




主服务器配置
1.创建一个专门用于复制的用户
create role pgrepuser replication login password 'replica';
2.在postgresql.conf文件配置一下参数
listen_addresses = '*'
wal_level = replica
archive_mode = on
max_wal_senders = 5
wal_keep_segments = 10
#用于指定pg_wal目录中保存的过去的wal文件(wal 段)的最小数量,以防备用服务器在进行流复制时需要
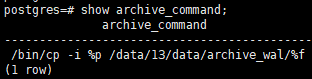
3.设置归档格式,postgresql.conf中设置archive_command
举例
4. 在pg_hba.conf 文件中设置一条权限规则
以允许从属服务器作为复制体系中的客户 端连到主服务器。例如,以下这条规则所代表的含义是:允许你的私有网络中某台服务器上一个名为 pgrepuser 的 PostgreSQL 账号连接到主服务器,其IP地址为10.23.103.101,验证方式为基于 MD5 的加密密码。
host replication pgrepuser 10.23.103.101/24 md5
5.重启主端postgresql服务让上述设置生效
6.创建全量备份
登录到备端 对主端进行备份操作
pg_basebackup
-h 指定host
-U 指定username 连接到数据库的用户 即pgrepuser
-D $PGDATA的目录 备端接收备份的目录 目标文件夹
-X wal_method none/fetch/stream fetch需要在备份完成后获取日志,stream会单独开启一个walsender
-P 显示进程信息
-R 会自动添加 primary_conninfo的信息 write configuration for replication
pg_basebackup -h 10.23.103.103 -U pgrepuser -D /data/13/data/ -X stream -P -R
该命令会直接物理备份相应目录,如果备端相同目录下有文件,请提前备份
7.观察备库的postgresql.auto.conf文件内容
是否有primary_conninfo信息

primary_conninfo = 'user=pgrepuser password=replica channel_binding=disable host=10.23.103.103 port=5432 sslmode=disable sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres target_session_attrs=any'
同时$PGDATA目录下会有一个standby.signal文件作为备库标志
8.启动备库服务
pg_ctl start
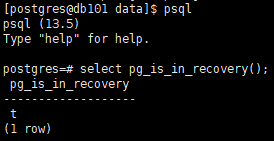
select pg_is_in_recovery();
t=true表示在恢复中 说明为备库
f=false为主库
select pid,usename,application_name,client_addr,state,sync_state from pg_stat_replication;

9.主备测试数据
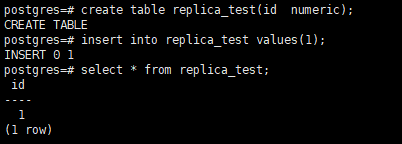
主库创建测试表,插入数据
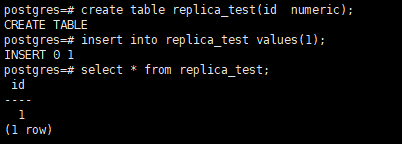
create table replica_test(id numeric);
insert into replica_test values(1);
select * from replica_test;
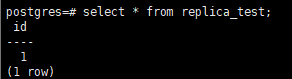
备库也可查询到对应数据
主从切换
1.关闭主库
pg_ctl stop
2.注释备库primary_conninfo信息

3.将从库升级为主库
pg_ctl promote -D $PGDATA
执行promote命令后,相当于备库升级为primay,因为standby.signal标志会自动被移除
4.原主库变成备库
手动创建standby.signal文件
配置postgresql.auto.conf文件
primary_conninfo = 'user=pgrepuser password=replica channel_binding=disable host=10.23.103.101 port=5432 sslmode=disable sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres target_session_attrs=any'
然后启动数据库
确认同步状态
select pid,usename,application_name,client_addr,state,sync_state from pg_stat_replication;

数据测试
主端新插入的数据 在备端未自动同步 查看pg_log

提示有WAL日志未从主端同步过来
从主端的$PGDATA/pg_wal/中将文件中提示的wal文件拷贝到备端$PGDATA/pg_wal/中
警告消除,数据同步成功
select pg_rotate_logfile(); --手动切换日志
数据测试
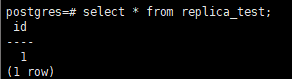
新主库创建测试表,插入数据
备库也可查询到对应数据
查看主从进程状态


当链接成功建立时,除了有对应进程外,streaming算是同步正在进行的标志
如果只有主从,日志未同步的外,streaming处往往是idle状态
第一次测试pg_rewind失败
使用pg_rewind同步主备时间线
pg_rewind --target-pgdata /data/13/data --source-server='host=10.23.103.101 port=5432 user=postgres dbname=postgres password=postgres'
需要修改postgresql.auto.conf文件
standby.signal文件会被pg_rewind移除 所以需要之后创建
本次失败原因可能是wal_keep_segments导致较早的wal文件在主端被删除 因此导致备端执行pg_rewind后失败
使用普通方式重建了流复制
第二次尝试

然而因为前期为修改wal_log_hints_on导致数据库以主角色启动过,所以时间线无法修复,只能重建
full_page_writes 默认on
wal_log_hints 默认off 使用pg_rewind需要on
总结:pg_rewind类似于oracle中broker机制下的flashback,可以将已经断联很久的库闪回到指定的时间线。实际操作,对于体量不那么大的库,用pg_basebackup更方便,也更好理解。
