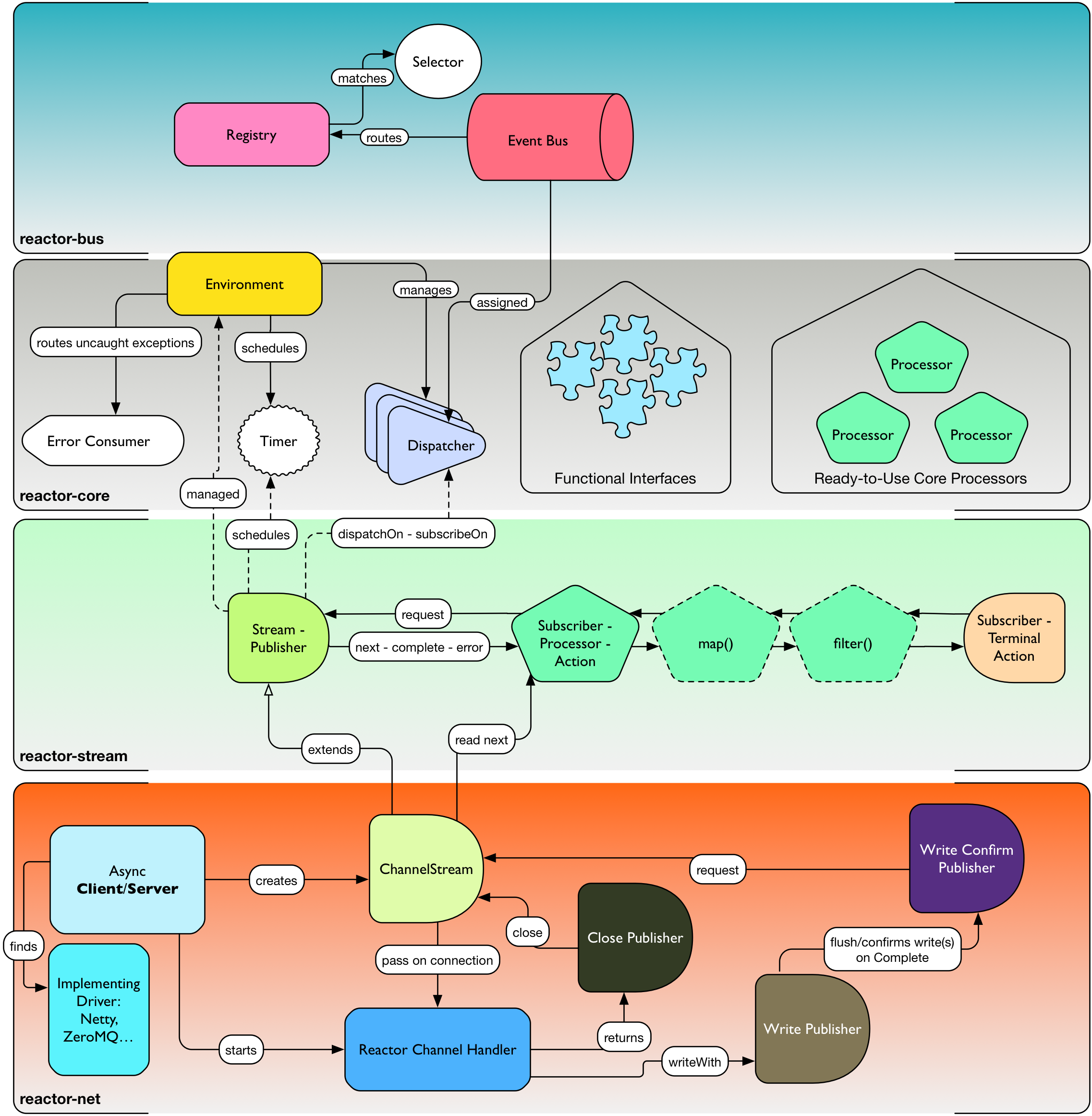
图2. Reactor 模块相互依赖关系快速概览
响应式数据流
响应式数据流作为一种新的数据流规范应用于 Java 9 及其后续版本,并被多个供应商和技术企业采纳,包括包括 Netflix,Oracle,Pivotal 或 Typesafe。
这一规范的定位非常清晰,旨在提供同/异步数据序列流式控制机制,并在 JVM 上首先推广。该规范由 4 个 Java 接口,1 个 TCK 和一些样例组成。在实现所需的 4 个接口之外,该规范的实质在于经由 TCK 验证的行为状态。能成功通过 TCK 实现类检测意味着满足 Reactive Streams Ready 状态。
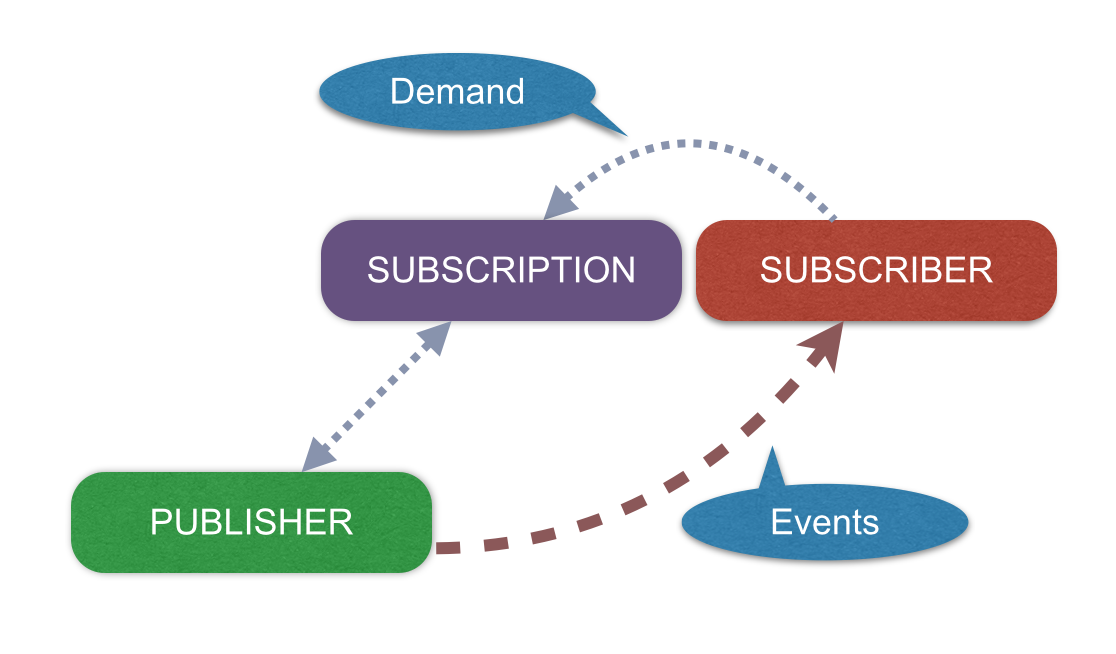
图 3. 响应式数据流约定
响应式数据流接口
- org.reactivestreams.Pubslisher:数据流发布者(信号从 0 到 N,N 可为无穷)。提供两个可选终端事件:错误和完成。
- org.reactivestreams.Subscriber:数据流消费者(信号从 0 到 N,N 可为无穷)。消费者初始化过程中,会请求生产者当前需要订阅多少数据。其他情况,通过接口回调与数据生产方交互: 下一条(新消息)和状态。状态包括:完成/错误,可选。
- org.reactivestreams.Subscription:初始化阶段将一个小追踪器传递给订阅者。它控制着我们准备好来消费多少数据,以及我们想要什么时候停止消费(取消)。
- org.reactivestreams.Processor:同时作为发布者和订阅者的组件的标记。

图 4. 响应式数据流发布协议
订阅者有两种方式向发布者请求数据,如下所示:
- 无界的:订阅者只需要调用 Subscription#request(Long.MAX_VALUE) 即可。
- 有界的:订阅者保留数据引用,调用request(long) 方法消费。
- 通常订阅者在订阅时会请求一个初始数据集或者一个数据
- 在 onNext 成功后(如 Commit,Flush 等… 之后),请求更多数据
- 建议请求数量呈线性,尽量避免请求叠加, 如每下一个信号请求 10 个数据
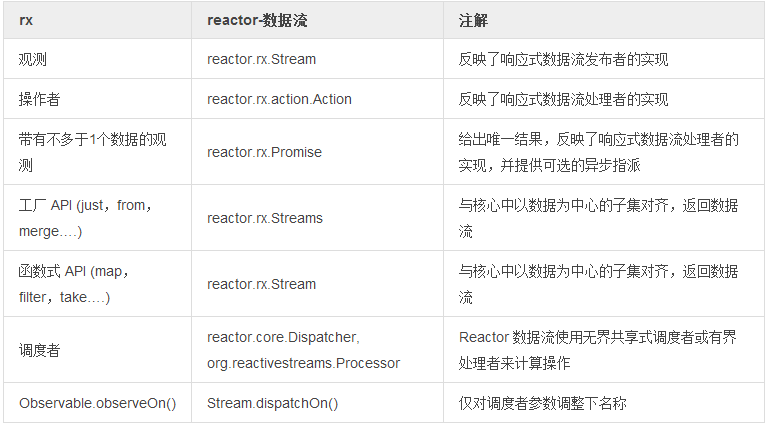
表1. 迄今为止,Reactor 可直接使用的接口有:
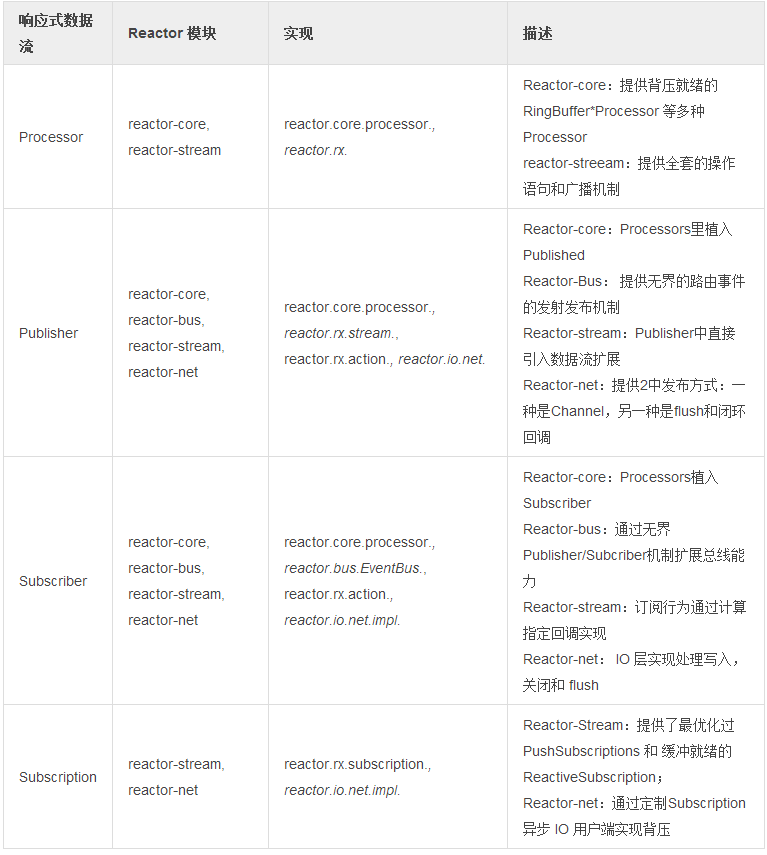
我们从 Reactor 2 开始就严格遵守这个规范直到 1.0.0 发布,在 Maven Central 和其他镜像上都可使用。当然它也是 reactor-core 的传递依赖。
响应式扩展
响应式扩展,就是通常所说的 Rx,是一组定义良好的函数式 API,大规模扩展了观察者模式。
Rx 模式支持响应式数据序列处理,主要的设计要点有:
- 使用回调链分离时间/延迟:仅当数据可用时才会回调
- 分离线程模型:用 Observable / Stream 来处理同步或异步
- 控制错误链/终止:数据载荷信号以及错误与完成信号都传递给回调链
- 解决各种预定义 API 中多重分散-聚合和构造问题
JVM 中响应式扩展的标准实现是 RxJava。它提供了强大的函数式 API,并将原始微软库中几乎全部的概念移植了过来。
Reactor 2 提供了一个实现了响应式扩展子集的特定模块,并在少量场合下调整了名称来匹配我们的特定行为。这种关注以数据为中心的问题(微批处理,构造…)的方法依赖于 Reactor 函数式单元,指派者和响应式数据流约定. 我们提倡需要各种 响应式扩展的用户尝试使用 RxJava 并和我们沟通。最终,用户能受益于 Reactor 以及与 RxJava 生态系统组合所提供的强大的异步和 IO 能力。
¡ 现阶段一些操作,行为和响应式数据流的概念仍然是 Reactor 所特有的。我们将会在合适的章节充实这些特性。
! 因为背压和自动冲洗(flush)选项和原因,异步 IO 能力仍依赖于数据流能力。
表2. Rx 与 Reactor 数据流之间的错位
2
reactor-核心
永远别独自展开异步工作。
— Jon Brisbin
在写 Reactor 1 之后
永远别独自展开异步工作。
— Stephane Maldini 在写 Reactor 2 之后
先来看看,某项目是如何使用 Groovy 的:
// 初始化上下文,获取默认调度者
Environment.initialize()
// RingBufferDispatcher,默认带 8192 槽容量
def dispatcher = Environment.sharedDispatcher()
// 创建回调
Consumer<Integer> c = { data ->
println "some data arrived: $data"
}
// 创建 error 回调
Consumer<Throwable errorHandler = { it.printStackTrace }
// 异步分发数据
dispatcher.dispatch(1234, c, errorHandler)
Environment.terminate()
然后,再看看响应式数据流例子
// 独立异步处理者
def processor = RingBufferProcessor.<Integer>create()
// 发送数据,确保数据的安全性,直到订阅成功
processor.onNext(1234)
processor.onNext(5678)
// 消费整型数据
processor.subscribe(new Subscriber<Integer>(){
void onSubscribe(Subscription s){
//unbounded subscriber
s.request Long.MAX
}
void onNext(Integer data){
println data
}
void onError(Throwable err){
err.printStackTrace()
}
void onComplete(){
println 'done!'
}
}
// 完全关闭内部线程和调用
processor.onComplete()
核心概述
图 5. Doge 如何使用 Reactor-核心
Reactor 核心含有如下特性:
- 通用 IO & 函数式类型,一些 Java 8 接口的反向移植•函数,提供者,消费者,谓词,双向消费者,双向函数
- 元组
- 资源池、暂停器、定时器
- 缓冲器,编解码和少量预定义的编解码器
- 环境上下文
- 调度者约定和几个预定义调度者
- 预定义响应式数据流处理者
Reactor-核心自身可替代其它消息传递机制,完成时序任务调度,或者帮你将代码组织为函数块,实现 Java 8 的反向移植接口。这种拆分便于同其他的响应式库配合使用,而没耐心的开发者也不用再去费劲弄懂环形缓冲区了。
¡ Reactor-核心隐含覆盖 LMAX Disruptor,所以它不和已有的 Disruptor 依赖共存或碰撞。
函数式功能
可重用函数块基本是你一开始使用 Reactor 就需要的核心功能。[1] 那么函数式编程酷在哪里呢? 其核心理念之一将可执行代码当作另一种数据来处理。[2]业务逻辑由原始调用者决定,这与闭包和匿名函数的理念不谋而合。函数式编程还避免了 IF/SWITCH 语句块的包袱,并清晰地分离了功能:每个代码块只负责一个独立功能,而不共享内容。
- 除非你只想用核心处理功能,而这些功能在这一阶段是基本独立的。我们打算逐步将调度器与核心调整到一致。
- 有人也许要说这观点过于简化了,不过我们这里先讲求实用 :)
规划函数块
每个函数组件有明确的功能:
- 消费者:使用回调函数 — 登记后就不用管了
- 双向消费者:带双参数的简单回调 (通常用于序列比较,如前后参数比较)
- 函数:转换逻辑 - 请求/回应
- 双向函数:带双参数的转换逻辑 (通常用于累加器,比较前后参数并返回一个新值)
- 供给者:工厂逻辑 - 轮询
- 谓词:测试逻辑 - 过滤
¡ 我们将发布者和订阅者接口也作为函数块处理,我们称之为响应式函数块。它们是基本的组件,在 Reactor 和 Beyond 中到处都有用到。通常可以直接调用数据流 API 来创建恰当的订阅者,你只需要向 API 传入 reactor.fn 参数。
好消息是:封装在函数功能中的可执行指令,可以像乐高积木一样重用。
Consumer<String> consumer = new Consumer<String>(){
@Override
void accept(String value){
System.out.println(value);
}
};
// 为了简约,现在用 Java 8 风格
Function<Integer, String> transformation = integer -> ""+integer;
Supplier<Integer> supplier = () -> 123;
BiConsumer<Consumer<String>, String> biConsumer = (callback, value) -> {
for(int i = 0; i < 10; i++){
// 对要运行的最后逻辑运行做惰性求值
callback.accept(value);
}
};
// 注意生产者到双向消费者执行过程
biConsumer.accept(
consumer,
transformation.apply(
supplier.get()
)
);
乍一看,你可能会觉得这个革新并不特别,但是这种编程理念的变化,对后续我们构建分层可组合代码却尤其重要。调度者通过消费者处理类型化的数据和错误的回调。Reactor Stream 模块也基于该理念实现优雅编码。
♠ 使用 Spring 这样的 IoC 容器的良好实践是利用 Java 配置特性返回无状态函数式 Beans。然后就可以从容地将代码块注入数据流管道,或者指派代码块的执行。
元组
或许你已经注意到:Reactor 提供的接口都是强类型、带有泛型支持和少量确定数目的参数。那如果形参个数大于1或者2呢,又该怎么办呢?此时,需要使用一个类:元组。元组像是单对象实例中的带类型 CSV 行,在函数式编程中,就是通过元组保证类型安全呢和可变参数。
让我们用双参数双向消费者代替单参数消费者实现上例的过程:
Consumer<Tuple2<Consumer<String>, String>> biConsumer = tuple -> {
for(int i = 0; i < 10; i++){
// 类型正确,开启编译器
tuple.getT1().accept(tuple.getT2());
}
};
biConsumer.accept(
Tuple.of(
consumer,
transformation.apply(supplier.get())
)
);
¡ 元组涉及到更多的资源分配,因此,通常键值对比较和键值信号量更倾向使用 Bi **类型接口。
环境与调度者
函数式功能块到位后,接下来开启异步之旅。第一步我们来看调度者的部分。
使用调度者前,先要确认我们能快速地创建它们。通常创建调度者开销较大,因为它们要预分配一个内存段以确保高度信号,实际上这是序言中所阐述的非常著名的运行时 VS 启动时平衡问题。 Reactor 引入了名为 环境 的特定共享上下文来管理各种调度者,来避免不恰当的创建。
环境
环境由 Reactor 用户(或可用的扩展库,如 @Spring)来创建和终止。它们自动读取位于 META_INF/reactor/reactor-environment.properties 的配置文件。
♠ 属性文件可在运行时通过 META-INF/reactor 类路径下所需的新属性配置进行调校。
运行时替换默认配置的操作可通过传递如下环境变量来实现:reactor.profiles.active.
java - jar reactor-app.jar -Dreactor.profiles.active=turbo
环境初始化与终止示例
Environment env = Environment.initialize();
// 判断系统环境与初始化环境是否相同
Assert.isTrue(Environment.get() == env);
// 找到名为"共享"的调度者
Dispatcher d = Environment.dispatcher("shared");
// 计时器与环境计时器绑定
Timer timer = Environment.timer();
// 关闭可能运行非守护进程的寄存调度者和计时器
Environment.terminate();
// 备选方案:通过注册shutdownHook实现终止自动调用
♠ 对一个给定的 JVM 应用,最佳实践是:保持单一的运行环境。大多数情况首选 Environment.initializeIfEmpty()。
调度者
Reactor 1 就提及过调度者,它用类似 Java Executor 的通用约定抽象出信息传递的方法。它实际上扩展了 Executor。
调度者约定提供了一个传递信号的强类型方式,相应的数据及错误消费者可以同(异)步执行。我们用这种方法解决了经典的 Executor 首要面临的问题:错误隔离。调用 Error 消费者比中断已分配资源过程效果更好。如果没有可调用的,调度者将尝试找一个现存的环境并使用其 errorJournalConsumer。
异步调度者提供的第二个特性是使用尾递归策略的可重入调度。尾递归的使用情形是,调度检测到 调度者classLoader 已被分配到运行中的线程,此时将当前消费者返回时将要执行的任务入队。
使用同步多线程调度者,比如这个 Groovy Spock 测试:
import reactor.core.dispatch.*
//...
given:
def sameThread = new SynchronousDispatcher()
def diffThread = new ThreadPoolExecutorDispatcher(1, 128)
def currentThread = Thread.currentThread()
Thread taskThread = null
def consumer = { ev ->
taskThread = Thread.currentThread()
}
def errorConsumer = { error ->
error.printStackTrace()
}
when: "a task is submitted"
sameThread.dispatch('test', consumer, errorConsumer)
then: "the task thread should be the current thread"
currentThread == taskThread
when: "a task is submitted to the thread pool dispatcher"
def latch = new CountDownLatch(1)
diffThread.dispatch('test', { ev -> consumer(ev); latch.countDown() }, errorConsumer)
latch.await(5, TimeUnit.SECONDS) // 等待任务执行
then: "the task thread should be different when the current thread"
taskThread != currentThread
! 我们将在随 2.x 发布计划加入 Executor 等没有的特性:响应式数据流协议。它们是 Reactor 没有直接绑定到响应式数据流标准的剩余部分之一。然而,它们可以与 Reactor 数据流结合并快速绑定,正如我们在数据流章节中将要探索的一样。本质而言,它意味着用户可以直接使用,直到最终或暂时遇到大部分调度者实现的容量界限。
表 3. 调度者族介绍
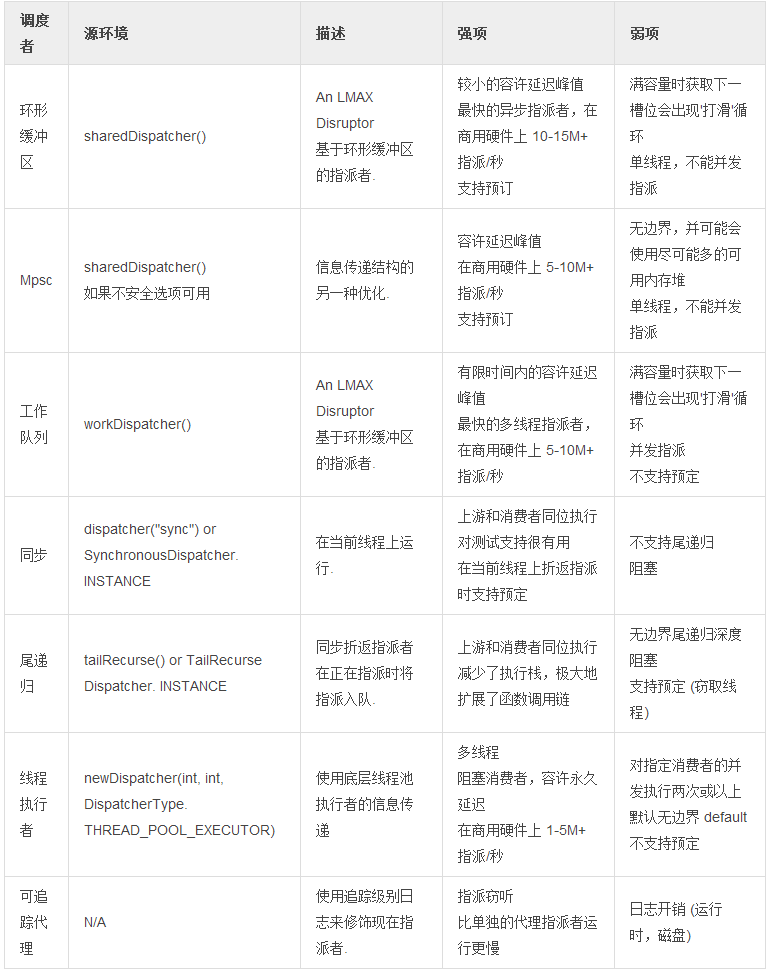
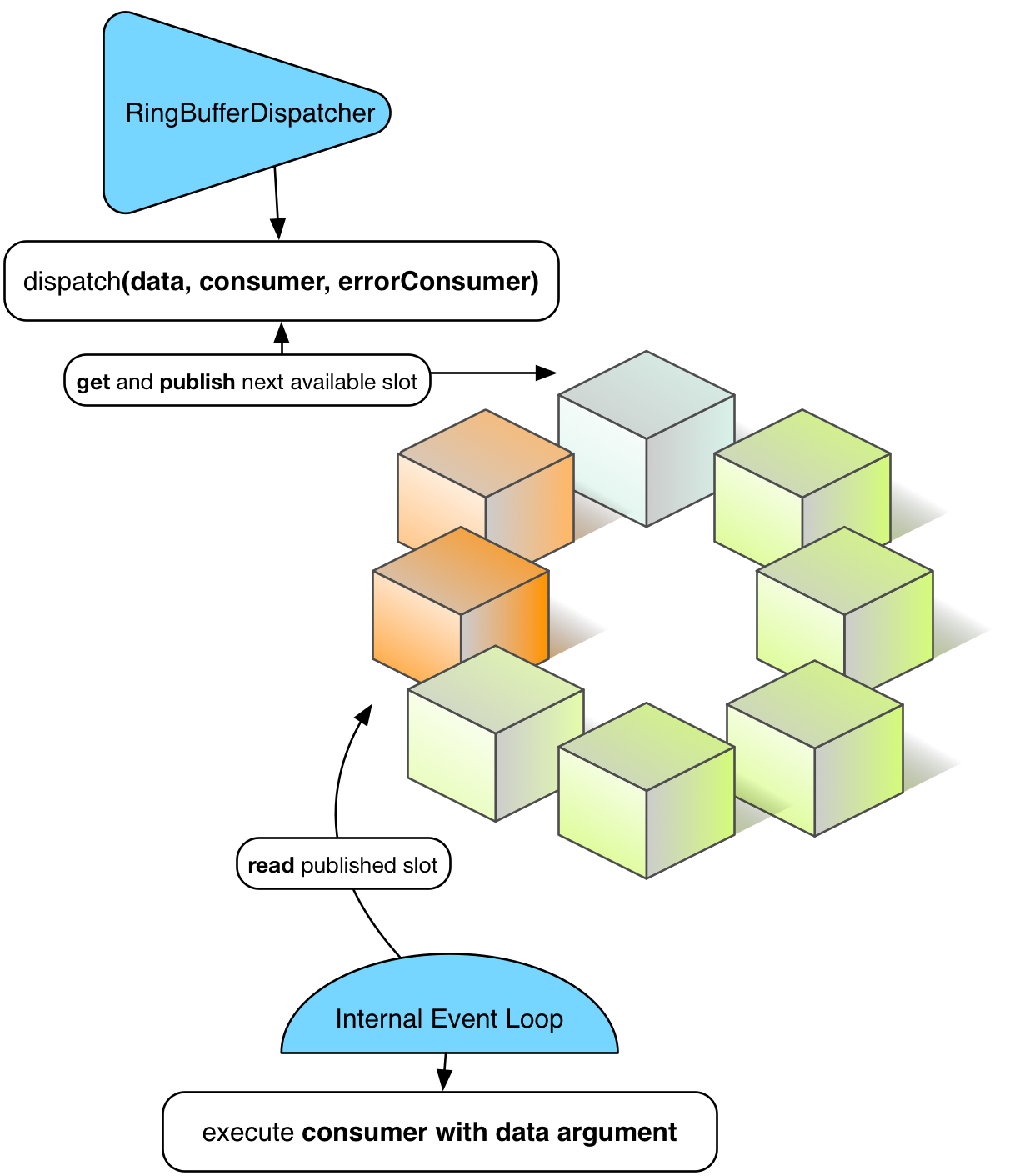
图 6. 给定时刻 T 的 RingBufferDispatcher
调度供给者
你也许注意到了一些调度者是间线程的,特别是 RingBufferDispatcher 和 MpscDispatcher。更进一步,根据响应式数据流规范,订阅者/处理者的实现中不应允许并发通知。这特别影响到了 Reactor 数据流。如果尝试带着调度者使用 Stream.dispatchOn(Dispatcher) 会引入并发信号,很明显会失败。
不过,可以用调度者池或调度供给者来绕过这个限制。作为供给者工厂,Supplier.get() 提供的间接取回调度者功能容许了一些有趣的缓冲池策略:循环,最少使用, …
环境提供了静态助手来对当前活动的调度者环境池进行创建,并最终反寄存:循环所返回的调度者组。一旦就绪,供给者将提供可控数量的调度者。
环境对调度者通常的一站式管理:
Environment.initialize();
//....
// 创建有2个调度者的匿名池,采用自动的默认设定(与默认调度者相同的类型,默认的积压大小...)
DispatcherSupplier supplier = Environment.newCachedDispatchers(2);
Dispatcher d1 = supplier.get();
Dispatcher d2 = supplier.get();
Dispatcher d3 = supplier.get();
Dispatcher d4 = supplier.get();
Assert.isTrue( d1 == d3 && d2 == d4);
supplier.shutdown();
// 创建并注册带3个调度者的新池
DispatcherSupplier supplier1 = Environment.newCachedDispatchers(3,"myPool");
DispatcherSupplier supplier2 = Environment.cachedDispatchers("myPool");
Assert.isTrue( supplier1 == supplier2 );
supplier1.shutdown();
计时器
调度者以尽可能快的速度运算传入的任务,而计时器提供了定期的一次性调度 API。Reactor 核心默认提供了 HashWheelTimer,并自动绑定到任一新建的环境上。HashWheelTimer 可以完美处理内存中大量并发任务,是 Java TaskScheduler 的强大替代选择。
! 虽然它适用于窗口技术 (分钟级以下的迷你任务),但因所有任务会随应用关闭而丢失,它并不用于弹性调度。
♠ 计时器在下次发布时会得到更多关注,比如我们想对 Redis 加入持续/共享调度支持。请在此表达你的意见,或提供一些贡献!
在我们的 Groovy Spock 测试 中创建的一个简单计时器:
import reactor.fn.timer.Timer
//...
given: "a new timer"
Environment.initializeIfEmpty()
Timer timer = Environment.timer()
def latch = new CountDownLatch(10)
when: "a task is submitted"
timer.schedule(
{ Long now -> latch.countDown() } as Consumer<Long>,
period,
TimeUnit.MILLISECONDS
)
then: "the latch was counted down"
latch.await(1, TimeUnit.SECONDS)
timer.cancel()
Environment.terminate()
核心处理者
核心处理者的工作比调度者更加专一:计算支持背压的异步任务。
同时它直接实现了 org.reactivestreams.Processor 接口,可以良好地与其它响应式数据流提供方合作。比如同时作为订阅者和发布者的处理者。你可以将它插入到响应式数据流链中你想要的地方(源,处理过程,槽)。
! 规范并不明确推荐直接使用 Processor.onNext(d)。我们技术上支持那种做法,但背压并不会传播,除非最终出现阻塞。你可以明确地用匿名订阅来做传递,先是用 Processor.onSubscribe 传递给处理者,用所实现的请求方式来获取背压反馈。
! OnNext 必须要序列化,例如每次来自一个单线程(不允许并发的 onXXX 信息)。不过 Reactor 可以支持这种方法,如果使用常规的 Processor.share() 方式创建处理者的话,比如 RingBufferProcessor.share()。在创建时就要决定用哪种方法,以便在实现中使用正确的协调逻辑,所以要谨慎选择:是要做一个标准发布序列(无并发),还是要使用多线程。
Reactor 在处理特定的某某工作处理者功能时有一个特例:
- 通常响应式数据流处理者会将相同的数据序列异步调度至所有在给定时刻 T 订阅的订阅者。这与发布/订阅模式类似。
- 工作处理者以方便的方式来分发数据,尽可能利用所有的订阅者。这意味着在给定时刻 T 的订阅者将一直看到不同的数据。这与工作队模式类似。
我们计划随着 2.x 的发布计划增加我们的核心处理者集。
环形缓冲区处理者
基于环形缓冲区的响应式数据流处理者有一些很棒的特性:
- 高吞吐量
- 重现最新未消费数据
- 如果没有订阅者在监听,数据不会丢失(不同于Reactor-数据流的广播者)。
- 如果订阅者在处理过程中取消,信号可以安全重现,该功能用环形缓冲区工作处理者 时也可以良好工作
- 智能背压,允许任意时刻动态分配大小,方便订阅者负责消费和请求更多数据
- 传播背压,作为处理者,可被订阅并传递信息
- 多线程入站/出站处理能力
实际上环形缓冲区处理者就是有类型的 MicroMessageBroker!
它仅有的缺陷在于运行时创建的成本较高,也不像环形缓冲区指派者那样容易共享。因而它适用于高吞吐量预定义数据管线。
环形缓冲区处理者
Reactor 中 RingBufferProcessor 组件本质上是适应响应式数据流 API 的 Disruptor RingBuffer 。它的目的在于提供与尽可能接近裸机的效率。它的适用场合是将任务以极低的开销,极高的吞吐量指派到其它线程上,并在你的工作流中管理背压.
我用环形缓冲区处理者来异步计算各种远程产出调用:AMQP,SSD 存储和内存中的储存,处理者完全覆盖了多变的延迟,我们的每秒百万信息的数据源从未阻塞过!
— Reactor 用户
环形缓冲区处理者用例
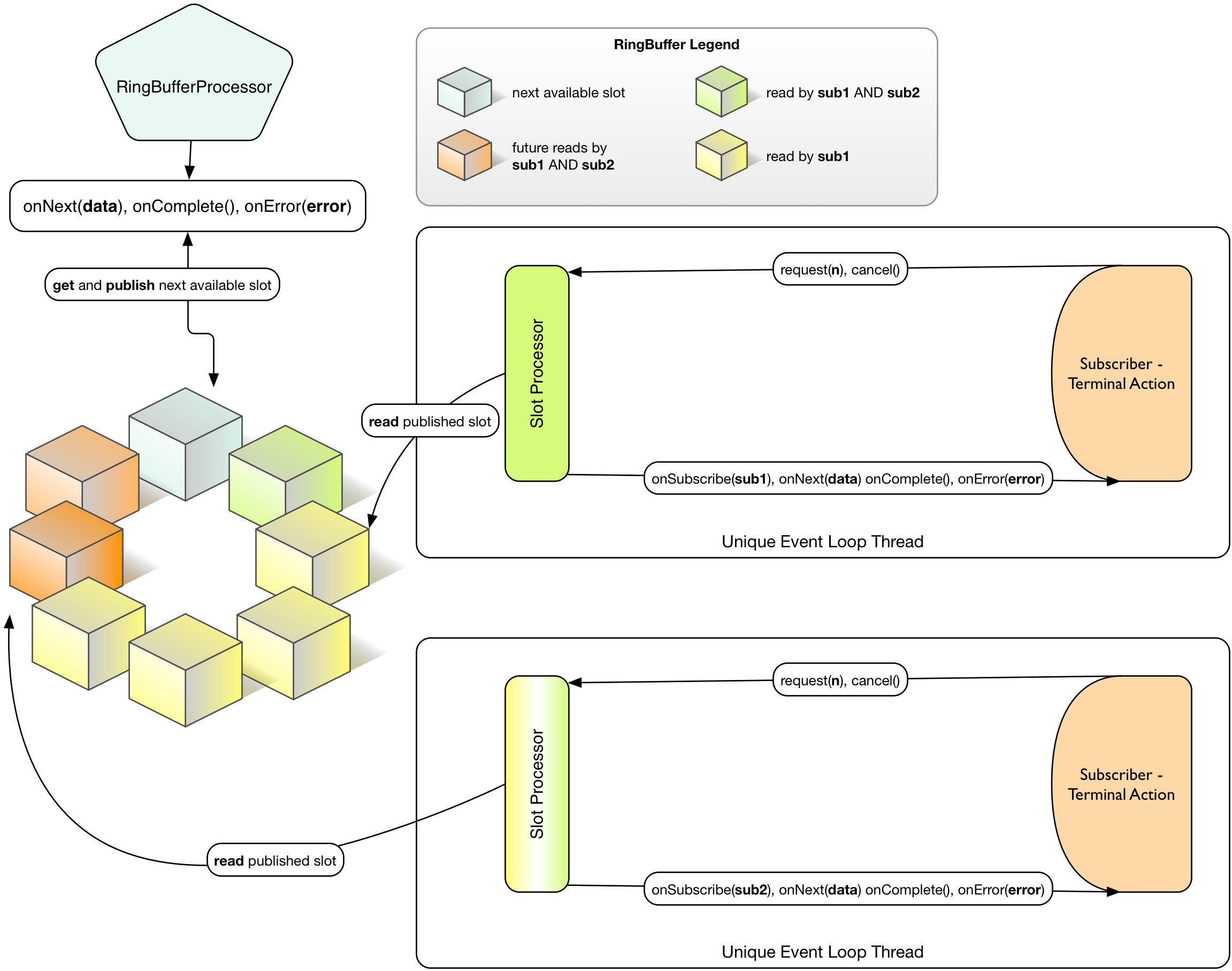
图 7. 给定时刻 T 带 2 个订阅者的环形缓冲区处理者。订阅者消费相同的序列,但在环形缓冲区满之前可以允许 delta 消费率存在。这在蓝方块与顺时针方向的下一个黄方块发生碰撞时会发生。
你需要用静态创建帮助者的方法来创建 环形缓冲区处理者。
Processor<Integer, Integer> p = RingBufferProcessor.create("test", 32); //*1
Stream<Integer> s = Streams.wrap(p); //*2
s.consume(i -> System.out.println(Thread.currentThread() + " data=" + i)); //*3
s.consume(i -> System.out.println(Thread.currentThread() + " data=" + i)); //*4
s.consume(i -> System.out.println(Thread.currentThread() + " data=" + i)); //*5
input.subscribe(p); //*6
- 创建带有 32 个槽容量的内部环形缓冲区的处理者。
- 从响应式数据流处理者创建 Reactor 数据流。
- 每个对消费的调用在其自身线程上创建一个 Disruptor。
- 每个对消费的调用在其自身线程上创建一个 Disruptor。
- 每个对消费的调用在其自身线程上创建一个 Disruptor。
- 将这个处理者订阅至一个响应式数据流发布者。
每个传递给处理者的 Subscribe.onNext(Buffer) 方法的数据元素都会被"广播"给所有消费者。在处理者没有循环指派,因为循环指派位于环形缓冲区工作处理者中,在下面会讨论这点。如果向处理者传递整数1,2,3,你在控制台看到的输入会像下面这样:
Thread[test-2,5,main] data=1
Thread[test-1,5,main] data=1
Thread[test-3,5,main] data=1
Thread[test-1,5,main] data=2
Thread[test-2,5,main] data=2
Thread[test-1,5,main] data=3
Thread[test-3,5,main] data=2
Thread[test-2,5,main] data=3
Thread[test-3,5,main] data=3
每个线程收到传递给处理者的所有值,因为内部使用环形缓冲区来管理发布值的可用槽,所以每个线程以有序的方式接收值。
! RingBufferProcessor 可以向任何潜在的订阅者重现因无订阅者而丢失的信号。如果满缓冲区未被订阅者耗尽,这会使处理者等待 onNext()。从 subsUp 接收的上一序列,到环形缓冲区的配置大小,都保持就绪以便为每个新的订阅者重现信号,即便事件已发出(分列)也是这样。
环形缓冲区工作处理者(RingBufferWorkProcessor)
与标准的环形缓冲区处理者向所有消费者广播数值的做法不同,环形缓冲区工作处理者根据消费者数量将传入的数值分区。进入处理者的数值以循环的方式被发送到各种线程(因为每个消费者都有自己的线程),同时这些数值通过适当地向生产者提供背压来使用内部环形缓冲区有效地管理数值的发布。
我们实现了环形缓冲区工作处理者来对各种 HTTP 微服务调用扩大规模和平衡负载。我说的也许不对,不过看起来它比光还快(!),而且垃圾回收压力完全得到控制。
— 开心的 Reactor 用户
环形缓冲区工作处理者用例
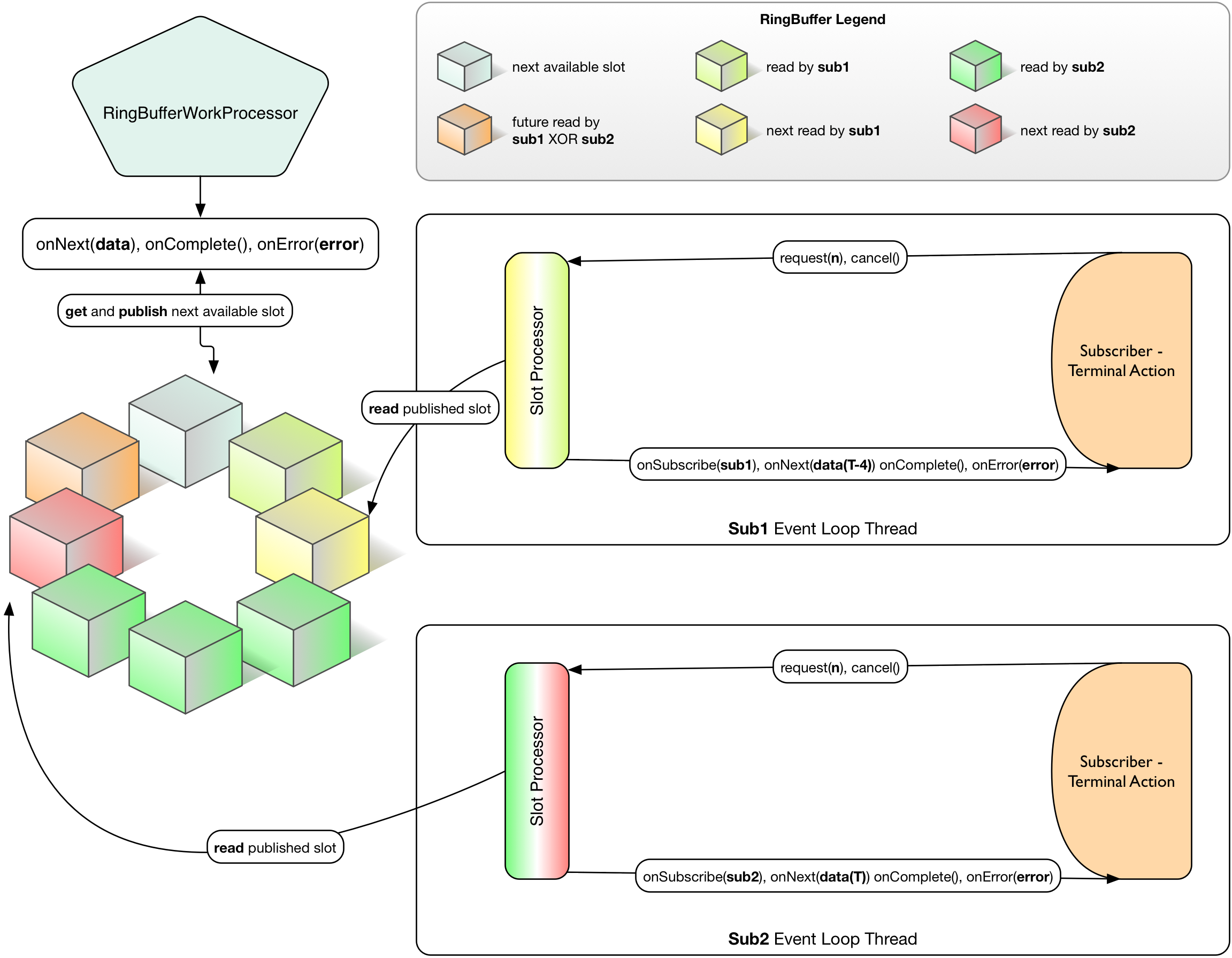
图 8. 在给定时刻 T 的 RingBufferWorkProcessor,带 2 个订阅者,消费各自独有的序列(可用 FIFO),但在环形缓冲区满之前可以允许 delta 消费率存在。这在蓝方块与顺时针方向的下一个黄方块发生碰撞时会发生。
要使用环形缓冲区工作处理者,上述例子中你唯一需要修改的是静态创建方法的引用,你需要在环形缓冲区工作处理者类自身上使用。其余代码都一致。
Processor<Integer, Integer> p = RingBufferWorkProcessor.create("test", 32); //*1
- 创建带有 32 槽容量的内部环形缓冲区处理者。 现在当值被发布到处理者时,并不会广播给每个消费者,而是根据消费者数量分区。现在当我们运行这个例子时,可以看到像下面这样的输出:
Thread[test-2,5,main] data=3
Thread[test-3,5,main] data=2
Thread[test-1,5,main] data=1
! RingBufferWorkProcessor 能够重现被中断的信号,从终止的订阅者那里检测 CancelException。当信号最终被其它订阅者实际播放时,这是唯一会出现的情况。我们可以保证任何事件都至少被交付一次。 如果你熟悉语义的话,你可能会说 "嗯~,这个环形缓冲区工作处理者用起来像 Message Broker?",的确是这样。
编解码器与缓冲区
字节操作是许多数据管线配置中用到的核心概念。从 reactor-net 到通过 IO 接收发送编组和解组字节中都得到广泛运用。
reactor.io.buffer.Buffer 是 Java ByteBuffer 操作的修饰符,提供了一系列操作,目的是通过调整字节缓冲区大小以及读取或覆盖预分配字节来最小化字节拷贝。在字节缓冲区中追踪定位可以让开发者快速进入脑痛期,至少对我们是这样。因而我们决定向我们的用户推荐这个小工具。
Groovy Spock 测试中简单的缓冲区操作代码如下所示:
import reactor.io.buffer.Buffer
//...
given: "an empty Buffer and a full Buffer"
def buff = new Buffer()
def fullBuff = Buffer.wrap("Hello World!")
when: "a Buffer is appended"
buff.append(fullBuff)
then: "the Buffer was added"
buff.position() == 12
buff.flip().asString() == "Hello World!"
一个有效的缓存应用是 Buffer.View ,它可由像 split() 这样的多路操作返回。它以免拷贝的方式来描述和内观字节缓冲区中的字节。Buffer.View 也是一种缓冲区,开放了相同的操作。
使用定界符和 Buffer.View 重用相同的字节来分块读取:
byte delimiter = (byte) ';';
byte innerDelimiter = (byte) ',';
Buffer buffer = Buffer.wrap("a;b-1,b-2;c;d;");
List<Buffer.View> views = buffer.split(delimiter);
int viewCount = views.size();
Assert.isTrue(viewCount == 4);
for (Buffer.View view : views) {
System.out.println(view.get().asString()); //prints "a" then "b-1,b-2", then "c" and finally "d"
if(view.indexOf(innerDelimiter) != -1){
for(Buffer.View innerView : view.get().split(innerDelimiter)){
System.out.println(innerView.get().asString()); //prints "b-1" and "b-2"
}
}
}
对通常的编组/解组用例而言调整缓冲区有点低层次的感觉。Reactor 带有一系列的预定义转换器,叫做 Codec。一些 Codec 需要类路径中的适当额外依赖,如 JSON 操作需要 Jackson。
Codec 有两种工作方式,第一种方式中它实现了将任意内容直接编码并返回已编码数据的函数,通常以缓冲的形式完成。这种很棒的方式只适用于无状态编码。另一种是使用 Codec.encoder() 返回的编码函数。
Codec.encoder() vs Codec.apply(Source)
- Codec.encoder() 返回唯一编码函数,在不同线程间不能共享
- Codec.apply() 直接编码(保存分配的编码器),在此情况下 Codec 需要在线程间共享。
♠ Reactor Net 实际上为每个新的连接都调用了 Codec.encoder 来处理这种区别。
Codec 也能从源类型解码数据,在大多数 Codec 实现上通常解码至缓冲区。要解码源数据,我们要从 Codec.decoder() 检索解码函数。与编码过程不同,解码没有像编码那样已经为编码目的而重载的便捷方法。与编码过程相同的是,解码函数在不同线程间不应共享。
Codec.decoder() 函数有两种形式,一种是直接返回解码数据,另一种 Codec.decoder(Consumer) 为每个解码事件调用已传递消费者。
Codec.decoder() vs Codec.decoder(Consumer)
Codec.decoder() 是阻塞式解码函数,直接在传入源码数据中返回解码数据。
Codec.decoder(Consumer) 可用于非阻塞解码,它返回 null,仅在解码后调用已传递消费者,可与任意异步方式结合。
Groovy Spock 测试 中使用预定义编/解码器示例代码:
import reactor.io.json.JsonCodec
//...
given: 'A JSON codec'
def codec = new JsonCodec<Map<String, Object>, Object>(Map);
def latch = new CountDownLatch(1)
when: 'The decoder is passed some JSON'
Map<String, Object> decoded;
def callbackDecoder = codec.decoder{
decoded = it
latch.countDown()
}
def blockingDecoder = codec.decoder()
// 这个异步策略太简单,不过先不用管它 :)
Thread.start{
callbackDecoder.apply(Buffer.wrap("{\"a\": \"alpha\"}"))
}
def decodedMap = blockingDecoder.apply(Buffer.wrap("{\"a\": \"beta\"}")
then: 'The decoded maps have the expected entries'
latch.await()
decoded.size() == 1
decoded['a'] == 'alpha'
decodedMap['a'] == 'beta'
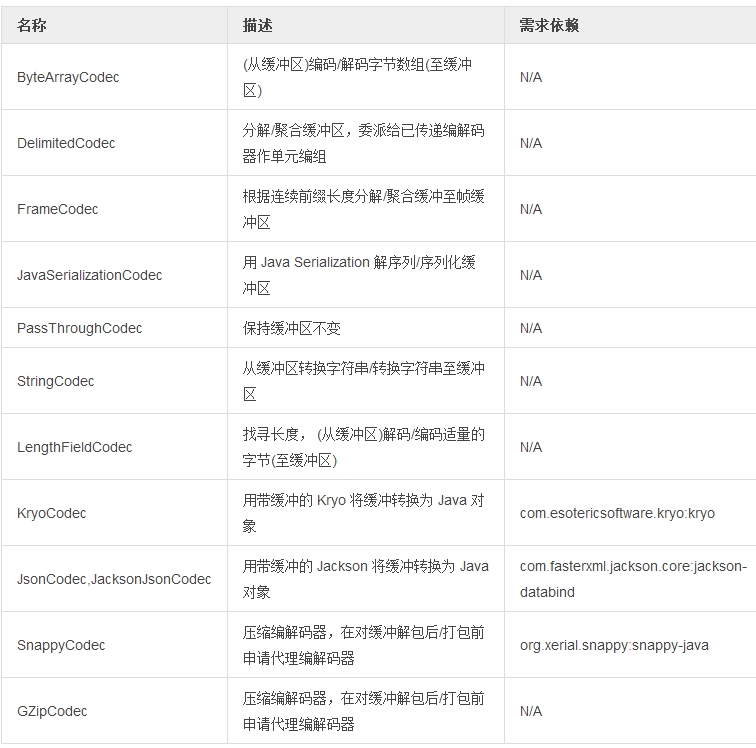
表 4. 可用的核心编解码器:
3
reactor-数据流
注意,你应该再也别去使用 Future.get() 了。
— Stephane Maldini
与一个银行业的客户
首先来看看一个 Java 8 示例中流 (Stream) 的运作方式
import static reactor.Environment.*;
import reactor.rx.Streams;
import reactor.rx.BiStreams;
//...
Environment.initialize()
//找到一个 String 列表中开头的 10 个词
Streams.from(aListOfString)
.dispatchOn(sharedDispatcher())
.flatMap(sentence ->
Streams
.from(sentence.split(" "))
.dispatchOn(cachedDispatcher())
.filter(word -> !word.trim().isEmpty())
.observe(word -> doSomething(word))
)
.map(word -> Tuple.of(word, 1))
.window(1, TimeUnit.SECONDS)
.flatMap(words ->
BiStreams.reduceByKey(words, (prev, next) -> prev + next)
.sort((wordWithCountA, wordWithCountB) -> -wordWithCountA.t2.compareTo(wordWithCountB.t2))
.take(10)
.finallyDo(event -> LOG.info("---- window complete! ----"))
)
.consume(
wordWithCount -> LOG.info(wordWithCount.t1 + ": " + wordWithCount.t2),
error -> LOG.error("", error)
);
使用 Stream 和 Promise(约定) 协调任务
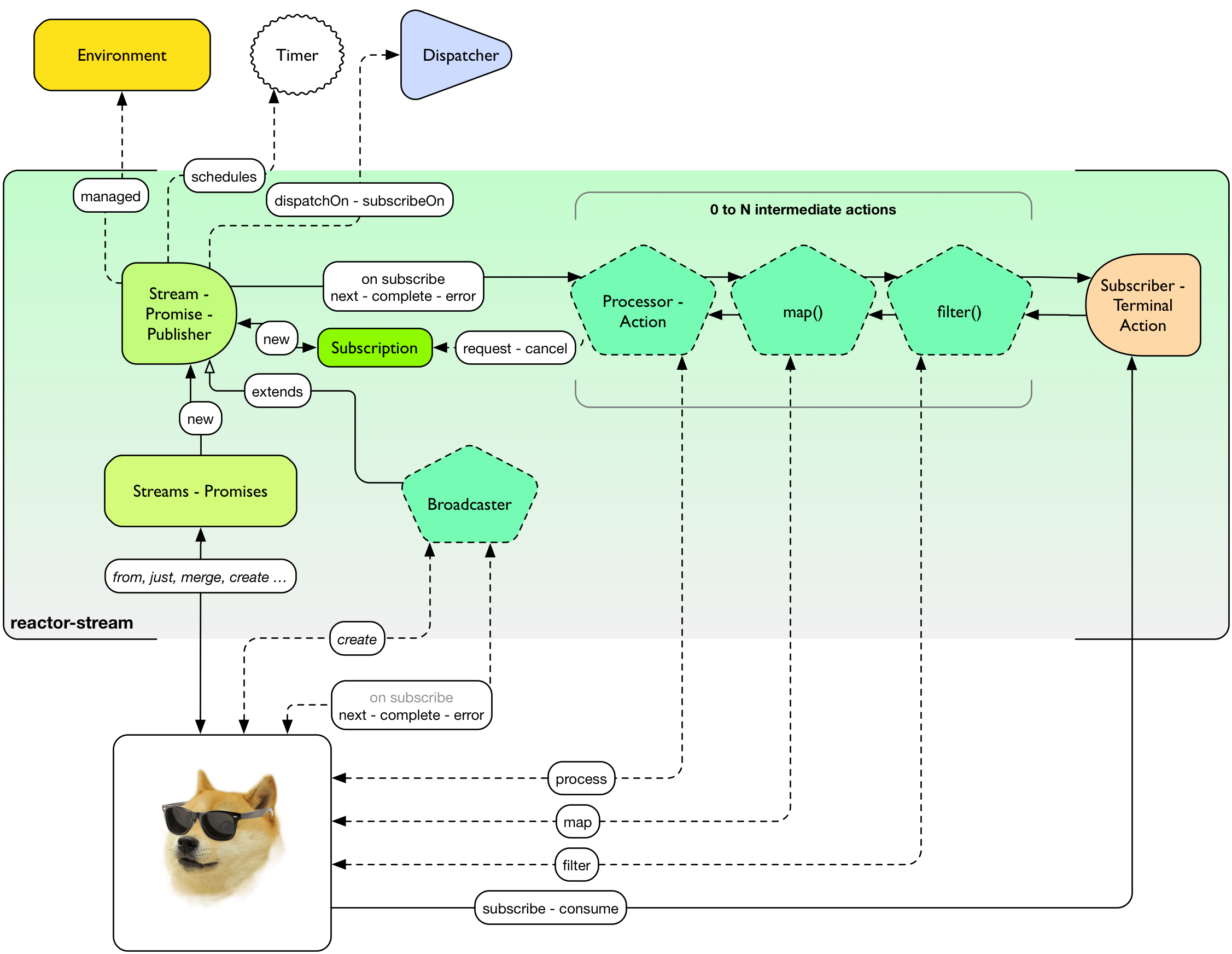
图 9. 程序员狗如何使用 Reactor-Stream
Reactor Streams 拥有下面这些功能部件:
- Stream 及其直接实现。
- 包含 reactive extensions 和其它一些 API 组件。
- 带有一套特殊 A+ 风格 API 的 Promise。
- 可以使用 Promise.stream() 再转换回到 Stream。
- 静态工厂,可以一站式的创建出相关的组件。
- Streams 用来从定义良好的数据源(Iterable, 什么都没有的对象, Future, Publisher…)创建出 Stream 。
- BiStreams 用于处理键值对型 Stream Stream (reduceByKey…)。
- IOStreams 用于对Streams 进行 持久化(Persisting) 和 解码(Decoding)。
- Promises 用于单一数据的 Promise。
- 由Stream提供的Action 及其每一个操作的直接实现都遵循响应式数据流处理器(Reactive Streams Processor)的规范。
- 并不直接创建,而是使用 Stream 的 API (Stream.map() → MapAction, Stream.filter() → FilterAction…)。
- Broadcaster, 一个为了实现动态数据分配而暴露 onXXXX
接口的明确的 Action
。- 不像 Core Processors, 如果没有订阅者访问,它们一般不会去接触缓存数据。
- 不过 BehaviorBroadcaster 会向新的订阅者 (Subscriber) 回放最近一次的信号。 >不要把 reactor.rx.Stream 同 JDK 8 中新的 java.util.stream.Stream 混淆了. 后者不提供一个基于 API 的 Reactive Streams ,也没有 Reactive Extensions。不过,当用于原生类型和集合时,JDK 8 的 Stream API 还是相当完备的。 事实上对于能使用 JDK 8 的应用程序而言将 JDK 的支持和 Reactive Streams 混在一起用相当有趣。
Streams 的基础知识
Reactor 提供了基于 Reactive Streams 标准的 Stream 或者 Promise 来组成静态类型的数据管道。
它是一个非常实用且灵活的组件。它在被用于像 RxJava 的 Observable 那样仅仅只对异步操作进行组合时是足够灵活的。而它也足够强大,可以像一个异步工作队列那样运行,取出或者加入任意的组件,或者来自于其它标准实现之一的 Reactive Streams 组件。[3]。
粗略来分有两类基础的流
- 一个是热 Stream ,它是没有界限的,像一个接收器那样接受输入数据。
- 可以回想一下诸如鼠标点击的UI事件,或者诸如传感器的实时反馈,交易位置或者推特(Twitter)。
- 适用于使用 Reactive Streams 协议的适配了的背压策略。
- 还有一个冷 Stream 则是有界限的,其创建一般是来自于固定的数据集合,像 List 或者或者 Iterable 对象。
- 可以回想一下诸如 IO 读取,数据库查询这样的 游标型读取操作(Cursored Read) ,
- 适用于自动的 Reactive Streams 背压策略。 >如我们之前所看到的, Reactor 使用一个 Environment 实体来持有 Dispatcher 实体,用于在一个给定的 JVM(和类装载器)中进行共享使用。一个 Environment 实体可以在一个应用程序中被创建出来并在各处进行传递,以避免类装载各自隔离的问题,或者其静态的辅助方法也可以被使用到。这个站点上的所有示例中,我们都将使用到静态其辅助方法,也鼓励你这样做。 为此,你需要在应用程序的某个地方初始化静态的 Environment。
``` static { Environment.initialize(); }
有赖于信号回调,Reactive Streams
和
Reactive Extensions
通常目标就是不干预线程行为。 Stream 整个就只关心
它将会在某个从现在到某个时间 T 之间执行
。 非并行的信号可能也会禁止
Subscriber
的无共享(share-nothing)并发访问, 不过信号和请求可以在两个非对称的线程上运行。
Stream
默认被分配了一个
SynchronousDispatcher
并将通过
Stream.getDispatcher()
来通知它当前的子
Actions
。
>各种
Stream
工厂、
Broadcaster
、
Stream.dispatchOn
还有终端的
xxxOn
方法可能会变更默认的
SynchronousDispatcher
。
>
理解 Reactor Stream 中三个可用的主要线程开发是很重要的
:
>-
Stream.dispatchOn
是
Stream
下唯一能在给定的
Dispatcher
上派发
onError、onComplete
和
onNext
信号的动作(action)。
- 如果其上下文中已经就绪,
request
和
cancel
也将会运行在调配器上面。否则它将会在当前的派发结束时执行。
-
Stream.subscribeOn
动作只会在传入的调配器上执行
onSubscribe
。
- 由于传入的
Dispatcher
被调用的唯一时机是
onSubscribe
, 任何的调配器,包括诸如 WorkQueueDispatcher 这样并发的都可以被使用。
- 第一个
request
可能仍在
onSubscribe
线程中执行,例如使用
Stream.consume()
动作。
- 通过
Stream.process
附上一个处理器(Processor),例如也可以影响到线程。诸如
Processor
这样的线程可以在其管辖的线程上运行
Subscriber
-
request 和 cancel
将会运行在处理器上,如果其上下文已经准备就绪也是这样。
-
RingBufferWorkProcessor
将只会将
onNext
信号分派到一个
Subscriber
,最多除非是它已经取消了正在进行的处理 (向一个新的
Subscriber
进行回放)。
最常用来开请求数据的
onSubscribe, subscribeOn
是一类高效的用来扩大数据流的工具,特别是那些没有的边界的。 如果一个
Subscriber
在
onSubscribe
中请求
Long.MAX_VALUE
,然后它将会成为唯一要执行的请求,并且会运行于
subscribeOn
中分配的调度器上。这是针对无边界的
Stream.consume
动作的默认行为。
无界需求在线程间的跳动
Streams .range(1, 100) .dispatchOn(Environment.sharedDispatcher()) //2 .subscribeOn(Environment.workDispatcher()) //1 .consume(); //3
1. 分配一个 onSubscribe 工作队列调配器。
2. 分配一个信号
onNext、onError、onComplete
调配器。
3. 使用 Subscription.request(Long.MAX) 来处理 Stream 的
onSubscribe
。
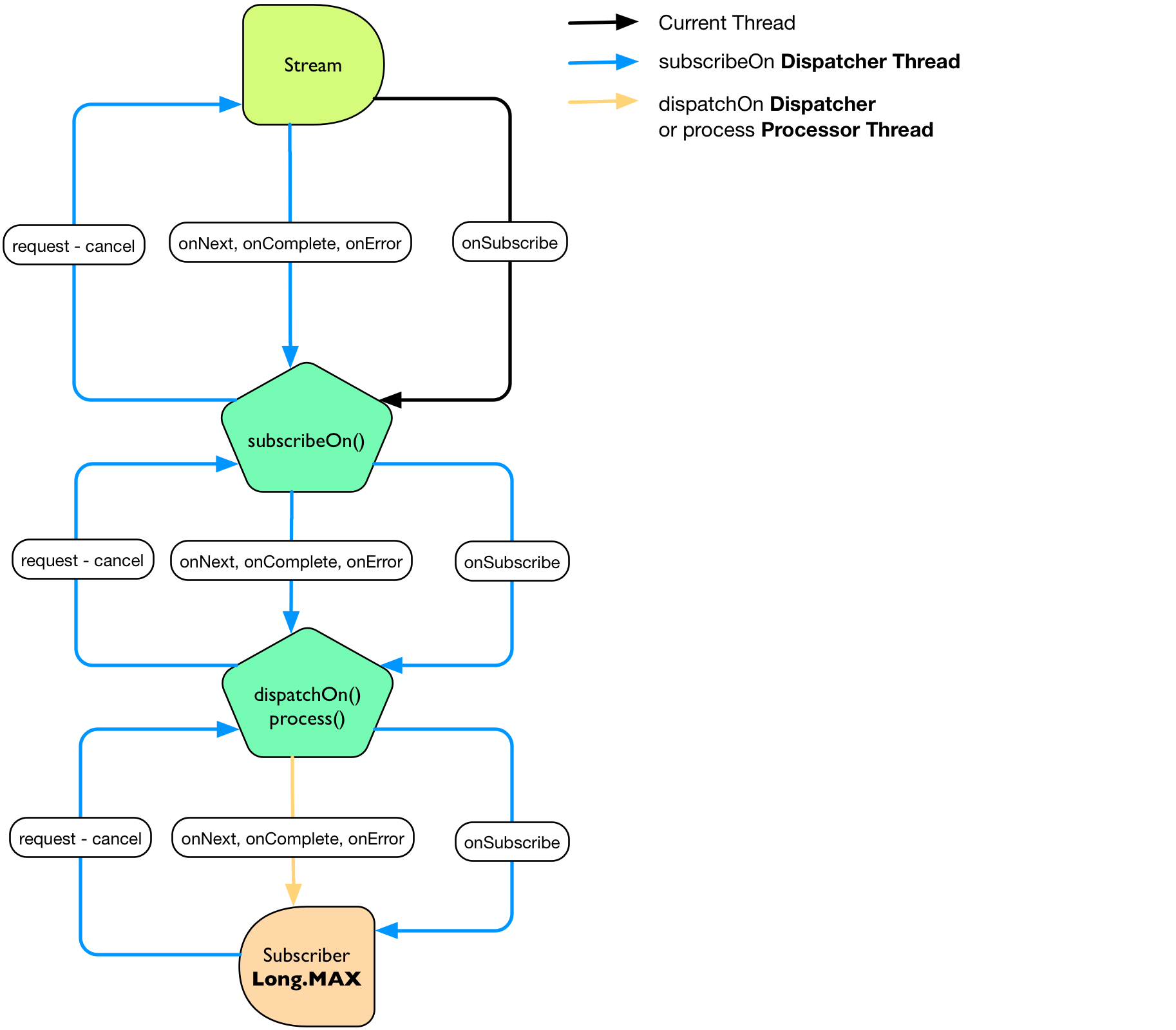
图 12,用无边界的 Subscriber 来 subscribeOn 和 dispatchOn/process
不过,在涉及到超过 1 个请求的时候,
subscribeOn
就很少有用了, 就像使用
Stream.capacity(n)
按步骤处理一样。唯一的请求执行可能运行于在
subscribeOn
中分配的第一个调度器之上。
有界需求 1 在线程间的跳动
Streams .range(1, 100) .process(RingBufferProcessor.create()) //2 .subscribeOn(Environment.workDispatcher()) //1 .capacity(1); //3 .consume(); //4
1. 分配一个
onSubscribe
工作队列调配器。要注意它是被放置在了 处理(process) 之后, 因为 subscribeOn 将会运行订阅器的 上的 ringBuffer 现成之上,而我们想将其变更为工作调配器。
2. 分配一个异步信号
onNext, onError, onComplete
处理器。类似于 dispatchOn 的行为。
3. 将 Stream 的容量指定为 1,得以让下行流动作可以适配。
4. 使用 Subscription.request(1) 处理 Stream 的
onSubscribe
,并且是在每次的
onNext
之后。
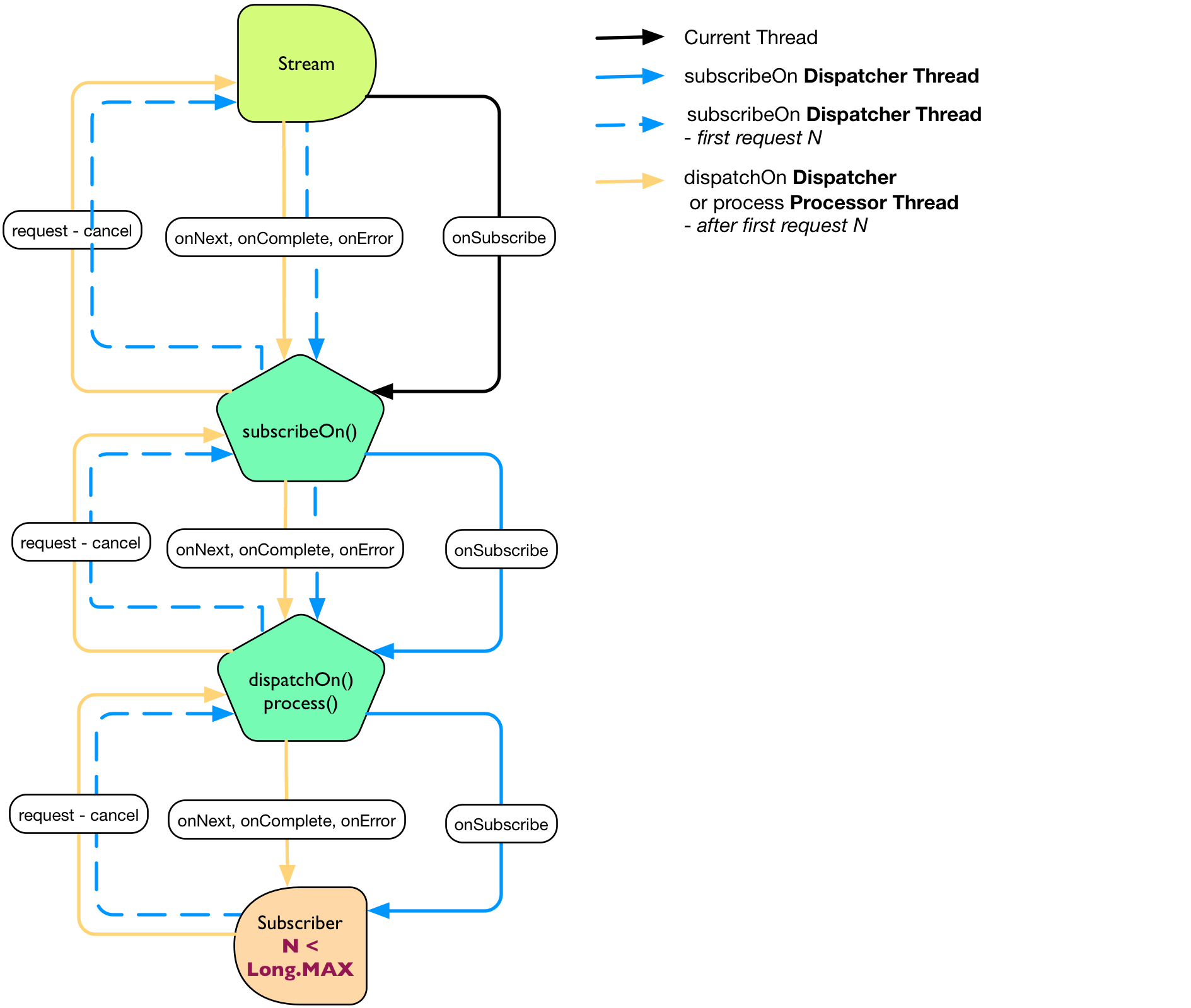
图 13,使用一个带有边界(也就是要求 N < Long.MAX)的 Subscriber 的subscribeOn 和 dispatchOn/process 方法
多数情况下,依照
Reactor Stream
的协定,背压可以被自动处理。如果
订阅者(Subscriber)
请求的数据并没有超过其处理能力(例如类似
Long.MAX_VALUE
的东西),数据源上游可以避免发送过多数据。如果你想在使用一个 “冷”的
发布者(Publisher)
时享受这种便利,你必须可以在任何时候关闭数据源的读取操作:从 socket 中读取多少、SQL 查询指针中有多少行、文件中有多少行、迭代构造体中有多少元素……
如果是
热
数据源
,
例如定时器或 UI 事件,或是一个可能从大型数据集上请求 Long.Max_VALUE 大小数据的订阅者(Subscriber),开发者必须针
对背压
制定明确的策略。
>
Reactor 提供了一系列处理冷热序列的 API**
>- 非控(热)序列应当主动管理。
- 减少 序列的信号量,例如“取样”。
- 当需求超过容量时,忽略 数据。
- 当需求超过容量时,缓冲 数据。
- 受控(冷)序列应当被动管理。
- 通过降低来自订阅者(Subscriber)或 Stream 上任意点的需求。
- 通过延迟请求断歇需求。
Reactor 扩展
文档中应用最广泛的示例就是
Marble Diagram
,双时间线帮助我们更直观的了解发布者(Publisher)、Stream以及订阅者(Subscriber) (如Action)在何时被观察,观察的内容又是什么。我们将使用这些图表来强调需求流,表明例如 Map 和 filter 这样的变换的本质。
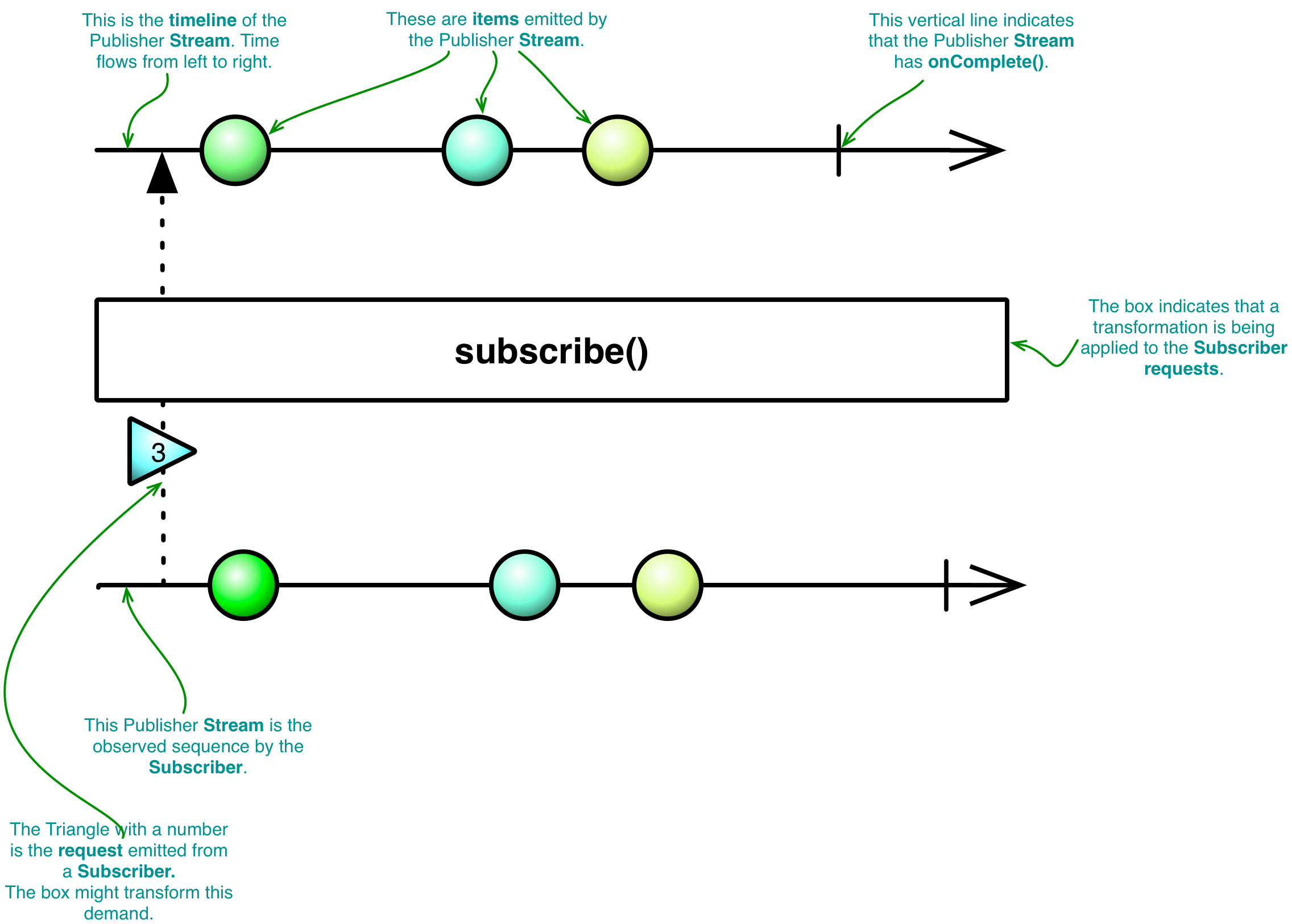
当两个 Action 的调度器或容量不同时,
Reactor
将自动提供一个内存溢出缓冲区。这不适用于核心处理器,它有自己的溢出处理机制。调度器可以重复使用,且
Reactor
必须限制调度器的数量,因此 Action 的调度器不同时,将添加内存缓冲区。
Streams.just(1,2,3,4,5) .buffer(3) //1 //onOverflowBuffer() .capacity(2) //2 .consume()
Streams.just(1,2,3,4,5) .dispatchOn(dispatcher1) //3 //onOverflowBuffer() .dispatchOn(dispatcher2) //4 .consume()
1. buffer 操作设定容量为 3。
2. consume() 或任何下游动作都被设定为 capacity(2),隐式的添加了一个 onOverflowBuffer()。
3. 在调度器 1 上执行第一个动作。
4. 在调度器 2 上执行第二个动作,隐式的添加了一个 onOverflowBuffer()。
最终
Subscriber
可以逐一的请求数据,限制管道中传输的数据为一个元素,并在每次成功调用
onNext(T)
后请求下一个元素。这种行为也可以通过
capacity(1).consume(...)
获得。
Streams.range(1,1000000) .subscribe(new DefaultSubscriber(){ Subscription sub;
@Override
void onSubscribe(Subscription sub){
this.sub = sub;
sub.request(1);
}
@Override
void onNext(Long n){
httpClient.get("localhost/"+n).onSuccess(rep -> sub.request(1));
}
);
1. 使用
DefaultSubscriber
以避免逐个实现订阅者的所有方法。
2. 持有订阅的指针后安排第一次需求请求。
3. 在成功的
GET
请求后,使用
异步 HTTP API
再次请求。延迟信息自然将被传递给
RangeStreamPublisher
。你可以想到,通过计算两次请求的时间间隔,我们将能够深入的了解执行过程及 IO 操作所产生的延迟。
表 12,控制传递数据的信号量
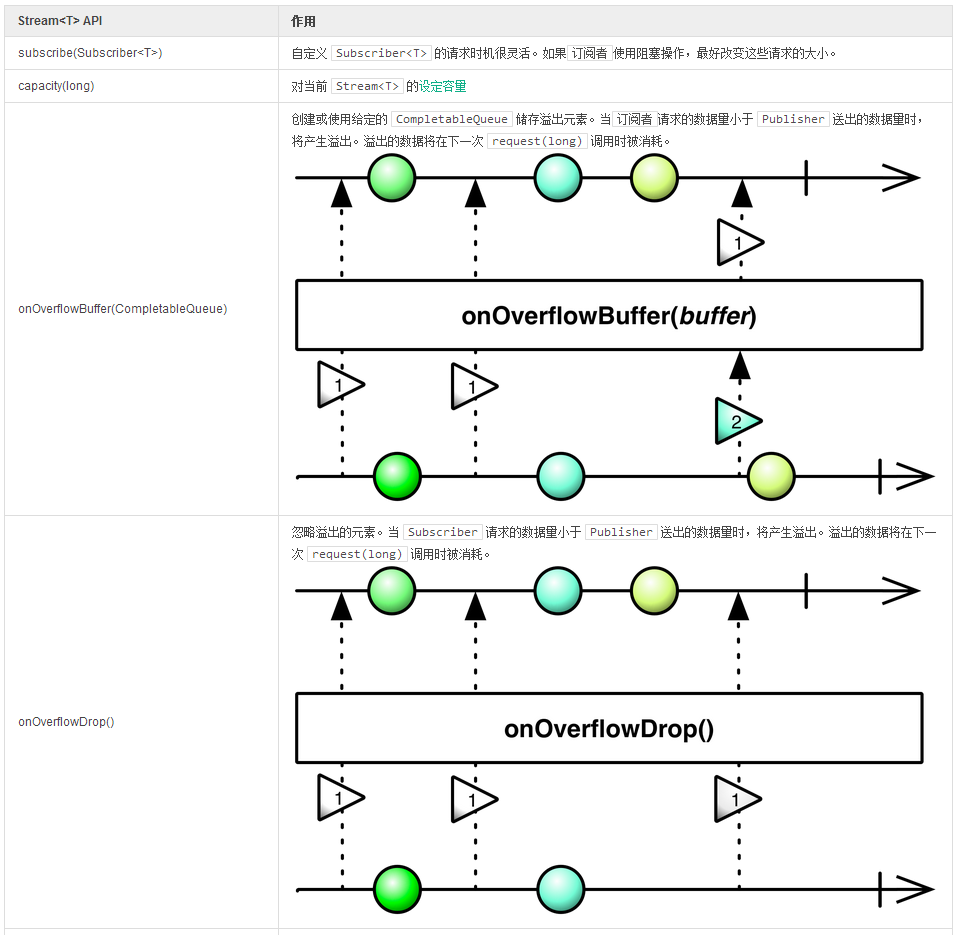
为了协调数据的
并行序列
,我们可以组合
发布者
。由于生成序列是合并的结果,它们也可以用于数据的[异步转换]异步转换。
通过非阻塞的协调方式可以避免开发者使用
Future.get() 或 Promise.await()
,这两个方法在多信号存在是容易引发问题。非阻塞意味着管道除了
订阅者
的需求,不会做任何等待。订阅者的请求将被切分至最小,然后分配给已经组合的
发布者
。
合并行为在
FanInAction
中建模,并通过一个订阅者委托的
线程偷取型
SerializedSubscriber
代理处理并行信号。它将对校验每个信号,查看对应的委托订阅者是否已经运行,如果没有运行,则重新分配信号。当繁忙的线程关闭订阅者代码时,信号将被轮询,处理信号的线程很可能已经不再是生产它的那个了。
>在使用
flatMap
之间就
削减需求信号量
没法说是好主意还是坏主意。实际上,如果无法处理所有的数据,是没有必要订阅多个并行发布者并合并操作的。然而它对并行
发布者
数据量的限制,也不会给予高速
发布者
挂起请求的机会。
Stream.zipWith(Function)
Streams .range(1, 100) .zipWith( Streams.generate(System::currentTimeMillis), tuple -> tuple ) //1 .consume( tuple -> System.out.println("number: "+tuple.getT1()+" time: "+tuple.getT2()) , //2 Throwable::printStackTrace, avoid -> System.out.println("--complete--") );
1. “Zip” 或聚合来自
RangeStream
的最新的信号,传递
SupplierStream
以提供当前时间。
2. 通过 “Zip” 操作,压缩
发布者
按照声明的顺序(自左及右,
stream1.zipWith(stream2)
)生成数据元组。
表13,组合数据源

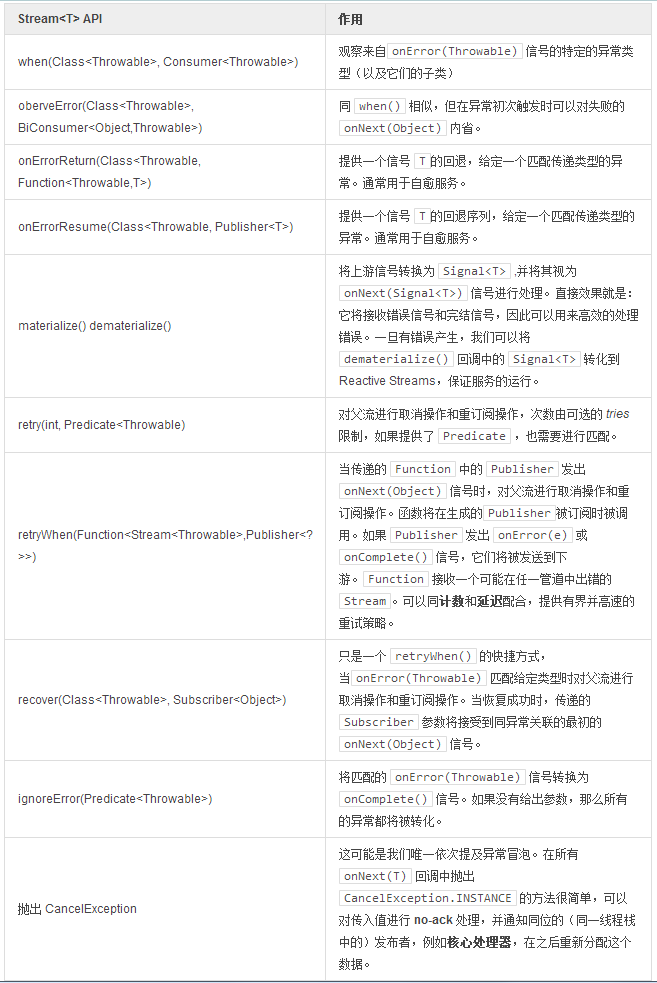
由于错误隔离是 Reactive 协定中一个很重要的部分,
Stream
API 已经实现了容错管道和相关的服务调用。
错误隔离可以防止
onNext、onSubscribe
和
onComplete
回调函数弹出任何异常。作为替代,这些异常被传递给
onError
回调函数,并传播给下游。一些
Action
可以积极或消极的对待这些信号,类如
when()
仅仅观察错误,而
onErrorResumeNext()
则可以切换至备用发布者。
>将传播过程逆向至消费侧而非生产侧是将数据生产者同管道错误隔离,保证生产者快活力的一种响应式的模式。
最后,错误将通过
onError()
回调函数通知给链中的最后一个订阅者。假设 订阅者 是一个
ConsumerActon
,如果没有一个通过
Stream.consume(dataConsumer, errorConsumer)
注册的
errorConsumer
回调函数存在,
Reactor
将重新路由错误信号。路由将触发当前环境的错误日志(如果有设定),默认使用 SLF4J 记录错误。
>Reactor 对
致命异常
的处理也不同常规,特别是在
onSubscribe
执行过程中。这些异常将不被孤立,且不会传递给下游 subscriber(s):
>- CancelException
- 如果
onNext
信号传播时没有可用的订阅者,此异常将被触发,例如在
onNext
信号传输时,订阅者被异步的取消了。
- 使用 JVM 属性 -Dreactor.trace.cancel=true 可以开启 CancelException 的详细模式,并将其记录在默认的环境日志中。如果不设置,环境日志中不会记录异常以及相关的错误堆栈。
- ReactorFatalException
- 此异常在 Reactor 遇到不可恢复的情况时触发,例如在
Timer
的调配不能匹配条件时。
- JVM unsafe exceptions:
- StackOverflowError
- VirtualMachineError
- ThreadDeath
- LinkageError
很多章节中都可以看到明确设定时间限制的好习惯,
timeout() + retry()
将是你对付网络分裂问题的最好伴侣。流向
Stream
的数据越多,它就越应具有自愈性和良好的服务可用性。
>理论上,在Reactive Streams中最多有一个错误能够穿过通道,因此你实不必在一个订阅者 上两次重复 onError(e)。而实践中,我们实现 Rx 的 retry() 和 retryWhen() 操作符将在 onError 时进行取消和重订阅操作。就是说,在新的通道,带着新的操作示例,被同名的物化时,我们依然遵循着协定。这也意味着在这种情形下,像 buffer() 这样状态化的 Action 应当谨慎使用,因为我们只是取消了对它们的引用,它们的状态可能会丢失。我们正在研究替代方案,一个想法就是为安全的状态化 Action 引入外部持久化。你可以在
相关章节
窥见一斑。
回退流很有趣
良好的串联回滚
Broadcaster broadcaster = Broadcaster.create();
Promise<List> promise = broadcaster .timeout(1, TimeUnit.SECONDS, Streams.fail(new Exception("another one!"))) .onErrorResumeNext(Streams.just("Alternative Message")) .toList();
broadcaster.onNext("test1"); broadcaster.onNext("test2"); Thread.sleep(1500);
try { broadcaster.onNext("test3"); } catch (CancelException ce) { //Broadcaster has no subscriber, timeout disconnected the pipeline }
promise.await();
assertEquals(promise.get().get(0), "test1"); assertEquals(promise.get().get(1), "test2"); assertEquals(promise.get().get(2), "Alternative Message");
1. 当给定的时间段内没有数据发出时,
TimeoutAction
可以提供回滚,但这个示例中它仅仅发出了另一个异常……
2. ……不过,我们很幸运有可以捕捉此异常的
onErrorResumeNext(Publisher)
,它传递了一些有效的字符串负荷。
另一个经典的管道容错示例在
手册
一节
表 18,错误处理
并不是所有的数据都要待在内存里,
Reactor
已经开始整合(可选依赖)
Java Chronicle
。
return Streams.merge( userService.filteredFind("Rick"), userService.filteredFind("Morty") ) .buffer() .retryWhen( errors -> errors .zipWith(Streams.range(1,3), t -> t.getT2()) .flatMap( tries -> Streams.timer(tries) ) ) .consume(System.out::println);
表 15,安全的持久化信号
度量操作和其它状态化操作一样,都是
Stream
API 的一部分。实际上,熟悉
Spark
的用户能够认出一些方法。
ScanAction
也提供了一些常用的同
reduce()
和
scan()
相关的累积功能。
使用键/值型数据和度量操作
Broadcaster source = Broadcaster. create(Environment.get()); long avgTime = 50l;
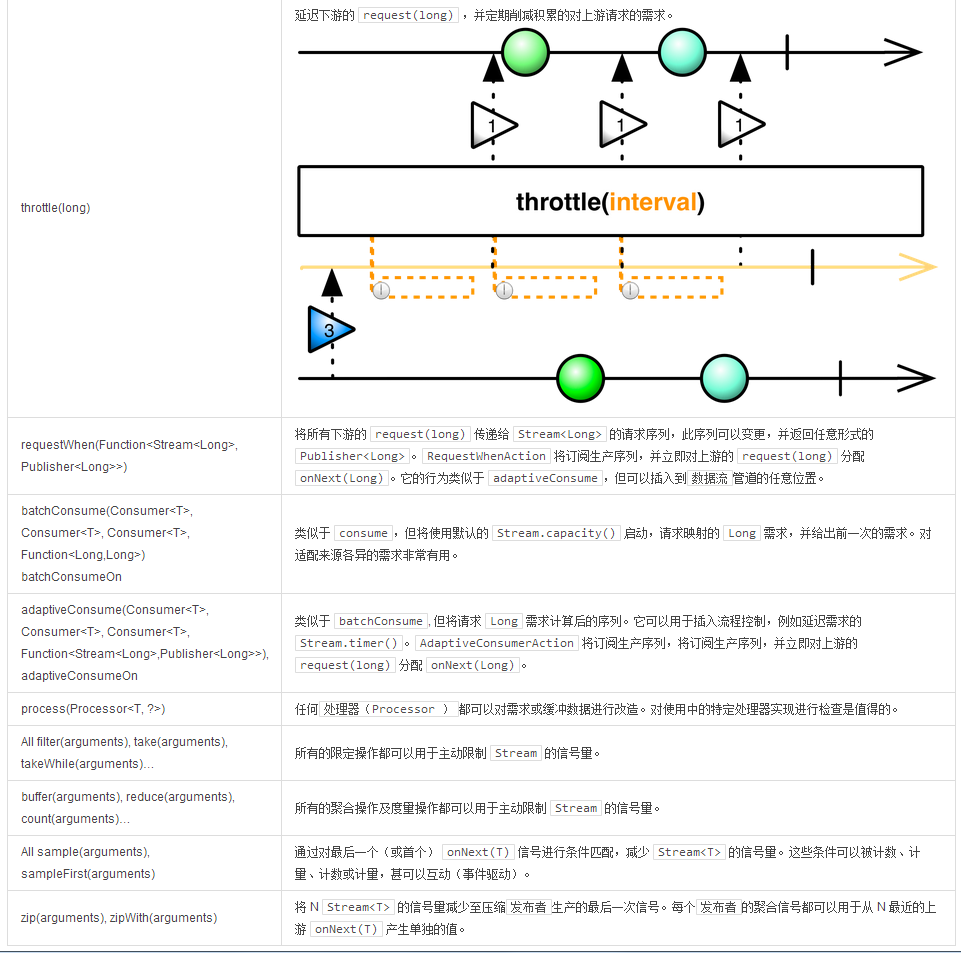
Promise result = source .throttle(avgTime) (1) .elapsed() (2) .nest() (3) .flatMap(self -> BiStreams.reduceByKey(self, (prev, next) -> prev + 1) (4) ) .sort((a,b) -> a.t1.compareTo(b.t1)) (5) .log("elapsed") .reduce(-1L, (acc, next) -> acc > 0l ? ((next.t1 + acc) / 2) : next.t1 (6) ) .next(); (7)
for (int i = 0; i < 10; i++) { source.onNext(1); } source.onComplete();
1. 将传入的订阅者(
Publisher
)减速至每 50 毫秒一次,逐个等待数据发出。
2. 在
onSubscribe
和 第一个信号之间,或是在两个信号之间产生一个拥有
时间增量
和
有效载荷
的
Tuple2
。
3. 使当前流可以接收
onNext
信号,以便我们将其同
flatMap
组合。
4. 累积所有数据,直到以
Tuple2.t1
和
Tuple2.t2
为键值对的内部
Map
发出
onComplete()
信号。下一个匹配的主键将为累加器
BiFunction
提供前一次的值和新发出的
onNext
信号。这样我们就可以每个键增加一个有效载荷。
5. 累积所有数据,直到内部
PriorityQueue
发出
onComplete()
信号,并使用给定比较器对流逝的时间 t1 进行排序。在
onComplete()
之后,所有的数据都会按顺序发出,然后就完成了。
6. 累积所有数据,直到
onComplete()
信号的平均传送时间为默认的首次被接收的时间。
7. 发出下一个信号,并且只计算平均值。
输出
03:14:42.013 [main] INFO elapsed - subscribe: ScanAction 03:14:42.021 [main] INFO elapsed - onSubscribe: {push} 03:14:42.022 [main] INFO elapsed - request: 9223372036854775807 03:14:42.517 [hash-wheel-timer-run-3] INFO elapsed - onNext: 44,1 03:14:42.518 [hash-wheel-timer-run-3] INFO elapsed - onNext: 48,1 03:14:42.518 [hash-wheel-timer-run-3] INFO elapsed - onNext: 49,2 03:14:42.518 [hash-wheel-timer-run-3] INFO elapsed - onNext: 50,3 03:14:42.518 [hash-wheel-timer-run-3] INFO elapsed - onNext: 51,3 03:14:42.519 [hash-wheel-timer-run-3] INFO elapsed - complete: SortAction 03:14:42.520 [hash-wheel-timer-run-3] INFO elapsed - cancel: SortAction
表 20,度量操作和其它状态化累积操作可用的操作
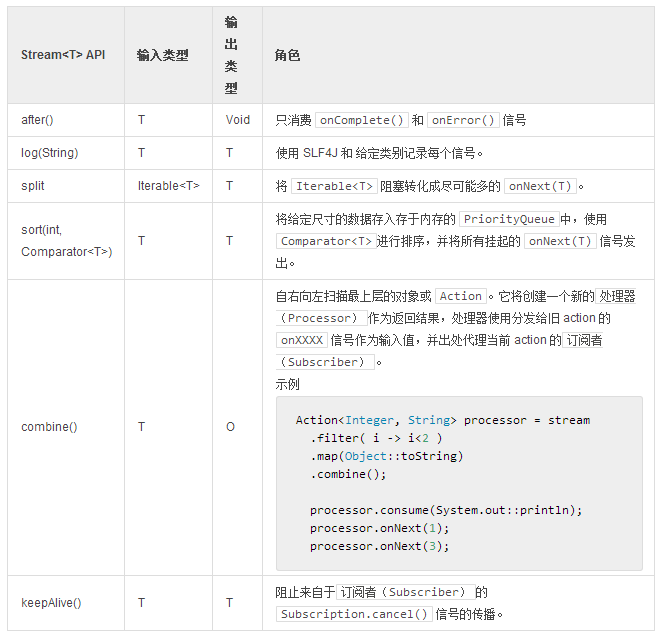
分区(Partition)是一种针对并行、并发作业的
Stream
。
以响应式编程的方式编写的功能组件,有一个重要的方面就是它的工作可以审慎的切块,交由任意调度器完成。这意味着你可以很轻松的将输入值组合冲一个工作流——在另一个线程执行操作,然后当结果可用时将其交给子序列,完成转化。这是 Reactor 很常见的使用模式。
DispatcherSupplier supplier1 = Environment.newCachedDispatchers(2, "groupByPool"); DispatcherSupplier supplier2 = Environment.newCachedDispatchers(5, "partitionPool");
Streams .range(1, 10) .groupBy(n -> n % 2 == 0) //1 .flatMap(stream -> stream .dispatchOn(supplier1.get()) //2 .log("groupBy") ) .partition(5) //3 .flatMap(stream -> stream .dispatchOn(supplier2.get()) //4 .log("partition") ) .dispatchOn(Environment.sharedDispatcher()) //5 .log("join") .consume();
1. 创建至多两个(奇/偶)数据流,以键值 0 或 1 标记,并将
onNext(T)
信号分发给匹配的数据流。
2. 使用前面的
GroupByAction
,为两个正在发送的
Stream
添加一个已经生成好的调度器。通过像这样使用分配于各自调度器的两个分区,数据流得到了有效的扩充。
FlatMap
将合并两个分区的返回值,这个过程运行在两个线程之一,但绝不会并行处理。
3. 创建 5 个分区,并将
onNext(T)
信号以循环的方式分发给它们。
4. 使用第二个调度器分配新生成的数据流。返回的序列将被合并。
5. 使用
Environment.sharedDispatcher()
而不是前两个线程池分派数据。 五个线程将在
Dispatcher
线程合并。
提取输出
03:53:42.060 [groupByPool-3] INFO groupBy - onNext: 4 03:53:42.060 [partitionPool-8] INFO partition - onNext: 9 03:53:42.061 [groupByPool-3] INFO groupBy - onNext: 6 03:53:42.061 [partitionPool-8] INFO partition - onNext: 4 03:53:42.061 [shared-1] INFO join - onNext: 9 03:53:42.061 [groupByPool-3] INFO groupBy - onNext: 8 03:53:42.061 [partitionPool-4] INFO partition - onNext: 6 03:53:42.061 [shared-1] INFO join - onNext: 4 03:53:42.061 [groupByPool-3] INFO groupBy - onNext: 10 03:53:42.061 [shared-1] INFO join - onNext: 6 03:53:42.061 [groupByPool-3] INFO groupBy - complete: DispatcherAction ```
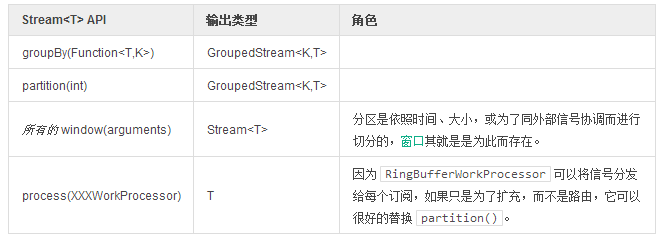
Rx 之外的其它 API
除了 Reactive Stream 直接实现的方法之外,还有一些 Stream
方法并没有被涉及,或是没有录入 Reactive 扩展文档之中。
表 22,在前面的用例中未涉及的一些方法
4
reactor-总线
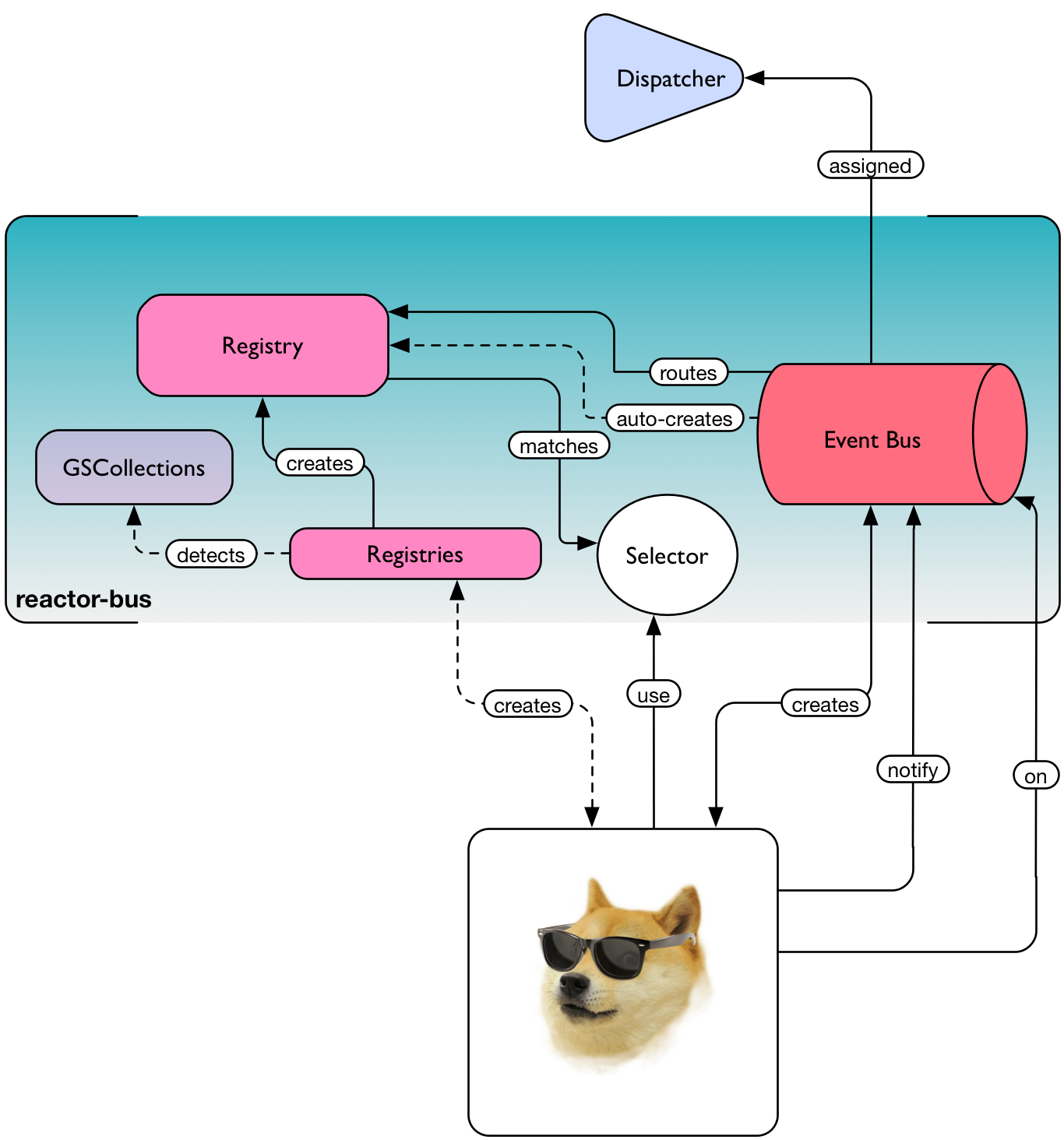
图14,程序员狗如何使用 reactor 总线
发布订阅模型
发布使用的是 EventBus
,而响应事件则使用 发布订阅模型
Reactor 的 EventBus
可以让你在通知的主键匹配特定条件时创建一个处理事件的消费者(Consumer
)。这项任务是在 选择器(Selector)
中被执行的。这跟订阅主题很像,但 Reactor 选择器
的实现可以匹配各种标准,从 Class<?>
类型到 JsonPath
表达式。这种抽象化非常的灵活且强大,它为匹配提供了广泛的可能性。
在创建多个使用相同 Selector
的消费者,也可以创建多个匹配同一主键的 Selector
。这种方式使得聚合和广播更加容易:你只需要将多个消费者订阅到同一主体选择器下即可。
如果你刚从 Reactor 1.1 升级的话,你会发现 Reactor
类消失了。它被重命名为EventBus
类,这是为了更精准的反应此类在框架中的角色。
使用选择器处理事件
EventBus bus = EventBus.create(Environment.get());
bus.on($("topic"), (Event<String> ev) -> {
String s = ev.getData();
System.out.printf("Got %s on thread %s%n", s, Thread.currentThread());
});
bus.notify("topic", Event.wrap("Hello World!"));
- 使用默认设置创建一个 EventBus 类,从静态的 Environment 中分享 RingBufferDispatcher
- 注册一个 Customer,当主键匹配 Selector 时通知 EventBus 调用。
- 使用给定主题发布 Event 到 EventBus。
静态方法 $
是方便调用 Selectors.object()
的缩写。有的人不喜欢使用缩写方法,例如对象选择器的 $()
,正则选择器的 R()
,*类选择器的 T()
等等。选择器也为这些缩写方法提供了长命名的替代方法。这些缩写方法只是为了减少代码噪音,提高代码可阅读性而的设定的。
请求应答模式
EventBus
发布和响应事件使用的是请求应答模式。
常见的情景是,你希望能够从运行在 EventBus 配置好的调度器(Dispatcher)
中的任务里获取应答。Reactor 的 EventBus
提供了比简单的发布订阅模型更全面的事件处理模型。除了 Cunsumer
,你也可以同样注册一个函数,EventBus
会自动将 Function
的返回值推送给 replyTo
主键中的主题。在这里,推荐使用 .receive() 和
.send()
方法,而不是 .on()
和.notify()
方法。
请求应答
EventBus bus;
bus.on($("reply.sink"), ev -> {
System.out.printf("Got %s on thread %s%n", ev, Thread.currentThread())
});
bus.receive($("job.sink"), ev -> {
return doWork(ev);
});
bus.send("job.sink", Event.wrap("Hello World!", "reply.sink"));
- 分配一个处理所有应答的 consumer
,不进行任何分析。 - 分配一个工作在Dispatcher
线程的 Function
,完成工作并返回结果。 - 使用给定的 replyTo
主键在总线中发布Event
。
如果没有一个发布应答的通用主题,你可以将请求和应答的操作绑定到一个单独的对 .sendAndReceive(Object, Event<?>, Consumer<Event<?>>)
方法的调用中。此方法将调用 .send()
,并在函数被调用时在 Dispatcher
线程调用给定的 replyTo
回调函数。
sendAndReceive()
EventBus bus;
bus.receive($("job.sink"), (Event<String> ev) -> {
return ev.getData().toUpperCase();
});
bus.sendAndReceive(
"job.sink",
Event.wrap("Hello World!"),
s -> System.out.printf("Got %s on thread %s%n", s, Thread.currentThread())
);
- 分配一个在 Dispatcher
线程完成工作并返回结果的 Function
。 - 在总线中发布一个Event
,并在 Dispatcher
中安排给定的 replyTo Consumer
,将接收事件的函数的返回值作为输入传递给它。
取消任务
有时候你希望取消一个任务,停止响应事件通知。注册函数.on()
和 .receive()
将返回一个 Registration
对象,如果持有该对象的引用,你可以用它取消给定Selector
的 Consumer
或 Function
。
EventBus bus;
Registration reg = bus.on($("topic"),
s -> System.out.printf("Got %s on thread %s%n", s, Thread.currentThread()));
bus.notify("topic", Event.wrap("Hello World!"));
// ...some time later...
reg.cancel();
// ...some time later...
bus.notify("topic", Event.wrap("Hello World!"));
- 对给定主题发布一个事件,应当在控制台中打印 Event.toString()
。 - 取消 Registration
对象的注册,组织消息抵达Consumer
。 - 这个通知不应当有任何结果。
牢记,取消一个Registration
的注册将对内部注册表进行原子访问。当系统中存在大量流向消费者的时间时,有时在你的.cancel()
调用完成后 注册表(Registry)
清理缓存并移除Registration
前,你的 Consumer
或 Function
依然会接收到一些事件。.cancel()
方法可以被称为:"请求尽快的取消"。 在测试类中你能够察觉这一行为特征,测试类中在.on()、.notify()
和 .cancel()
的调用之间没有任何时间延迟。
注册表
使用注册表(Registry)
缓存内存中的值。
5
reactor-网络
最后的最后
TCP 101
HTTP 101
HTTP 101
HTTP 路由解析
数据写入
缓冲区刷新策略
消费数据
背压策略
关闭通道
6
扩展
Groovy 语言扩展
在 Spring XD 系统中使用 Reactor
Clojure 语言支持
7
简明手册
制作一个快速断路器
制作一个高效的数据管道
制作一个非阻塞型微服务
制作一个类 CQRS 应用
其他示例程序


更多信息请访问

