




点击上方蓝字关注我们

1
文章背景
大多数现有系统都依赖于LRU缓冲区置换算法或其变体和近似算法。默认情况下,DB2使用LRU但也为用户提供切换到先进先出FIFO的选项,后者的内部锁争用较少。Oracle也使用标准 LRU,但对LRU列表进行分区以减少锁争用。此外,还使用单独的策略来避免大表扫描带来的页面换出换入颠簸。
SQL Server是少数几个使用稍微更先进的算法,且广泛使用的系统,即LRU-2。它是LRU-K的一个特殊实例。LRU-2用最近访问列表中访问次数大于2的页面作为置换候选。
在开源系统中,MariaDB以及MySQL的存储引擎InnoDB在LRU列表中间(而不是前面)插入页面来修改LRU列表。这确保了大表扫描不会影响整个缓冲池(但只会影响一部分)。
PostgreSQL使用CLOCK算法的变种Clock-Sweep, 该算法为每个最近被使用的页面增加了权重,使用越频繁越不容易被替换出去,更加符合真实的场景; WiredTiger(MongoDB默认存储引擎)则采用LRU近似算法, 该实现扫描整个缓冲区,替换低于某个阈值的旧页面。LRU被广泛使用,但是受限于大并发场景下的可扩展性问题,需要针对该场景下进行优化。常用的解决方法是将LRU列表进行分区减缓集中式锁争用。但是该优化会降低命中率,增加IO。另外一个分布式解决方法是完全移除LRU列表,利用权重函数给每一个页面都赋一个值,然后使用采样的方法来确定淘汰哪一个页面。
LRU另外一个潜在的问题是冷页面在被偶然访问以后,需要很长的时间才会被置换出去。及早将这些页面驱逐,为其他经常被访问的页面留出空间对系统性能而言是有益的。LRU-K算法就是为规避上述缺点而设计的, 它在访问次数不小于K的列表中淘汰第K次访问离现在最久的页面。
在实践中,一般将K设定为2,即忽略最近使用过的页面。2Q算法采用类似的思想,不同于LRU-K,它将页面分成两个列表,不同访问频率的页面放置于不同的列表。只有访问次数大于2的页面才被移动到LRU列表。2Q算法的一个不足是需要参数调优。ARC算法也是依赖于两个列表,但是可以根据工作负载自适应地确定它们各自的大小。所有这些算法都是试图提高置换效率。
由于现代多核CPU的问题,他们都面临LRU列表头部热点问题,遇到了严重的可扩展性问题。此外,针对SSD而设计一些缓冲区置换算法,为提高SSD的使用寿命以及从写出代价明显高于读入代价出发点而更倾向于将脏页面留在缓冲区。这些算法不能权衡读写权重。
2
写感知的时间戳追踪算法
不直接跟踪访问频率, 没有存储页面历史记录, 不区分读写。
WATT通过在访问日志中维护的时间戳来跟踪每个数据页的访问历史,在最前面的位置 i=1 处添加新时间戳。在下面的示例中,一个页面在时间戳 0、8 和 15 被访问,然后在时间戳 42处被第四次访问:
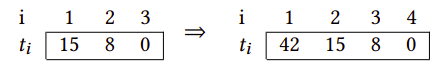
对比最近访问排序 (LRU) 或访问频率计数 (LFU),完整的访问历史记录肯定包含更多内容信息。但是,如何使用这些信息指导页面置换却并不明显。为更好地使用这些信息,WATT设计了一个值函数,将这些页面访问记录作为输入,输出值作为页面置换依据,算法总是挑选该值最小的页面进行置换。为了计算在时间戳tnow时刻的页面值,首先需要日志中每个访问的子频率SFi,计算方式如下:
SFi(tnow) = i /( tnow - ti)
正如函数名字的意义,它计算每个访问i的频率。对于第一个访问而言,公式考虑最近访问;对于第二访问而言,公式考虑最近两次访问,以此类推。完成子频率计算之后,综合可得页面值PV:
PV*(tnow) = max{SFi(tnow)}
当然使用平均数或者中位数也是可行的,取最大值是从计算代价角度考虑,在兼顾算法的效率情况下,计算代价最小。传统的两个经典算法LRU与LFU尝试模拟两个完全不同的场景。LFU 隐式假定统计上独立且恒定的页面访问频率——因此只有长期观察的频率才重要。
相比之下,LRU假设缓存中的工作集可能会突然发生变化-这里只有最近访问才重要。在WATT中,SF1(SFmax)即等同于LRU(LFU)。通过综合子频率,我们可以得到两个极端之间的折中。在访问突发期间,最近访问频率很高,这使得工作集有很高的概率驻留在缓存。在突发访问过后,只有少数最近访问的页面值会迅速收缩,直到被后续较高频率的访问所替换。这对应长时间运行的访问频率。
由于PV依赖于tnow,因此即使某个页面没有被修改,它的值却仍然在改变。将缓冲区里所有的数据页按照PV值维护在一个队列里面的方法是不可行的,这将耗费可观的计算资源。
此外,把一个数据页所有的访问历史存储起来也是不切实际的。针对第一个问题,论文采用随机以及延迟评估的方法确定需要淘汰的页面。具体操作如下:在淘汰页面的时刻,随机抽取N个页面(论文中通过实验发现8个页面是最优的),动态地计算此时N个页面最小的PV值min{PVi|1≤ i ≤8}。随后将该PV值作为阈值,作为淘汰页面的依据。驱逐PV值小于该阈值的页面。这种随机的,延迟的方式完全去除了集中式数据结构,具有很好的扩展性以及最小化计算代价。
针对第二个问题,论文只存储8个读操作历史记录以及4个写操作历史记录。保留的历史记录的数值确定为8和4可以方便使用SIMD指令进行高效计算。只保留小量历史记录的不足之处在于突发访问很容易耗尽历史日志,所有旧的访问历史都会丢失。
为了避免这个问题,采用epoch的方式推进时间戳。Epoch的设计不仅具有概念上的好处(它可以防止突发访问使页面的整个历史记录频繁丢失),这对于可扩展的并发页面跟踪也至关重要。在跟踪页面历史记录过程中,只有距离当前最近的页面访问时间发生变化时,我们才插入新的时间戳。
因此,基于epoch的跟踪机制避免过于频繁地修改热点页。例如,考虑在一个并发内存B树上的工作负载,其中每个操作都会访问根节点。没有epoch,根节点页面该树将成为争用热点,因为每次访问会修改跟踪信息, 导致高速缓存颠簸, 降低可扩展性。利用epoch可以极大减缓全局时间的变更,对于大部分访问根节点追踪的时间戳都保持未更改状态,避免了频繁修改根节点导致的扩展性问题。
论文也考虑了SSD固态硬盘存在读写不对称问题,赋予写操作一定的权重,能够感知写操作。写操作权重取决于写操作代价。增加权重倾向于将脏页面留在缓存中,页面置换的时候优先考虑干净的页面。因此页面的PV值使用下面的公式计算:
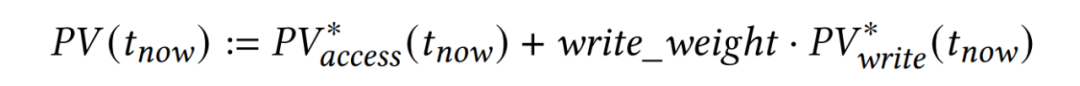
许多置换算法,包括LRU-K和ARC,都倾向于不赋予最近一次的访问操作太多的优先级。直观上,这很有帮助,因为最近的访问通常都是暂时的而不是常态。论文通过抑制最近访问子频率降低它的权重,将SF1乘以一个小于1的常数实现该目的,表达如下:
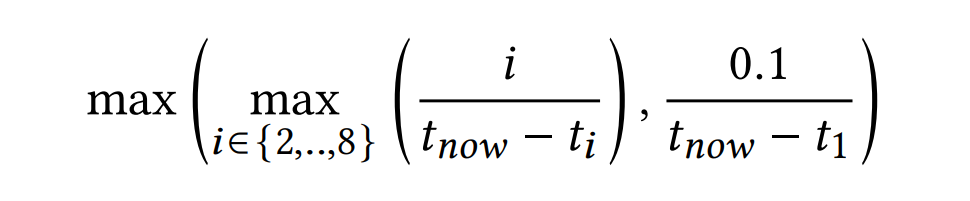
不看广告,看疗效。论文在读写IO以及命中率等指标上对比了多种缓冲区置换算法,证明了算法的高效。下面是一些实验结果。
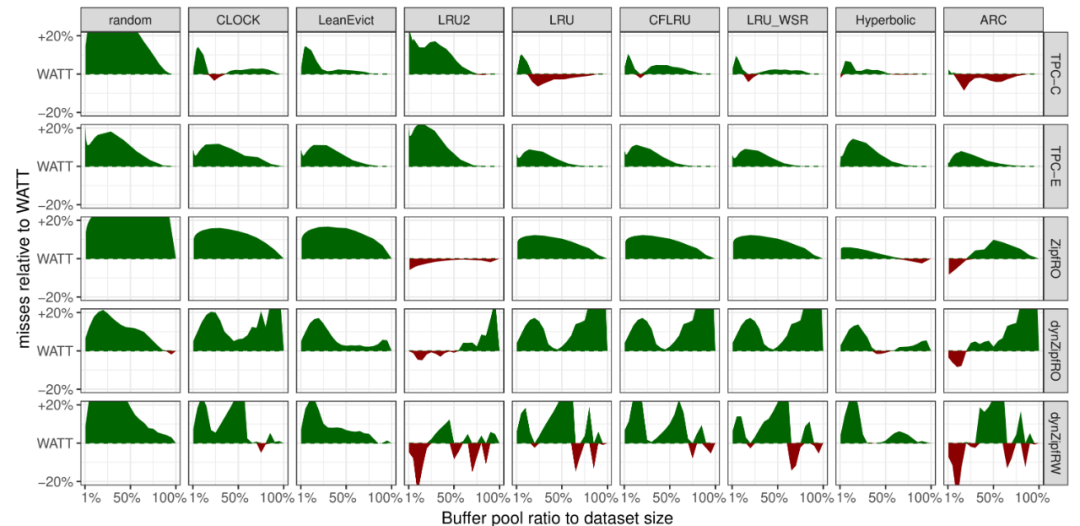
图1. 置换算法比较
首先,在TPC-C、TPC-E以及Zifian等工作负载上对比了多种置换算法关于命中率上表现。蓝色的表示WATT算法优于其他算法(较低的未命中率),红色则表示其他算法优于WATT。
总体而言,在所有工作负载和数据大小中,WATT具有最佳效果。结果还可以洞见各种算法的相对优点和缺点。显然,随机策略的效果最差。Clock 比 LRU 稍差,这并不奇怪因为它们实际上是 LRU 的近似算法。对于写感知的 LRU 变体算法, CFLRU和LRU_WSR,情况也是一样。有趣的是,对比LRU,LRU2在Zipf工作负载上取得了更好的性能工作负载,但在TPC-C和TPC-E上它的性能比LRU差。Web应用的缓存算法Hyperbolic和 ARC 通常比LRU表现更好,但在平均还是比WATT差。
论文也比较了不同的算法在读写IO上以及事务TPS上的表现。得益于写感知,WATT能够大幅减少事务读写IO次数,同时不损害总体性能。
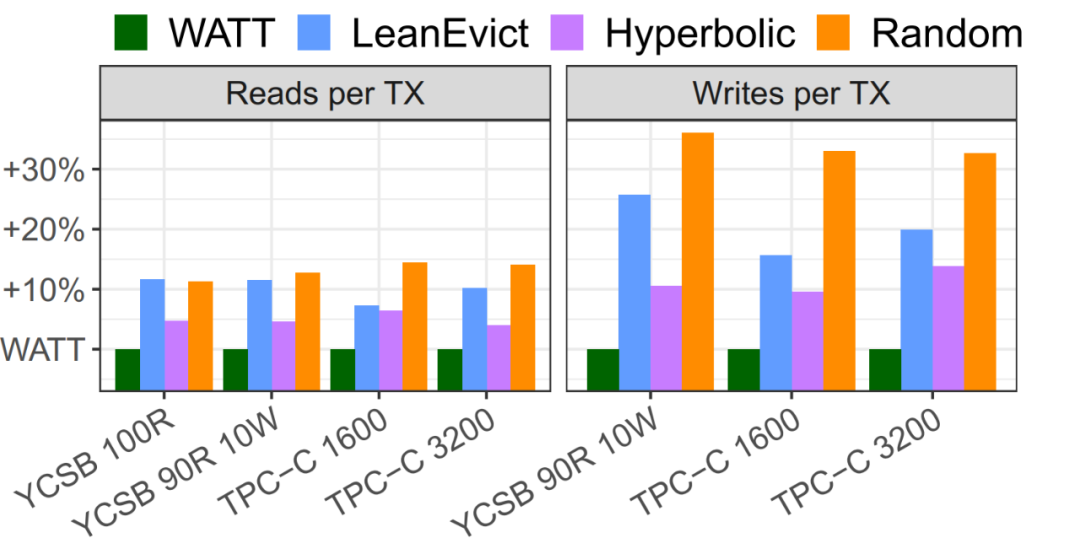
(a) 读写IO
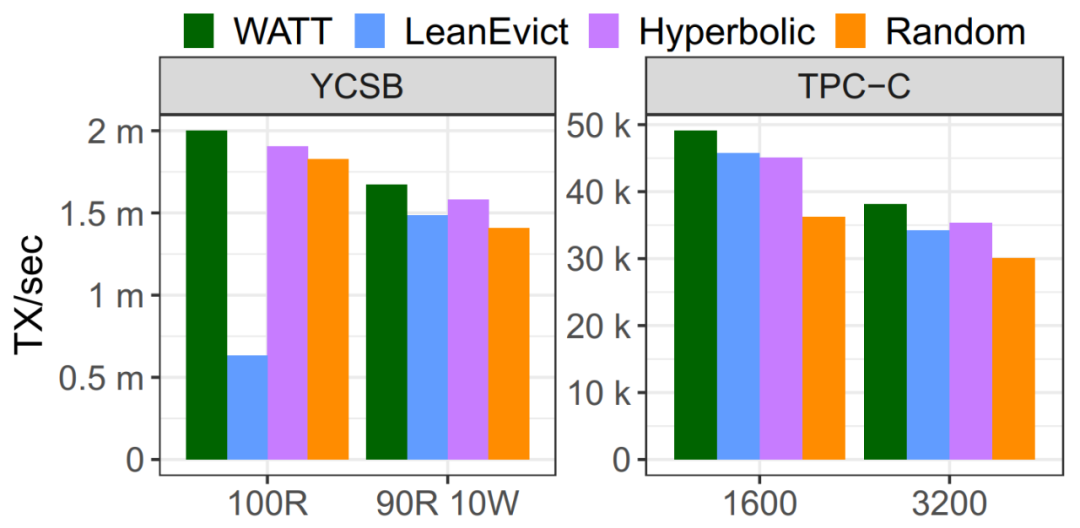
(b)事务吞吐量
图2. 算法其他指标
3
总结

