




最近在为公司业务去做数据库选型,其中时序是一个比较大的需求。在墨天轮上,关系型数据库的比例确实是很高,但是切到时序的时候,可选的余地就不多了。再去仔细对比调研,尤其是匹配金融行业需求的,只留下一个名字:DolphinDB。虽然之前有过时序数据库的调研,但是主要面向的场景都是高并发乱序写入和一些插值查询,对于金融行业的一些典型场景,不能说是了如指掌,至少也是知之甚少(通辽黑话,说着说着就上瘾了)。在得到DolphinDB原厂诸位的帮助下,对这个在金融领域已经占据很大一片空间的产品有了基础的认知。
但是作为DBA出身的我,仍然需要做一件事情,亲自动手部署一遍,体验一下到底有哪些地方要注意,哪些东西和之前用过的时序数据库不一样。
准备工作
首先就是,官网能下载到的是社区版,支持单节点模式和单节点集群模式。本文主要的部署方式是单节点集群模式。其次就是,除了数据库软件,还有一个桌面版的客户端 DolphinDB GUI。既然体验就都下载一次。
https://www.dolphindb.cn/product#downloads
通过官网下载下来两个安装包DolphinDB_GUI_V1.30.22.1.zip和DolphinDB_Linux64_V2.00.10.7.zip
本次选择的是在Linux部署,具体环境如下:
操作系统:Redhat 8.5
CPU:8C
内存:32GB
磁盘:100GB
准备完毕之后开始部署。
部署服务
参考部署手册:https://gitee.com/dolphindb/Tutorials_CN/blob/master/single_machine_cluster_deploy.md
将Linux64那个包传到服务器,GUI的包留在本地。接下来创建目录并解压缩
# mkdir /DolphinDB
# mv /tmp/DolphinDB_GUI_V1.30.22.1.zip /DolphinDB
# cd /DolphinDB
# unzip DolphinDB_GUI_V1.30.22.1.zip
解完压缩,会有一个server目录和几个文件,后续我们所有的服务器操作都在server目录下。
打开里面的dolphindb.cfg,里面的参数做下调整
maxMemSize=32 #最大内存数,社区版限制8GB,感谢dolphindb的朋友给我的license解除限制
因为是单节点集群模式,所以要相继启动控制节点、代理节点、数据和计算节点,还要修改文件相关权限
# cd /DolphinDB/server
# chmod +x dolphindb
# cd clusterDemo
# ./startController.sh #启动控制节点
# ./startagent.sh #启动代理节点
# ps aux|grep dolphindb #查看状态
到这一步如果前面都顺利,就能看到已经启动的几个节点信息:

根据官方文档,此时还剩下没有启动的就是数据节点和计算节点,这两个节点从web端访问,在浏览器中输入http://server_ip:8900 ,勾选上两个status是红色的计算节点和数据节点,点击执行,等几秒刷新后,状态就是全勾

到这一步,整个部署只用了10分钟左右,不能不感叹,简洁易用。
配置客户端
接下来在我本地部署一个UI客户端,需要用到JDK,如果没有安装会报错。一切就绪之后,解压缩GUI那个包,直接运行gui.bat即可。第一次运行会要求你配置一个workspace,选一个自己本地的目录。
然后添加服务器,就是我们上一步配置好的那个端口8900的地址
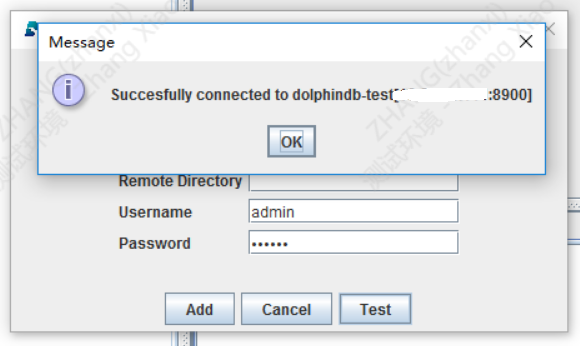
添加完成别忘了测试一下,这里默认的管理员账号密码是admin/123456,实际生产记得要换。
 ![8.PNG]
![8.PNG]
添加完成后,关掉GUI再打开,选择人头图标重新登录试试,登陆成功即意味着客户端配置完成
查询实验
接下来我们在WEB端来跑个demo查询试试,点击datanode中dnode1的链接,进入变成交互页面
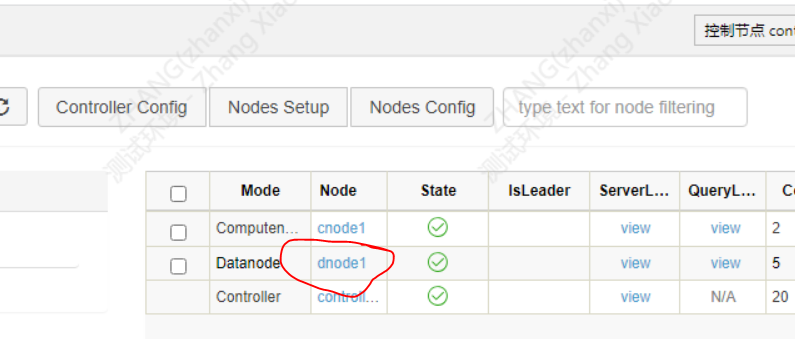
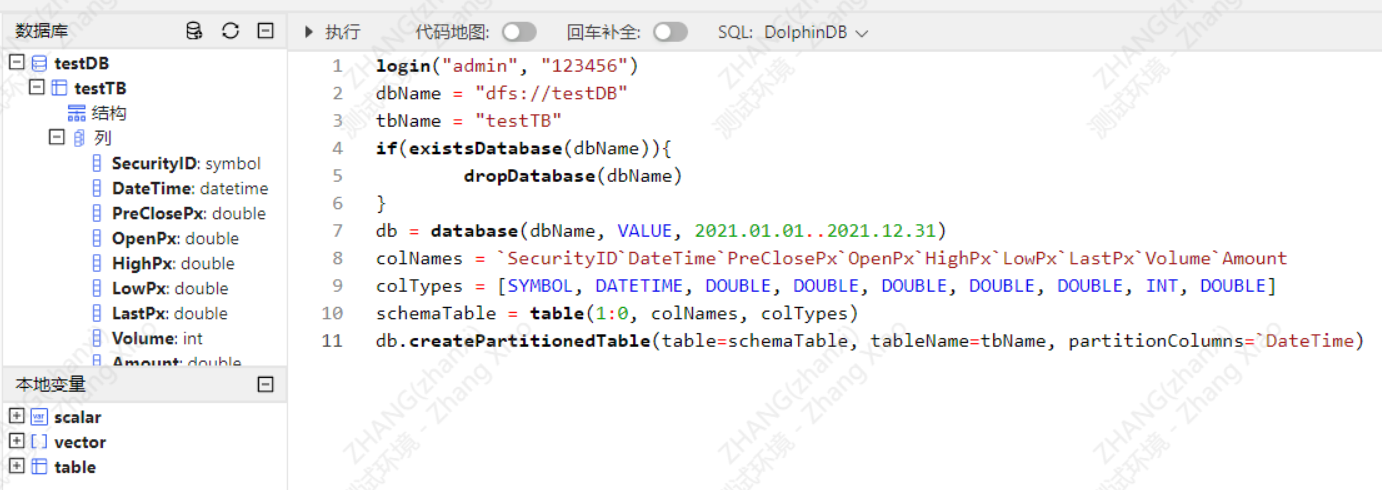
以admin登录,并创建数据库testDB与表testTB
login("admin", "123456")
dbName = "dfs://testDB"
tbName = "testTB"
if(existsDatabase(dbName)){
dropDatabase(dbName)
}
db = database(dbName, VALUE, 2021.01.01..2021.12.31)
colNames = `SecurityID`DateTime`PreClosePx`OpenPx`HighPx`LowPx`LastPx`Volume`Amount
colTypes = [SYMBOL, DATETIME, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE, INT, DOUBLE]
schemaTable = table(1:0, colNames, colTypes)
db.createPartitionedTable(table=schemaTable, tableName=tbName, partitionColumns=`DateTime)
创建完成在左侧刷新一下数据库,可以看到库、表、列等元数据信息以及当前的变量
执行以下语句模拟生成 5000 个股票 1 天的 1 分钟 K 线数据并写入上面创建的分区表,这里根据你的机器配置情况,可以适当调整n或者其他参数:
n = 1210000
randPrice = round(10+rand(1.0, 100), 2)
randVolume = 100+rand(100, 100)
SecurityID = lpad(string(take(0..4999, 5000)), 6, `0)
DateTime = (2023.01.08T09:30:00 + take(0..120, 121)*60).join(2023.01.08T13:00:00 + take(0..120, 121)*60)
PreClosePx = rand(randPrice, n)
OpenPx = rand(randPrice, n)
HighPx = rand(randPrice, n)
LowPx = rand(randPrice, n)
LastPx = rand(randPrice, n)
Volume = int(rand(randVolume, n))
Amount = round(LastPx*Volume, 2)
tmp = cj(table(SecurityID), table(DateTime))
t = tmp.join!(table(PreClosePx, OpenPx, HighPx, LowPx, LastPx, Volume, Amount))
dbName = "dfs://testDB"
tbName = "testTB"
loadTable(dbName, tbName).append!(t)
// 加载分区表对象
pt = loadTable("dfs://testDB", "testTB")
至此表里的数据就已经都加载完成,接下来依次跑两条查询:
select count(*) from pt group by date(DateTime) as Date
select first(LastPx) as Open, max(LastPx) as High, min(LastPx) as Low, last(LastPx) as Close from pt group by date(DateTime) as Date, SecurityID
网页右侧可以看到消耗时间。
接下来切回客户端,我们再重新跑一次第二条查询,这里比较麻烦的是,如果想要在客户端里去跑查询,需要先新建一个脚本,然后用客户端打开,没有新建按钮,有些不习惯,这里还提供了一个功能,就是把查询结果直接导出到csv,很实用的功能
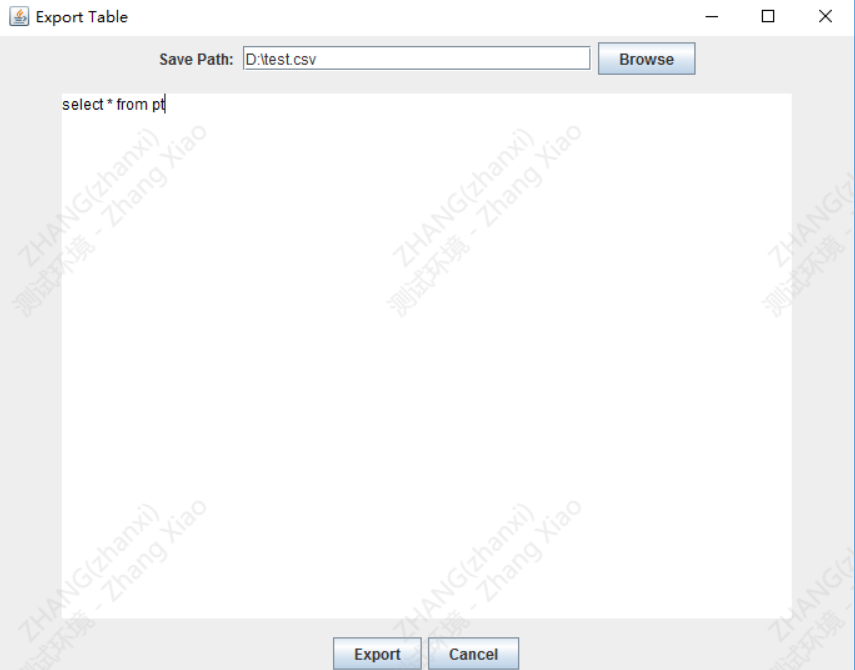
看结果,100MB左右,所有的数据都导出来了

总结
最后我总结一下,dolphindb使用过程中的一些点。
优点:
单节点部署简单,新手和老DBA都可以很容易地部署,集群版因为没有配置,以后有机会再更新。
网页集成了管理和类似于SQL编辑器的功能,不需要额外任何其他工具就可以用
有单独的UI客户端,满足不同类型用户的需求
缺点:
部署文档和手册分布在两个不同的网站,一个在gitee一个在官网
GUI和Web虽然能看到各个级别的元数据,但是无法用鼠标做操作
