统计信息调优介绍
GaussDB是基于代价估算生成的最优执行计划。优化器需要根据analyze收集的统计信息进行行数估算和代价估算,因此统计信息对优化器行数估算和代价估算起着至关重要的作用。通过analyze收集全局统计信息,主要包括:pg_class表中的relpages和reltuples;pg_statistic表中的stadistinct、stanullfrac、stanumbersN、stavaluesN、histogram_bounds等。
实例分析1:未收集统计信息导致查询性能差
在很多场景下,由于查询中涉及到的表或列没有收集统计信息,会对查询性能有很大的影响。
表结构如下所示:
CREATE TABLE LINEITEM ( L_ORDERKEY BIGINT NOT NULL , L_PARTKEY BIGINT NOT NULL , L_SUPPKEY BIGINT NOT NULL , L_LINENUMBER BIGINT NOT NULL , L_QUANTITY DECIMAL(15,2) NOT NULL , L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL , L_DISCOUNT DECIMAL(15,2) NOT NULL , L_TAX DECIMAL(15,2) NOT NULL , L_RETURNFLAG CHAR(1) NOT NULL , L_LINESTATUS CHAR(1) NOT NULL , L_SHIPDATE DATE NOT NULL , L_COMMITDATE DATE NOT NULL , L_RECEIPTDATE DATE NOT NULL , L_SHIPINSTRUCT CHAR(25) NOT NULL , L_SHIPMODE CHAR(10) NOT NULL , L_COMMENT VARCHAR(44) NOT NULL ) with (orientation = column, COMPRESSION = MIDDLE) distribute by hash(L_ORDERKEY); CREATE TABLE ORDERS ( O_ORDERKEY BIGINT NOT NULL , O_CUSTKEY BIGINT NOT NULL , O_ORDERSTATUS CHAR(1) NOT NULL , O_TOTALPRICE DECIMAL(15,2) NOT NULL , O_ORDERDATE DATE NOT NULL , O_ORDERPRIORITY CHAR(15) NOT NULL , O_CLERK CHAR(15) NOT NULL , O_SHIPPRIORITY BIGINT NOT NULL , O_COMMENT VARCHAR(79) NOT NULL )with (orientation = column, COMPRESSION = MIDDLE) distribute by hash(O_ORDERKEY);
查询语句如下所示:
explain verbose select count(*) as numwait from lineitem l1, orders where o_orderkey = l1.l_orderkey and o_orderstatus = 'F' and l1.l_receiptdate > l1.l_commitdate and not exists ( select * from lineitem l3 where l3.l_orderkey = l1.l_orderkey and l3.l_suppkey <> l1.l_suppkey and l3.l_receiptdate > l3.l_commitdate ) order by numwait desc;
当出现该问题时,可以通过如下方法确认查询中涉及到的表或列有没有做过analyze收集统计信息。
- 通过explain verbose执行query分析执行计划时会提示WARNING信息,如下所示:
WARNING:Statistics in some tables or columns(public.lineitem.l_receiptdate, public.lineitem.l_commitdate, public.lineitem.l_orderkey, public.lineitem.l_suppkey, public.orders.o_orderstatus, public.orders.o_orderkey) are not collected. HINT:Do analyze for them in order to generate optimized plan.
- 可以通过在pg_log目录下的日志文件中查找以下信息来确认当前执行的query是否由于没有收集统计信息导致查询性能变差。
2017-06-14 17:28:30.336 CST 140644024579856 20971684 [BACKEND] LOG:Statistics in some tables or columns(public.lineitem.l_receiptdate, public.lineitem.l_commitdate, public.lineitem.l_orderkey, public.linei tem.l_suppkey, public.orders.o_orderstatus, public.orders.o_orderkey) are not collected. 2017-06-14 17:28:30.336 CST 140644024579856 20971684 [BACKEND] HINT:Do analyze for them in order to generate optimized plan.
当通过以上方法查看到哪些表或列没有做analyze,可以通过对WARNING或日志中上报的表或列做analyze来解决由于未收集统计信息导致查询变慢的问题。
实例分析3:多表join的复杂查询存在中间结果不准调优
现象描述:查询与指定人在前后15分钟内、同一网吧登记上网的人员信息:
SELECT C.WBM, C.DZQH, C.DZ, B.ZJHM, B.SWKSSJ, B.XWSJ FROM b_zyk_wbswxx A, b_zyk_wbswxx B, b_zyk_wbcs C WHERE A.ZJHM = '522522******3824' AND A.WBDM = B.WBDM AND A.WBDM = C.WBDM AND abs(to_date(A.SWKSSJ,'yyyymmddHH24MISS') - to_date(B.SWKSSJ,'yyyymmddHH24MISS')) < INTERVAL '15 MINUTES' ORDER BY B.SWKSSJ, B.ZJHM limit 10 offset 0 ;
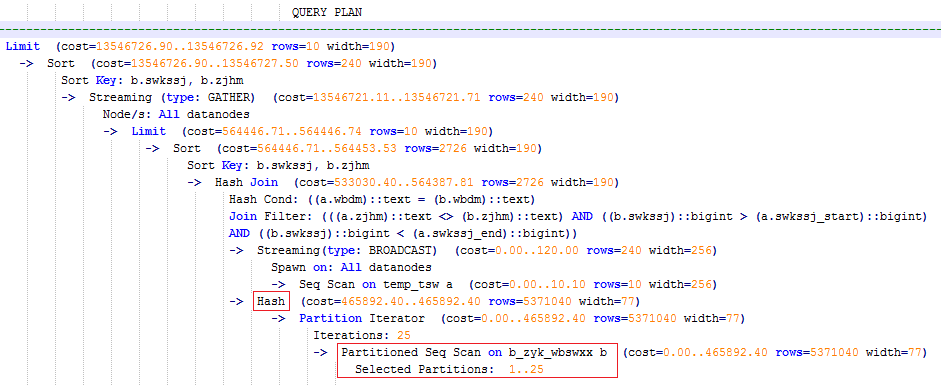
执行计划如图1所示。该查询实际耗时约12秒。

优化分析:分析过程如下:
- 分析该执行计划发现,扫描节点已使用Index Scan,耗时主要在最外层Nest Loop Join的Join Filter计算中,且该计算执行了字符串的加减法和不等值比较。
- 考虑使用unlogged table保存目标人的上网信息,且在插入时处理上网开始时间和终止时间,以避免后续进行时间加减。
//创建临时unlogged table CREATE UNLOGGED TABLE temp_tsw ( ZJHM NVARCHAR2(18), WBDM NVARCHAR2(14), SWKSSJ_START NVARCHAR2(14), SWKSSJ_END NVARCHAR2(14), WBM NVARCHAR2(70), DZQH NVARCHAR2(6), DZ NVARCHAR2(70), IPDZ NVARCHAR2(39) ) ; //插入目标人的上网记录,并处理上网开始和结束时间。 INSERT INTO temp_tsw SELECT A.ZJHM, A.WBDM, to_char((to_date(A.SWKSSJ,'yyyymmddHH24MISS') - INTERVAL '15 MINUTES'),'yyyymmddHH24MISS'), to_char((to_date(A.SWKSSJ,'yyyymmddHH24MISS') + INTERVAL '15 MINUTES'),'yyyymmddHH24MISS'), B.WBM,B.DZQH,B.DZ,B.IPDZ FROM b_zyk_wbswxx A, b_zyk_wbcs B WHERE A.ZJHM='522522******3824' AND A.WBDM = B.WBDM ; //查询和目标人在前后十五分钟内在同一网吧上网的人员信息,比较大小时强制转换为int8。 SELECT A.WBM, A.DZQH, A.DZ, A.IPDZ, B.ZJHM, B.XM, to_date(B.SWKSSJ,'yyyymmddHH24MISS') as SWKSSJ, to_date(B.XWSJ,'yyyymmddHH24MISS') as XWSJ, B.SWZDH FROM temp_tsw A, b_zyk_wbswxx B WHERE A.ZJHM <> B.ZJHM AND A.WBDM = B.WBDM AND (B.SWKSSJ)::int8 > (A.swkssj_start)::int8 AND (B.SWKSSJ)::int8 < (A.swkssj_end)::int8 order by B.SWKSSJ, B.ZJHM limit 10 offset 0 ;
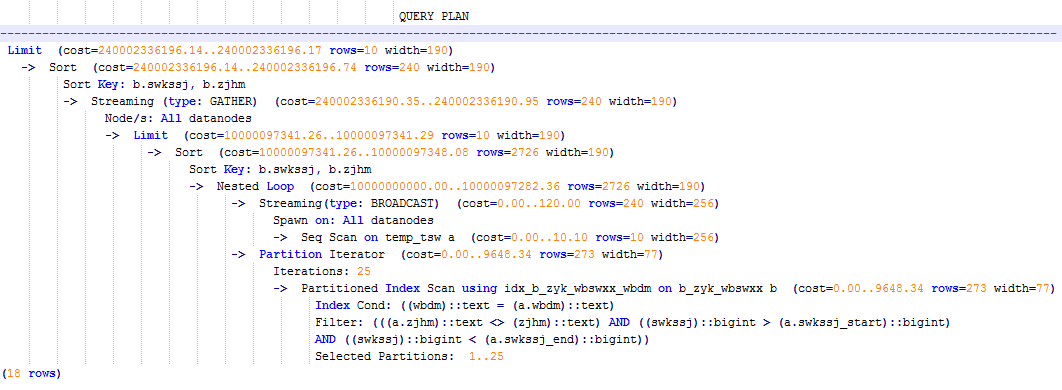
上述查询耗时约7秒,执行计划如图2所示。
- 分析上述执行计划,发现执行了Hash Join,对大表b_zyk_wbswxx建立了Hash Table。由于该表数据量大,创建过程耗时较长。
由于temp_tsw中仅包含几百条记录,且temp_tsw和b_zyk_wbswxx均通过wbdm(网吧代码)执行等值连接。因此,如果Join方式改为Nest Loop Join,则扫描节点可以实现Index Scan,性能预计将会提升。
- 执行如下语句,将Join方式改为Nest Loop Join。
SET enable_hashjoin = off;
执行计划如图3所示。查询耗时约3秒。
- 使用unlogged table保存结果集并用于分页显示。
如果需要在上层应用页面实现分页显示,需要修改offset值确定显示目标页的结果集。按此实现,每次翻页时均执行上面查询语句,耗时较长。
为解决上述问题,建议使用unlogged table保存结果集。
//创建保存结果集的unlogged table CREATE UNLOGGED TABLE temp_result ( WBM NVARCHAR2(70), DZQH NVARCHAR2(6), DZ NVARCHAR2(70), IPDZ NVARCHAR2(39), ZJHM NVARCHAR2(18), XM NVARCHAR2(30), SWKSSJ date, XWSJ date, SWZDH NVARCHAR2(32) ); //将结果集插入unlogged table,插入耗时约3秒。 INSERT INTO temp_result SELECT A.WBM, A.DZQH, A.DZ, A.IPDZ, B.ZJHM, B.XM, to_date(B.SWKSSJ,'yyyymmddHH24MISS') as SWKSSJ, to_date(B.XWSJ,'yyyymmddHH24MISS') as XWSJ, B.SWZDH FROM temp_tsw A, b_zyk_wbswxx B WHERE A.ZJHM <> B.ZJHM AND A.WBDM = B.WBDM AND (B.SWKSSJ)::int8 > (A.swkssj_start)::int8 AND (B.SWKSSJ)::int8 < (A.swkssj_end)::int8 ; //查询结果集表进行分页显示,分页查询耗时约10ms。 SELECT * FROM temp_result ORDER BY SWKSSJ, ZJHM LIMIT 10 OFFSET 0;


 注意:
注意:
收集更准确的统计信息,通常会改善查询性能,但是也有可能使性能劣化。如果遇到性能劣化,可以考虑:
统计信息调优介绍
GaussDB是基于代价估算生成的最优执行计划。优化器需要根据analyze收集的统计信息进行行数估算和代价估算,因此统计信息对优化器行数估算和代价估算起着至关重要的作用。通过analyze收集全局统计信息,主要包括:pg_class表中的relpages和reltuples;pg_statistic表中的stadistinct、stanullfrac、stanumbersN、stavaluesN、histogram_bounds等。
实例分析1:未收集统计信息导致查询性能差
在很多场景下,由于查询中涉及到的表或列没有收集统计信息,会对查询性能有很大的影响。
表结构如下所示:
CREATE TABLE LINEITEM ( L_ORDERKEY BIGINT NOT NULL , L_PARTKEY BIGINT NOT NULL , L_SUPPKEY BIGINT NOT NULL , L_LINENUMBER BIGINT NOT NULL , L_QUANTITY DECIMAL(15,2) NOT NULL , L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL , L_DISCOUNT DECIMAL(15,2) NOT NULL , L_TAX DECIMAL(15,2) NOT NULL , L_RETURNFLAG CHAR(1) NOT NULL , L_LINESTATUS CHAR(1) NOT NULL , L_SHIPDATE DATE NOT NULL , L_COMMITDATE DATE NOT NULL , L_RECEIPTDATE DATE NOT NULL , L_SHIPINSTRUCT CHAR(25) NOT NULL , L_SHIPMODE CHAR(10) NOT NULL , L_COMMENT VARCHAR(44) NOT NULL ) with (orientation = column, COMPRESSION = MIDDLE) distribute by hash(L_ORDERKEY); CREATE TABLE ORDERS ( O_ORDERKEY BIGINT NOT NULL , O_CUSTKEY BIGINT NOT NULL , O_ORDERSTATUS CHAR(1) NOT NULL , O_TOTALPRICE DECIMAL(15,2) NOT NULL , O_ORDERDATE DATE NOT NULL , O_ORDERPRIORITY CHAR(15) NOT NULL , O_CLERK CHAR(15) NOT NULL , O_SHIPPRIORITY BIGINT NOT NULL , O_COMMENT VARCHAR(79) NOT NULL )with (orientation = column, COMPRESSION = MIDDLE) distribute by hash(O_ORDERKEY);
查询语句如下所示:
explain verbose select count(*) as numwait from lineitem l1, orders where o_orderkey = l1.l_orderkey and o_orderstatus = 'F' and l1.l_receiptdate > l1.l_commitdate and not exists ( select * from lineitem l3 where l3.l_orderkey = l1.l_orderkey and l3.l_suppkey <> l1.l_suppkey and l3.l_receiptdate > l3.l_commitdate ) order by numwait desc;
当出现该问题时,可以通过如下方法确认查询中涉及到的表或列有没有做过analyze收集统计信息。
- 通过explain verbose执行query分析执行计划时会提示WARNING信息,如下所示:
WARNING:Statistics in some tables or columns(public.lineitem.l_receiptdate, public.lineitem.l_commitdate, public.lineitem.l_orderkey, public.lineitem.l_suppkey, public.orders.o_orderstatus, public.orders.o_orderkey) are not collected. HINT:Do analyze for them in order to generate optimized plan.
- 可以通过在pg_log目录下的日志文件中查找以下信息来确认当前执行的query是否由于没有收集统计信息导致查询性能变差。
2017-06-14 17:28:30.336 CST 140644024579856 20971684 [BACKEND] LOG:Statistics in some tables or columns(public.lineitem.l_receiptdate, public.lineitem.l_commitdate, public.lineitem.l_orderkey, public.linei tem.l_suppkey, public.orders.o_orderstatus, public.orders.o_orderkey) are not collected. 2017-06-14 17:28:30.336 CST 140644024579856 20971684 [BACKEND] HINT:Do analyze for them in order to generate optimized plan.
当通过以上方法查看到哪些表或列没有做analyze,可以通过对WARNING或日志中上报的表或列做analyze来解决由于未收集统计信息导致查询变慢的问题。
恢复默认的统计信息。实例分析3:多表join的复杂查询存在中间结果不准调优
现象描述:查询与指定人在前后15分钟内、同一网吧登记上网的人员信息:
SELECT C.WBM, C.DZQH, C.DZ, B.ZJHM, B.SWKSSJ, B.XWSJ FROM b_zyk_wbswxx A, b_zyk_wbswxx B, b_zyk_wbcs C WHERE A.ZJHM = '522522******3824' AND A.WBDM = B.WBDM AND A.WBDM = C.WBDM AND abs(to_date(A.SWKSSJ,'yyyymmddHH24MISS') - to_date(B.SWKSSJ,'yyyymmddHH24MISS')) < INTERVAL '15 MINUTES' ORDER BY B.SWKSSJ, B.ZJHM limit 10 offset 0 ;
执行计划如图1所示。该查询实际耗时约12秒。
优化分析:分析过程如下:
- 分析该执行计划发现,扫描节点已使用Index Scan,耗时主要在最外层Nest Loop Join的Join Filter计算中,且该计算执行了字符串的加减法和不等值比较。
- 考虑使用unlogged table保存目标人的上网信息,且在插入时处理上网开始时间和终止时间,以避免后续进行时间加减。
//创建临时unlogged table CREATE UNLOGGED TABLE temp_tsw ( ZJHM NVARCHAR2(18), WBDM NVARCHAR2(14), SWKSSJ_START NVARCHAR2(14), SWKSSJ_END NVARCHAR2(14), WBM NVARCHAR2(70), DZQH NVARCHAR2(6), DZ NVARCHAR2(70), IPDZ NVARCHAR2(39) ) ; //插入目标人的上网记录,并处理上网开始和结束时间。 INSERT INTO temp_tsw SELECT A.ZJHM, A.WBDM, to_char((to_date(A.SWKSSJ,'yyyymmddHH24MISS') - INTERVAL '15 MINUTES'),'yyyymmddHH24MISS'), to_char((to_date(A.SWKSSJ,'yyyymmddHH24MISS') + INTERVAL '15 MINUTES'),'yyyymmddHH24MISS'), B.WBM,B.DZQH,B.DZ,B.IPDZ FROM b_zyk_wbswxx A, b_zyk_wbcs B WHERE A.ZJHM='522522******3824' AND A.WBDM = B.WBDM ; //查询和目标人在前后十五分钟内在同一网吧上网的人员信息,比较大小时强制转换为int8。 SELECT A.WBM, A.DZQH, A.DZ, A.IPDZ, B.ZJHM, B.XM, to_date(B.SWKSSJ,'yyyymmddHH24MISS') as SWKSSJ, to_date(B.XWSJ,'yyyymmddHH24MISS') as XWSJ, B.SWZDH FROM temp_tsw A, b_zyk_wbswxx B WHERE A.ZJHM <> B.ZJHM AND A.WBDM = B.WBDM AND (B.SWKSSJ)::int8 > (A.swkssj_start)::int8 AND (B.SWKSSJ)::int8 < (A.swkssj_end)::int8 order by B.SWKSSJ, B.ZJHM limit 10 offset 0 ;
上述查询耗时约7秒,执行计划如图2所示。
- 分析上述执行计划,发现执行了Hash Join,对大表b_zyk_wbswxx建立了Hash Table。由于该表数据量大,创建过程耗时较长。
由于temp_tsw中仅包含几百条记录,且temp_tsw和b_zyk_wbswxx均通过wbdm(网吧代码)执行等值连接。因此,如果Join方式改为Nest Loop Join,则扫描节点可以实现Index Scan,性能预计将会提升。
- 执行如下语句,将Join方式改为Nest Loop Join。
SET enable_hashjoin = off;
执行计划如图3所示。查询耗时约3秒。
- 使用unlogged table保存结果集并用于分页显示。
如果需要在上层应用页面实现分页显示,需要修改offset值确定显示目标页的结果集。按此实现,每次翻页时均执行上面查询语句,耗时较长。
为解决上述问题,建议使用unlogged table保存结果集。
//创建保存结果集的unlogged table CREATE UNLOGGED TABLE temp_result ( WBM NVARCHAR2(70), DZQH NVARCHAR2(6), DZ NVARCHAR2(70), IPDZ NVARCHAR2(39), ZJHM NVARCHAR2(18), XM NVARCHAR2(30), SWKSSJ date, XWSJ date, SWZDH NVARCHAR2(32) ); //将结果集插入unlogged table,插入耗时约3秒。 INSERT INTO temp_result SELECT A.WBM, A.DZQH, A.DZ, A.IPDZ, B.ZJHM, B.XM, to_date(B.SWKSSJ,'yyyymmddHH24MISS') as SWKSSJ, to_date(B.XWSJ,'yyyymmddHH24MISS') as XWSJ, B.SWZDH FROM temp_tsw A, b_zyk_wbswxx B WHERE A.ZJHM <> B.ZJHM AND A.WBDM = B.WBDM AND (B.SWKSSJ)::int8 > (A.swkssj_start)::int8 AND (B.SWKSSJ)::int8 < (A.swkssj_end)::int8 ; //查询结果集表进行分页显示,分页查询耗时约10ms。 SELECT * FROM temp_result ORDER BY SWKSSJ, ZJHM LIMIT 10 OFFSET 0;
注意:
收集更准确的统计信息,通常会改善查询性能,但是也有可能使性能劣化。如果遇到性能劣化,可以考虑:
- 恢复默认的统计信息。
- 使用plan hint来调整到之前的查询计划。(详细参见使用Plan Hint进行调优)
- 通过explain verbose执行query分析执行计划时会提示WARNING信息,如下所示:
- 使用plan hint来调整到之前的查询计划。(详细参见使用Plan Hint进行调优)