




一、背景
当前大数据 Hadoop 生态圈涉及服务很多,例如 HDFS 分布式文件系统、YARN 分布式计算框架、Hive 大数据仓库、HBase 分布式列存储数据库、Kafka 流处理平台;每种服务都有自己的权限管理,比如 HDFS 文件系统权限、YARN 队列权限、Hive 跟 HBase 的数据库/表/列管理权限,Kafka 主题等权限,不管是哪个服务都有自己的权限实现方式,基本都有各自的 Acl 权限管理。如何将这些服务权限统一管理起来,显得尤为必要,而一套安全的系统更需要将认证和授权有效统一起来,只有经过身份认证才能确定是准确用户,避免恶意访问,进而对用户进行权限管控。
对于认证体系的选择,Hadoop 生态圈选用了 Kerberos;对于权限管控体系的选择,目前有 Ranger/Sentry,其中 Ranger 提供了基于访问控制策略的标准授权方式,我们在项目中选择了 Ranger 作为权限管控。Ranger 插件实现了各个服务的 Acl 管理类,从而使大数据生态系统有了统一的认证授权体系。想要访问系统,则必然离不开使用者。如何将用户跟系统关系起来以便进行使用,则需要对用户、认证体系、生态圈有所了解。本篇便将其关系梳理了下,方便大家理解。
二、用户访问体系介绍
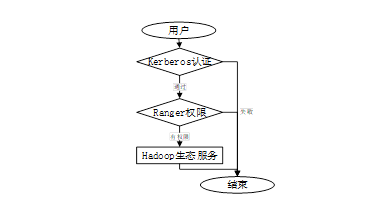
图 1 User/Kerberos/Ranger/服务关系
首先,对于如上几个服务做简单说明。用户访问 Hadoop 生态圈服务,需要先经过 Kerberos 认证,只有认证通过的用户,方可进行下一步操作,如果认证失败,则流程结束;经过认证的用户如果访问 HDFS 服务,则需要检查其是否均有路径的读写权限,该权限由 Ranger 服务进行管控配置,只有 Ranger 权限检查成功方可对 HDFS 进行相关操作,如果权限不通过,则流程结束。同理访问 Hive 数据库、表等权限时,同样需要 Ranger 上有对数据库、表等访问权限才可进一步访问。
1、用户管理
其次,看下用户是怎么来的,这里我们选择了 Ldap 作为用户存储的来源,看下 Ldap 是如何跟用户和用户组关联的。
Ldap【Lightweight Directory Access Protocol】是轻量级目录访问协议,本身是一个小型数据库,而其数据目录以树状层次结构进行存储,可提供统一的用户管理。由于 Ldap 可采用了 Server+Client 的方式进行运行,可通过一次创建,实现处处可访问,故用其作为用户管理再合适不过了。
Ldap 内部主要组成 DN【Distinguished Name】、CN 以及 OU,因为是树状结构,Ldap 任何一个叶子结点均可以回溯到根部 DN;Ldap 中每一条记录被称为 entry,其表示方法也按照根类别进行设置,例如用户 smokeuser,其在 Ldap 中的表示就可以采用如下方式 dn: cn=smokeuser,ou=users.dc=hadoop,dc=cmss,dc=org,用户组可以表示为:dn: cn=hadoop,ou=groups,dc=hadoop,dc=cmss,dc=org。
通过 Ldap 的每条记录信息可以很容易找到对应的用户;当该用户去访问 Hadoop 生态服务时,需要进行认证。这里我们选择了 Kerberos 作为身份认证体系。
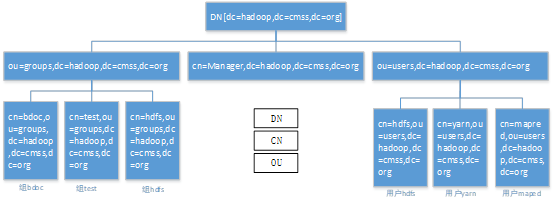
图 2 Ldap 内部结构
2、用户认证
Kerberos 是一种基于加密 Ticket 的身份认证协议,主要由 KDC(Key Distribution Center)、Client 和 Service 三部分组成。其自带一个数据库【默认在/var/kerberos/krb5kdc 下】,该数据库存储具有认证权限的用户服务主机等信息,以 principal 进行表示,Kerberos 可以选择 Ldap 作为其数据库,仅需要在其配置文件/etc/krb5.conf 中 realms 下加入 database_module=openLdap_Ldapconf,配置 Ldap 的 DN、密码等配置便可以实现联动。
Kerberos 使用 principal 作为用户或服务的主体,这一点便是 Ldap 能够存储的用户模块部分,每个访问 Hadoop 生态服务的用户均需要证明自己是 Kerberos 中的某个主体,才能进一步访问集群服务。
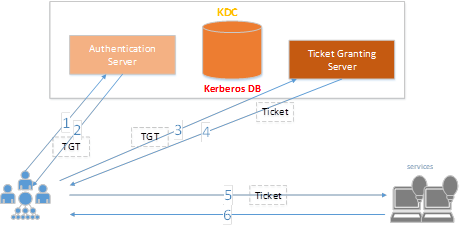
图 3 Kerberos 服务相关关系
3、用户授权
经过认证后的用户,访问服务时需要检查其是否具有对应服务的管理权限,此处选择 Ranger 作为统一授权服务。Apache Ranger 是一个提供集中式安全管理的框架,能够对 Hadoop 生态组件【例如 HDFS、Yarn、Hive、HBase、Kafka 等】进行数据访问控制,用户可通过 Ranger 控制台进行策略配置来控制用户访问。
Ranger 由 Ranger Admin、Ranger Plugin 以及 Ranger UserSync 三个组件构成,其中 Ranger UserSync 便是用于进行用户同步的一个工具,通过该组件,管理员便可以方便的从操作系统或者 Ldap Server 中获取用户和用户组,默认 1min 同步一次用户。涉及配置如下:ranger.usersync.Ldap.url、ranger.usersync.Ldap.binddn,如此管理员在进行权限设置时,便可选择对应的用户/用户组进行授权操作。
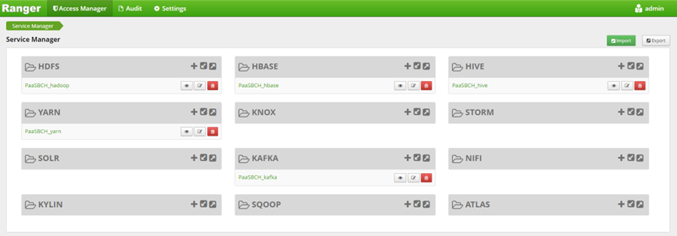
图 4 Ranger 服务管理页面
4、用户访问
经过授权的用户,是如何跟 Hadoop 进行关联的,一起看下 Hadoop 相关的内容。Apache Hadoop 是 Apache 基金会用于解决海量数据存储和分析计算的一个分布式系统架构。当用户访问 Hadoop 文件系统时,最终都会落在主机层面去执行相关的操作。
主机层面的目录权限主要由用户、用户属组、其他三部分组成,如果没有对应的用户,则检查其所属组权限,而 Hadoop 的用户组由其配置 core-site 的 hadoop.security.group.mapping 属性决定,该属性默认从操作系统读取用户的属组,常见属性值有 JniBasedUnixGroupsMappingWithFallback、LdapGroupsMapping、CompositeGroupsMappingHadoop 等。
分布式集群规模成千上万,不管是存储还是计算最终都会在操作提供层面进行执行,如何保证存储或者计算时任务在执行到相应节点时能得到该用户跟用户,就涉及到了另一个服务 Nslcd。
Nslcd 顾名思义叫做 Naming service Ldap client Daemon,其是专门用来处理 Ldap 服务查询的一个后台进程,其作为客户端可以从 Ldap 中获取相关用户和用户组,通过此服务当任务执行到对应节点时便可以读取到对应的用户和用户组。
由于 Nslcd 本身并未提供缓存功能,如果频繁读取 Nslcd,会造成巨大压力,为缓解 Nslcd 压力,使用操作系统自带的 Nscd 服务【Nscd is a daemon that provides a cache for the most common name service requests】,其提供了对于 group、password、hosts 以及 services 四种名称服务的缓存,从而大规模集群在到操作系统层面执行任务时便可以快速获取对应的用户、用户组。
图 5 Ldap 服务组件关联组件
如此整个生态圈的用户、用户组便通过 Ldap 关联了起来。而为什么使用 Ldap 这个数据库,是因为其诞生之初就是为了查询、浏览以及搜索而优化的一种树状结构组织的数据库,读性能特别强,同时支撑多集群管理模式,能很好实现对于超大规模下用户的获取。
