




时序数据库的持续聚集和实时数仓的实时分析都会用到流式计算,流式 计算属于分布式计算框架,在 Hadoop 生态圈中流式计算框架比较丰富,如Storm、Spark Streaming、Flink、Kafka Streams、Heron 等。
最近几年随着 SQL 的回归,流式计算也开始向数据库方向发展,陆续出现几个流数据库,如 HStreamDB、Materialize 等,流数据库对外 SQL 接口, 使用流数据库进行流式计算就像操作传统数据库一样方便。数据库中 SQL 语句经过解析器解析和优化器优化后转换成执行计划树,执行计划树的结构和 流式计算框架中的拓扑图结构非常相似,因此流式计算系统可以做成数据库 的样子对外提供 SQL 接口。标准 SQL 语句转换成的执行计划树是有向无环图(Directed Acyclic Graph,DAG),复杂的流式计算框架,比如 Flink 拓扑图可以是环状的,称为有向循环图(Directed Cyclic Graph,DCG),针对这些情况需要对标准 SQL 语法做一下扩展。下面是流数据库 Materialize 用 SQL 语句进行流式计算的例子,如图 7-15 所示。
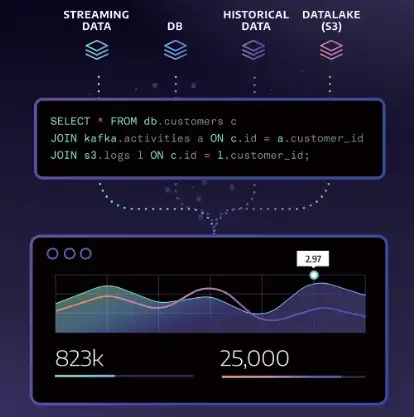
Materialize 的成功说明把流式计算框架做成 SQL 执行引擎技术上可行。AntDB 后续也会借鉴 Materialize 的实现原理在分布式 SQL 执行引擎中加入流式计算能力。
关于AntDB数据库
AntDB 数据库始于 2008 年,在运营商的核心系统上,为全国 24 个省份的 10 亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近 15 年,并在通信、金融、交通、能源、物联网等行业成功商用落地。
