




https://llmrecsys.github.io/
推荐系统的应用
推荐系统已经成为当今科技领域中不可或缺的一部分,广泛应用于电子商务、社交网络、新闻推送、搜索引擎、导航系统、旅行规划、专业网络、医疗保健和在线教育等领域。

如在电子商务领域,推荐系统通过分析用户的购物历史、浏览行为和兴趣标签,为用户提供个性化的商品推荐。这不仅提高了用户购物的效率,还促进了销售额的增长。通过深度学习和机器学习算法,推荐系统能够不断优化推荐结果,使其更加符合用户的偏好。
推荐系统的发展
推荐系统技术的发展经历了从浅层模型到深层模型再到大型模型的演进。本文将探讨推荐系统技术的进步历程,从早期的浅层模型,到深度模型的引入,再到如今大型模型的崛起,同时介绍了一些代表性的算法,如矩阵分解、深度宽度神经网络和P5等。
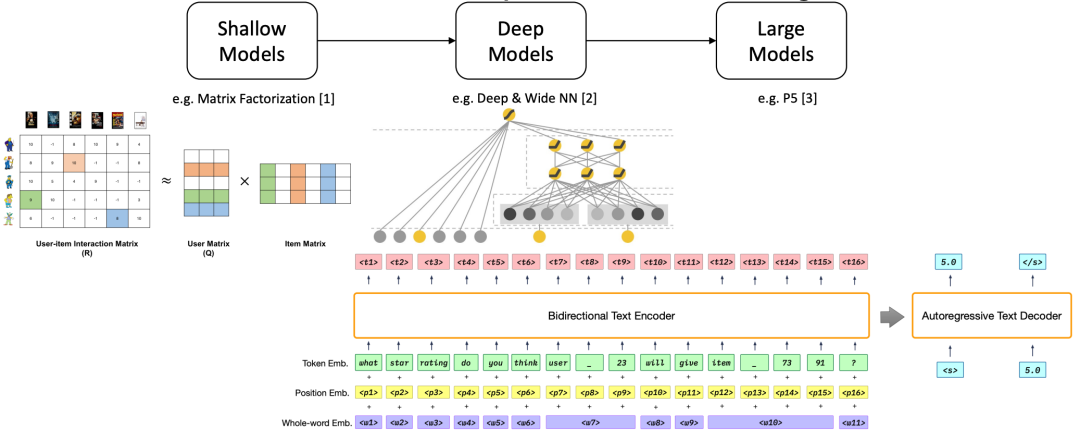
浅层模型
早期的推荐系统主要采用浅层模型,其中代表性的算法是矩阵分解[1]。矩阵分解通过分解用户-物品交互矩阵,将用户和物品映射到潜在的隐空间,从而捕捉用户和物品之间的关系。这种方法简单而直观,但在处理大规模数据和复杂模式时存在一定的局限性。
深度模型
随着深度学习的兴起,推荐系统逐渐引入了深度模型,以更好地挖掘用户和物品之间的复杂关系。深度宽度神经网络[2]是其中的代表之一,通过多层神经网络学习高阶特征表示,提高了模型的表达能力和预测准确性。深度模型的引入使得推荐系统能够更好地适应不同类型的数据和任务。
大型模型
随着计算资源的增加和分布式计算的发展,推荐系统开始采用更大型的模型,以应对日益增长的数据规模和复杂性。P5等大型模型代表了当前推荐系统领域的最新趋势,这些模型通过更深、更宽的网络结构以及更复杂的训练策略,进一步提高了推荐系统的性能和泛化能力。
客观AI与主观AI之比较:以推荐系统为例
在人工智能领域,任务可分为客观AI和主观AI两类。推荐系统作为主观AI的代表,与计算机视觉和自然语言处理等任务相比,更接近人类的思维和感知。

推荐系统在AI任务中与人类思维最为接近。通过分析用户的行为、历史和反馈,推荐系统试图模拟人类的推荐思维过程,致力于为用户提供个性化、符合主观喜好的建议。
推荐系统被视为典型的主观AI。在推荐任务中,不同用户对相同物品可能有不同的偏好,这使得推荐系统需要更灵活的建模和个性化策略,与客观性任务相比更具挑战性。
推荐系统不仅仅是物品排名
推荐系统涉及多种任务,不仅限于物品排名。本文将介绍推荐系统中的多样化任务,包括评分预测、物品排名、顺序推荐、用户档案构建、评论摘要生成、解释生成、公平性考虑等
推荐系统任务的多样性 推荐系统任务丰富多样,包括但不限于:
评分预测 物品排名 顺序推荐 用户档案构建 评论摘要生成 解释生成 公平性考虑等 推荐解释的重要性 推荐系统不仅关注推荐的内容,还注重如何解释推荐决策。与人类推荐类似,解释可以增加用户对推荐的理解,提高用户信任度和接受度。
是否可以同时处理所有推荐系统任务?虽然有多种推荐任务,但是否真的需要设计数千个推荐模型?在工业生产环境中,整合这么多模型可能会面临困难,因此需要权衡模型数量和集成难度。
工业环境中的挑战 在工业环境中同时处理多个推荐任务存在挑战,包括模型整合、计算资源、数据管理等方面的问题。此外,还需要考虑模型的实时性和可扩展性。
传统推荐系统的概览
传统的推荐系统通常采用多阶段过滤的流程,其中包括判别性排名方法。本文将介绍传统推荐系统的多阶段过滤流水线,以及判别性排名的一些模型和问题。
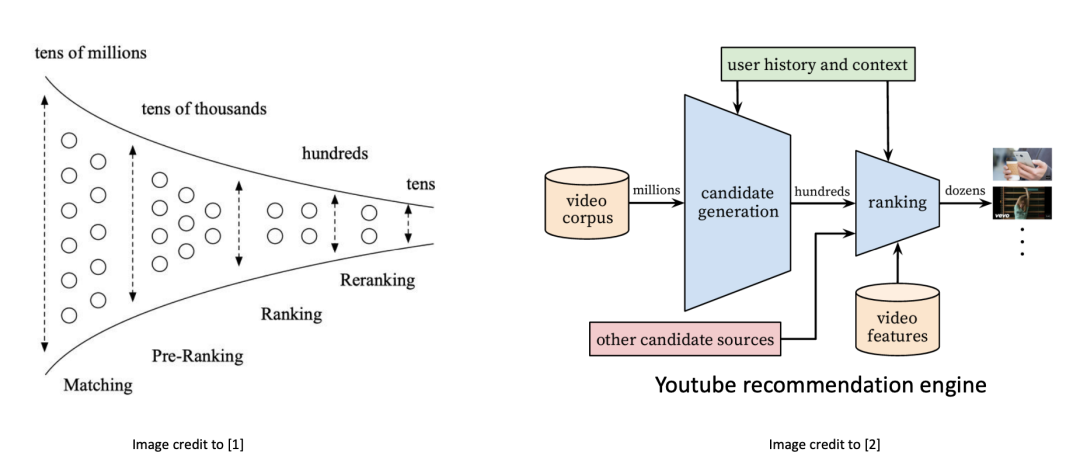
多阶段过滤的推荐系统流水线 传统推荐系统通常采用多阶段过滤的流水线。这一流程包括多个阶段,其中简单规则在初期阶段使用,而高级算法则仅在后期的少数物品上应用。这一策略的原因在于用户和物品数量庞大,例如,亚马逊拥有3亿用户和3.5亿商品,YouTube每月活跃用户超过26亿,视频数量超过50亿。通过多阶段过滤,系统能够更有效地处理大规模数据集,提高推荐效果。
判别性排名方法 判别性排名方法是传统推荐系统中常用的一种技术。该方法基于嵌入(embeddings)进行用户-物品匹配,并采用判别性排名损失函数,例如贝叶斯个性化排名(BPR)损失。这些方法通过学习用户和物品之间的嵌入表示来进行个性化推荐。
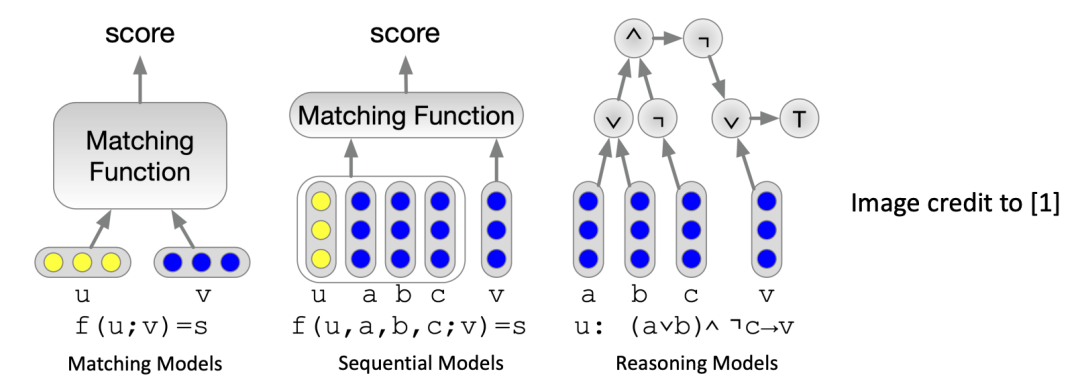
判别性排名的问题 判别性排名方法面临一个挑战,即用户和物品数量庞大。例如,亚马逊和YouTube的庞大用户和物品数量使得在推荐时面临巨大的候选物品集。为了解决这个问题,推荐系统通常采用多阶段过滤策略,但这也导致了评估困难。许多研究论文采用采样评估的方式,例如1/100或1/1000的采样率,以降低评估的计算复杂度。
大模型(LLMs)的应用
大型语言模型(LLMs)通过自回归解码进行生成式预测,实现了生成预训练和预测。LLMs的生成式预测通过Beam Search技术解决了推荐候选生成的问题,实现了从多阶段排名到单阶段排名的过渡。
生成式预测与Beam Search
生成式预训练:使用先前的标记来预测下一个标记。 Beam Search:使用有限的标记表示(几乎)无限数量的项目,通过束搜索(Beam Search)技术解决了推荐候选的生成问题。例如,当使用100个词汇标记,ID大小为10时,候选项目数量为100^10=10^20。 相较于判别性排名,生成式预测中不再需要逐个计算候选分数,而是直接生成推荐的项目ID。
生成式排名
从多阶段排名过渡到单阶段排名,LLMs能够自动考虑所有项目作为候选池的情况。 使用固定大小的项目解码,例如使用100个标记⟨00⟩⟨01⟩...⟨99⟩来表示项目ID。
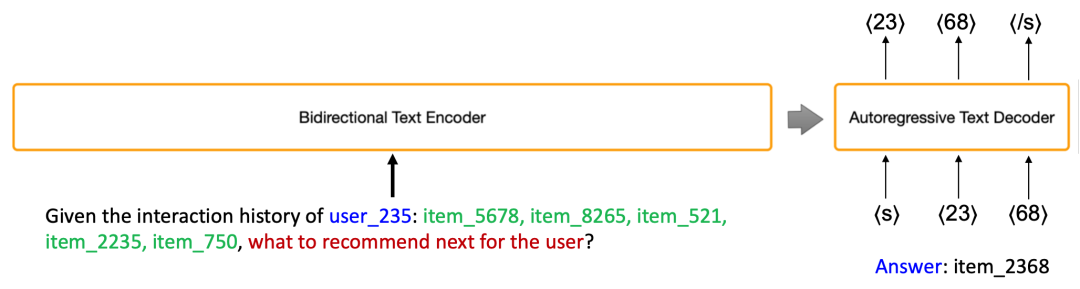
带有束搜索的生成式推荐
由于项目ID被标记化(例如[“item”, “_”, “73”, “91”]),束搜索在宽度上受到限制。 例如,使用100个标记的宽度:⟨00⟩,⟨01⟩,⟨02⟩,…,⟨98⟩,⟨99⟩。 在LLMs中,传统推荐中为项目分配标记的方法不切实际,会占用大量内存并具有计算上的昂贵性。
基于LLM的推荐系统
基于大型语言模型(LLM)包括是否对LLM进行微调、LLM在推荐系统中的角色、典型的推荐任务、以及在生成式推荐中的Beam Search技术。
是否对LLM进行微调
LLM在推荐系统中的角色
典型角色:LLM作为推荐系统的特征提取器 典型角色:基于LLM的代理,其中RecSys作为其中一个工具 典型推荐任务
评分预测、顺序推荐、直接推荐 个性化提示
多任务预训练:P5基于T5检查点进行多任务预训练,使用多个子词单元表示个性化字段
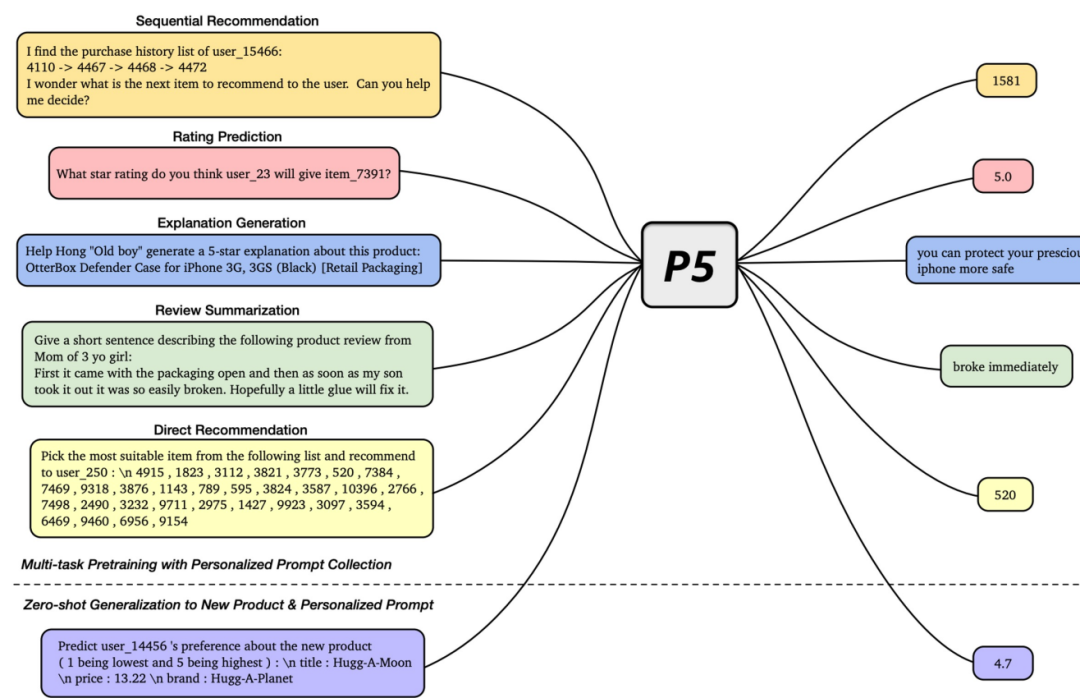
生成式推荐与Beam Search
编码器接收输入序列 解码器自回归生成下一个词 P5通过一种模型、一种损失和一种数据格式统一各种推荐任务 预训练P5的推断:应用束搜索生成潜在的下一个物品列表
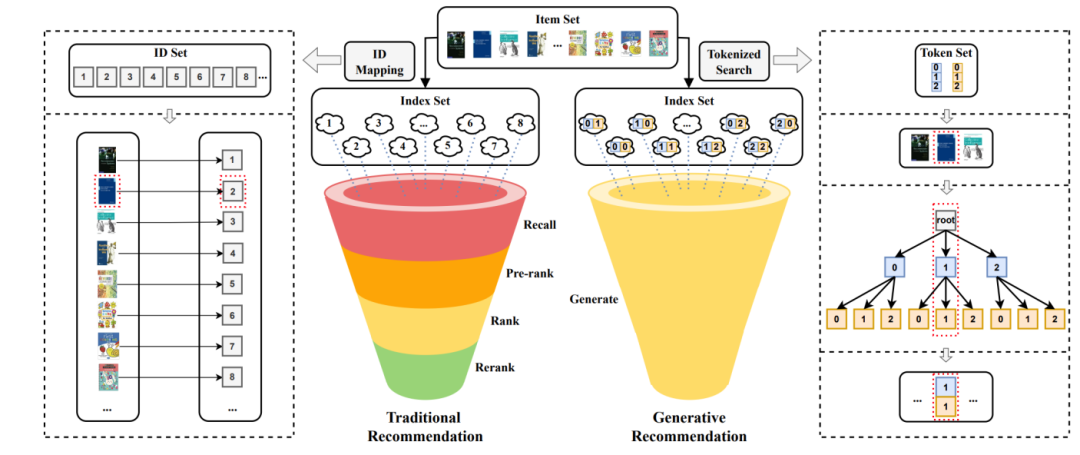
LLM在推荐系统中的微调与角色
在推荐系统中,微调LLM是必要的,因为推荐系统是一个高度专业化的领域,涉及到协作知识。LLM在推荐系统中的角色可以包括作为推荐系统本身、特征编码器、评分函数、排名函数以及管道控制器。
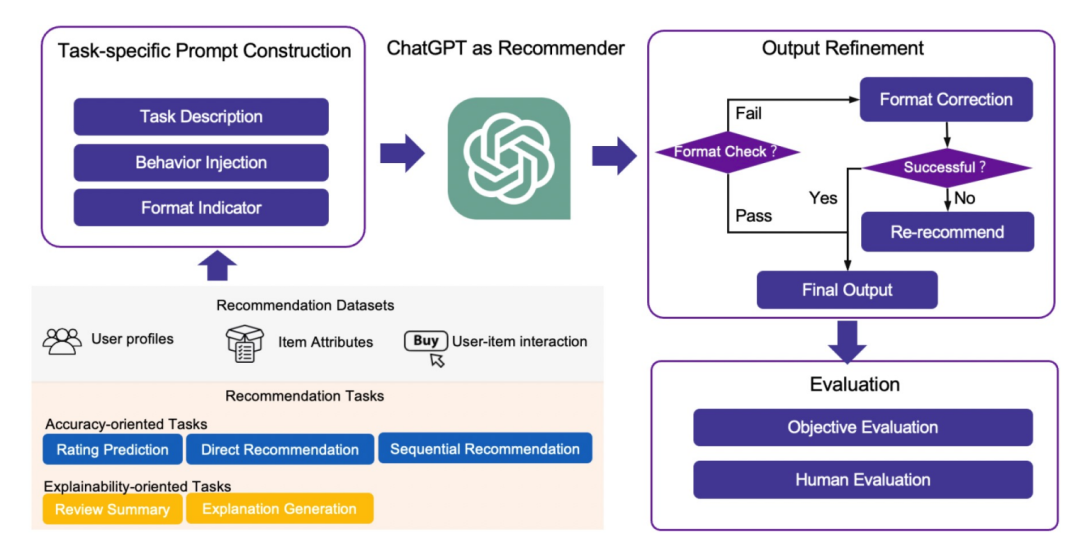
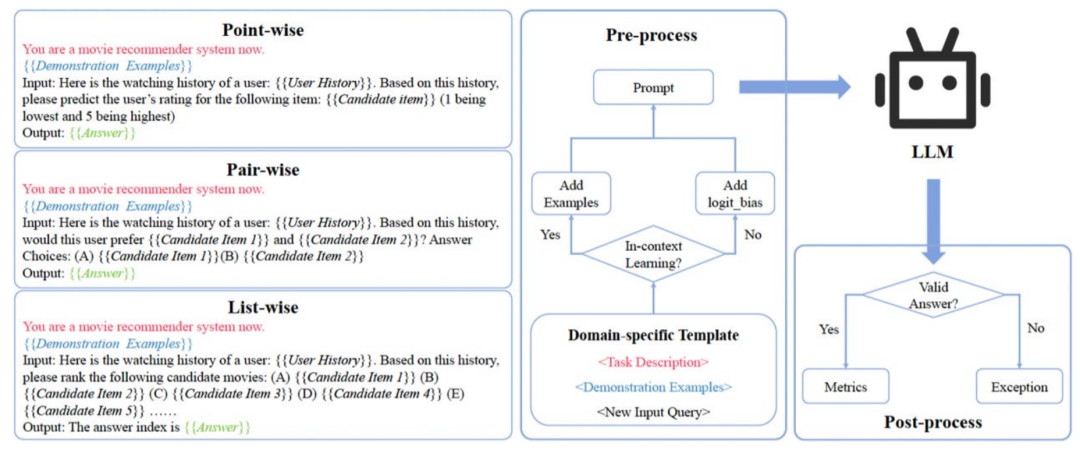
微调与否
不进行微调,LLM难以解决推荐系统问题 推荐系统是一个高度专业化的领域,需要协作知识,而LLM在预训练阶段没有学到这些协作知识 推荐系统的协作知识(如用户行为数据)是高度动态的 相对于自然语言处理(NLP)社区,推荐系统从业者没有像NLP社区那样的存在危机,因为NLP问题在LLM的帮助下可以更容易解决,而推荐系统仍然是一个开放问题,将随着LLM的发展而演进 LLM在推荐系统中的角色
将每个任务分解成几个规划步骤 思考、行动和观察 控制个性化记忆和世界知识 使用工具执行特定任务,例如,任务特定的模型 提供另一个推荐系统生成的候选项,由LLM进行重新排名 指示LLM生成每个物品的二进制评分(喜欢或不喜欢) 与传统的推荐系统一样是判别性的 通过生成物品的标记来将LLM与推荐空间相结合 这些标记再映射到实际物品空间中的实际物品
会话式推荐
会话式推荐中,LLM可以扮演多个不同的角色,包括整个对话推荐系统、对话管理器、排名函数和用户模拟器。评估协议涵盖了推荐和生成两个方面,需要使用多种指标和先进的评估方法,以全面了解系统性能。
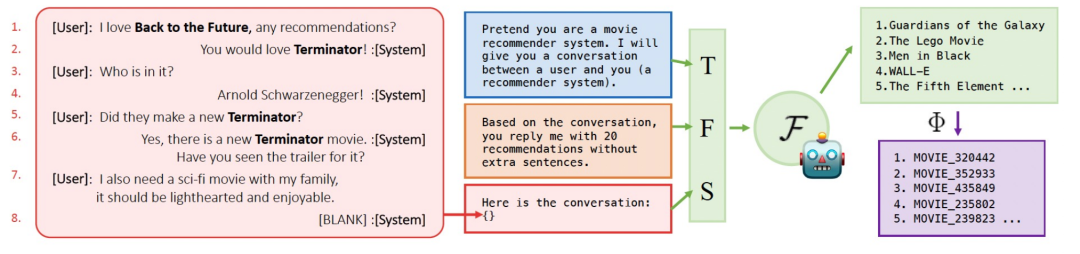
LLM作为整个对话推荐系统
T: 任务描述 F: 格式要求 S: 对话上下文 LLM负责整个会话式推荐系统,考虑任务描述、格式需求和对话上下文。 LLM作为对话管理器
LLM作为对话管理器,负责整合不同类型的信息,包括来自其他模型的推荐和对话历史。 多个LLM扮演不同角色
对话管理器 排名函数 用户模拟器 多个LLM在会话式推荐中发挥不同的作用,担任不同的角色。
物品生成与索引方法
在生成式推荐中,尤其是在生成推荐物品时,面临虚构问题。为了解决这个问题,可以考虑采用物品ID的形式,使得生成和索引变得更加简便。三种朴素的索引方法(随机ID、标题作为ID和独立ID)可以根据具体情况选择,以满足物品可区分、相似物品有相似ID和不相似物品有不相似ID的要求。
LLM生成式推荐范式
希望直接生成推荐的物品 避免逐个计算排名分数 生成的文本可能很长,例如产品描述和新闻文章 生成长文本的困难
回到逐个计算排名的问题! 生成的文本不对应数据库中真实存在的物品 虚构问题 如何计算生成文本与物品文本之间的相似度? 物品ID
数字标记序列 <73><91><26> 单词标记序列 物品ID:物品的短标记序列 易于生成和索引 物品ID可以采用不同的形式 如何索引物品(创建物品ID)
随机ID(RID):物品 ⟨73⟩⟨91⟩,物品 ⟨73⟩⟨12⟩,… 标题作为ID(TID):物品 ⟨the⟩⟨lord⟩⟨of⟩⟨the⟩⟨rings⟩,… 独立ID(IID):物品 ⟨1364⟩,物品 ⟨6321⟩,… 物品可区分(不同物品有不同的ID) 相似物品有相似的ID(ID中共享的标记更多) 不相似的物品有不相似的ID(ID中共享的标记更少) 三个好的物品索引方法的属性 三个朴素的索引方法
顺序、协同与混合索引方法
SID通过利用物品在标记化后共享相似标记的本地共现信息来建立索引。CID则通过基于物品-物品共现矩阵的谱矩阵分解和分层谱聚类来利用全局共现信息。HID是一种混合方法,将多种索引方式拼接在一起,包括随机ID、标题作为ID、独立ID、顺序ID、协同ID和语义ID。文章以实例展示了如何通过HID将语义ID和协同ID组合成混合ID。
顺序索引(SID)
利用物品之间的本地共现信息 在标记化后,共现的物品共享相似的标记 例如,物品1004:<100><4>,物品1005:<100><5>
协同索引(CID)
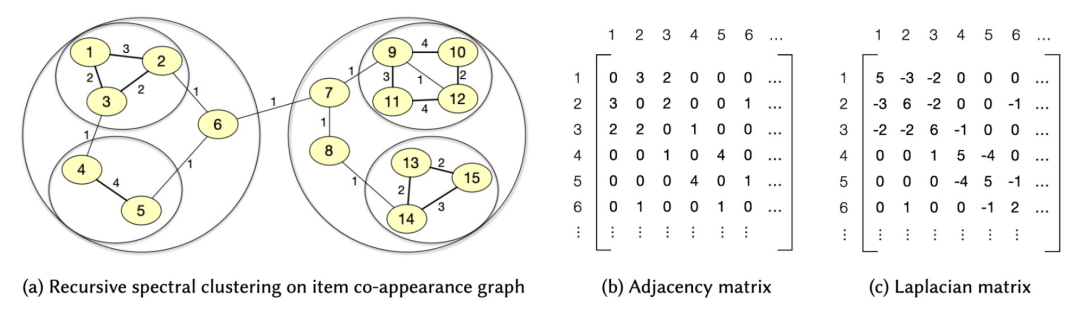
利用物品之间的全局共现信息 基于物品-物品共现矩阵的谱矩阵分解和分层谱聚类
混合索引(HID)
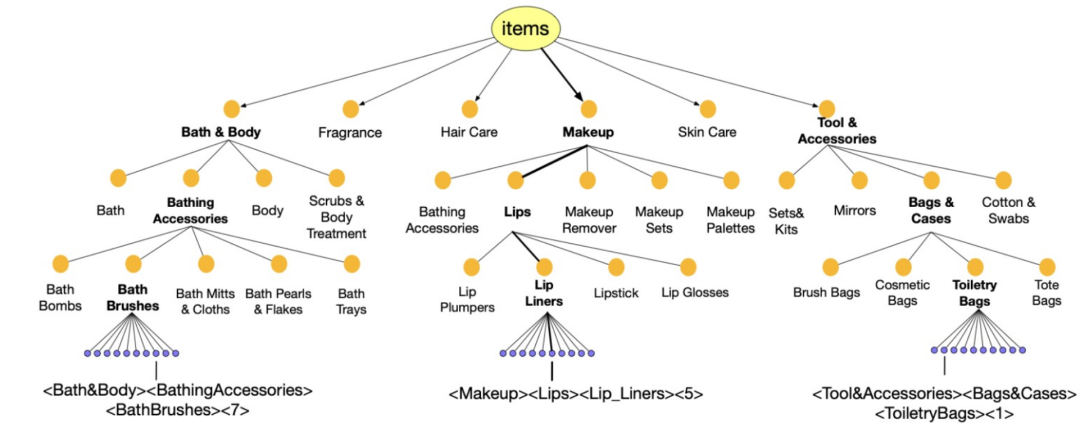
语义ID:⟨Makeup⟩⟨Lips⟩⟨Lip_Liners⟩⟨5⟩ 协同ID:⟨1⟩⟨9⟩⟨5⟩⟨4⟩ 则其混合ID为⟨Makeup⟩⟨Lips⟩⟨Lip_Liners⟩⟨1⟩⟨9⟩⟨5⟩⟨4⟩
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

