




生成式人工智能(Generative artificial intelligence - GAI)擅长基于大型语言模型(LLM)创建文本回复,其中人工智能是在大量数据点上进行训练的。
好消息是,生成的文本通常易于阅读,并能提供广泛适用于软件所提问题(通常称为提示)的详细回复。
坏消息是,用于生成回复的信息仅限于用于训练人工智能的信息,通常是通用的 LLM。LLM 的数据可能已经过期数周、数月或数年,在企业人工智能聊天机器人中可能不包括有关企业产品或服务的具体信息。这可能会导致错误的回复,从而削弱客户和员工对技术的信心。
什么是检索增强生成(RAG)?
这就是检索增强生成(RAG)的用武之地。RAG 提供了一种在不修改底层模型本身的情况下,利用目标信息优化 LLM 输出的方法;目标信息可以比 LLM 更新颖,也可以是特定组织和行业的特定信息。这意味着生成式人工智能系统可以针对提示提供更符合实际情况的答案,并将这些答案建立在最新数据的基础上。
RAG 首次引起生成式人工智能开发人员的注意,是在 2020 年帕特里克-刘易斯(Patrick Lewis)和 Facebook 人工智能研究团队发表的论文《知识密集型 NLP 任务的检索增强生成》(Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks)之后。RAG 概念受到了许多学术界和业界研究人员的追捧,他们将其视为显著提高生成式人工智能系统价值的一种方法。
假设有一个体育联盟希望球迷和媒体能够使用聊天工具访问其数据,并回答有关球员、球队、体育历史和规则以及当前统计数据和排名的问题。通用的 LLM 可以回答有关历史和规则的问题,或者描述某支球队的球场。但它无法讨论昨晚的比赛,也无法提供有关某位运动员伤情的最新信息,因为 LLM 并不掌握这些信息–而且鉴于 LLM 需要耗费大量计算能力来重新训练,因此保持模型的最新性并不可行。
除了大型、相当静态的 LLM 之外,体育联盟还拥有或可以访问许多其他信息源,包括数据库、数据仓库、包含球员简历的文档以及深入讨论每场比赛的新闻源。RAG 可让生成式人工智能获取这些信息。现在,聊天可以提供更及时、更适合上下文、更准确的信息。
简而言之,RAG 可以帮助大模型提供更好的答案。
RAG 是一种相对较新的人工智能技术,它可以让大型语言模型 (LLM) 无需重新训练即可利用更多数据资源,从而提高生成式人工智能的质量。
RAG 模型基于企业自身的数据建立知识库,知识库可以不断更新,以帮助生成式人工智能提供及时、符合上下文的答案。
聊天机器人和其他使用自然语言处理的对话系统可以从 RAG 和生成式人工智能中受益匪浅。
实施 RAG 需要矢量数据库等技术,这些技术可以快速编码新数据,并根据这些数据进行搜索,为 LLM 提供信息。
考虑一个组织所拥有的所有信息–结构化数据库、非结构化 PDF 和其他文档、博客、新闻源、过去客户服务会话的聊天记录。在 RAG 中,这些海量的动态数据会被转换成通用格式,并存储在知识库中,供人工智能生成系统访问。
然后,知识库中的数据会使用一种称为嵌入式语言模型的特殊算法处理成数字表示,并存储在向量数据库中,以便快速搜索和检索正确的上下文信息。
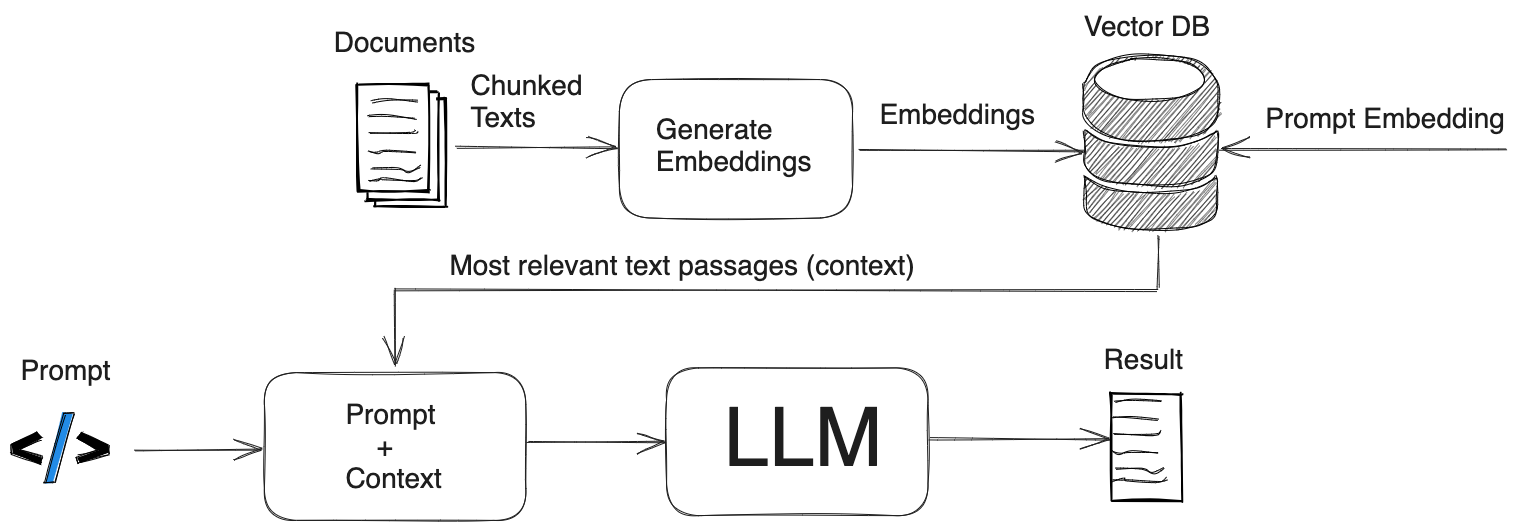
RAG 的另一个好处是,通过使用向量数据库,生成式人工智能可以提供其答案中引用的具体数据源–这是 LLM 无法做到的。因此,如果生成式人工智能的输出不准确,包含错误信息的文档可以被快速识别和纠正,然后将纠正后的信息输入矢量数据库。
简而言之,RAG 为生成式人工智能提供了基于证据的及时性、上下文和准确性,超出了 LLM 本身所能提供的范围。
