




对文本进行相似性分析,需要将文本内容转换为向量空间模型,把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度。
文本是由若干单词构成的,若把文本内的每一个单词看作文本向量的一个维度,去掉一些没有意义的停用词(如的、地这样的虚词),然后计算每个单词在文本内出现的次数,就可以得到该文本的向量空间模型。
例句1:Hanna wants to go to China.
例句2:Lusy wants to go to France.
分别对例句1和例句2进行分词,得到下面的词典。
词典:{ Hanna,wants,to,go,China,Lusy,France }
计算词典中的所有单词在例句1和例句2出现的次数,并形成向量A和B。A向量表示词典内所有单词在例句1出现的次数,B向量表示词典内所有单词在例句2出现的次数。A和B向量分量的顺序与词典顺序一致。
向量A:{ 1,1,2,1,1,0,0 }
向量B:{ 0,1,2,1,0,1,1 }
通过统计每个词在文本中出现的次数,得到了文本基于词频率特征的向量A和B。现在需要判断向量A和B的相似度,判定规则是若两个向量平行或重合,我们认为这两个向量为1,若两个向量垂直或者说正交,我们认为这两个向量的相似度为0。
图1、图2和图3在二维空间绘制了向量A和B相交、正交和重合的情况。向量A和B的相似度可以通过夹角θ来确定。θ越小两个向量的相似度越高,当θ为0度时,两个向量重合,相似度为1,当θ为90度时,两个向量正交,相似度为0。
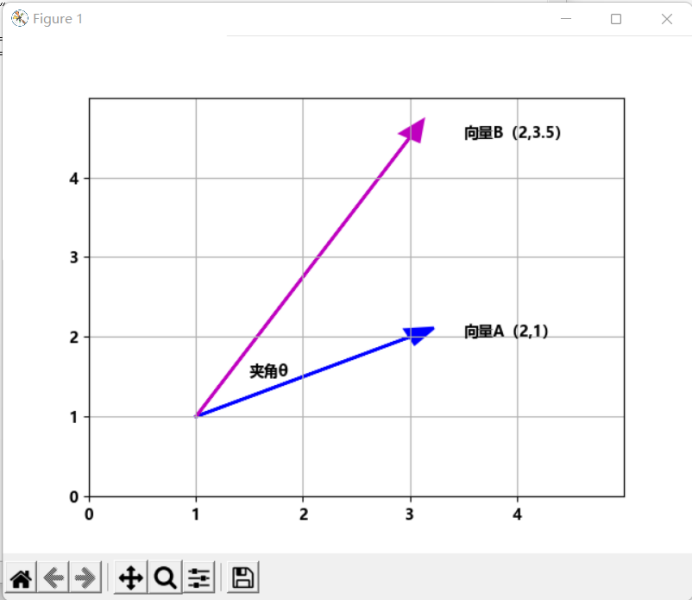
图 1 向量A和B
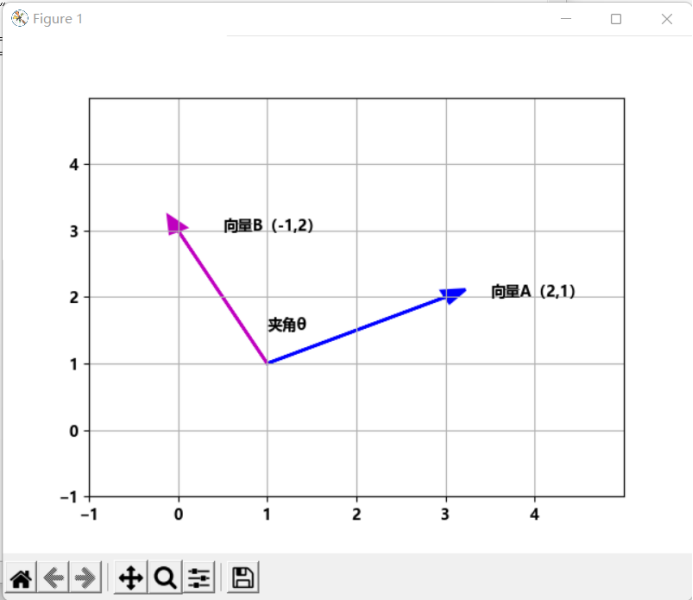
图 2向量A和B正交
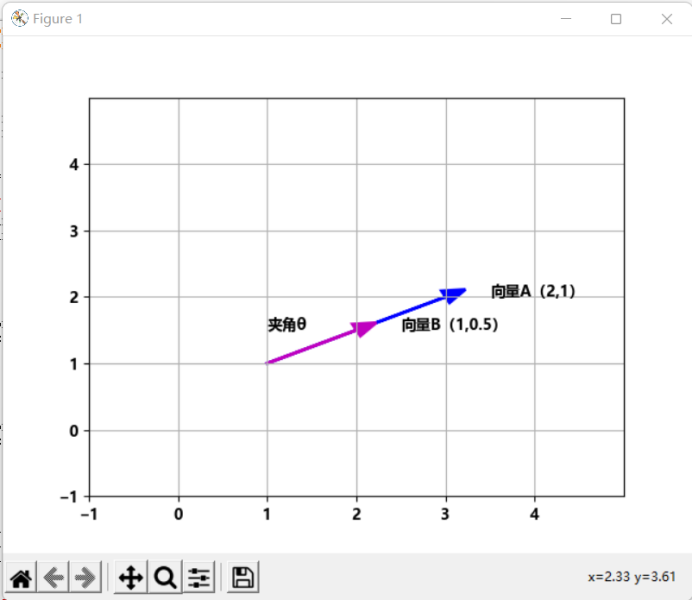
图 3向量A和B重合
import numpy as npimport matplotlib.pyplot as pltplt.rc("font",family='MicroSoft YaHei',weight="bold")# 定义向量A和BA = np.array([2,1])B = np.array([2,3.5])# 创建坐标轴ax = plt.axes()# (1,1)为起点,绘制向量A和Bax.arrow(1, 1, *A, color='b', linewidth=2.0, head_width=0.20, head_length=0.25)ax.arrow(1, 1, *B, color='m', linewidth=2.0, head_width=0.20, head_length=0.25)# 设置X轴范围plt.xlim(0,5)# 设置X轴刻度major_xticks = np.arange(0, 5)ax.set_xticks(major_xticks)# 设置Y轴范围plt.ylim(0, 5)# 设置Y轴刻度major_yticks = np.arange(0,5)ax.set_yticks(major_yticks)# 绘制网格线plt.grid(b=True, which='major')# 绘制标注ax.text(A[0]+1.5,A[1]+1,"向量A(2,1)")ax.text(B[0]+1.5,B[1]+1,"向量B(2,3.5)")ax.text(1.5,1.5,"夹角θ")# 显示图像plt.show()
通过计算两个向量的夹角余弦值可以评估它们的相似度,计算两个n维向量夹角余弦值的计算公式为:
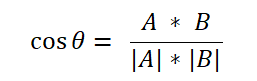
其中A*B是A和B向量的点积,|A|*|B|是向量A和B模长的积。
【例1】 计算例句1和例句2的相似度
程序清单
import numpy as np# 定义向量A和BA = np.array([1,1,2,1,1,0,0])B = np.array([0,1,2,1,0,1,1])# 计算点积dot = np.dot(A,B)# 计算向量A的模长ma = np.linalg.norm(A)# 计算向量B的模长mb = np.linalg.norm(B)# 计算向量A和B的相似度sim = dot/(ma*mb)print('相似度为%.6f' % (sim))
文本相似度分析过程主要包括文本分词、创建词典、创建词向量(语料)、语料建模、相似度计算。
文本分词是文本处理的一个基础步骤,在进行中文自然语言处理时,通常需要先进行分词。文本相似性分析、机器翻译、语音识别等自然语音处理都有用到文本分词,文本分词的好坏直接影响到自然语音处理结果。对文本进行分词可以选择比较成熟的中文分词库。
文本分词完成后,进入创建词典的过程,对所有的分词去重后建立词典,词典内的每个分词具有唯一性。
一个词向量是一段文本内所有分词映射到实数的向量,映射关系可以是分词在文本内的重复次数,也可以是其他映射关系。词向量的数量与文本数量相关,若要分析文本的数量为n个,则词向量的数量也为n个,词向量的维度为词典内分词的数量。
语料建模:将所有的词向量作为训练样本,确定一个假设函数。该假设函数尽可能拟合客观存在的映射函数,而不是单纯计算向量间的余弦值。例如IF_IDF模型就是一个假设函数,它将输入的词向量做进一步处理,提取单词在文本内的权重,输出加入单词权重的词向量。在相似度分析中,若仅考虑词频,而忽略词的其他特征,语料建模可以省略。
相似度计算:根据已建立的词向量或模型,对待分析的文本逐一与词向量或模型内的样本计算其相似值,相似值越高的词向量所表示的文本,与待分析的文本相似程度越高。
