




1.下载Hadoop 安装包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
2.SSH 配置
# 生成密钥ssh-keygen -t rsa# 写入 authorized_keyscat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys# 更改权限等级chmod 600 ~/.ssh/authorized_keys# 免密登录ssh 127.0.0.1
3.解压安装包
tar zxvf hadoop-3.3.0.tar.gz -C ~/app
4.hadoop-env.sh 配置
vi ~/app/hadoop-3.3.0/etc/hadoop/hadoop-env.shexport JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_281.jdk/Contents/Home"
5.core-site.xml 配置
vim ~/app/hadoop-3.3.0/etc/hadoop/core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:///Users/tech/app/data/hadoop-3.3.0/tmp</value></property></configuration>
6.hdfs-site.xml 配置
vim ~/app/hadoop-3.3.0/etc/hadoop/hdfs-site.xml<configuration><property><name>dfs.namenode.name.dir</name><value>file:///Users/tech/app/data/hadoop-3.3.0/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:///Users/tech/app/data/hadoop-3.3.0/dfs/data</value></property><property><name>dfs.replication</name><value>3</value></property></configuration>
7.yarn-site.xml 配置
vim ~/app/hadoop-3.3.0/etc/hadoop/yarn-site.xml<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property></configuration>
8.配置Hadoop 环境变量
# java evnexport JAVA_8_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_281.jdk/Contents/Home"export JAVA_HOME=$JAVA_8_HOMEexport PATH=$JAVA_HOME/bin:$PATH# scala evnexport SCALA_HOME="/usr/local/opt/scala@2.12"export PATH=$SCALA_HOME/bin:$PATH# spark evnexport SPARK_HOME="/Users/tech/app/spark-3.1.1-bin-3.3.0"export PATH=$SPARK_HOME/bin:$PATH# hadoop evnexport HADOOP_HOME="/Users/tech/app/hadoop-3.3.0"export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
Note: 这里需要的注意的是SPARK_HOME,由于本机运行的Hadoop的版本是3.3.0,而Spark3.1.1官方兼容的版本是3.2.0,可以查看Spark3.1.1源码包目录下的pom.xml
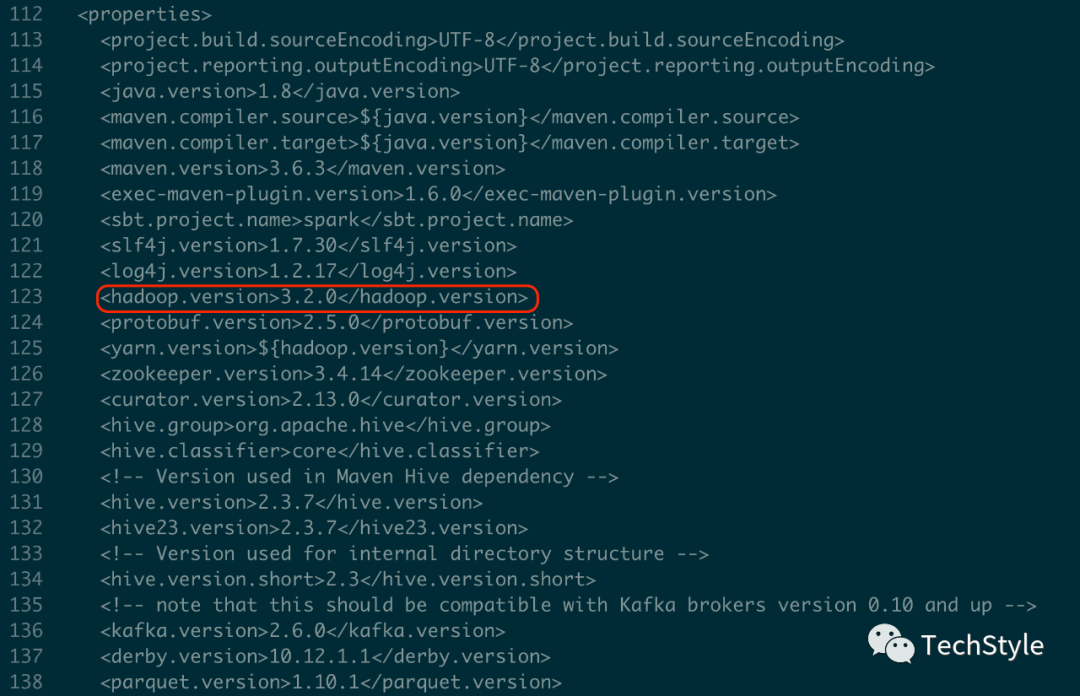
所以为了在YARN 上稳定运行Spark ,需要统一Spark 对应的 Hadoop 的版本,这里可以自定义编译构建,步骤如下:
下载Spark source code
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.1.1/spark-3.1.1.tgz
解压
tar zxvf spark-3.1.1.tgz
修改 make-distribution.sh
cd spark-3.1.1/devvi make-distribution.sh
添加如下4个变量
VERSION=3.1.1SCALA_VERSION=2.12SPARK_HADOOP_VERSION=3.3.0SPARK_HIVE=2.3
注释掉133-151行
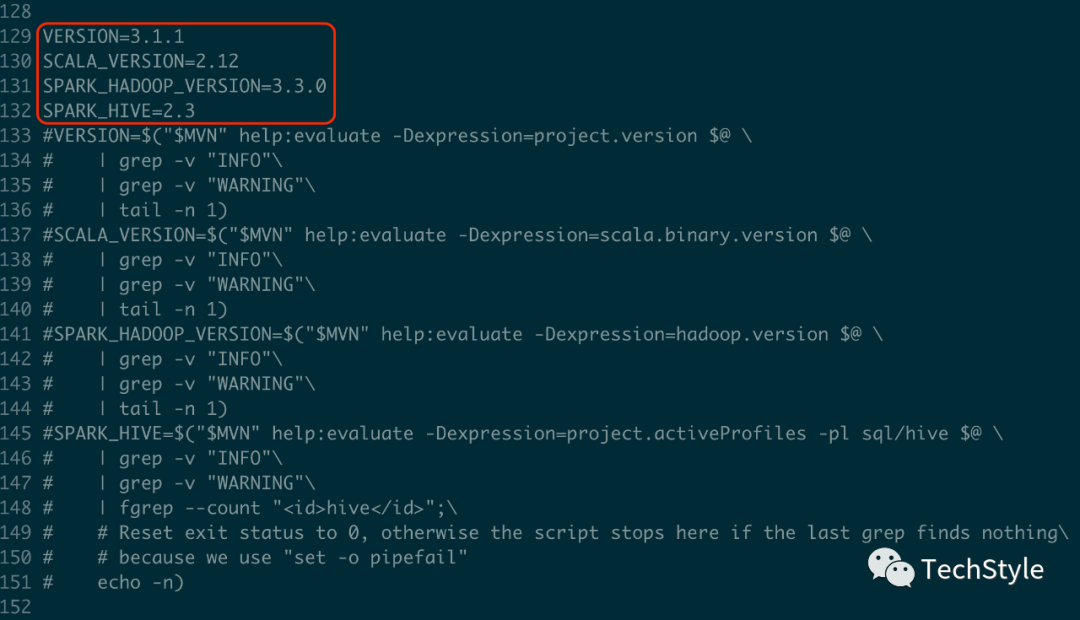
编译构建打包
./make-distribution.sh --name 3.3.0 --tgz -Dhadoop.version=3.3.0 -Pyarn -Phive -Phive-thriftserver -DskipTests
等待若干时间后,自定义指定版本的Spark 构建成功,如下图所示
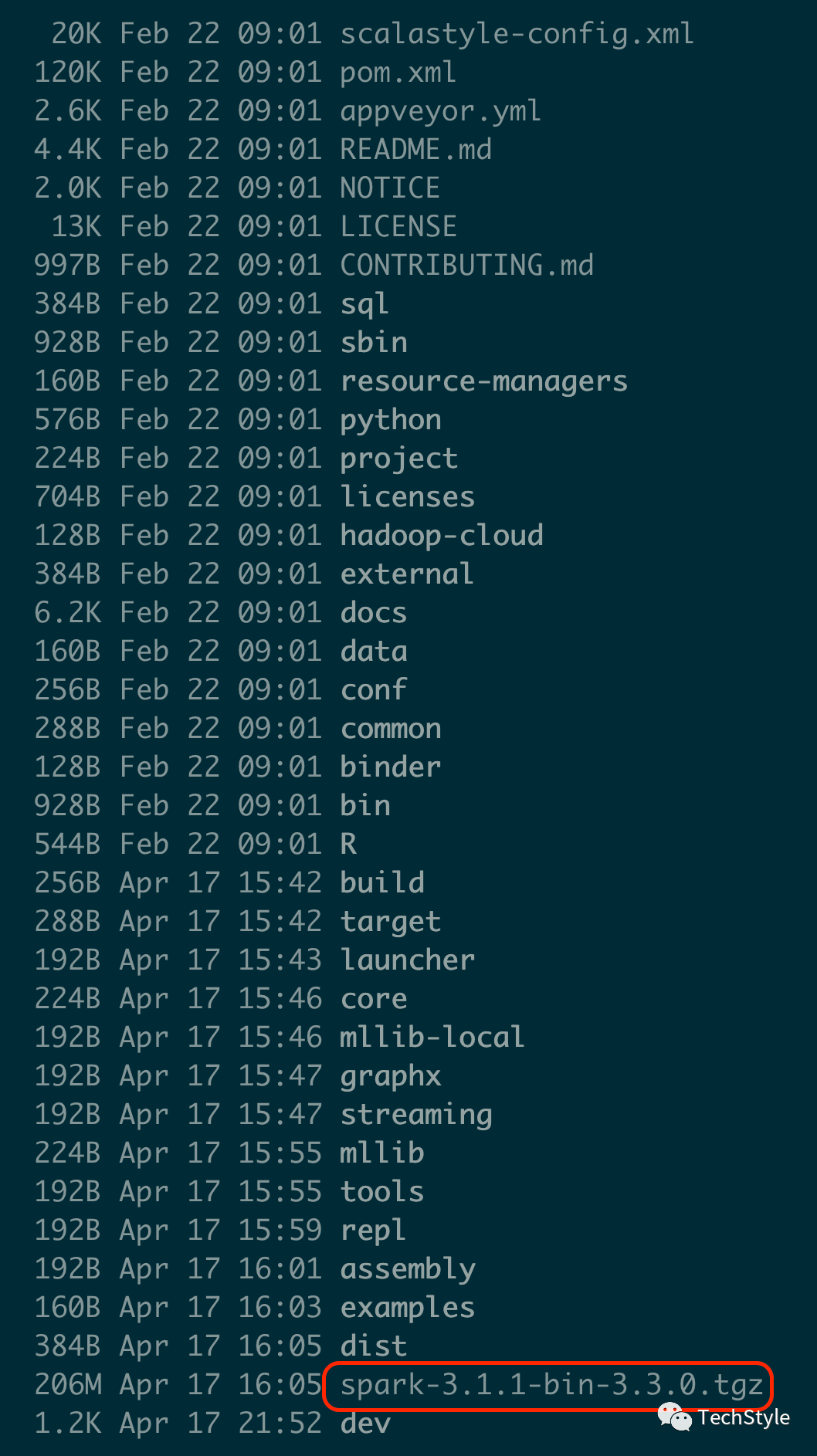
之后参考Spark Standalone 运行环境安装 配置SPARK_HOME、spark-env.sh、workers 后启动Spark
cd $SPARK_HOME/sbin./start-all.sh
会遇到这个错,遭遇启动失败
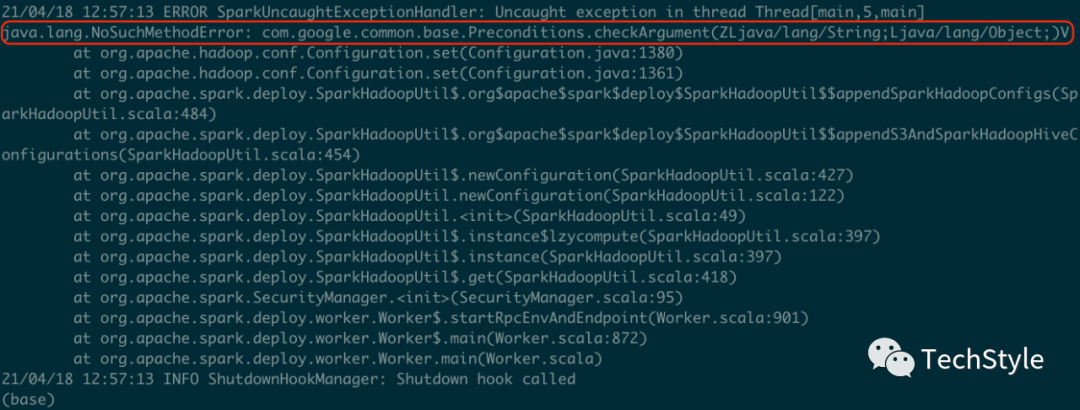
原因是自定义编译构建的spark的guava版本太低,
解决办法是移除掉spark-3.1.1-bin-3.3.0/jars/guava-14.0.1.jar,添加hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar
rm ~/app/spark-3.1.1-bin-3.3.0/jars/guava-14.0.1.jarcp hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ~/app/spark-3.1.1-bin-3.3.0/jars
然后重新启动
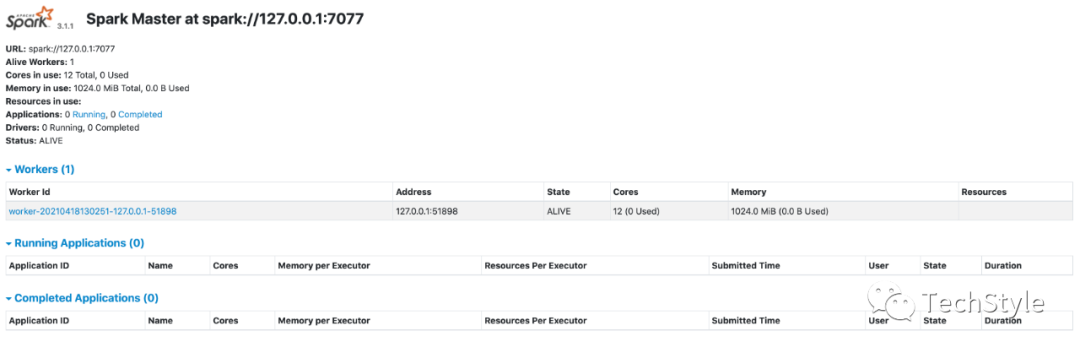
9.初始化HDFS NameNode
# 初始化 HDFScd ~/app/hadoop-3.3.0/bin./hdfs namenode -format
10.启动Hadoop
# 启动HDFS和YARNcd ~/app/hadoop-3.3.0/sbin./start-all.sh
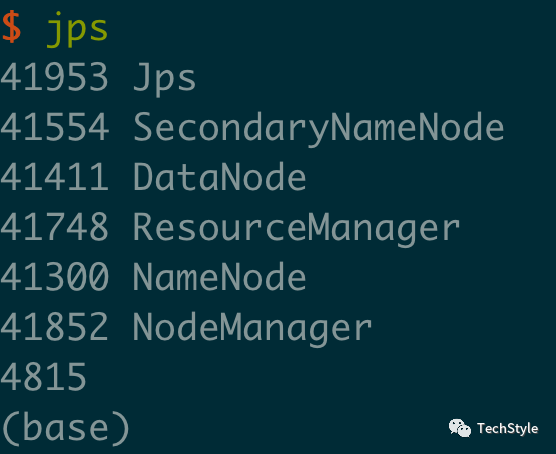
11.jps
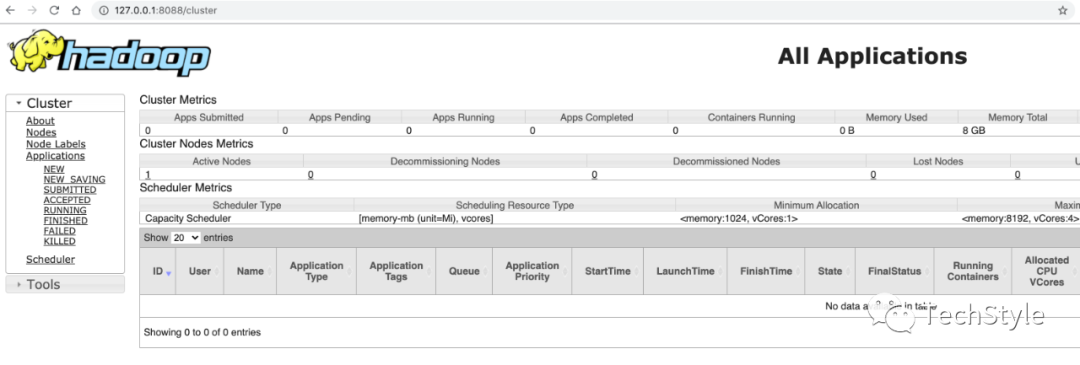
12.服务查看
http://127.0.0.1:8088/cluster
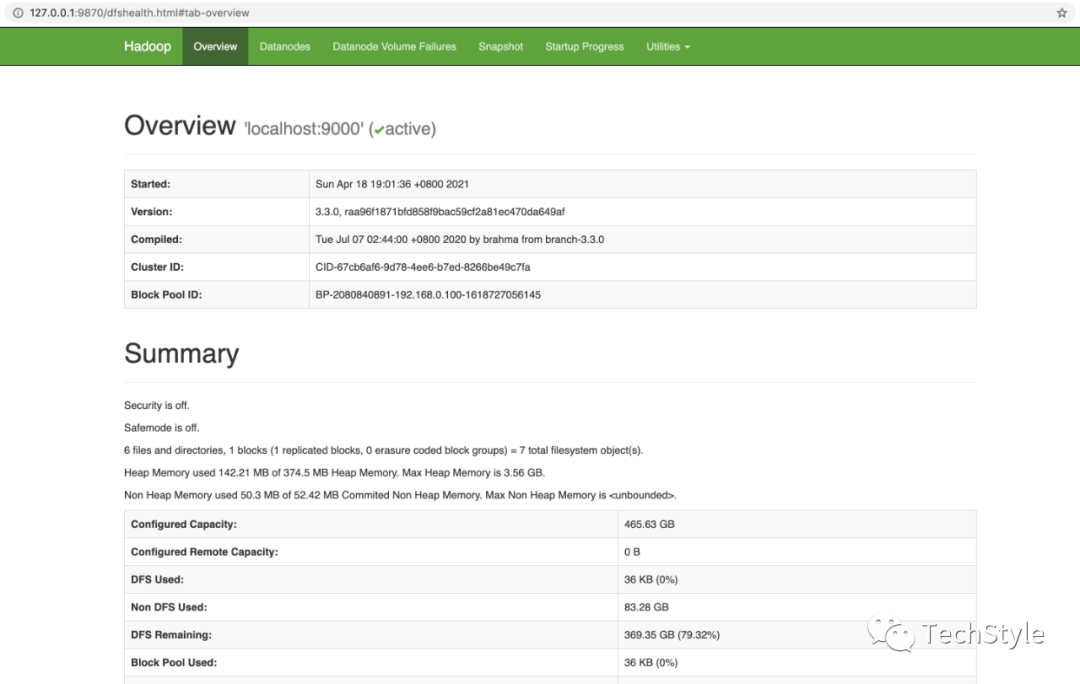
http://127.0.0.1:9870/dfshealth.html#tab-overview
13.HDFS 数据目录创建和数据写入
cd ~/app/hadoop-3.3.0/bin./hdfs dfs -mkdir /input./hdfs dfs -put ./../etc/hadoop/hadoop-env.sh /input./hdfs dfs -ls /input
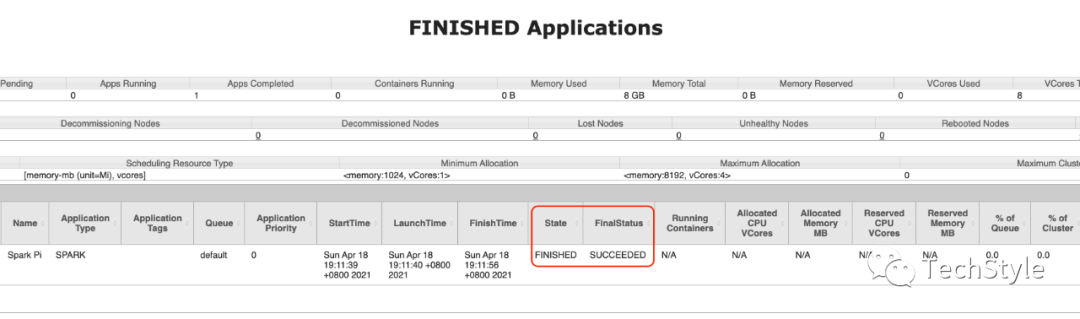
14.将Spark 任务提交到YARN 上执行
cd $SPARK_HOMEbin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.12-3.1.1.jar
Reference
http://spark.apache.org/docs/latest/building-spark.html
泰克风格 只讲干货 不弄玄虚
