




赛题名称:CCL2023网络诈骗案件分类 赛题类型:自然语言处理、文本分类
赛题介绍
https://github.com/GJSeason/CCL2023-FCC
任务背景
2022年12月1日起,新出台的《反电信网络诈骗犯罪法》正式施行,表明了我国治理当前电信网络诈骗乱象的决心。诈骗案件分类问题是打击电信网路诈骗犯罪过程中的关键一环,根据不同的诈骗方式、手法等将其分类,一方面能够便于统计现状,有助于公安部门掌握当前电信网络诈骗案件的分布特点,进而能够对不同类别的诈骗案件作出针对性的预防、监管、制止、侦查等措施,另一方面也有助于在向群众进行反诈宣传时抓住重点、突出典型等。
任务简介
文本分类是自然语言处理领域的基础任务,面向电信网络诈骗领域的案件分类对智能化案件分析具有重要意义。本任务目的是对给定案件描述文本进行分类。案件文本包含对案件的整体描述(经过脱敏处理)。具体细节参考第2部分。
评测数据
数据简介
数据采集: 案件文本内容为案情简述,即为受害人的笔录,由公安部门反诈大数据平台导出。
数据清洗: 从反诈大数据平台共计导出 13 个类别的数据,去除了“其他类型诈骗”类别,因此最终采用 12 个类别。
脱敏处理: 去除了案件文本中的姓名、出生日期、地址、涉案网址、各类社交账号以及银行卡号码等个人隐私或敏感信息。
分类依据: 类别体系来源于反诈大数据平台的分类标准,主要依据受害人的法益及犯罪分子的手法进行分类,例如冒充淘宝客服谎称快递丢失的,分为冒充电商物流客服类;冒充公安、检察院、法院人员行骗的,分为冒充公检法及政府机关类;谎称可以帮助消除不良贷款记录的,分为虚假政信类等等。
类别数量: 12 个类别。
数据样例
数据以json格式存储,每一条数据具有三个属性,分别为案件编号、案情描述、案件类别。样例如下:
{
"案件编号": 28043,
"案情描述": "事主(女,20岁,汉族,大专文化程度,未婚,现住址:)报称2022年8月27日13时43分许在口被嫌疑人冒充快递客服以申请理赔为由诈骗3634元人民币。对方通过电话()与事主联系,对方自称是中通快递客服称事主的快递物件丢失现需要进行理赔,事主同意后对方便让事主将资金转入对方所谓的“安全账号”内实施诈骗,事主通过网银的方式转账。事主使用的中国农业银行账号,嫌疑人信息:1、成都农村商业银行账号,收款人:;2、中国建设银行账号,收款人:。事主快递信息:中通快递,.现场勘查号:。",
"案件类别": "冒充电商物流客服类"
},
{
"案件编号": 49750,
"案情描述": "2022 年 11 月 13 日 14 时 10 分 23 秒我滨河派出所接到 110 报警称在接到自称疾控中心诈骗电话,被骗元,接到报警民警赶到现场,经查,报警人,在辽宁省 17 号楼 162 家中,接到自称沈阳市疾控报警中心电话,对方称报警人去过,报警人否认后对方称把电话转接到哈尔滨市刑侦大队,自称刑侦大队的人说报警人涉及一桩洗钱的案件让报警人配合调查取证,调查取证期间让报警人把钱存到自己的银行卡中,并向报警人发送一个网址链接,在链接上进行操作,操作完后,对方在后台将报警人存在自己银行卡的钱全部转出,共转出五笔,共计元。",
"案件类别": "冒充公检法及政府机关类"
},
{
"案件编号": 78494,
"案情描述": "2022 年 1 月 10 日 11 时至 18 时许,受害人在的家中,接到陌生电话:(对方号码:)对方自称是银保监会的工作人员,说受害人京东 APP 里有个金条借款要关闭,否则会影响征信。后对方就让受害人下载了“银视讯”的会议聊天软件,指导受害人如何操作,让受害人通过手机银行(受害人账户:1、交通银行;2、紫金农商银行;3、中国邮政储蓄银行:;4、中国民生银行:;)转账到对方指定账户:嫌疑人账户:1、中国农业银行;2、中国银行;3、中国银行;4、中国建设银行;5、中国银行;共计损失:元。案件编号:",
"案件类别": "虚假征信类"
}
数据分布
提供数据共有12个类别,类别具体分布如下表所示。
| 类别名称 | 样本数量 |
|---|---|
| 刷单返利类 | 35459 |
| 冒充电商物流客服类 | 13772 |
| 虚假网络投资理财类 | 11836 |
| 贷款、代办信用卡类 | 11105 |
| 虚假征信类 | 8464 |
| 虚假购物、服务类 | 7058 |
| 冒充公检法及政府机关类 | 4563 |
| 冒充领导、熟人类 | 4407 |
| 网络游戏产品虚假交易类 | 2155 |
| 网络婚恋、交友类(非虚假网络投资理财类) | 1654 |
| 冒充军警购物类 | 1092 |
| 网黑案件 | 1197 |
| 总计 | 102762 |
注:在数据集(训练集和测试集)中 “冒充军警购物类” 的标注为 “冒充军警购物类诈骗” 。
训练集及测试集划分如下所示。
| 数据划分 | 样本数量 |
|---|---|
| 训练集 | 82210 |
| 测试集A | 10276 |
| 测试集B | 10276 |
| 总计 | 102762 |
本次评测任务计划仅采用训练集及测试集A以作评测。
评价标准
评测性能时,本任务主要采用宏平均F1值作为评价标准,即对每一类计算F1值,最后取算术平均值,其计算方式如下:
其中 为第i类的 值,n为类别数,在本任务中n取12。
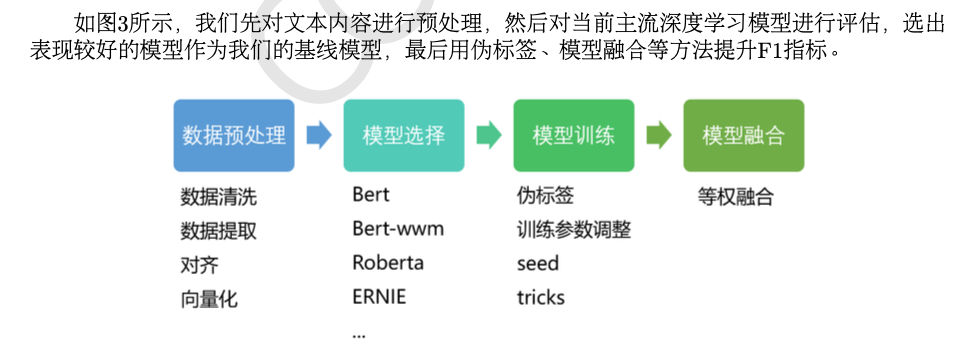
赛题方案总结
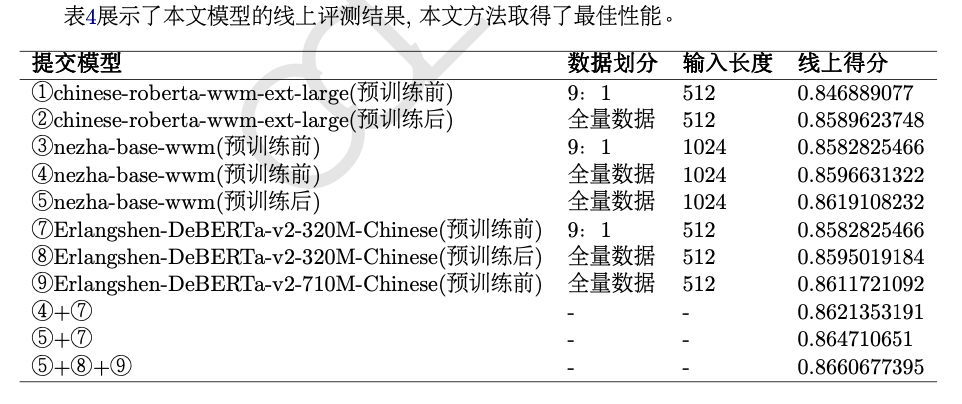
本次评测共有 60 支参赛队伍报名。最终有 34 支参赛队伍提交结果。共有 15 支队伍得分超过 baseline。鉴于篇幅有限, 仅展示超过 baseline 的队伍得分结果, 如表4所示。
比赛方案分析
第一名
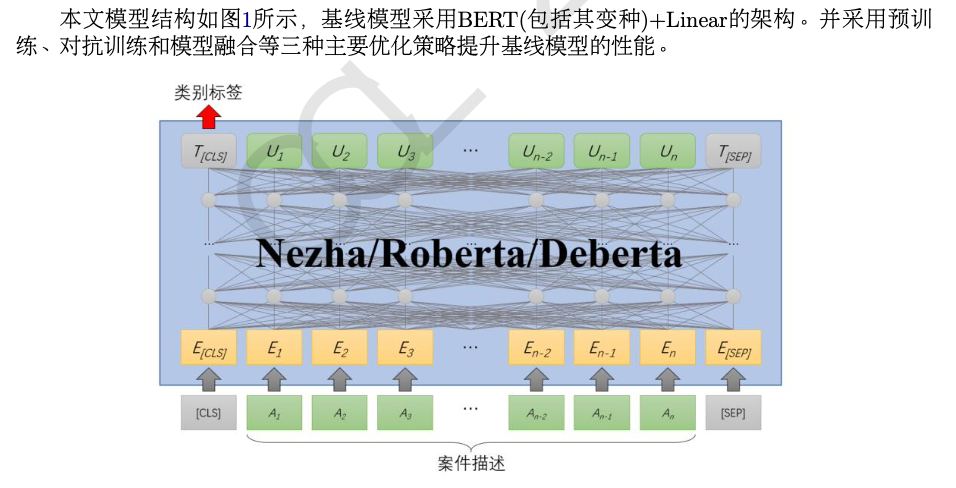
第一名使用了多个不同的预训练模型进行评测, 包括Chinese-RoBERTa-wwm-extlarge
(Cui et al., 2021)、 NEZHA-base-wwm
(Wei et al., 2019) 和Erlangshen-DeBERTav2
(Wang et al., 2022) 等系列模型, 在这些模型上进行领域预训练 (Sun et al., 2019; Gururangan et al., 2020)任务, 同时结合了 FreeLB (Zhu et al., 2019) 的对抗训练方法, 最终提交结果融合了 NEZHA 模型与参数量为 的 Erlangshen 模型。
第二名
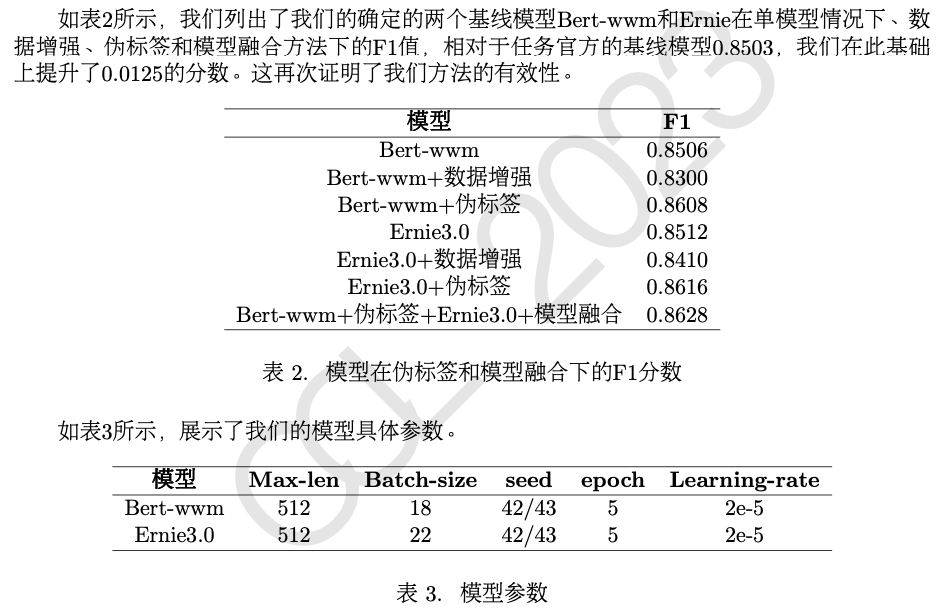
第二名尝试了BERT-base
、BERT-wwwm
、BERT-wwm-ext
、ERNIE
(Sun et al., 2019)和Chinese-RoBERTa-wwm-ext
等多个预训练模型, 根据实验结果, 选择了BERT-wwm
和ERNIE
作为基底模型, 针对数量较少的类别采取了伪标签 (Rizve et al., 2021)的方法增加了训练集数量, 最后提交结果融合了这两个基底模型。
第三名
第三名以NEZHA
模型为基底模型, 采用了FGM
(Miyato et al., 2016) 对抗训练方法增加扰动, 并使用了指数移动平均策略更新网络权重。
第无名
第五名基于NEZHA
模型, 采用了层次分解方法延拓了位置编码向量, 同时也采用了对抗训练策略增加模型的鲁棒性。
第六名
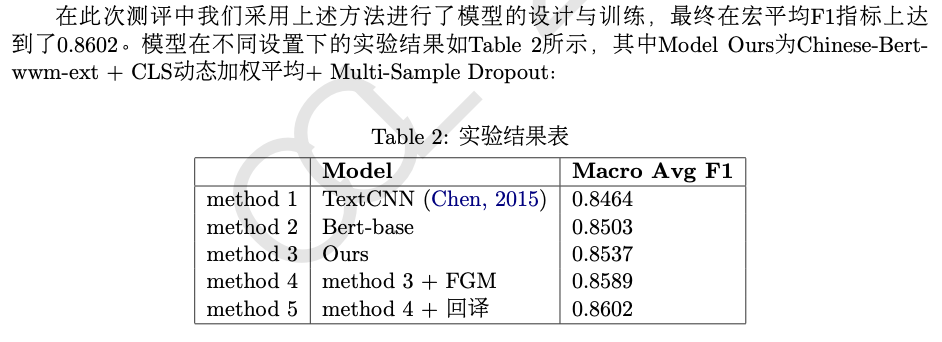
第六名采用Chinese-BERT-wwm-ext
作为基底模型, 通过对CLS
位置进行动态加权平均增强向量的语义表征能力, 同时采用Multi-Sample Dropout
方法对输出进行多次Dropout
以增强模型泛化能力, 此外还通过回译 (Wei and Zou, 2019)的方式, 扩充了数量较少类别的样本规模, 最后同样在训练过程中加入了FGM
对抗训练方法。
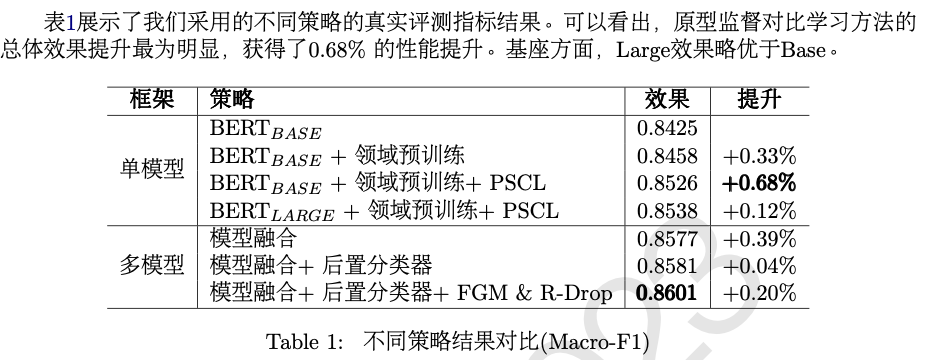
第七名
第七名基于原型监督对比学习 (Wang et al., 2021)思想, 以BERT-base
、BERT-large
为基底模型, 结合了领域预训练、FGM
对抗训练、R-Drop
(Liang et al., 2021) 等方法, 并针对混淆程度较高的类别使用后置分类模块进行二次补充判别。
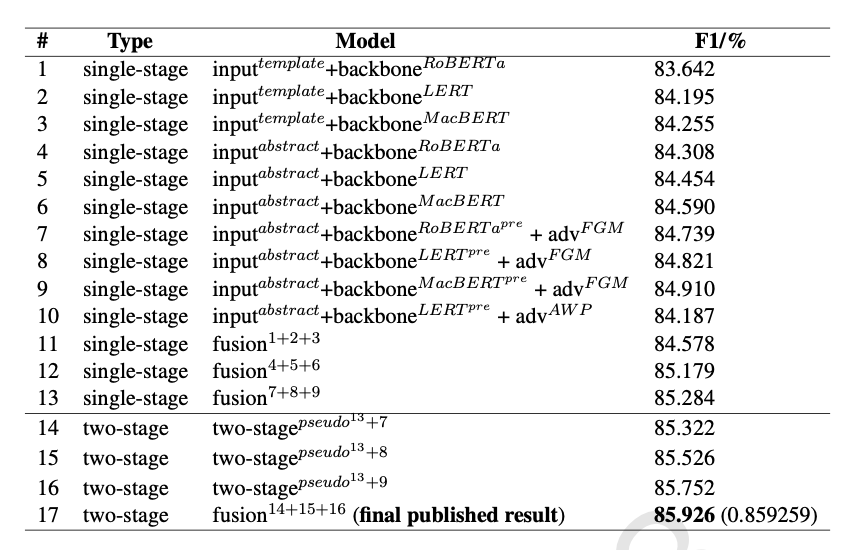
第八名
第八名采用Chinese-RoBERTa-wwm-ext
、LERT
(Cui et al., 2022)、MacBERT
(Cui et al., 2020) 等作为基底模型, 结合领域预训练方法, 以增强模型语义理解能力, 通过FGM
、AWP
(Dong et al., 2020) 对抗训练和多次随机采样方法, 以提高模型语义挖掘能力。此外, 还将伪标签 (Lee, 2013)样本添加到训练集中, 进行了语义增强。最后结合了模型融合方法进行预测以获得结果。
结果分析
从本次任务采用模型来看, 本次评测队伍基本采用的是 BERT 类的模型, 典型的包括 BERT、RoBERTa 等, 还有中文预训练模型 ERNIE、NEZHA 等。这表明在目前的文本分类任务上, 主要还是以传统的预训练模型结合微调技术的方法为主, 而当下较为火热的大模型,如 ChatGPT 等并未被采用进行本任务。当然, 这可能跟本次任务未能提供相关支持有关。
从本次任务的结果来看, 对抗训练、模型融合是使用最多且有效的方法。作为案件简述文本来说, 其中噪声较多, 对于分类并无帮助的文本内容较多, 例如各类未涉及隐私的个人信息、时间、银行名称等, 同时由于数据脱敏时采用的方式较为直接, 文本中残留不少标点符号, 因此对抗训练通过增加扰动, 可能增强了模型对于这类信息的抗干扰性, 从而提高了模型性能。此外, 模型融合作为一般性策略, 在各类评测任务中均有较好效果, 本次任务结果也验证了这一点。
在数据不平衡方面, 部分队伍通过伪标签或回译的方法取得了较好的结果。伪标签方法通过将无标签的测试集样本, 经模型预测后标注伪标签, 加入到训练集中, 增加了训练集数量,从结果上来看, 有效缓解了部分类别样本数量较少的问题。回译方法通过将将数据样本翻译为另一语言甚至多个语言后, 再翻译回原语言的方式, 同样增加了不平衡类别的样本数量, 从而提高了模型结果。
本次任务可看作是电信网络诈骗领域的文本分类任务, 即特定领域文的本分类任务, 因此部分队伍采用了领域预训练的方法, 通过在本次任务的领域语料上进行继续预训练任务, 使模型能够学习到领域中数据分布特征。本次任务结果也验证了该方法的有效性。
此外, 少数队伍注意到了数据中存在易混淆的类别, 并提出后置分类的方法, 以解决该问题。该方法通过在模型预测所有类别后, 针对易混淆类别进行二次补充判别, 最终提高了易混淆类别识别效果以及模型整体的预测结果。易混淆类别的存在, 根源于分类体系的定义不够明确清晰, 类别之间划分边界较为模糊, 从而导致类别混淆、类别重叠等问题。
方案分享
中原工学院 & 河南省网络舆情监测与智能分析重点实验室

CVTE
中国科学院信息工程研究所
广东工业大学 & 桂林理工大学

中国电信数字智能科技分公司
South China University of Technology & Northeast Petroleum University
💖私聊小助手,领取数据集 + 报告PDF汇总💖
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

