




OceanBase的索引
索引和分区是数据库的关键核心基本功能,Oceanbase是一个单体分布式的架构,具有高性能、高扩展、高可用的特点,索引和分区立了大功。
Oceanbase的索引有局部索引和全局索引 ,局部索引和全局索引的索引区别在哪里?下面通过实战例子演示如何给Oceanbase做优化。
阅读时注意is_index_back、is_global_index、physical_range_rows、logical_range_rows、Plan type,这是优化的关键参考指标。
- is_index_back表示查询SQL是否已经回表,数值是off是最好。
- is_global_index表示是否已经激活全局索引。
- physical_range_rows表示读取的物理范围行, 数值越小越好
- logical_range_rows表示读取的逻辑范围行, 数值越小越好
- Plan type有3个选项,最优是Local对应本地调用,REMOTE对应远程调用,最坏情况是DISTRIBUTED
建表语句
CREATE TABLE `user1` (
`id` int(11) DEFAULT NULL,
`name` varchar(100) DEFAULT NULL,
`phone` int(12) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL
) partition by hash(id+1) partitions 3;
obclient [tpch]> select count(*) from user1
-> ;
+----------+
| count(*) |
+----------+
| 79993 |
+----------+
1 row in set (0.025 sec)
填充数据
delimiter //
create procedure bulk_user()
begin
declare i int;
declare phone int;
set i=100000;
set phone=1592014273;
while i<1000001 do
insert INTO user (id,name ,phone,address) values (i,'yang',phone+i,'address');
set i=i+1;
end while;
end
//
delimiter ;
场景1:没有加索引
obclient [tpch]> explain extended select phone ,name from user1 where phone = 1592014286;
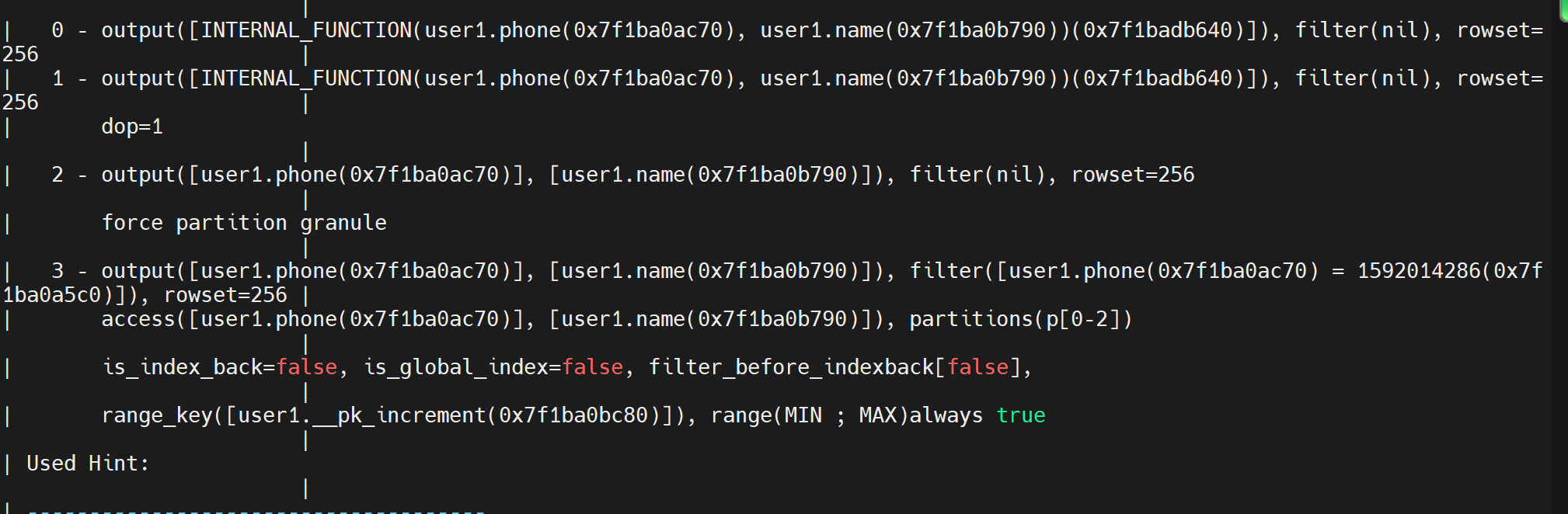
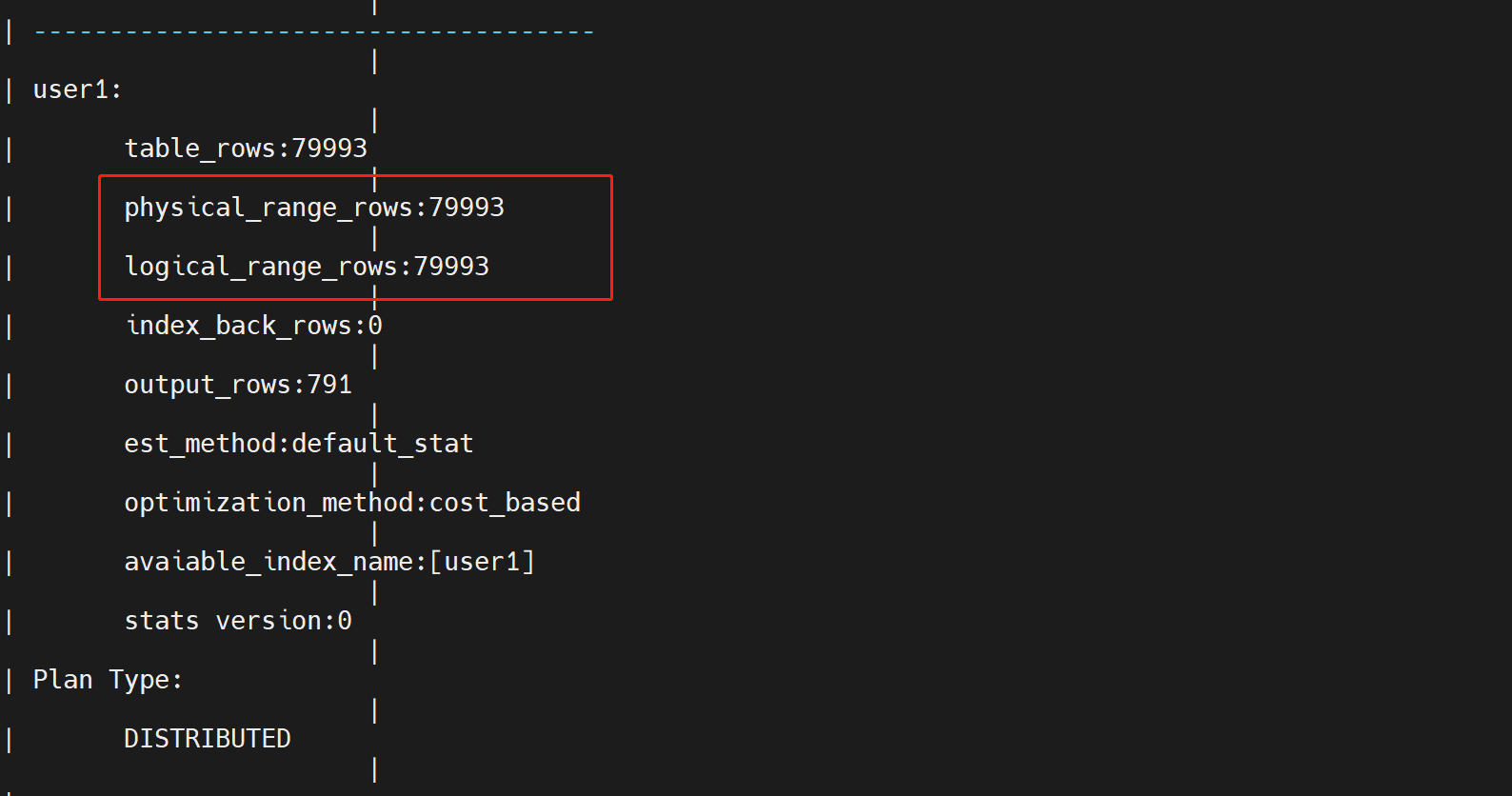
索引测试,没有加索引前,对全盘进行扫描找到了目标对象,操作过程中产生没有产生回表。
场景2:加了局部索引
obclient [tpch]> create index idx_user1_phone on user1 (phone) local;
Query OK, 0 rows affected (3.152 sec)
explain extended select phone,name from user1 where phone = 1592014286;
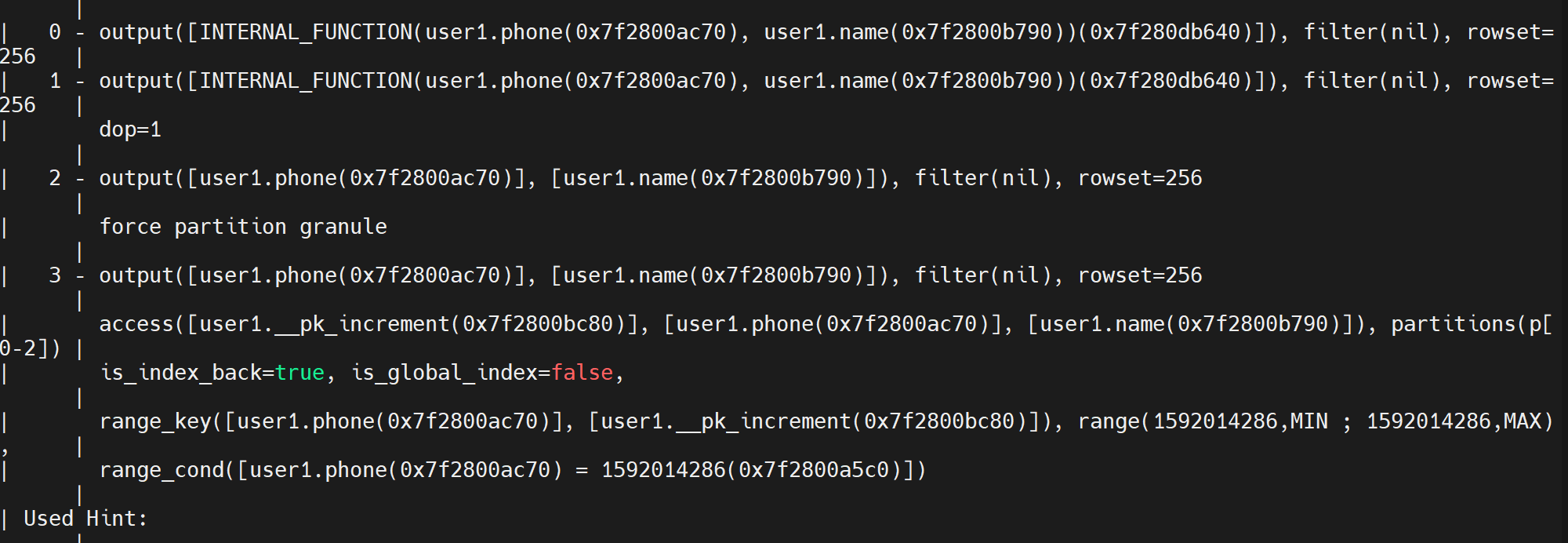
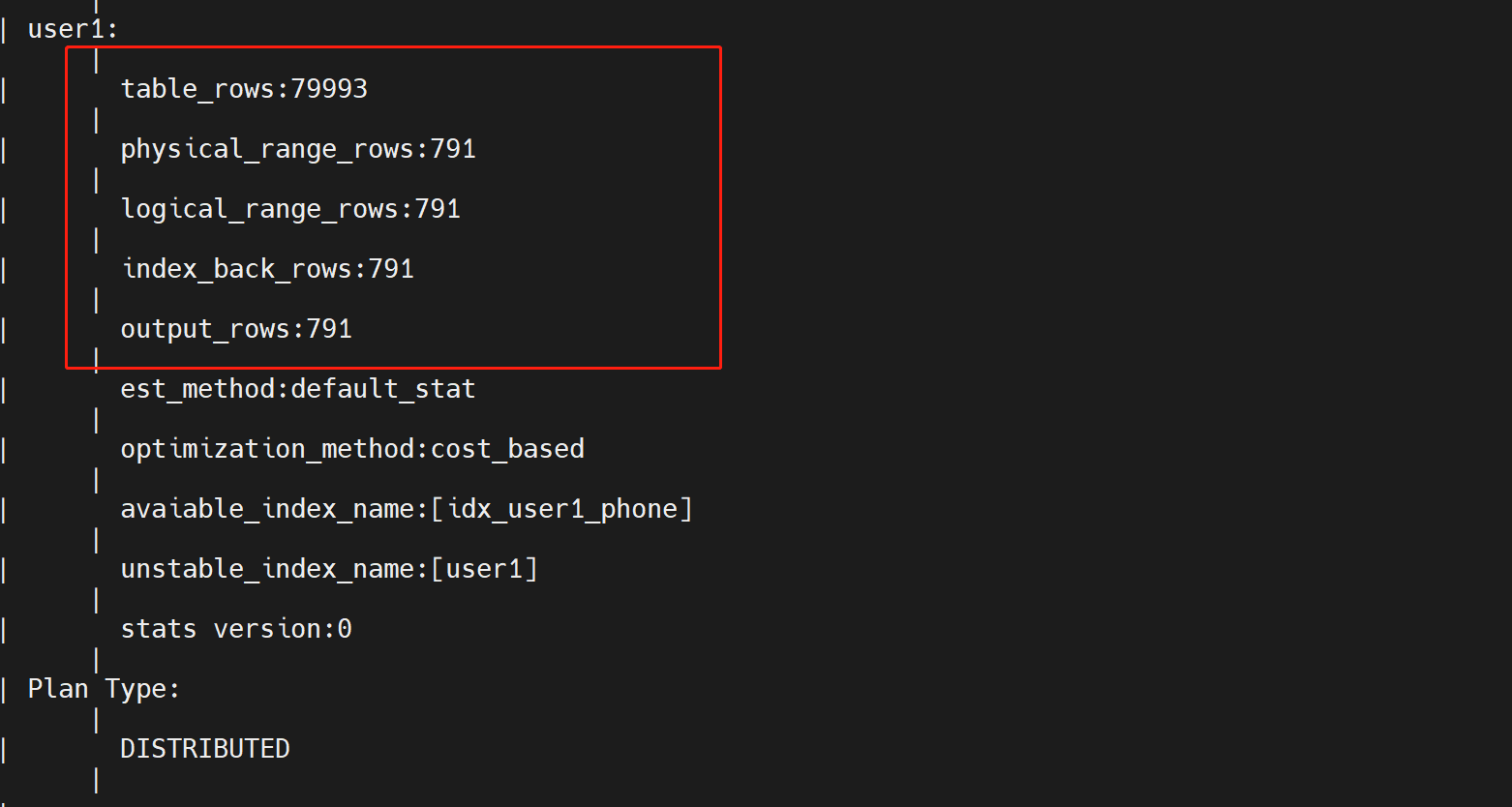
索引测试,加了局部索引后,对硬盘扫描只查找了791行,操作过程中居然产生了回表操作。
场景3:分区查找
obclient [tpch]> explain extended select name, phone from user1 where id= 5000;

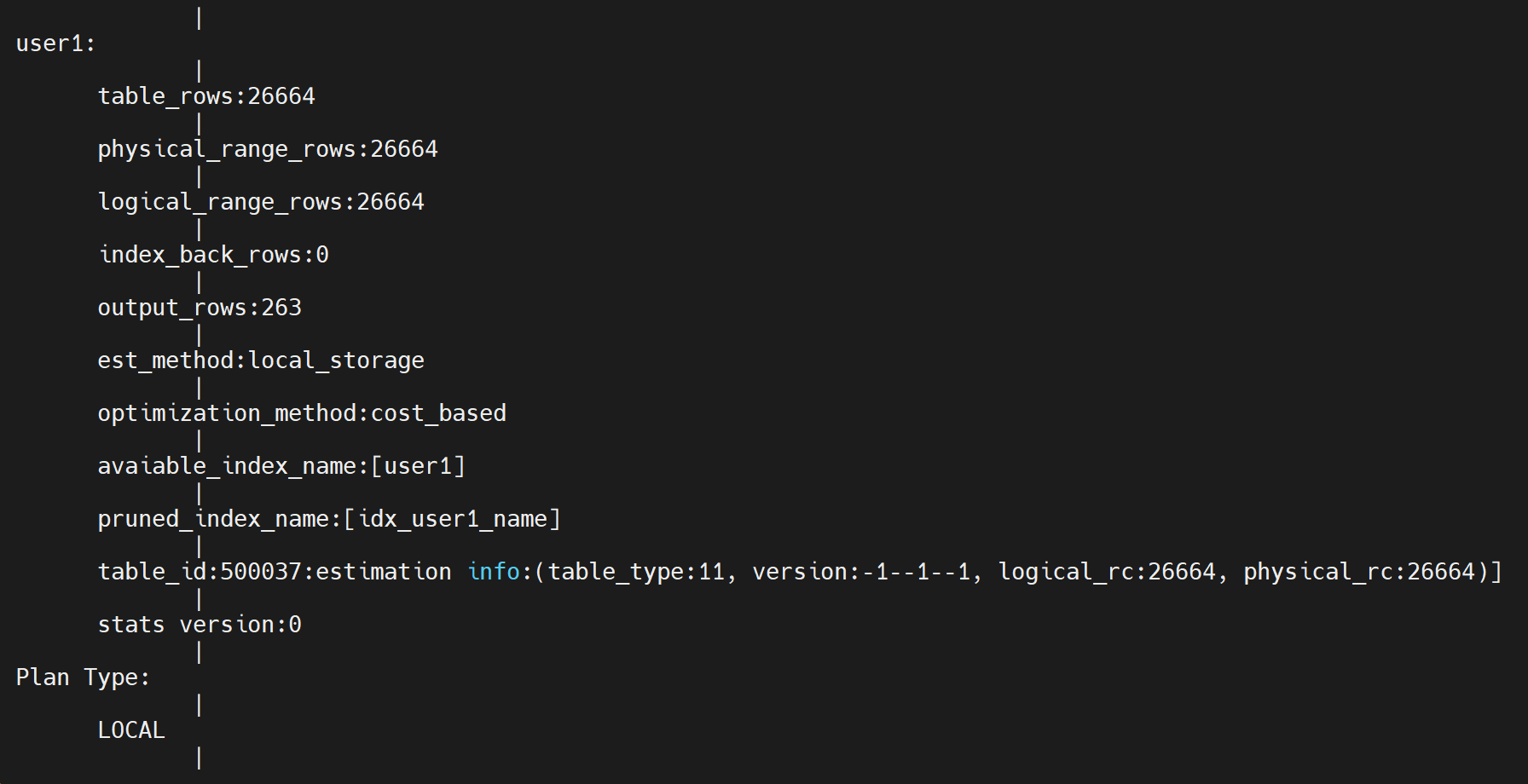
分区测试,通过分区为关键字查找,按划分的分区【26664】查找,由于没有索引设置,遍历所有的26664,没有产生回表。
场景4:分区加索引进行查找
obclient [tpch]> create index idx_user1_id on user1 (id) local;
Query OK, 0 rows affected (3.379 sec)
obclient [tpch]> explain extended select name, phone from user1 where id= 5000;

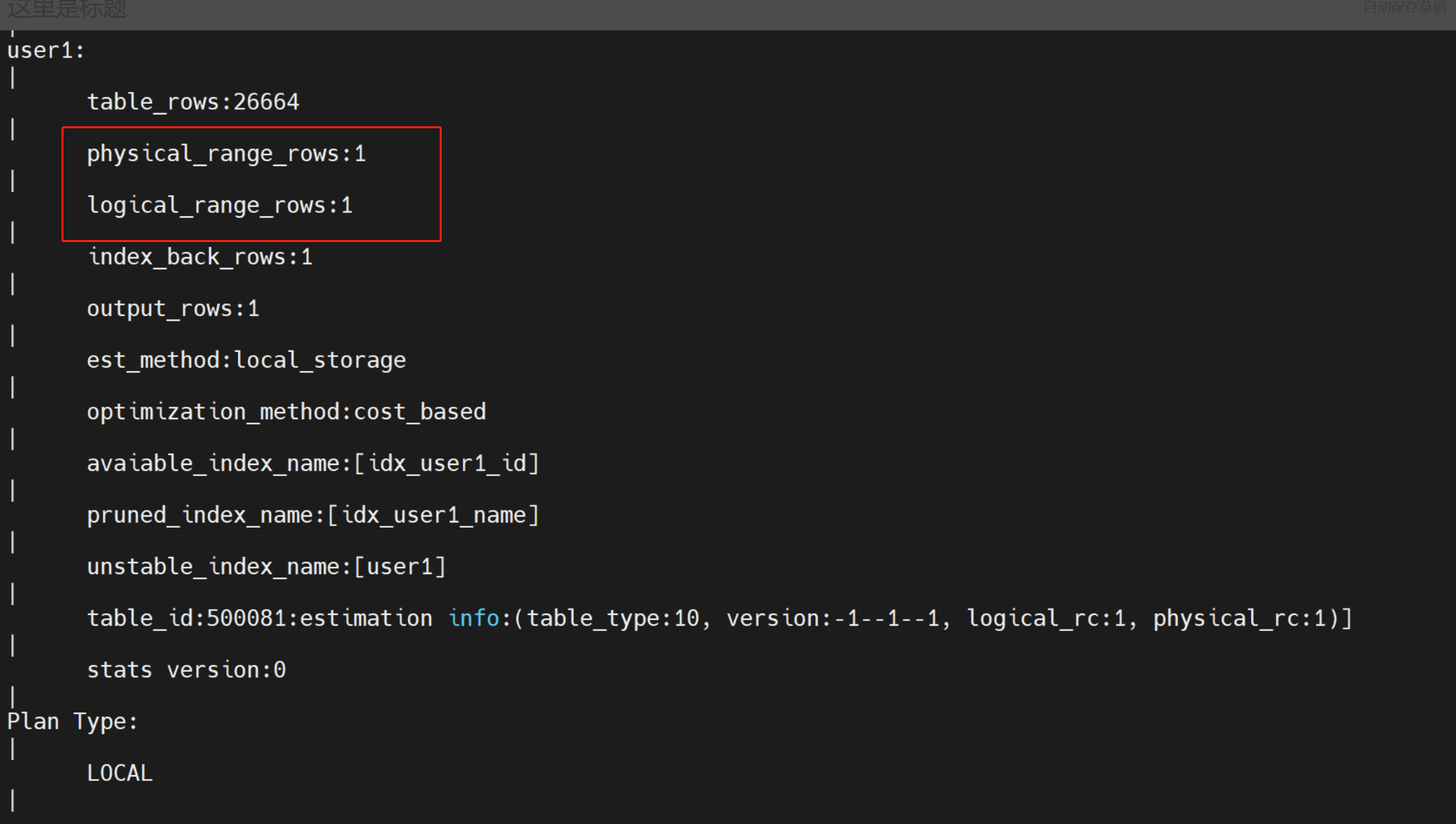
分区加索引测试,id即是索引也是分区,设置索引后按划分的分区【26664】查找,physical_range_rows和logical_range_rows成绩喜人,但是发生回表的操作。
为什么产生回表?主要语句有select name, phone,id是虽然做了索引,但name和phone是投影,从而做了回表。
场景5:创建唯一索引消灭回表
obclient [tpch]> create unique index idx_user_phone_name on user1 (phone,name) local ;
ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning function
提示1503错误,创建唯一索引必须指定分区的指定
obclient [tpch]> create unique index idx_user_id_phone_name on user1 (phone,name,id) local ;
Query OK, 0 rows affected (3.352 sec)
explain extended select phone ,name from user1 where phone = 1592014286;
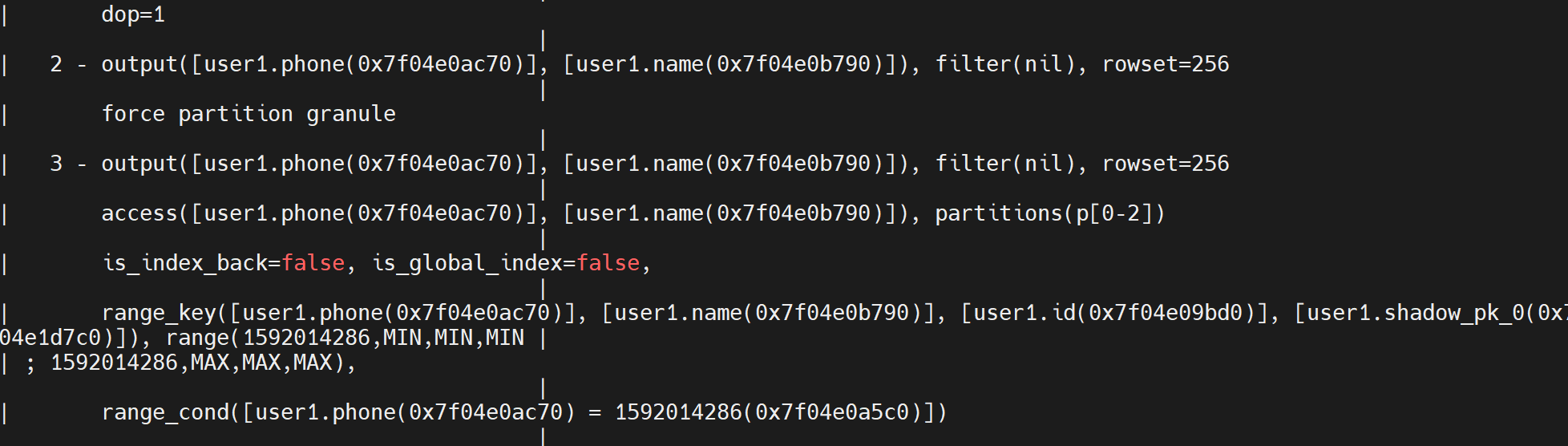
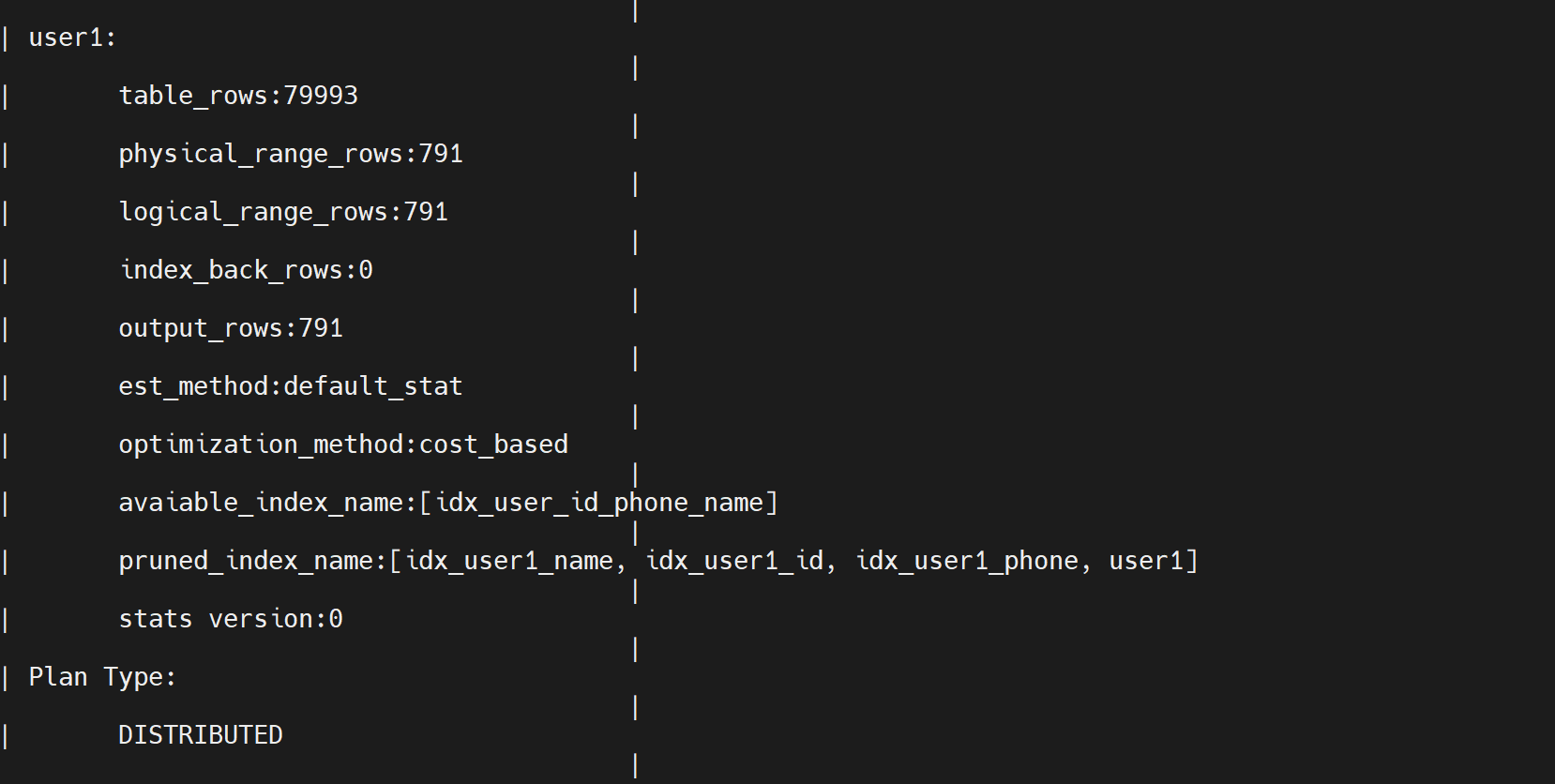
为什么唯一索引必须内含内含分区ID,必须是唯一性,必须包括主键列,基于局部索引加上唯一索引,不产生回表。
场景6:创建全局索引消灭回表
create unique index global_idx_phone on user1(phone,name) global ;
explain extended select phone ,name from user1 where phone = 1592014286;
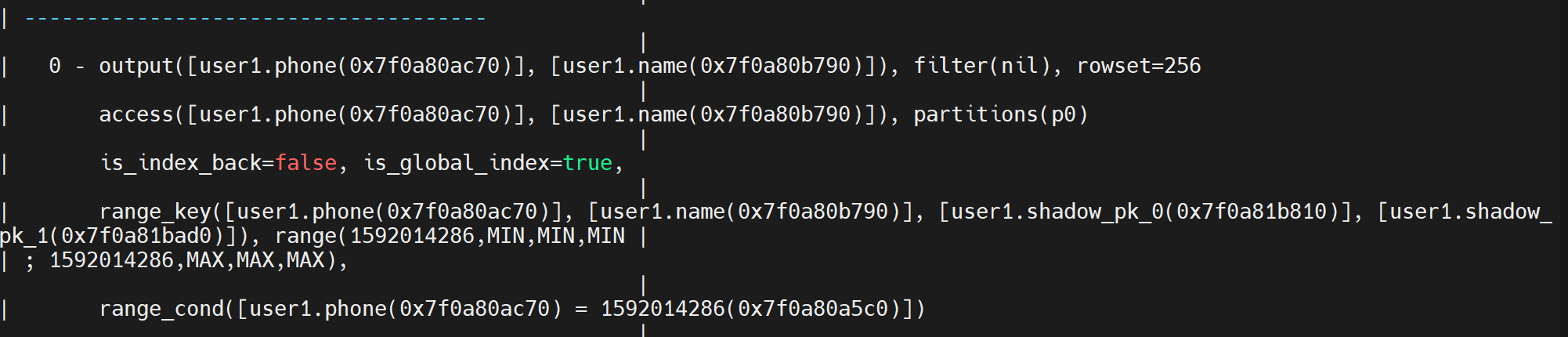
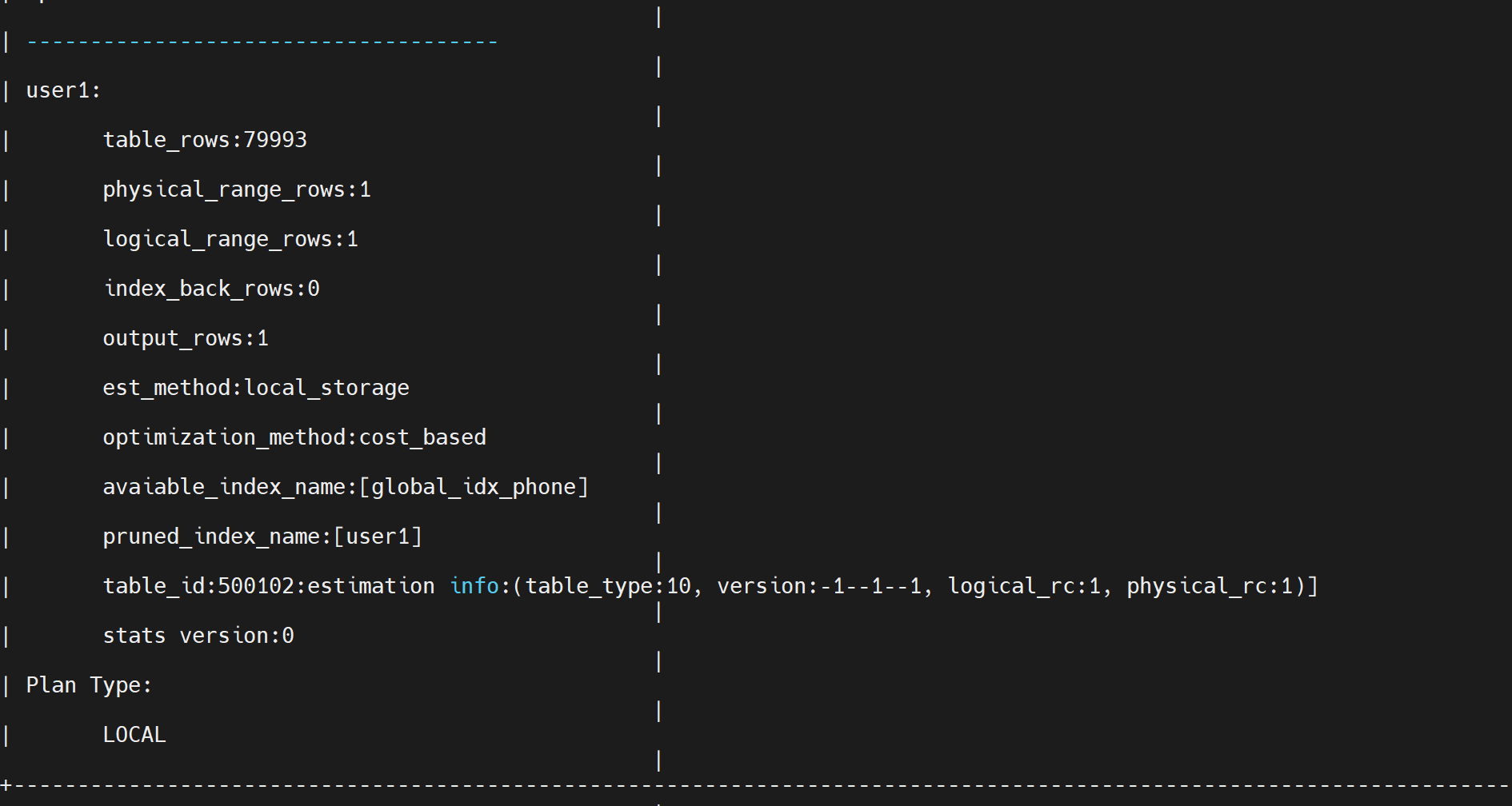
全局索引按照phone,name也可以消来回表。
总结
- OceanBase是单体分布式架构的数据库,调优第一原则遵从先单体再分布的特色,简而言之最好内循环把单机性能用光,再外循环使用分布式,力争Local优先、Remote为次、Distrubte是最坏的,综合执行状况要结合扫描数据范围和回表状况来看。
- 局部索引应用于争取Local的场景,避免Distrubte。场景2、场景3、场景4使用local,但是场景5使用Distribute,深思的是必须结合分区键才能完成唯一索引创建。这里内部的逻辑,局部索引要完成跨域,必须要与分区键绑定。
- 全局索引也可以实现Local的场景,见场景6。笔者没有OB的分布式环境,假设是分布式环境兼数据多的业务场景下,笔者揣测Distrubte的机会性较大。
