PgSQL的优化器为一个查询生成一个执行效率相对较高的物理执行计划树。执行效率的高低依赖于代价估算。比如估算查询返回的记录条数、记录宽度等,就可以计算出IO开销;也可以根据要执行的物理操作估算出CPU代价。那么估算依赖的信息来源哪呢?系统表pg_statistic(列级别统计信息)为代价估算提供了关键统计信息。Analyze操作或者vacuum进行了统计信息采集,并将对数据按列进行分析,得到每列的数据分布、最常见值、频率等信息,更新到pg_statistic表。当然还有表级别的统计信息,存储在系统表pg_class:relptuples表示表的总元组数,relpages表示总页面数,等。
Analyze具体都做哪些事呢?本文先介绍下统计信息系统表。
1、pg_statistic
首先需要了解analyze都输出哪些信息到系统表。也就是pg_statistic系统表每列的含义。
postgres=# \d+ pg_statistic
数据表 "pg_catalog.pg_statistic"
栏位 | 类型 | 校对规则 | 可空的 | 预设 | 存储 | 统计目标 | 描述
-------------+----------+----------+----------+------+----------+----------+------
starelid | oid | | not null | | plain | |
staattnum | smallint | | not null | | plain | |
stainherit | boolean | | not null | | plain | |
stanullfrac | real | | not null | | plain | |
stawidth | integer | | not null | | plain | |
stadistinct | real | | not null | | plain | |
stakind1 | smallint | | not null | | plain | |
stakind2 | smallint | | not null | | plain | |
stakind3 | smallint | | not null | | plain | |
stakind4 | smallint | | not null | | plain | |
stakind5 | smallint | | not null | | plain | |
staop1 | oid | | not null | | plain | |
staop2 | oid | | not null | | plain | |
staop3 | oid | | not null | | plain | |
staop4 | oid | | not null | | plain | |
staop5 | oid | | not null | | plain | |
stacoll1 | oid | | not null | | plain | |
stacoll2 | oid | | not null | | plain | |
stacoll3 | oid | | not null | | plain | |
stacoll4 | oid | | not null | | plain | |
stacoll5 | oid | | not null | | plain | |
stanumbers1 | real[] | | | | extended | |
stanumbers2 | real[] | | | | extended | |
stanumbers3 | real[] | | | | extended | |
stanumbers4 | real[] | | | | extended | |
stanumbers5 | real[] | | | | extended | |
stavalues1 | anyarray | | | | extended | |
stavalues2 | anyarray | | | | extended | |
stavalues3 | anyarray | | | | extended | |
stavalues4 | anyarray | | | | extended | |
stavalues5 | anyarray | | | | extended | |
索引:
"pg_statistic_relid_att_inh_index" UNIQUE, btree (starelid, staattnum, stainherit)
访问方法 heapCatalog定义在pg_statistic.h中:
* pg_statistic definition. cpp turns this into
* typedef struct FormData_pg_statistic
* ----------------
*/
CATALOG(pg_statistic,2619,StatisticRelationId)
{
/* These fields form the unique key for the entry: */
Oid starelid; /* relation containing attribute */
int16 staattnum; /* attribute (column) stats are for */
bool stainherit; /* true if inheritance children are included */
/* the fraction of the column's entries that are NULL: */
float4 stanullfrac;
/*
* stawidth is the average width in bytes of non-null entries. For
* fixed-width datatypes this is of course the same as the typlen, but for
* var-width types it is more useful. Note that this is the average width
* of the data as actually stored, post-TOASTing (eg, for a
* moved-out-of-line value, only the size of the pointer object is
* counted). This is the appropriate definition for the primary use of
* the statistic, which is to estimate sizes of in-memory hash tables of
* tuples.
*/
int32 stawidth;
/* ----------------
* stadistinct indicates the (approximate) number of distinct non-null
* data values in the column. The interpretation is:
* 0 unknown or not computed
* > 0 actual number of distinct values
* < 0 negative of multiplier for number of rows
* The special negative case allows us to cope with columns that are
* unique (stadistinct = -1) or nearly so (for example, a column in which
* non-null values appear about twice on the average could be represented
* by stadistinct = -0.5 if there are no nulls, or -0.4 if 20% of the
* column is nulls). Because the number-of-rows statistic in pg_class may
* be updated more frequently than pg_statistic is, it's important to be
* able to describe such situations as a multiple of the number of rows,
* rather than a fixed number of distinct values. But in other cases a
* fixed number is correct (eg, a boolean column).
* ----------------
*/
float4 stadistinct;
/* ----------------
* To allow keeping statistics on different kinds of datatypes,
* we do not hard-wire any particular meaning for the remaining
* statistical fields. Instead, we provide several "slots" in which
* statistical data can be placed. Each slot includes:
* kind integer code identifying kind of data (see below)
* op OID of associated operator, if needed
* coll OID of relevant collation, or 0 if none
* numbers float4 array (for statistical values)
* values anyarray (for representations of data values)
* The ID, operator, and collation fields are never NULL; they are zeroes
* in an unused slot. The numbers and values fields are NULL in an
* unused slot, and might also be NULL in a used slot if the slot kind
* has no need for one or the other.
* ----------------
*/
int16 stakind1;
int16 stakind2;
int16 stakind3;
int16 stakind4;
int16 stakind5;
Oid staop1;
Oid staop2;
Oid staop3;
Oid staop4;
Oid staop5;
Oid stacoll1;
Oid stacoll2;
Oid stacoll3;
Oid stacoll4;
Oid stacoll5;
#ifdef CATALOG_VARLEN /* variable-length fields start here */
float4 stanumbers1[1];
float4 stanumbers2[1];
float4 stanumbers3[1];
float4 stanumbers4[1];
float4 stanumbers5[1];
/*
* Values in these arrays are values of the column's data type, or of some
* related type such as an array element type. We presently have to cheat
* quite a bit to allow polymorphic arrays of this kind, but perhaps
* someday it'll be a less bogus facility.
*/
anyarray stavalues1;
anyarray stavalues2;
anyarray stavalues3;
anyarray stavalues4;
anyarray stavalues5;
#endif
} FormData_pg_statistic;列描述:
1)starelid表示当前列所属的表或者索引
2)staattnum表示本行统计细腻些属于上面表或者索引的第几列
3)stainherit表示统计信息是否包含子列。通常情况下,analyze后每个表列都会有一个条目,并且stainerit为false。如果该表有分区子表,那么还会创建stainherit=true的第2条记录。其实stainherit=true,可以认为是父表,也就是这一行是所有子表的列的统计信息,而stainherit=false,则认为是叶子表,仅表示该子表的列的统计信息。
4)stanullfrac表示该列中NULL个数的比例
5)stawidth表示该列非空值的平均宽度
6)stadistinct表示列中非空值唯一值个数,即去重后的个数或比例。>0表示唯一值个数。=0表示唯一值个数未知。<0表示其绝对值去重后个数占总个数的比例,比如80%的个数是非NULL,平均每个非NULL值出现2次,那么这个是就可以表示为-0.4
7)stakindN用来表示统计信息的形式,即后面number、values所表示的数据的用途,用于生成pg_stats.统计信息形式的定义如下:
#define STATISTIC_KIND_MCV 1
#define STATISTIC_KIND_HISTOGRAM 2
#define STATISTIC_KIND_CORRELATION 3
#define STATISTIC_KIND_MCELEM 4
#define STATISTIC_KIND_DECHIST 5
#define STATISTIC_KIND_RANGE_LENGTH_HISTOGRAM 6
#define STATISTIC_KIND_BOUNDS_HISTOGRAM 7
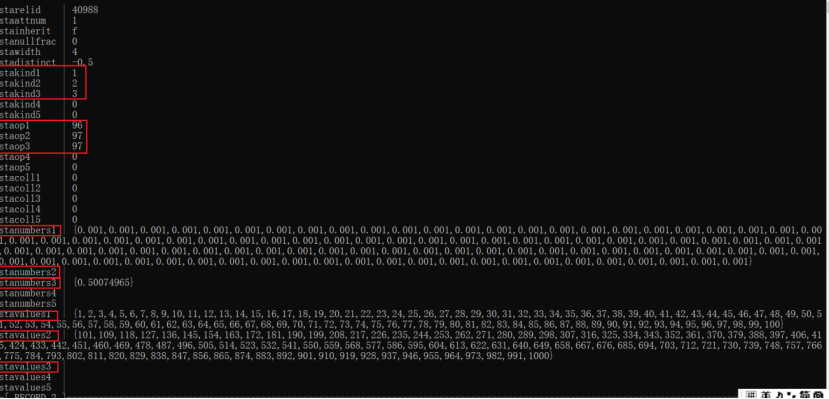
PG数据库对每个属性列的统计目前最多只能应用5(STATISTIC_NUM_SLOTS)种统计方法,因此在pg_statistic中会有stakind1--stakind5、staop1--staop5、stanumbers1--stanumbers5以及stavalues1--stavalues5共5个slot。如果stakind不为0,则表示该对应slot有统计信息。第一个统计方法的信息会先记录到第一个slot中(stakind1、staop1、statnumber1、stavalues1),第2个统计方法信息会记录到第二个slot中(stakind2、staop2、statnumber2、stavalues2),依次类推,可有存5个统计方法信息。而stakindi的值则为上述统计信息形式的宏定义。比如1表示MCV值;2表示直方图的值;3表示相关性的值等。Kind的范围:1-99:内核占用;100-199,PostGIS占用;200-299,ESRI ST_Geometry几何系统占用;300-9999,未来公共占用。
8)staopN用来表示该统计值支持的操作,如“=”或者“<”
9)stacollN用来表示统计信息的排序规则
10)stanumbersN用来表示如果是MCV类型,这里就是下面对应stavaluesN出现的概率值
11)stavaluesN用来表示统计值数组
例:表t4有两列,分别插入两次1--1000的值。
create table t4(id1 int,id2 int);insert into t4 select generate_series(1,1000),generate_series(1,1000);insert into t4 select * from t4;说明:
id1列应用了3个统计方法,占了3个slot,分别是MCV(1)、直方图(2)、相关系数(3)
stakind1为1,表示使用MCV,stanumbers1保存的是高频值数组,数组中记录的是每个高频值占用的频率值,而stavalues1则保存的是高频数数组对应的数值。
stakind3为3,表示使用相关性,stanumbers3中保存的是相关系数。若相关系数为1,则表示数据分布和排序(按物理位置)后的数据分布完全正相关。
stakind2为2,表示使用直方图,stavalues2保存的是直方图每个slot的边界值。因为用的是等频直方图,只需要记录每个桶边界值,就可以获取的每个桶的平均比例。