





新闻速递
1.企业数据要素与资产运营的建设路径:数据资源化、数据资产化和数据资本化,星环科技技术助力成功
2.新“局”已定,数据要素市场将迎利好
3. 国家“数据要素市场”相关政策要点解析
4.千亿已成标配,北京启动数据要素先行区
大数据
5.数据治理、反欺诈、风险预警、反洗钱···星环科技入选“中国银行业人工智能与大数据市场图谱”
6. 清雁科技发布企业数据资产入表一站式服务平台!
7.三大数智产品升级发布,网易数帆夯实数智生态方法论“根基”
8.ClickHouse牵手阿里云发布阿里云ClickHouse企业版,并启动公测
9.阿里云数据库SelectDB版发布!提供极速实时、融合统一、简单易用的云上数仓服务
数据库
10.开源图数据库gStore 1.2版本正式上线,体验再度升级!
11.百度给给Elasticsearch 加上向量检索能力,支撑大模型场景需求
12.柏睿向量数据库基于RapidsDB实现安全高效的向量存储
13.Monte Carlo推出矢量数据库的数据可观测性
14.MongoDB推出Atlas for Retail,一个合作伙伴生态系统计划
数据安全
15.《中国网络安全产业分析报告 (2023年)》全文发布,10个发展热点值得关注
16.瑞数信息发布新一代数据安全防护体系,守住数据安全最后一道防线
17.埃森哲通过收购MNEM,扩大网络安全服务能力
AI
18.填补政策量化分析空白,星环科技与中信证券荣获上交所ITRDC行业共研课题一等奖
19.比尔·盖茨:5年内每个人都将拥有一位人工智能驱动的个人助理
20.《上海市推动人工智能大模型创新发展若干措施(2023-2025年)》发布
21.Predibase推出用于微调LLM的SDK
22.李开复说话算数:零一万物大模型首次发布
23.OpenAI 推出专注于创建AI训练数据集的合作伙伴计划
24.HPE、SAP为语言模型开发商Aleph Alpha提供5亿美元轮融资
本周热点
1
企业数据要素与资产运营的建设路径:数据资源化、数据资产化和数据资本化,星环科技技术助力成功
从技术上拆解数据要素价值的生成路径,企业数据要素与资产运营的建设路径可分为三个典型的阶段:数据资源化、数据资产化和数据资本化。
第一阶段是做好数据治理和安全,使企业有数据产品用并且能够管理起来。企业可以利用星环科技推出的数据安全管理平台Defensor完成数据分类和合规检查的工作,实现自查自纠并向监管单位提供合规检查报告。
第二阶段进入流通阶段,基础设施组成部分包括:隐私计算、沙箱、数据资产登记以及数据流通之后,跨境数据的统一安全管控。星环科技拥有自己的隐私计算平台,并协助各个数据交易所进行数据运营体系建设工作,包括数据安全合规和通过大数据平台提供数据加工挖掘等能力。
最后一个阶段比较新,星环科技也在帮助企业做资产目标的试点,包含从资产识别到价值评估到合格审计、持续性盘点等一系列工作。
2
新“局”已定,数据要素市场将迎利好
数字化时代,数据成为继土地、劳动力、资本、技术之后的“第五个关键生产要素”。数据资源凭借其巨大价值,成为推动经济社会发展的重要动力。但同时,数据交易“场外热场内冷”、数据要素市场数据持有权、使用权、经营权不明晰等问题阻碍着数据要素的高质量发展。
10月25日,国家数据局正式挂牌成立。多位受访专家表示,国家数据局的成立恰逢其时,意义深远。这将进一步加快全国统一、辐射全球的数据大市场的建设,推动数字经济加速发展。
影响将包括充分激活数据要素潜能,全链条管理的产业生态体系将逐步形成,激发数实融合新动能等。
3
国家“数据要素市场”相关政策要点解析
数据要素作为数字经济时代关键生产要素,已成为促进数字技术与实体经济深度融合、推动数字经济高质量发展的核心引擎。
近年来,国家顶层设计持续加码,数据要素市场建设重视程度加速走高。为进一步了解我国数据要素市场建设的宏观政策导向以及潜在发展机遇,大数据团队整理形成国家层面推动数据要素改革、促进数据要素市场高质量发展的政策亮点,以飨读者。
4
千亿已成标配,北京启动数据要素先行区
11月10日,北京正式启动数据要素基础制度先行区,邀请了国家数据局局长刘烈宏首次公开发表国家数据要素方面的顶层设计。
在本次活动上,北京市计划到2030年,完全建成数据基础制度先行区,打造数据要素市场化配置的政策高地、可信空间和数据工场,数据产业规模超1000亿元。
北京数据先行区总体规划面积68平方公里;共有18个数据要素相关的产业园区;共有4.57万家市场主体,其中数据要素类重点企业30家;产业可利用面积约261.7万平方米。从功能布局上看,将在北投台湖产业园建设数据先行区管理服务中心,在信创园建设智能算力中心和数据训练基地,在演艺小镇图书城改造项目等地布局数据总部基地。
在相关部门的共同推动下,北京数据基础制度先行区建设工作办公室、北京公共数据开放创新基地、北京公共数据资产登记中心、北京社会数据资产登记中心、北京数据资产评估服务站、北京数据跨境服务中心等一系列数据服务窗口正式入驻数据先行区,首信云技术有限公司、北京国际算力服务有限公司等10家数据要素市场主体已率先在数据先行区落地。
到2030年,完全建成北京数据先行区,打造数据要素市场化配置的政策高地、可信空间和数据工场,汇聚高价值数据资产总量达到100PB,数据交易额达到100亿元,数据产业规模超过1000亿元,打造“2+5+N”的数据先行区基础架构。
2是数据先行区基础设施层,包含智能算力基础设施和国家区块链网络枢纽;
5是数据先行区业务中台层,包含数据资产登记平台、数据资产评估平台、数据资产托管平台、数据交易节点、数字资产管理平台等;
N是数据应用层,即金融数据、政务数据、“三医”数据、自动驾驶数据、航运贸易数据、文旅数据等数据专区与应用。
大数据
5
数据治理、反欺诈、风险预警、反洗钱···星环科技入选“中国银行业人工智能与大数据市场图谱”
近日,沙丘社区发布《2023中国银行业人工智能与大数据用例分析报告》,凭借在大数据与人工智能领域的技术优势,以及深耕金融领域多年的成功经验,星环科技入选该报告《中国银行业人工智能与大数据市场图谱》“数据治理”、“反欺诈”、“风险预警”、“反洗钱”多个板块。
报告指出,银行是最早应用人工智能与大数据技术的领域之一,目前已在多个业务场景实现落地并取得不错的应用效果。星环科技致力于打造企业级大数据基础软件,围绕数据全生命周期提供基础软件与服务,已形成大数据与云基础平台、分布式关系型数据库、数据开发与智能分析工具的软件产品矩阵。星环科技深耕金融领域多年,有着完善的产品、解决方案和丰富的落地经验,能够深度赋能银行业数智化转型。
6
清雁科技发布企业数据资产入表一站式服务平台!
为协助企业合规高效管理数据资产,保障数据资产合规入表,清雁科技正式推出“企业数据资产入表一站式服务平台”。
清雁科技由清华大学和北京雁栖湖应用数学研究院联合孵化,集产学研为一体,依托顶级科研团队,一直深耕于数据资产管理和数据要素流通的理论、技术及应用场景。此次发布的“企业数据资产入表一站式服务平台”,遵循财政部印发的《企业数据资源相关会计处理暂行规定》,并基于清雁科技在数据资产化领域积累的研究成果和实践经验,为企业数据资产纳入财务报表提供全面解决方案。
企业数据资产入表一站式服务平台支持私有化部署和SAAS模式两种使用方式,为企业提供入表、界权、披露、合规、估值服务。平台融合了数据资源录入、数据资产规划、成本归集、数据资产台账、导出披露报表等全流程的数据资产管理能力,以及数据看板、资产估值、合规提示等一系列工具,帮助企业在数据资源初始计量和后续计量过程中实现降本增效,保障数据资源合规入表。
7
三大数智产品升级发布,网易数帆夯实数智生态方法论“根基”
网易数帆在大会上带来了轻舟云原生平台2.0、指标中台EasyMetrics和CodeWave智能开发平台3.0三款数智软件产品的发布与升级,为企业提供了从云原生架构、数据研发运营到低代码开发的全方位解决方案,助力企业实现高质量的数字化、智能化发展。
轻舟云原生平台1.0提供了从容器、微服务、服务网格、中间件管理等全面的产品能力,帮助企业实现分布式架构的平滑演进和优化。随着金融企业IT水平的提升,业务系统的复杂性增加,业务稳定和管理问题逐步暴露,轻舟云原生平台2.0应运而生,旨在解决这些痛点。
全新升级的CodeWave智能开发平台3.0在开发门槛、开发效率、企业IT深度融合以及AI辅助编程等方面都进行了重大升级,包括IDE界面、Design组件库、UI设计器、集成中心、智能助手、业务组件和资产中心等,为企业提供了一种全新的软件生产方式。
有别于业界其他指标中台产品,网易数帆指标中台EasyMetrics的核心能力为一次定义、多次复用,通过自动计算根除指标重复开发带来的口径不一致的痼疾,这与Gartner对指标中台的定义高度吻合。目前,指标中台在网易已有成熟实践,更好地解决了指标重复开发带来的指标口径不一致的问题,实现了数据开发平均周期缩短3-5天,开发人力消耗减少30%。
8
ClickHouse牵手阿里云发布阿里云ClickHouse企业版,并启动公测
ClickHouse作为全球流行的开源实时分析数据库,凭借其优异的性能得到了广大开发者和用户的青睐,在国内外有大量全球知名客户在使用ClickHouse。ClickHouse公司牵手阿里云战略合作发布阿里云ClickHouse企业版,并启动公测。
ClickHouse企业版具有非开源的商业化SharedMergeTree引擎,基于存储计算分离的云原生架构,支持完全Serverless使用模式,可以帮助用户降低80%存储成本,50%的计算资源成本。
ClickHouse联合创始人、ClickHouse产品技术总裁Yury Izrailevsky发表了《云数据库ClickHouse企业版发布,产品和最佳实践介绍》演讲,他重申:“ClickHouse将继续保持在实时分析性能方面的领跑优势,当前对比其他分析产品在数据加载场景有37倍左右的性能优势,在查询方面具有20倍以上的性能优势。”
9
阿里云数据库SelectDB版发布!提供极速实时、融合统一、简单易用的云上数仓服务
在2023年云栖大会上,作为阿里云的生态合作伙伴,“飞轮科技”正式对外发布了云原生全托管产品——“阿里云数据库 SelectDB 版”,通过深度融合云随需而用的特性,构建起云原生存算分离的全新架构,面向企业海量数据的实时分析需求提供极速实时、融合统一、简单易用的云上数仓服务。
随着“阿里云数据库 SelectDB 版”的全面公开,企业用户也能够更加深度地体验到产品的以下特性,为用户行为与画像分析、日志管理与分析、实时报表与实时决策、交互式探索分析等场景实现提升:
·实时分析:充分满足企业大规模实时数据上的极速查询需求。通过创新的技术优化实现秒级的数据实时导入与实时存储;在高并发点查、大宽表查询、多表 Join 查询、增量 ETL 等多种查询负载上提供优于同类产品的极速性能。
·融合统一:为企业提供更加彻底的湖仓融合能力。能够作为高效的联邦查询引擎从各类数据湖和异构数据源进行联邦分析,也能够作为开放的数据湖格式被其他引擎快速、高效地读取。
·云原生化:提供全新云原生存算分离架构的弹性计算、负载隔离和数据共享,为企业实现极致性价比。
数据库
10
开源图数据库gStore 1.2版本正式上线,体验再度升级!
gStore是由北京大学王选计算机研究所邹磊教授团队研发的,面向RDF知识图谱的开源图数据库系统。11月11日,gStore 最新1.2版本正式上线发布。
新增功能包括:
·精简 ORDER BY 执行逻辑、去除不必要的类型判断和转换,大幅提升执行效率。
·优化构建模块:支持构建空库。
·优化三元组解析器:支持纯数字IRI,支持由数字和字母组成的IRI,以及以数字开头的IRI。
·新增API接口:gStore 1.2版本的ghttp和gRPC服务增加了上传文件、下载文件、统计系统资源、重命名、获取备份路径5个接口。
·gStore 1.2版本新增了7个高级函数,分别是单源最短路径(SSSP、SSSPLen)、标签传播(labelProp)、弱连通分量(WCC)、整体/局部集聚系数(clusteringCoeff)、鲁汶算法(louvain)、K跳计数(kHopCount)、K跳邻居(kHopNeighbor)等。
11
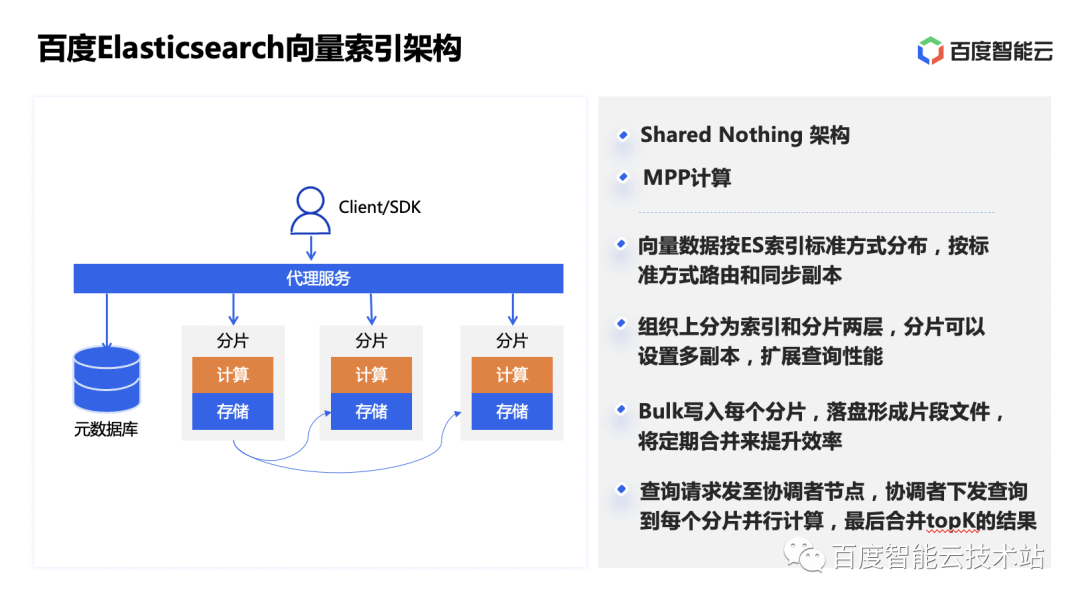
百度给给Elasticsearch 加上向量检索能力,支撑大模型场景需求
Elasticsearch 是一个基于 Apache Lucene 的分布式的搜索与分析引擎,在搜索引擎数据库领域排名第一。百度智能云 Elasticsearch(BES) 是基于开源 Elasticsearch 构建的成熟的公有云产品,拥有云上的资源保障和运维能力。2023 年,BES针对向量检索的场景,从向量引擎、套餐资源等各方面进行了优化,以便满足大模型的场景需求。
BES 的架构由管控平台和 BES 集群实例两部分组成。管控平台是全局层面来进行统一的集群管理,监控报警,以及集群扩缩容、冷热分离调度的平台。BES 集群实例则是一套构件在云主机和云磁盘上面的 Elasticsearch 集群服务,前面通过 BLB 四层代理做节点负载均衡。磁盘上的数据可以通过策略定期下沉存储到对象存储 BOS 上,降低存储成本。
12
柏睿向量数据库基于RapidsDB实现安全高效的向量存储
面向AI大模型时代,柏睿数据打造向量数据库Rapids VectorDB。目前Rapids VectorDB已经在企业智能知识库等场景落地应用。
Embedding (向量嵌入)通过将高维度的原始数据(如文字、图片、音频等)映射到低维度的向量空间,从而将半结构化、非结构化数据转化向量形式,其中每个向量元素通常代表特定的特征或属性。
向量数据类似于数字序列,这种类型的数据存储是传统数据库的强项。柏睿数据具有完全自主知识产权的新一代分布式全内存数据库RapidsDB在这方面具有显著优势。
因此,柏睿向量数据库Rapids VectorDB采用RapidsDB作为向量存储模块。基于成熟丰富的数据管理经验,RapidsDB可为高性能向量检索和相似性搜索提供灵活高效、安全可靠的向量存储服务。
13
Monte Carlo推出矢量数据库的数据可观测性
数据可观测性专家Monte Carlo公布了旨在确保数据质量的新功能,包括与矢量数据库和Apache Kafka的集成。
数据可观测性是在数据从引入到分析的整个管道中监视数据的过程,以确保用于为决策提供信息的数据准确且最新。
当组织仅从少数来源收集数据并将其数据存储在本地数据库中时,数据可观测性相对简单。然而,现在,组织从无数来源收集数据,因此数据本身在结构上可能大相径庭,并存储在多个位置。
因此,随着数据的质量监控变得越来越困难,总部位于旧金山的蒙特卡洛和 Acceldata 等供应商现在专注于数据可观测性。
除了集成之外,Monte Carlo还推出了性能监控(Performance Monitoring)和数据产品仪表板(Data Product Dashboard),前者可以使用它来发现数据管道中的低效率问题,后者使用户能够跟踪数据产品(包括人工智能和机器学习模型)的可靠性。(techtarget.com)
14
MongoDB推出Atlas for Retail,一个合作伙伴生态系统计划
MongoDB推出了MongoDB Atlas for Retail,这是一套新的行业特定计划和合作伙伴关系,旨在使零售企业能够在供应商的数据库平台上更好地开发相关数据产品。
此外,MongoDB还推出了MongoDB合作伙伴生态系统目录,使客户能够访问供应商的合作伙伴网络以及这些合作伙伴提供的许多数据产品。
Atlas 是 MongoDB 的开发者平台。11 月 7 日,Atlas for Retail 和合作伙伴生态系统目录在 MongoDB.local Paris 期间公布,这是一场面向法国客户的面对面活动。
MongoDB 总部位于纽约市,是一家数据库供应商,其 NoSQL 数据库提供了传统关系数据库的替代方案。(techtarget.com)
数据安全
15
《中国网络安全产业分析报告 (2023年)》全文发布,10个发展热点值得关注
《中国网络安全产业分析报告(2023年)》由中国网络安全产业联盟(CCIA)发布,中国电子技术标准化研究院、数说安全提供研究支持。
近年来,《网络安全法》《数据安全法》《个人信息保护法》《关键信息基础设施安全保护条例》等一系列法律法规和政策文件相继颁布实施,构建起网络安全政策法规体系的“四梁八柱”,网络综合治理体系基本建成;网络空间国际话语权和影响力明显增强,网络强国建设迈出新步伐;网络产品和技术服务层出不穷,产业规模持续增长,产业综合实力不断提高。但与此同时,我国网络安全在技术、资源、人才、管理等方面与发达国家相比差距较大,仍存在自主创新不足、网络安全防护技术体系尚不健全等问题。
截至 2023 年上半年,我国共有 3984 家公司开展网络安全业务,同比增长 22.4%,其中,服务型企业数量同比增长 32.5%,是网络安全企业数量增长的主要来源。据国内网络安全主要企业调研数据分析显示, 2022 年,我国网络安全市场规模约为 633 亿元,同比增长 3.1%。
报告从网络安全技术、服务和治理三个维度,重点列举了 10 个发展热点,分别是生成式人工智能、人工智能对抗攻防技术、量子安全技术、云原生安全、网络安全保险服务、安全审计和合规性服务、网络安全防护有效性验证服务、云密码服务、数据安全治理,以及软件供应链安全治理。
16
瑞数信息发布新一代数据安全防护体系,守住数据安全最后一道防线
网络安全创新厂商瑞数信息打造了数据备份和快速恢复备份数据的数据安全检测与应急响应系统(DDR)系统。从系统功能层面,瑞数DDR数据安全检测和响应系统重点从事前、事中、事后三个维度来提高数据反勒索的效率:
事前数据健康体检。“如果备份的数据本身就是不安全的,被破坏过或者是被植入了勒索程序,那备份就是没有意义的。”因此事前阶段,瑞数DDR系统首先会基于创新的“深度内容检测”技术,对企业要处理的文件和数据库进行健康体检,然后再开始备份。
事中智能威胁检测。在对企业关键数据进行备份后,瑞数DDR系统会定期对数据健康情况进行定期的健康体检,持续对异常数据进行检测,确保数据的可信。同时通过数据安全存储和隔离等功能来保证备份数据的安全性,防止恶意软件或黑客对备份数据进行破坏或篡改。
事后快速响应恢复。即便企业遭遇了勒索软件攻击,瑞数DDR系统会基于“智能深度检测引擎”,对勒索软件攻击过程中损毁的数据进行安全检测,找到被勒索病毒感染的数据及感染时间点,协助安全管理人员快速移除勒索软件,找出干净可用的数据,实现分钟级的一键快速恢复。
首个DDR体系的功能架构拥有多项核心创新技术:“智能深度健康监测引擎”;在智能检测引擎部分,瑞数还引入了许多AI技术,去对勒索软件的加密特性进行学习和提取,同时进行数据的预处理和关联分析等一系列自动化检测动作;为了实现更快速的数据恢复,瑞数还基于数据原始格式备份技术搭建了一个数据安全底座。
17
埃森哲通过收购MNEM,扩大网络安全服务能力
埃森哲收购了MNEMO Mexico,这是一家专门从事网络安全管理服务的私营公司。财务条款未披露。
MNEMO Mexico 于 2012 年在墨西哥城成立,拥有 229 名网络安全专业人员和 180 项网络安全行业认证,与主要生态系统合作伙伴合作。该公司的产品组合包括先进的网络防御和响应能力、由生成式人工智能和其他先进技术提供支持的网络情报平台,以及位于墨西哥城的 24/7/365 安全运营中心。其客户群横跨多个行业,包括电信、银行和保险。(nasdaq.com)
AI
18
填补政策量化分析空白,星环科技与中信证券荣获上交所ITRDC行业共研课题一等奖
近日,证券信息技术研究发展中心(上海)(简称ITRDC)发布了2022年度行业共研评审结果,星环科技与中信证券股份有限公司联合申报的《基于多模态知识图谱政策事件驱动的智能投研技术研究与应用》课题荣获ITRDC 2022年行业共研课题一等奖。
星环科技获奖的联合课题围绕“基于多模态知识图谱政策事件驱动的智能投研技术研究与应用”这一主题,运用知识图谱、自然语言处理、图算法、量化投研工程技术,构建了“政策-新闻-产业链知识图谱-个股”舆情市场量化一体化体系,实现了基于产业链知识图谱的政策实时推理功能,完成了影响因子传播算法的自研,最终设计了基于多模态知识图谱的政策事件驱动投研方案,并在中信证券投研魔方平台完成落地上线,实现了产研结合。
《基于多模态知识图谱政策事件驱动的智能投研技术研究与应用》课题创新性体现在三个方面:
首先,充分利用知识图谱、自然语言处理、图传播算法和量化投研工程等多项技术,对政策新闻进行解析、传播推理并实际作用到市场端,是国内利用多模态技术进行量化投研的先创之一;
其次,基于独创性的政策事件驱动投研方案,做到了实时的量化因子挖掘,解决了行业痛点,满足了市场参与者对于政策量化分析的需求,填补了行业空白。
最后,自研影响因子传播算法考虑产业链传播的时序性,结合属性图进行传播算法设计,并按照拓扑关系进行排序,让结果更加客观,符合实际。该算法具有场景通用性,已复制到基于企业关联图谱的风险传播等其他场景中。
19
比尔·盖茨:5年内每个人都将拥有一位人工智能驱动的个人助理
https://www/AI-agents
比尔·盖茨(Bill Gates)预测,在5年内,每个人都将拥有一位人工智能驱动的个人助理,无论他们是否在办公室工作:“它们将彻底改变我们的生活方式”。
巧合的是,星环科技创始人、CEO孙元浩在5月的新品发布会上就提出,让每个人都拥有个性化的AI助理,每个企业和行业都打造自己的专属大模型,数据处理平民化让人人成为数据科学家。
比尔·盖茨观点还包括:
·开发人工智能和人工通用智能一直是计算机行业的伟大梦想。
·人工智能的崛起将使人们有更多的时间去做软件永远无法做到的事情,如教学、照顾患者和支持老年人等。
·在未来5到10年内,由人工智能驱动的软件将最终实现革命性地改变人们教学和学习的方式。
·像大多数发明一样,人工智能可以用于善良的目的或恶意的目的。
·我们应该记住,我们只是在人工智能可以实现的开始阶段。无论它今天有什么限制,它都将在我们不知不觉中被消除等。(gatesnotes.com)
20
《上海市推动人工智能大模型创新发展若干措施(2023-2025年)》发布
为推动上海大模型创新发展,营造通用人工智能创新生态,加快打造世界级人工智能产业集群,《上海市推动人工智能大模型创新发展若干措施(2023-2025年)》发布。
文件提出,重点支持在智能制造、生物医药、集成电路、智能化教育教学、科技金融、设计创意、自动驾驶、机器人、数字政府等领域构建示范应用场景,打造标杆性大模型产品和服务。推动大模型赋能产业互联网平台应用。
鼓励浦东新区、徐汇区等建立大模型生态集聚区,聚焦大模型研发和产业化加大支持力度;鼓励自贸区临港新片区探索大模型相关国际交流合作。优先推荐大模型创新重点人才纳入国家和本市相关高层次人才计划,重点支持大模型相关紧缺技能人才落户。组织企业、高校、科研机构联合培养跨学科大模型人才。
21
Predibase推出用于微调LLM的SDK
Predibase 推出了一个软件开发工具包 (SDK),用于高效微调和服务大型语言模型 (LLM)。它声称它将大大提高训练速度,降低部署成本和复杂性。同时,该公司发布了使用 Nvidia A100 GPU 的 Predibase AI Cloud。它指出,这将有效地训练最大的开源 LLM。
Predibase声称:特定任务模型的训练速度提高了 50 倍;部署成本降低 15 倍。
为了实现这一目标,Predibase表示有许多新的创新。它在公告中提到了三个:
·自动内存效率微调:压缩任何开源 LLM,使其可在商用 GPU(如 Nvidia T4)上训练。它建立在用于声明式模型构建的开源 Ludwig 框架之上。然后,Predibase 使用其他设置来允许在可用硬件上进行训练。
·无服务器大小合适的训练基础结构:内置编排逻辑使用云中最具成本效益的硬件来运行每个训练作业。
·为微调模型提供经济高效的服务:LLM 部署可以随流量而扩展和缩减。动态服务的 LLM 可以与数百个其他专门的微调 LLM 共同部署。 Predibase 表示,与专用部署相比,这可以降低 100 倍以上的成本。重要的是,LLM 不需要自己单独的 GPU。(enterprisetimes.co.uk)
22
李开复说话算数:零一万物大模型首次发布
李开复带队创办的 AI 2.0 公司零一万物,开源发布了Yi系列模型,包含 34B 和 6B 两个版本。
令人惊艳的是,从参数量和性能上来看,Yi-34B 相当于只用了不及 LLaMA2-70B一半、Falcon-180B五分之一的参数量,碾压 了LLaMA2-70B 和 Falcon-180B 等众多大尺寸模型。凭借这一表现,跻身目前世界范围内开源最强基础模型之列。
根据 Hugging Face 英文开源社区平台和 C-Eval 中文评测的最新榜单,Yi-34B 预训练模取得了多项 SOTA 国际最佳性能指标认可,成为全球开源大模型「双料冠军」。这也是迄今为止唯一成功登顶 Hugging Face 全球开源模型排行榜的国产模型。
零一万物创始人及CEO李开复博士表示:「零一万物坚定进军全球第一梯队目标,从招的第一个人,写的第一行kl代码,设计的第一个模型开始,就一直抱着成为‘World's No.1’的初衷和决心。」
从「AI 1.0」迈向「AI 2.0」,李开复说话算数,一步步向目前迈进。
23
OpenAI 推出专注于创建AI训练数据集的合作伙伴计划
OpenAI LP 今天宣布了一项新计划,即 OpenAI 数据合作伙伴关系,通过该计划,它将从其他组织收集记录以创建人工智能训练数据集。
训练文件的质量直接影响它们用于构建的神经网络的可靠性。数据集的相关性越高,神经网络就越能准确地回答用户的问题。创建高质量的数据集通常是一个耗时且昂贵的过程,这可能是 OpenAI 寻求外部组织帮助的原因之一。
该公司新合作伙伴计划的一个目标是组装可用于训练其基础模型的私有数据集。此外,OpenAI 将利用这些记录进行模型定制。在上周的DevDay产品活动中,该公司推出了一个程序,允许企业通过“修改模型训练过程的每一步”来定制GP-4以满足他们的要求。
该计划的另一个目标是创建一个开源的人工智能数据集,供开发人员免费使用。根据OpenAI的说法,该数据库将专门针对语言模型项目。该公司补充说,它可能会考虑使用存储库中的文件来构建和发布开源人工智能模型。
OpenAI 已经提供了一系列开源神经网络。该系列的两个最新成员 Whisper large-v3 和 Consistency Decoder 在上周的 DevDay 活动中首次亮相。他们分别专注于转录和图像生成任务。(siliconangle.com)
24
HPE、SAP为语言模型开发商Aleph Alpha提供5亿美元轮融资
专注于开发大型语言模型的德国初创公司 Aleph Alpha GmbH 宣布已经完成了价值超过 5 亿美元的 B 轮融资。HPE、SAP SE和其他几家机构投资者也参与其中。
Aleph Alpha 提供了一个名为 Luminous 的大型语言模型系列,其中包含三个神经网络。它们分别具有 130 亿、300 亿和 700 亿个参数。Aleph Alpha 的网站显示,它还计划开发更高级的语言模型,拥有多达 3000 亿个参数。
目前构成 Luminous 系列的三种型号可以处理英语、德语、法语、意大利语和西班牙语的文本,以及将图像作为输入。Aleph Alpha 说,他们适合完成各种任务,从文本生成到按主题对文档进行排序。该公司通过应用程序编程接口提供其语言模型,开发人员可以将其集成到他们的软件中。
Aleph Alpha 的所有三个模型都带有内置的 AI 可解释性工具。据该公司称,该工具可以帮助客户确保模型可靠地处理他们的数据。(siliconangle.com)

扫码关注我们
END
