




缓冲区管理器位于用户和数据库存储之间,用户进程请求数据块时,由缓冲区管理器从数据库存储层将数据块读取到数据缓冲区提供服务。
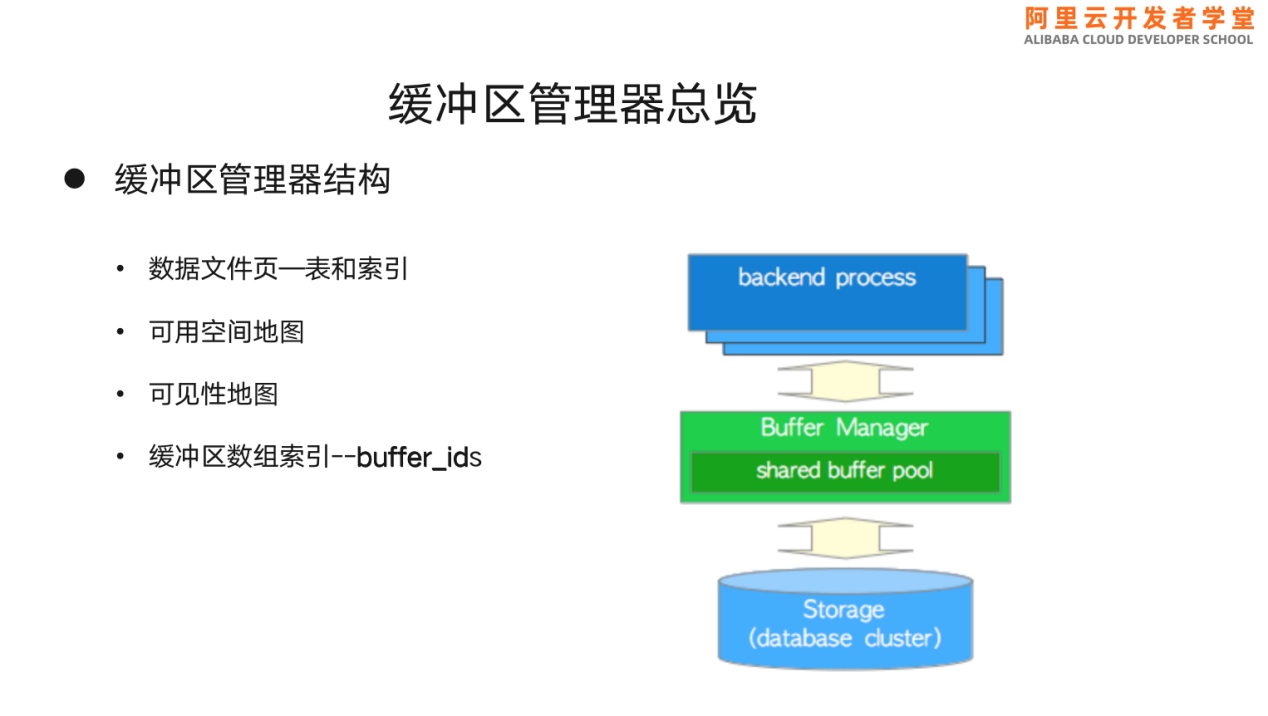
数据缓冲区内存放的是数据块,包含表和索引的块、可用性地图的块、可见性地图的块以及缓冲区索引块。
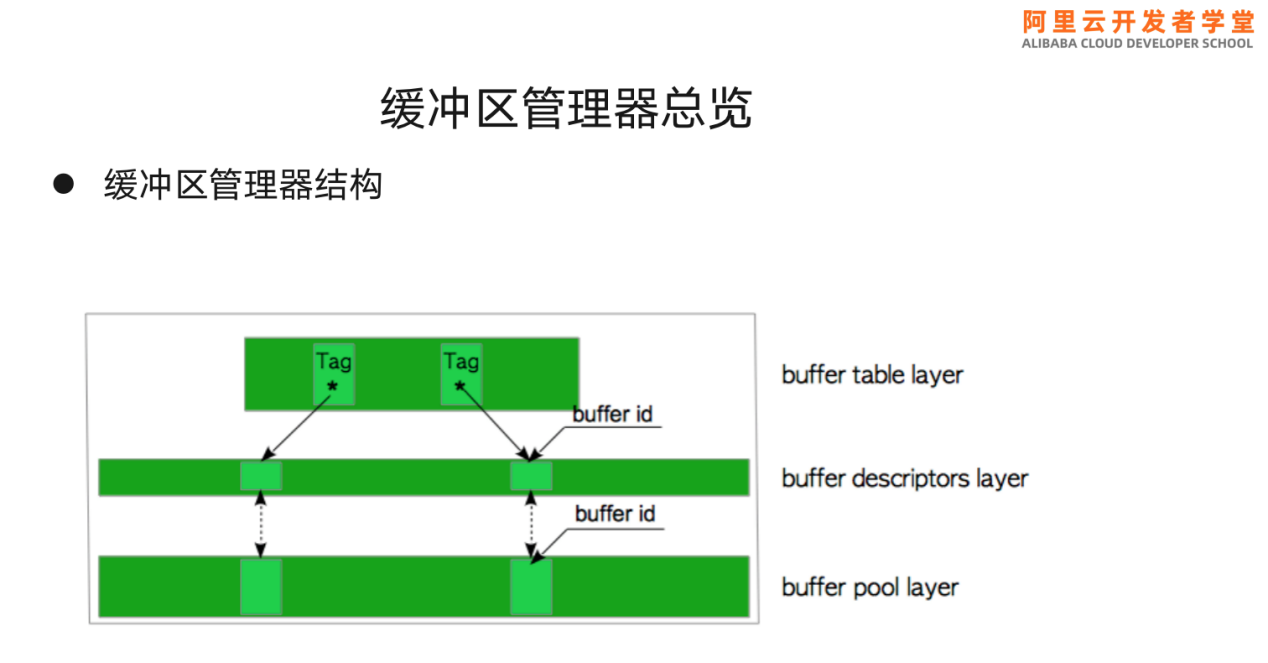
缓冲区管理器分为三层,第一层为缓冲区表层,第二层为缓冲区描述层,第三层为缓冲区池层(负责将数据块从数据文件读到内存)。缓冲区描述层包含大量信息,也是对于管理最重要的一层。
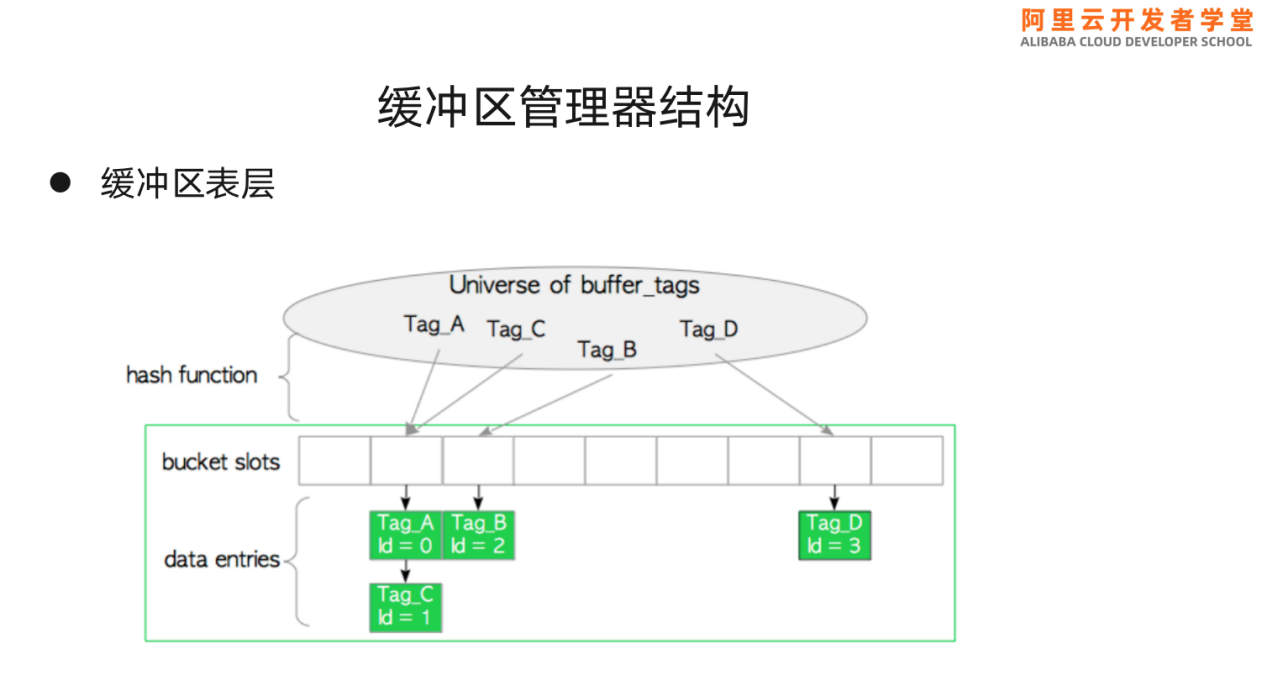
缓冲区表层存在很多插槽,每个插槽里存放了数据块的标记,标记里包含了对于要访问的数据块的描述,比如哪个数据文件的第几个块。每个槽里记录了一个或多个标记。

比如缓冲区标记为{(16821、16384、37721)、0、7},其中16821、16384、37721分别代表对象oid、数据库oid以及表空间oid,0代表页面的fork number,7代表页面number。

将数据块读到数据缓冲区需要记录信息,此类信息存放在描述层。
描述层里包含了缓冲区的tag信息以及buffer_id。PolarDB将缓冲区分为多个大小相同的块,每个块都有自己的buffer_id。
refcount和usage_count用于描述缓冲区被访问的热度。缓冲区被某个进程访问过一次,refcount和usage_count均会+1。与此同时,如果缓冲区被时钟扫描过后refcount-1,refcount=0代表该缓冲区可用。
Flag有三个状态,其中dirty bit代表缓冲区已经被修改过;valid bit代表已经被写到数据文件,当前可用;io_in_progress bit代表正在被进程处理。
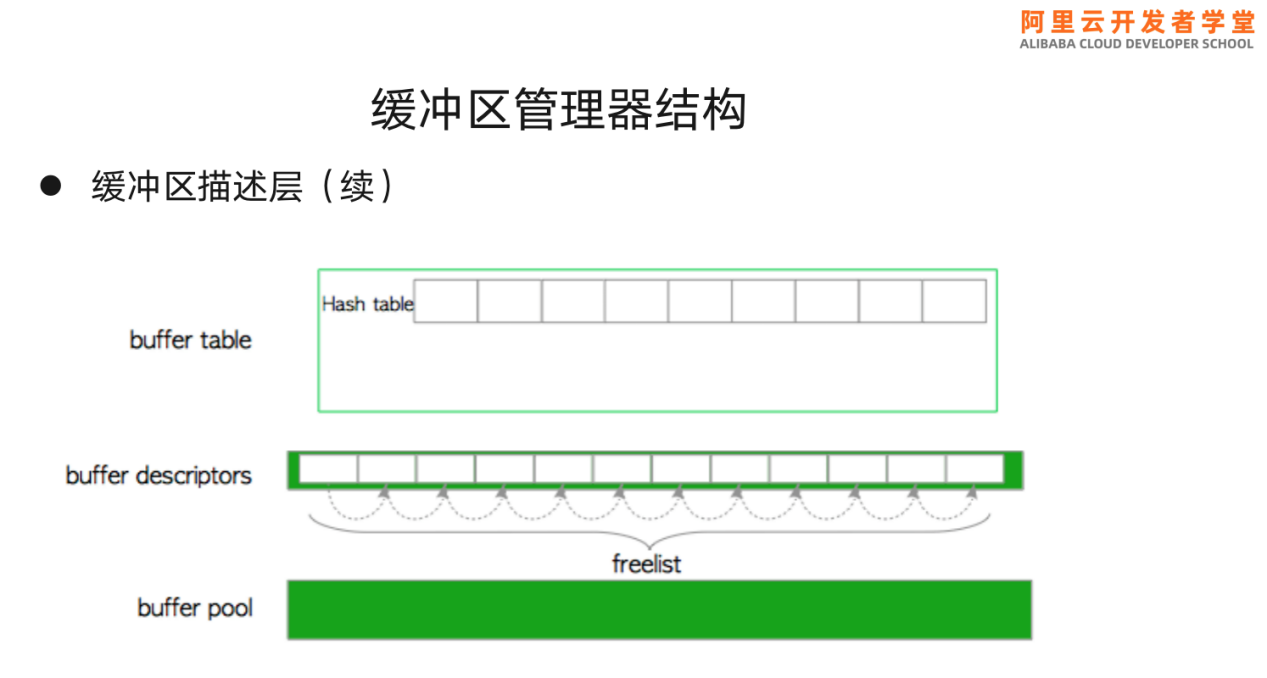
缓冲池层是连接描述层与表层非常重要的一层,它将内存分割为若干个内存块,每个内存块都有一个buffer_id。
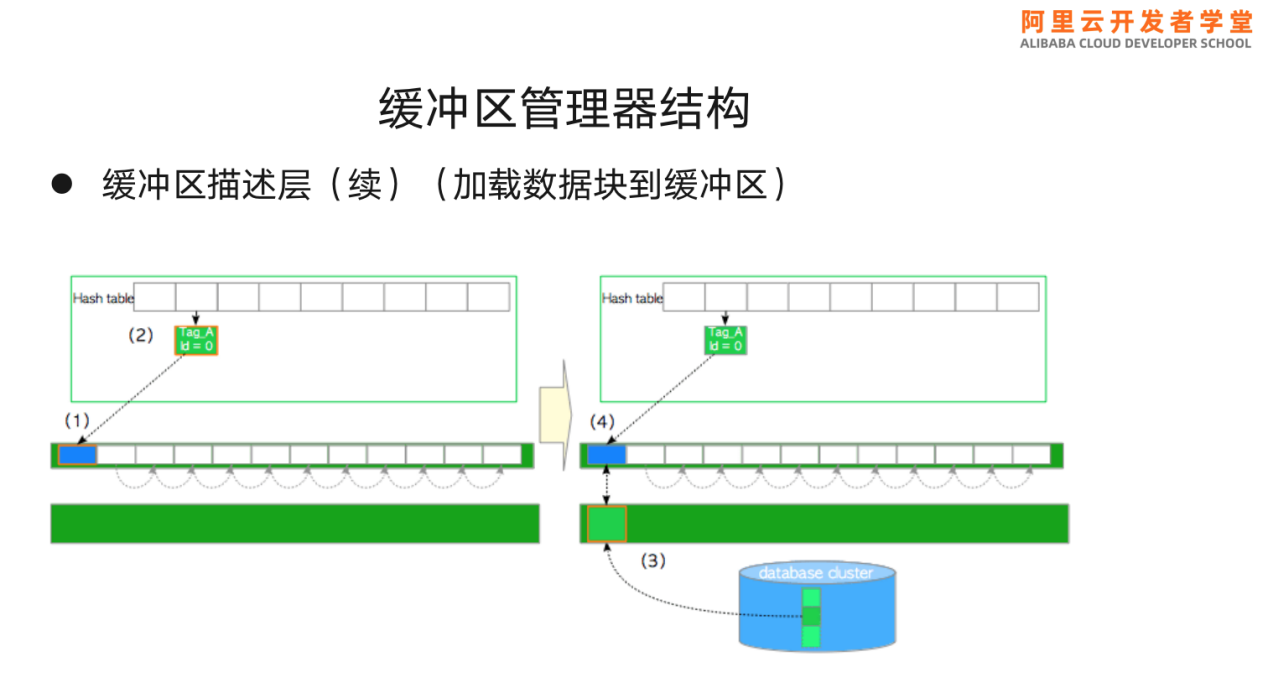
将数据块读取到数据缓冲区的流程如下:首先,发送一个请求,请求到达描述层后分配一个插槽,管理器将数据块的标记记录在描述里,同时从数据缓冲区层申请内存块,将缓冲数据块的标记从数据库读到缓冲区,并发送 Buffer_id,使得块的标记与 Buffer_id的标记能够进行匹配。

假如数据块是8k,则缓冲池会被分割为若干个8k的池槽,正好等于数据块的大小。
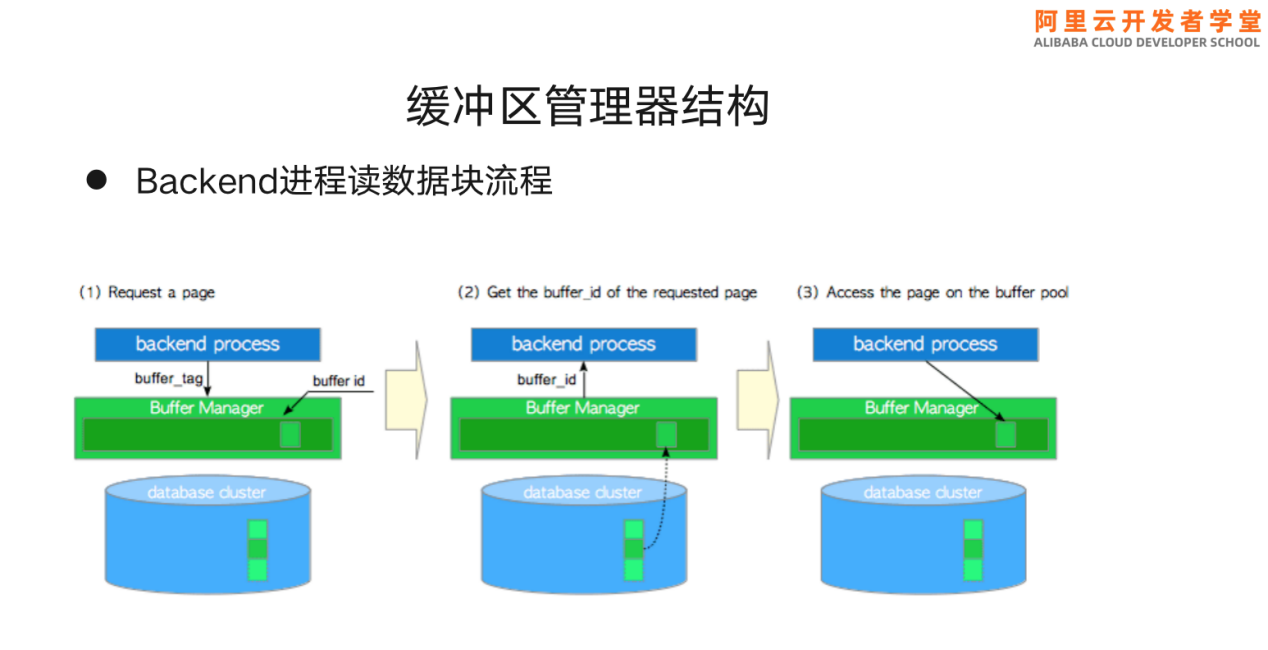
Backend访问数据块时,读取数据的流程如下:
首先,将进程要访问的数据块标记发送给管理器,并由管理器负责寻找当前哪个ID存在可用空间。然后管理器将找到的Buffer_id发送给用户进程并记录到描述层,管理器的后台将数据块读到数据缓冲区。后台进程得到Buffer_id以后,根据Buffer_id找到数据块。
如果下一次要读同样的块,backend进程会将需要访问的buffer tag发送给管理器,管理器扫描该数据块是否曾被访问过。如果有,则查询该数据块当前放在哪个Buffer_id并将Buffer_id发给backend进程,然后进行访问。由于数据块已经存在缓冲区,因此不再需要从磁盘里读数据块。
数据缓冲区的大小固定,无法将整个数据库的数据都存放在内存中,因此数据缓冲区的空间应轮流重复使用,需要做替换。
通常,页面替换的算法有两种,分别为LRU即最近最少使用规则(Oracle使用的算法)以及时钟扫描。
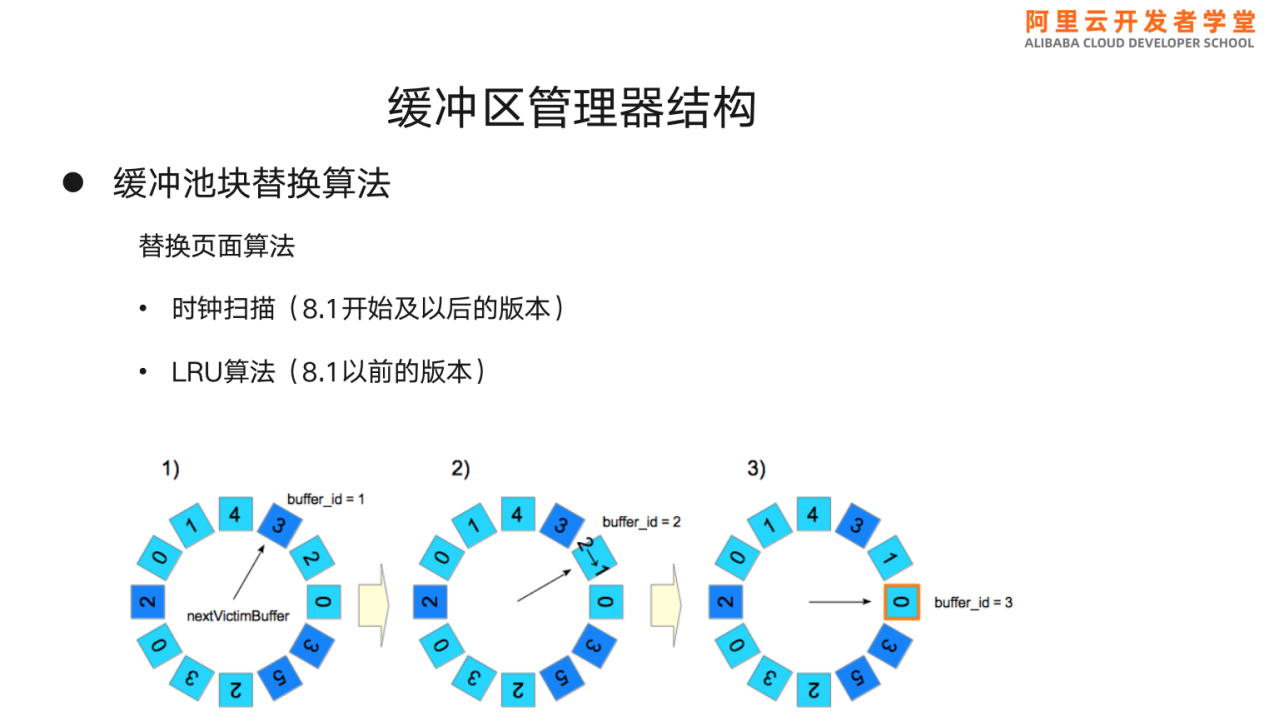
时钟扫描:描述层里通过refcount参数记录了数据块曾经被访问过的次数,进程访问一次则+1,被时钟扫描过一次则-1,以此判断数据块当前的受欢迎程度。如果refcount为0则代表该数据块可用。
如上图,
• 图里时钟指向的数据块refcount=3,则跳过,继续指向下一个数据块。
• 图里指向的refcount=2,对其做-1操作,继续指向下一个数据块。
• 图里指向的refcount=0,代表该块可用,因此可分配给进程使用。
LRU算法和时钟扫描算法的本质都是根据数据块当前被关注的程度来判断其是否可被替换。

数据缓冲区里的数据块被修改以后,会被标识为脏块。PolarDB提供了checkpointer和background writer两个进程用于写脏块。
Oracle也提供了两个进程,但是只由DBWriter负责写脏块,检查点进程只负责向数据缓冲区发信号。

检查点进程会将检查点的记录写到WAL日志文件,再将相应的脏块写到数据文件。写操作属于密集型操作,会影响数据库的性能,因此,此处写的机制为一点一点地刷新脏页,以求对数据库活动的影响最低。
默认情况下,每次写100个数据块,200毫秒写入一次。可理解为缓冲区不断地被修改,又不断地保存。过了一段时间再发检查点时,会将上一次发生检查点到目前为止的所有脏块都写入。

可以通过shared_buffers参数来控制共享缓冲区的尺寸,共享缓冲区内包含数据缓冲区里的内容。可以通过wal_buffers控制日志缓冲区的尺寸。effectiv_cache_size默认为4G,用于告知优化器内核中可用的缓存量,为扫描方式的选择提供参考性意见。
