





前言
众所周知,数据库的优化器是核心技术中关键的的一环,由于yashandb使用了数据块、区、段、表空间的逻辑存储方式,按理很多调优方面类似Oracle。所以下面的测试用例在yashandb做一轮,同样也会在Oracle上也做一轮测试。从客户端操作使用感受可用性,从服务端提供的工程规则感受丝滑性。
测试思路
-
用例一,单表插入批量数据,不加索引MAX/MIN查询以及 加索引后进行MAX/MIN查询
-
用例二, 单表建立分区及索引 ,并插入批量数据, 进行分区及索引的查找
-
用例三,索引查询单表,观察回表与不回表的差别
-
用例四,插入空值后索引是否快,对比全表扫描的差别。
-
用例五,插入8个表数据,查看表索引大小,以及索引表的高度,查看表的统计数据,并对比两个大表体验。
-
用例六,两表关联,通过不同顺序和指定,查看优化器分配的表连接用的算法。
准备语句
create table single_t as select * from dba_objects;
insert into single_t select * from single_t;
insert into single_t select * from single_t;
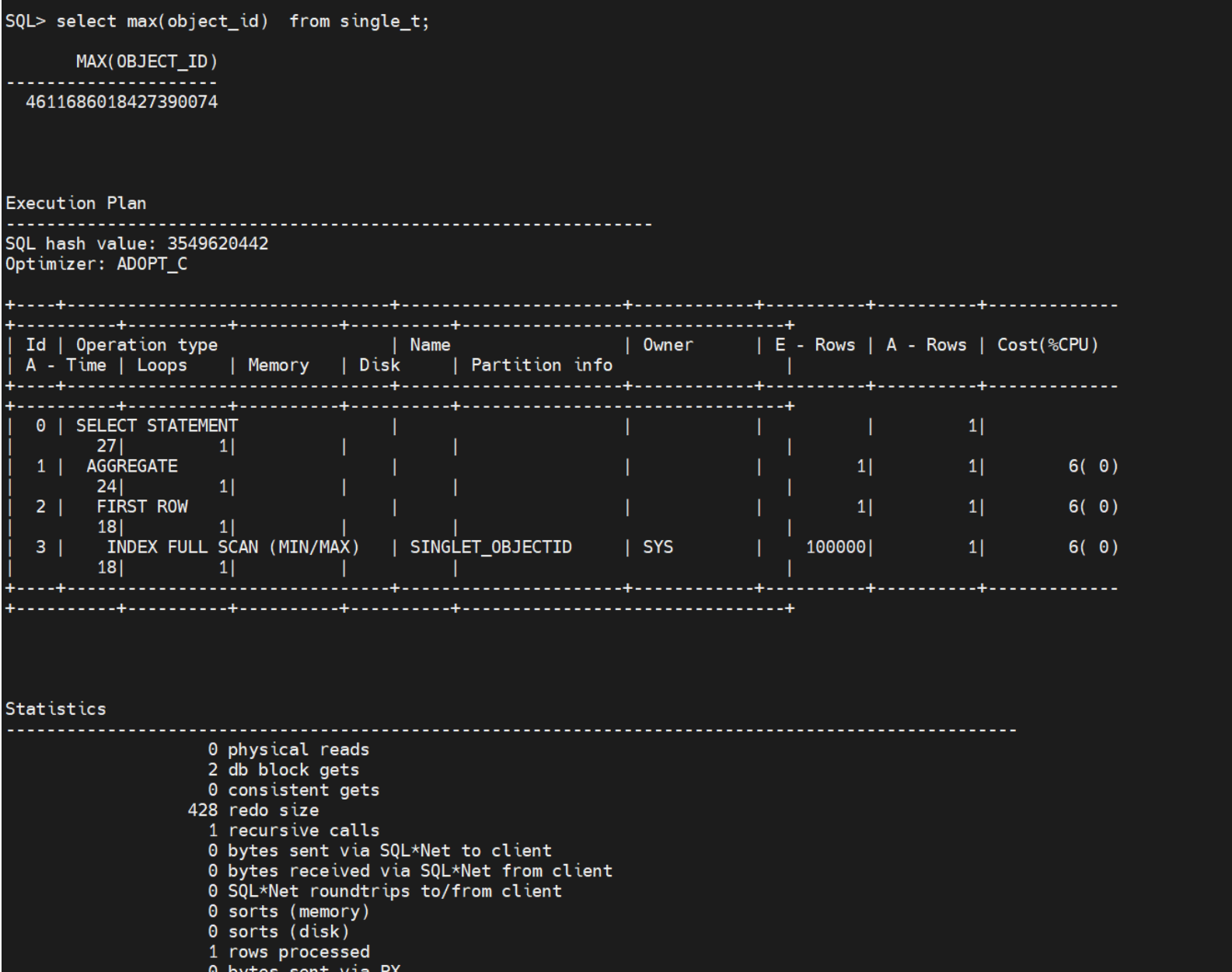
select max(object_id) from single_t;
select min(object_id) from single_t;
create index singlet_objectid on single_t(object_id);
create table part_t(id int,col2 int, col3 int)
partition by range(id)
(
partition p1 values less than(10000),
partition p2 values less than(20000),
partition p3 values less than(30000),
partition p4 values less than(40000),
partition p5 values less than(50000),
partition p6 values less than(60000),
partition p7 values less than(70000),
partition p8 values less than(80000),
partition p9 values less than(90000),
partition p10 values less than(100000),
partition p11 values less than(110000),
partition p12 values less than(120000),
partition p13 values less than(130000),
partition p14 values less than(140000),
partition p15 values less than(150000),
partition p16 values less than(MAXVALUE)
);
insert into part_t select rownum,rownum+1,rownum+2 from dual connect by rownum<=2100000;
create index idx_par_t_col2 on part_t(col2) local;
create index idx_par_t_col3 on part_t(col3) ;
ALTER SESSION SET statistics_level=ALL;
set autotrace traceonly;
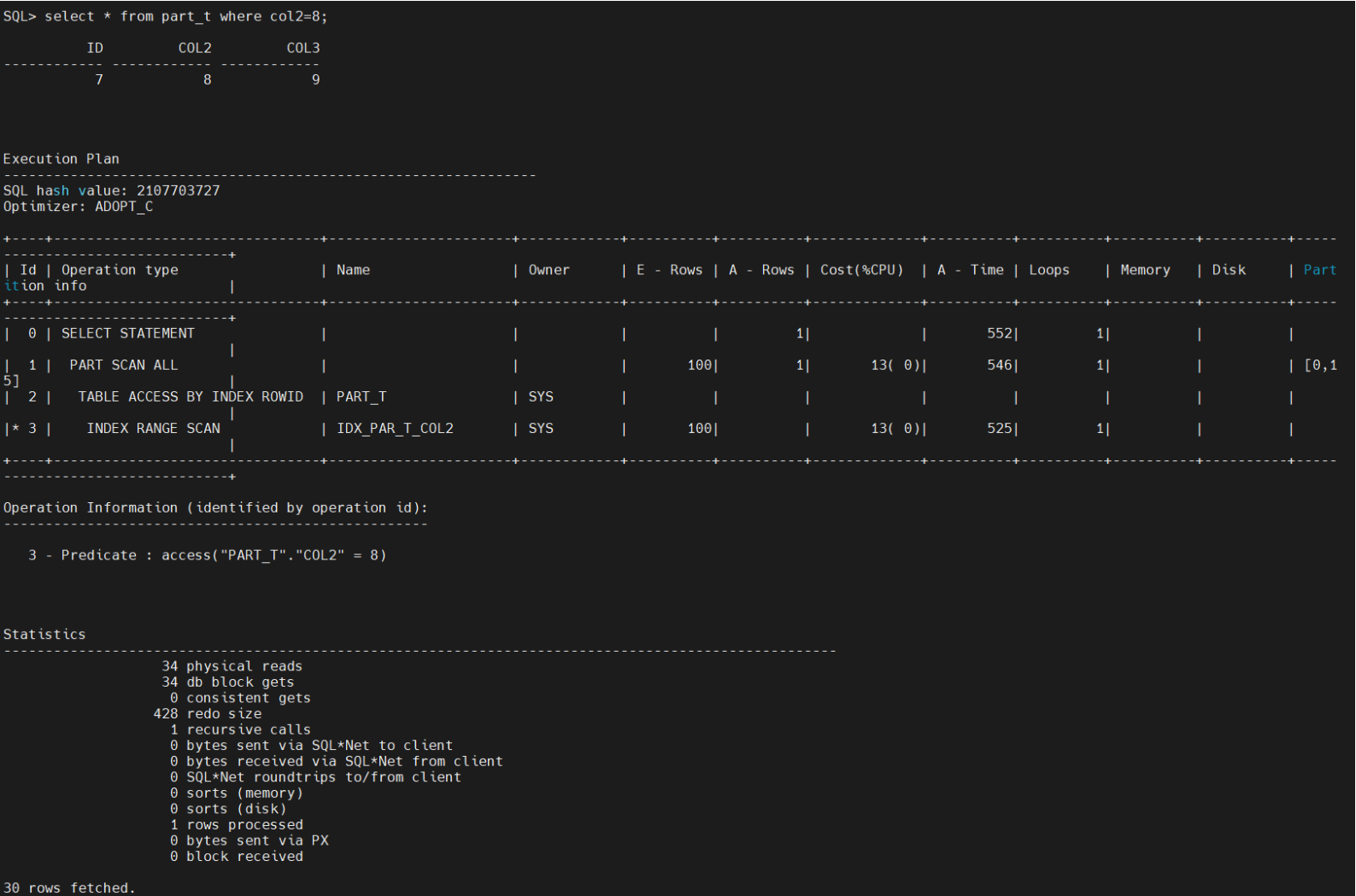
select * from part_t where col2=8;
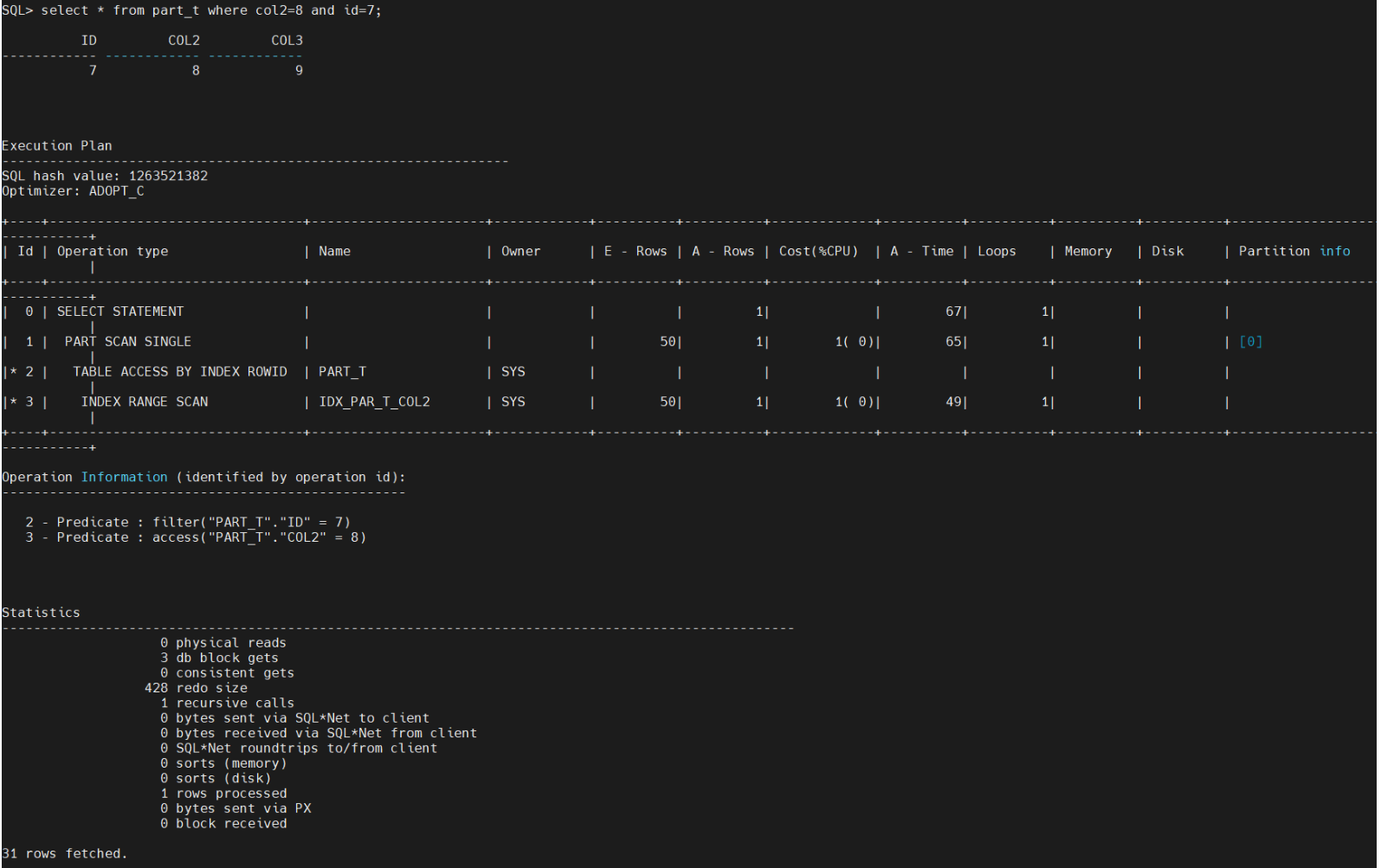
select * from part_tab where col2=8 and id=7;
insert into part_t values(1,null,null);
select * from part_t where col3=500000;
select col3 from part_t where col3=500000;
create table part_t2 as select * from part_t;
用例一
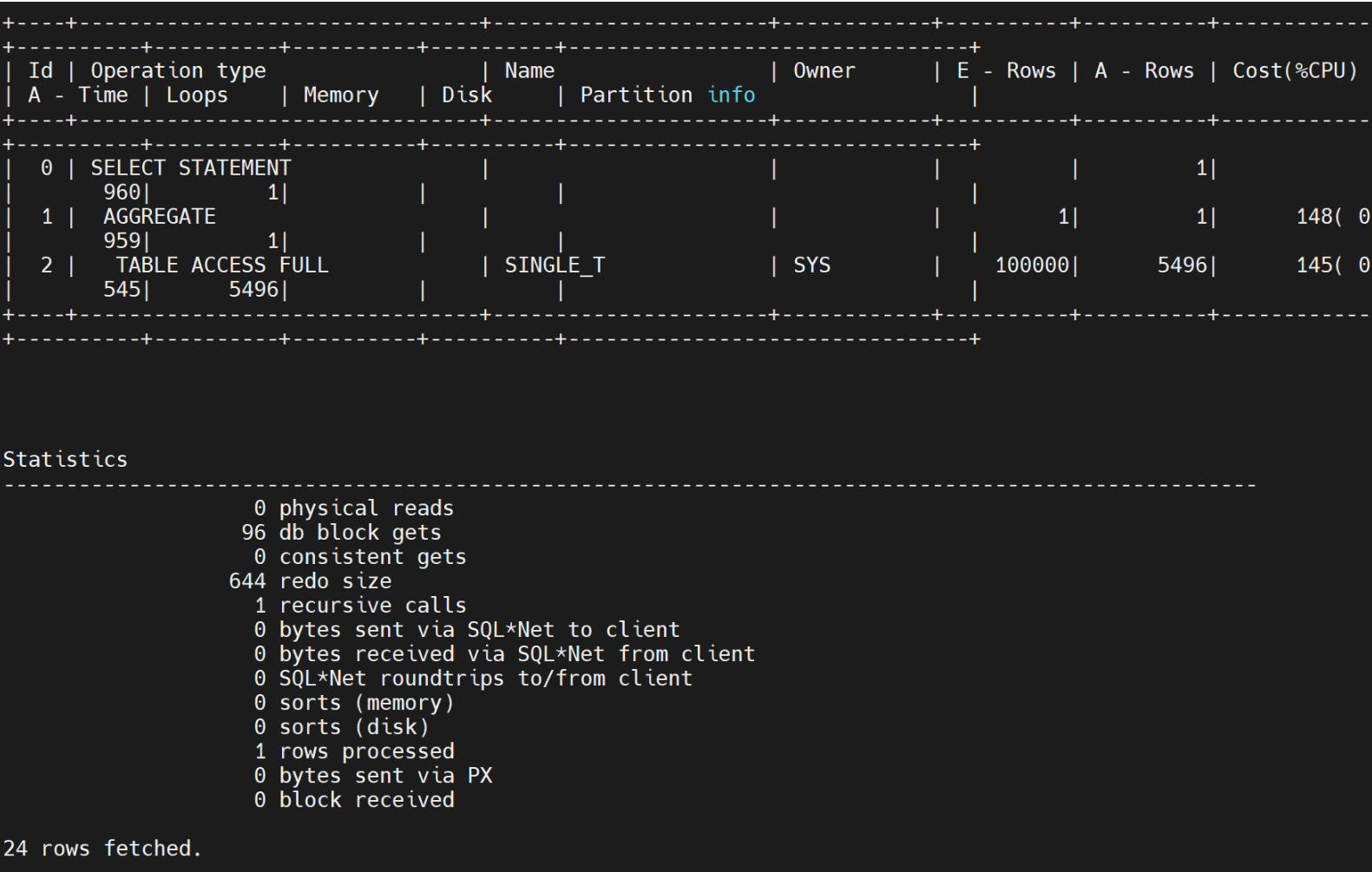
select max(object_id) from single_t;未加索引前,整个表走了全表索引,约花费了96个db blocks get
加了索引后,表往索引的方向进行,只用了2个db block
用例二
select * from part_t where col2=8 虽然有普通 索引 ,但是分区上走了所有的分区的查找,从分区1到分区15都走遍了,34个物理读 ,34个db block。
select * from part_t where col2=8 and id=7 因为有分区索引 ,所以路径上走了分区的查找,只花费了3个db blocks gets。
用例三
select * from part_t where col3=50000很明显因为*走了回表。3个物理读 ,4个逻辑读 。
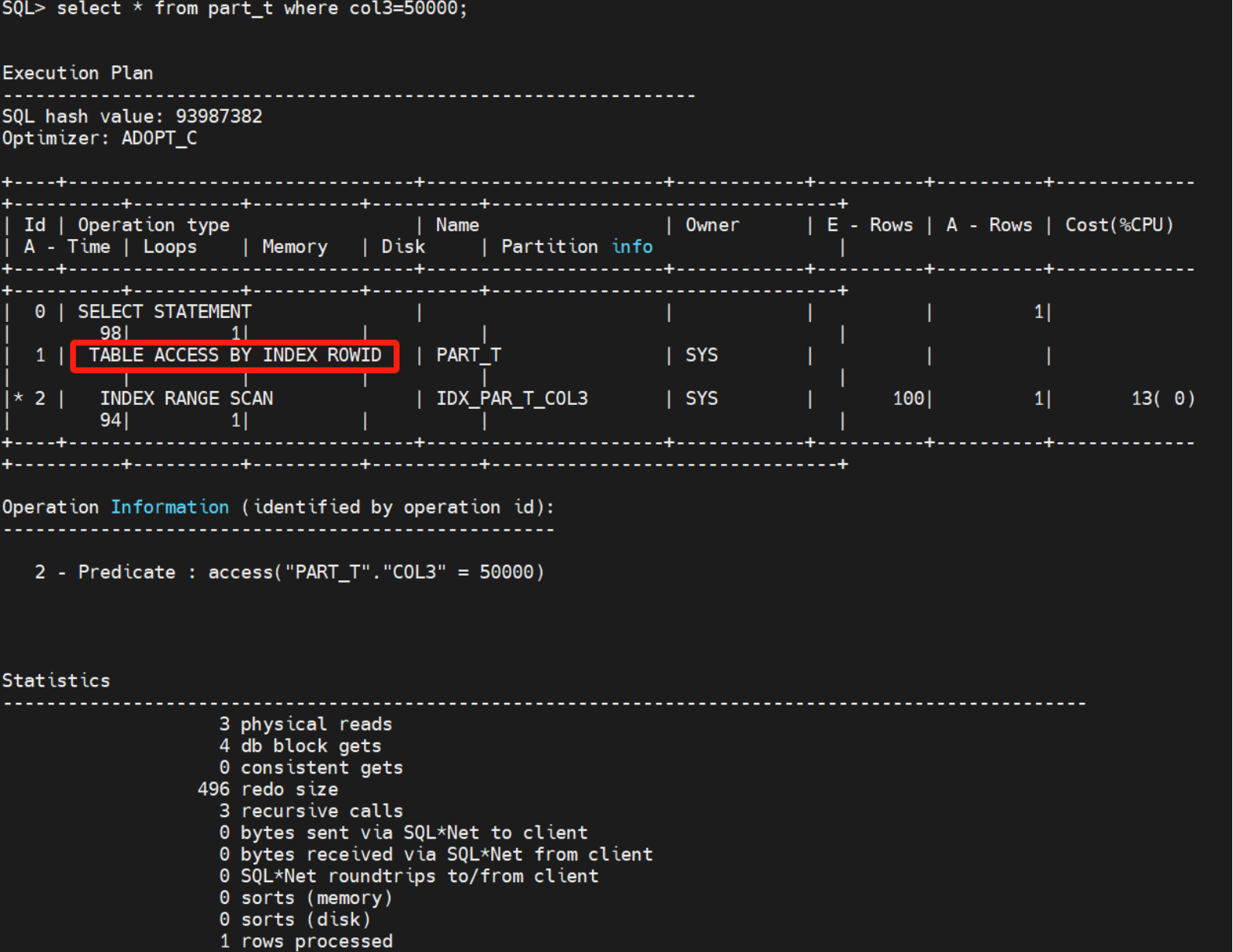
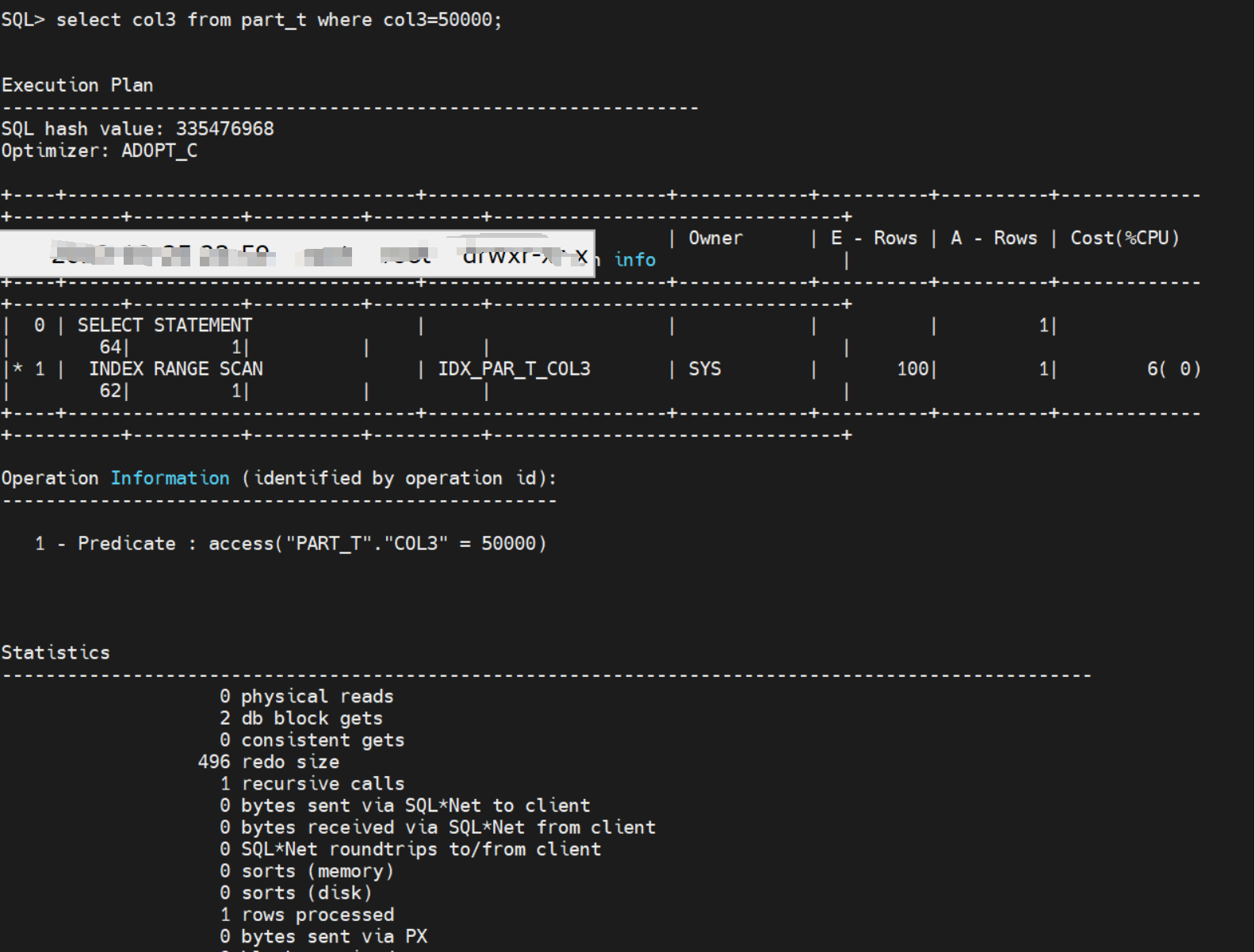
select col3 from part_t where col3=50000我们把*改成索引对应值,回表就消失了,只有2个db block
用例四
目前part_t表没有空值,count等聚集函数还会走索引,26035个物理读,4213845个逻辑读 。
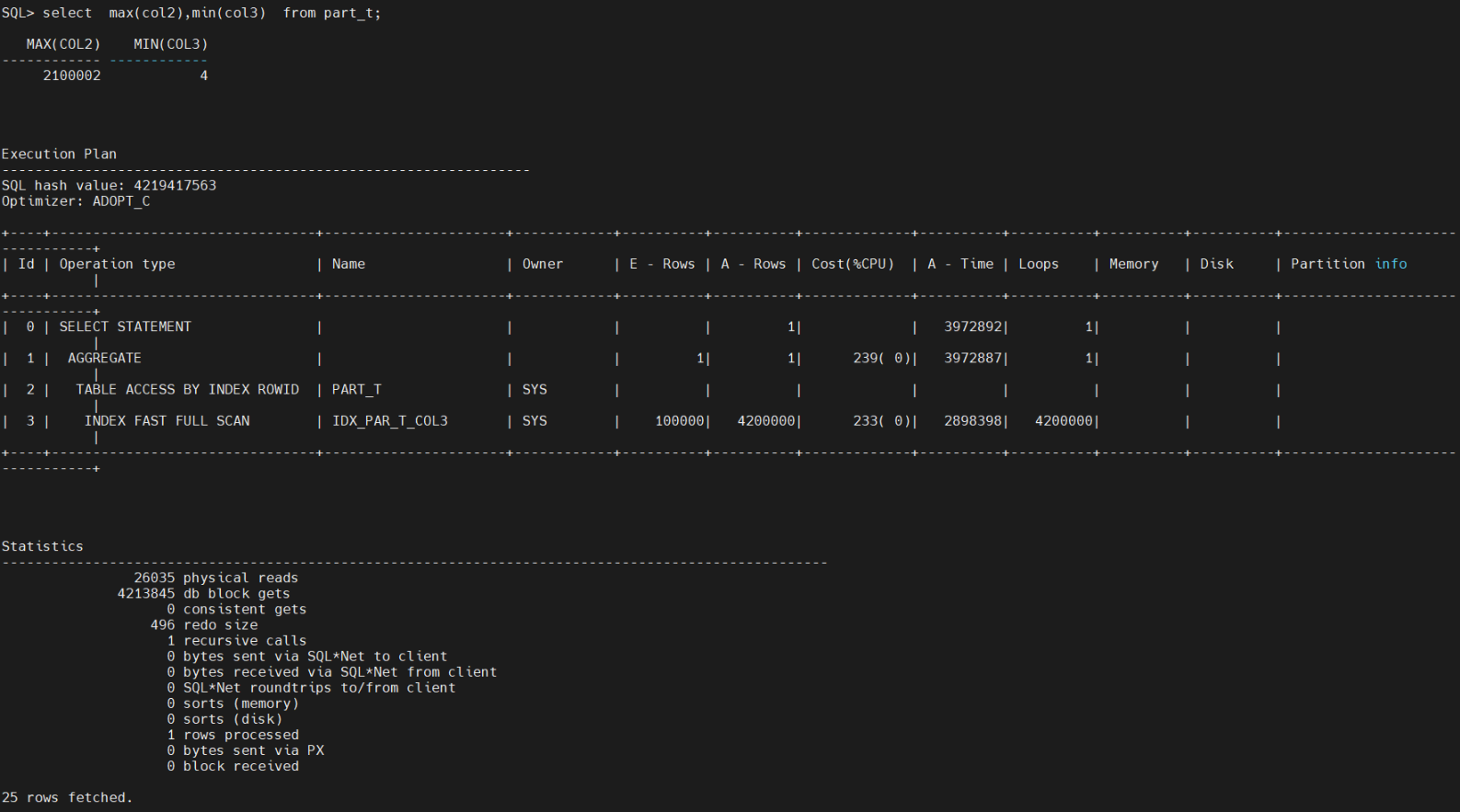
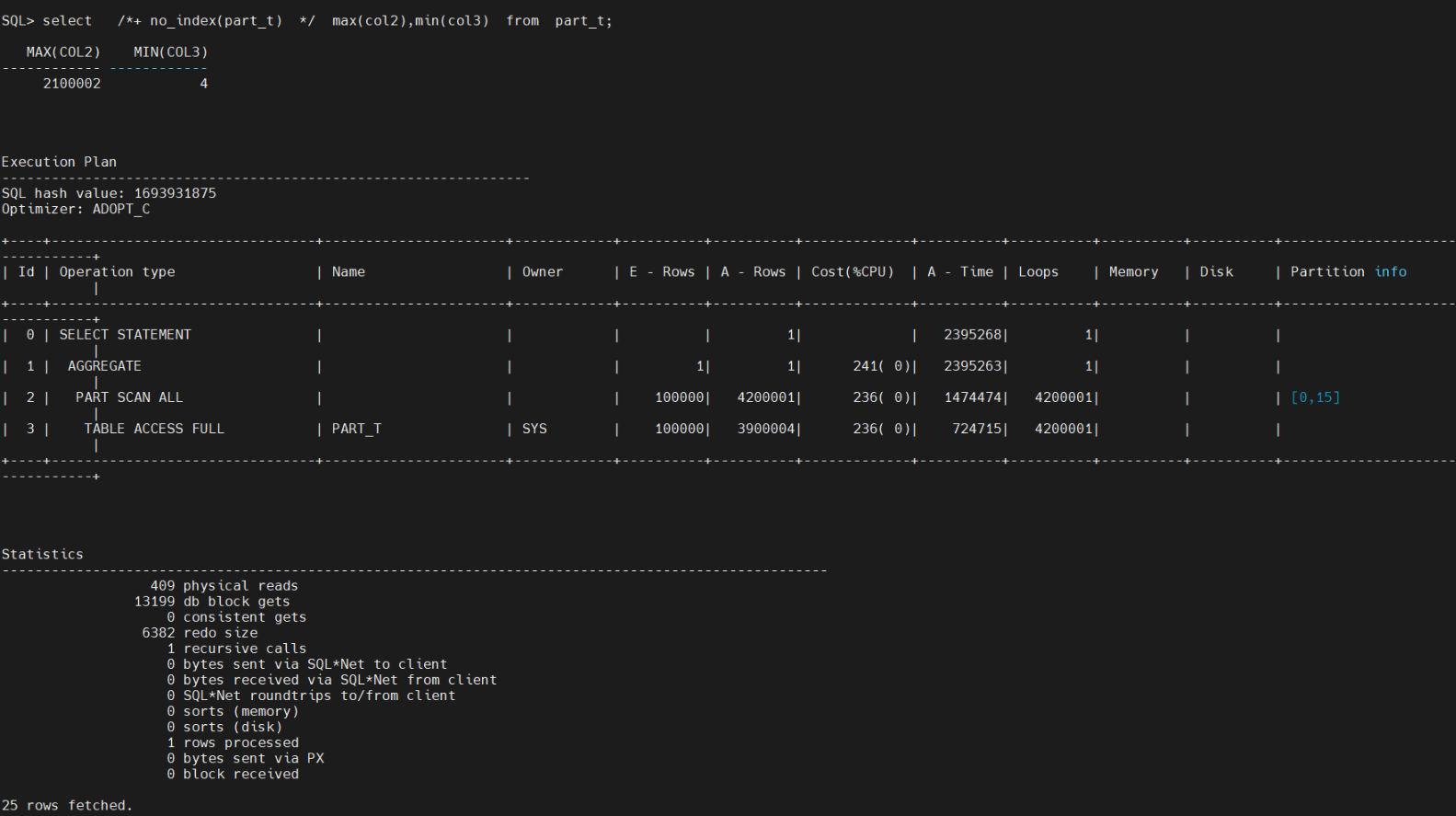
insert into part_t values(1,null,null); 插入空值后,预期会这个空值,没有走索引,走了全盘索引
select max(col2),min(col3) from part_t;发现还是走了索引,物理读和逻辑读 差不多。
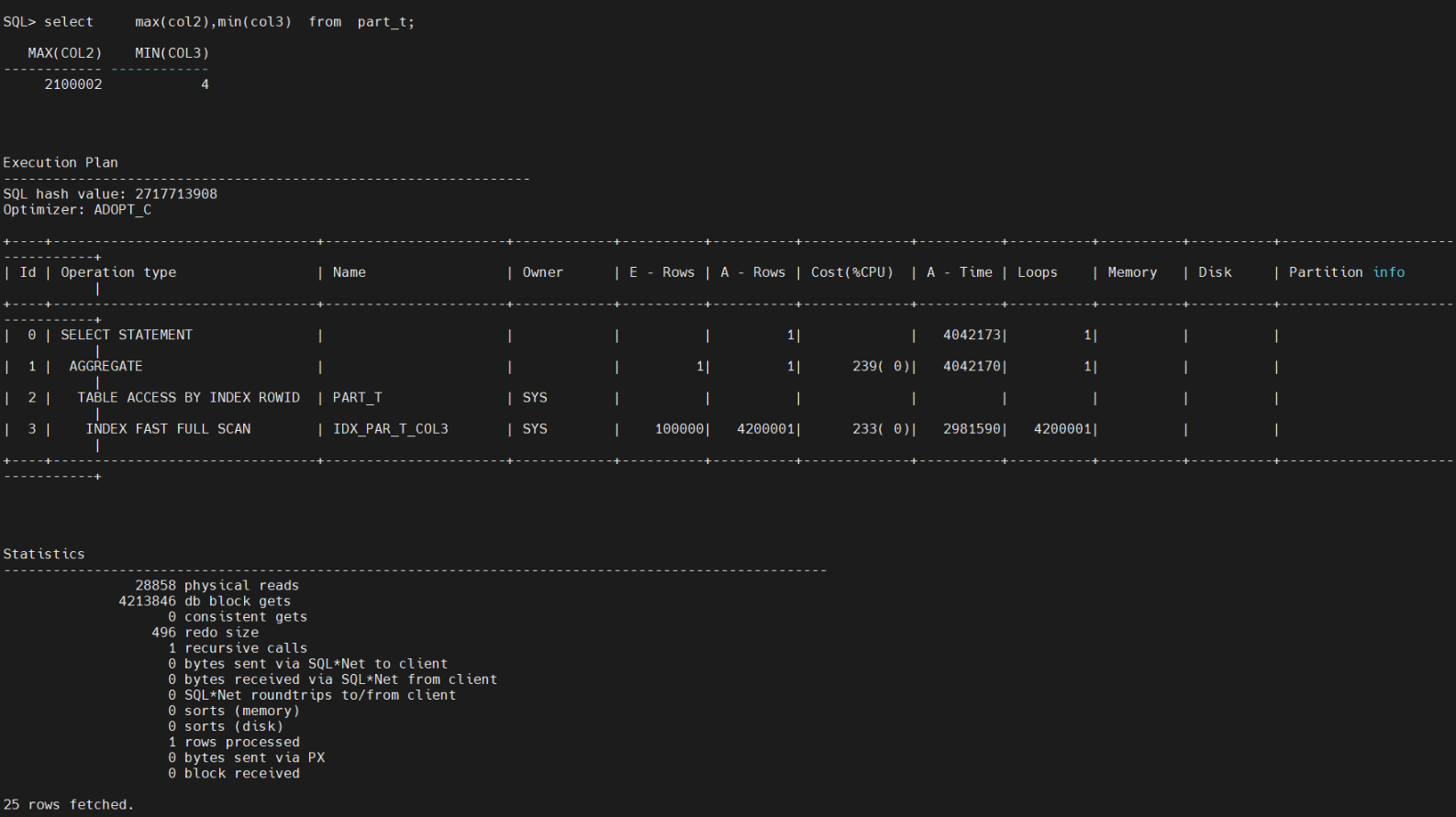
select /*+ no_index(part_t) */ max(col2),min(col3) from part_t; 通过HINT没有走索引,终于走了全盘扫描,物理读和逻辑读 比原来好很多了。
用例五
drop table t1 purge;
drop table t2 purge;
drop table t3 purge;
drop table t4 purge;
drop table t5 purge;
drop table t6 purge;
drop table t7 purge;
drop table t8 purge;
create table t1 as select rownum as id,rownum+1 as id2 from dual connect by level<=1;
create table t2 as select rownum as id,rownum+1 as id2 from dual connect by level<=10;
create table t3 as select rownum as id,rownum+1 as id2 from dual connect by level<=100;
create table t4 as select rownum as id,rownum+1 as id2 from dual connect by level<=1000;
create table t5 as select rownum as id,rownum+1 as id2 from dual connect by level<=10000;
create table t6 as select rownum as id,rownum+1 as id2 from dual connect by level<=100000;
create table t7 as select rownum as id,rownum+1 as id2 from dual connect by level<=1000000;
create table t8 as select rownum as id,rownum+1 as id2 from dual connect by level<=10000000;
create index idx_id_t1 on t1(id);
create index idx_id_t2 on t2(id);
create index idx_id_t3 on t3(id);
create index idx_id_t4 on t4(id);
create index idx_id_t5 on t5(id);
create index idx_id_t6 on t6(id);
create index idx_id_t7 on t7(id);
create index idx_id_t8 on t8(id);
BEGIN
DBMS_STATS.GATHER_INDEX_STATS('sys', 'idx_id_t1', '', 0.2, 2,'ALL');
DBMS_STATS.GATHER_INDEX_STATS('sys', 'idx_id_t2', '', 0.2, 2,'ALL');
DBMS_STATS.GATHER_INDEX_STATS('sys', 'idx_id_t3', '', 0.2, 2,'ALL');
DBMS_STATS.GATHER_INDEX_STATS('sys', 'idx_id_t4', '', 0.2, 2,'ALL');
DBMS_STATS.GATHER_INDEX_STATS('sys', 'idx_id_t5', '', 0.2, 2,'ALL');
DBMS_STATS.GATHER_INDEX_STATS('sys', 'idx_id_t6', '', 0.2, 2,'ALL');
DBMS_STATS.GATHER_INDEX_STATS('sys', 'idx_id_t7', '', 0.2, 2,'ALL');
DBMS_STATS.GATHER_INDEX_STATS('sys', 'idx_id_t8', '', 0.2, 2,'ALL');
END;
/
select index_name,blevel,leaf_blocks,num_rows,distinct_keys,clustering_factor
from user_ind_statistics where table_name
in('T1','T2','T3','T4','T5','T6','T7','T8');
select segment_name, segment_type,tablespace_name,bytes,blocks,extents from user_segments where segment_name in( 'IDX_ID_T1', 'IDX_ID_T2', 'IDX_ID_T3', 'IDX_ID_T4', 'IDX_ID_T5', 'IDX_ID_T6', 'IDX_ID_T7','IDX_ID_T7');
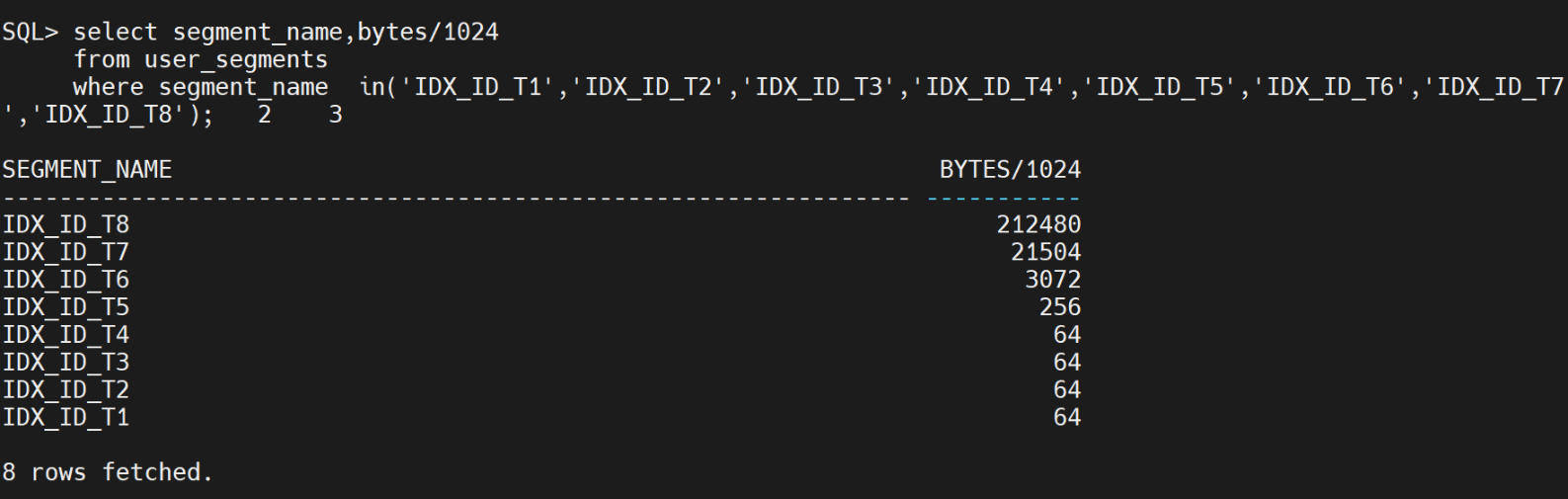
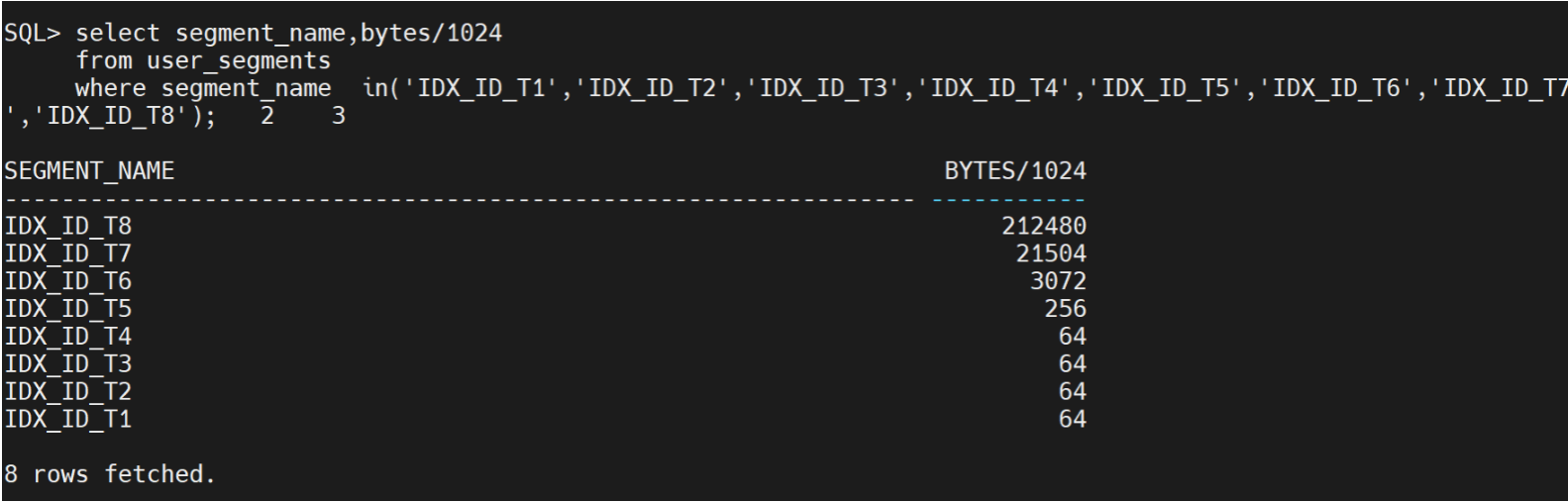
USER_SEGMENTS 用于查询每个表拥有的段,列出idx_id_t1到idx_id_t8一共8个索引的占用段大小。最小索引占用的段64KB。
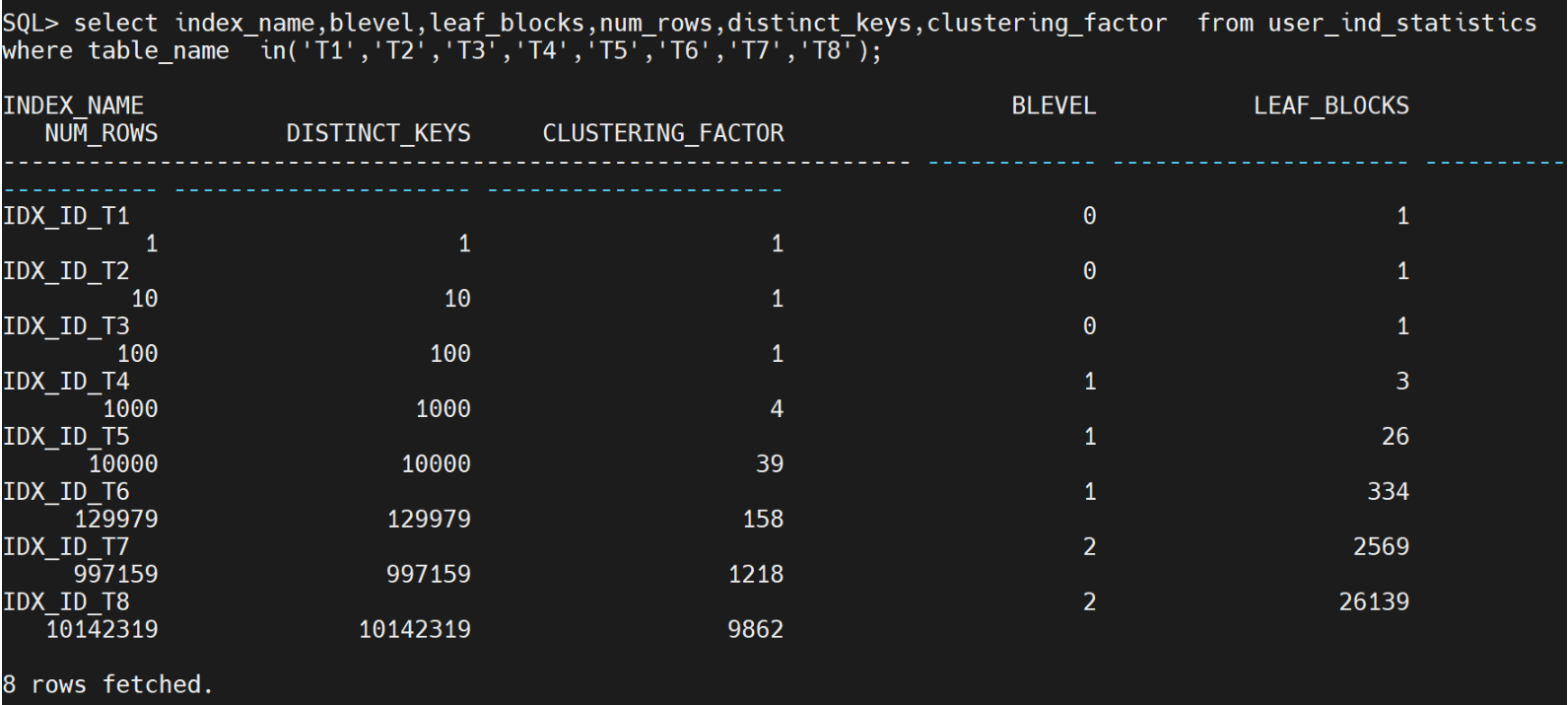
user_tab_statistics表包括很重要的统计信息,主要看BLEVEL和LEAF_BLOCKS,BLEVEL把它当成一个树结构的层次组来,第一层就是根页,根页是占用一个block,Yashandb默认的DB_BLOCK_SIZE 是8092,估计是4K。T4要插入1000行数据就要进入第2层了。更多的数据就要进入第三层,T8的数据也是第三层。从调优来看,无论多大的数据都要保障在三层的范围,这样的话索引的效果才会好。
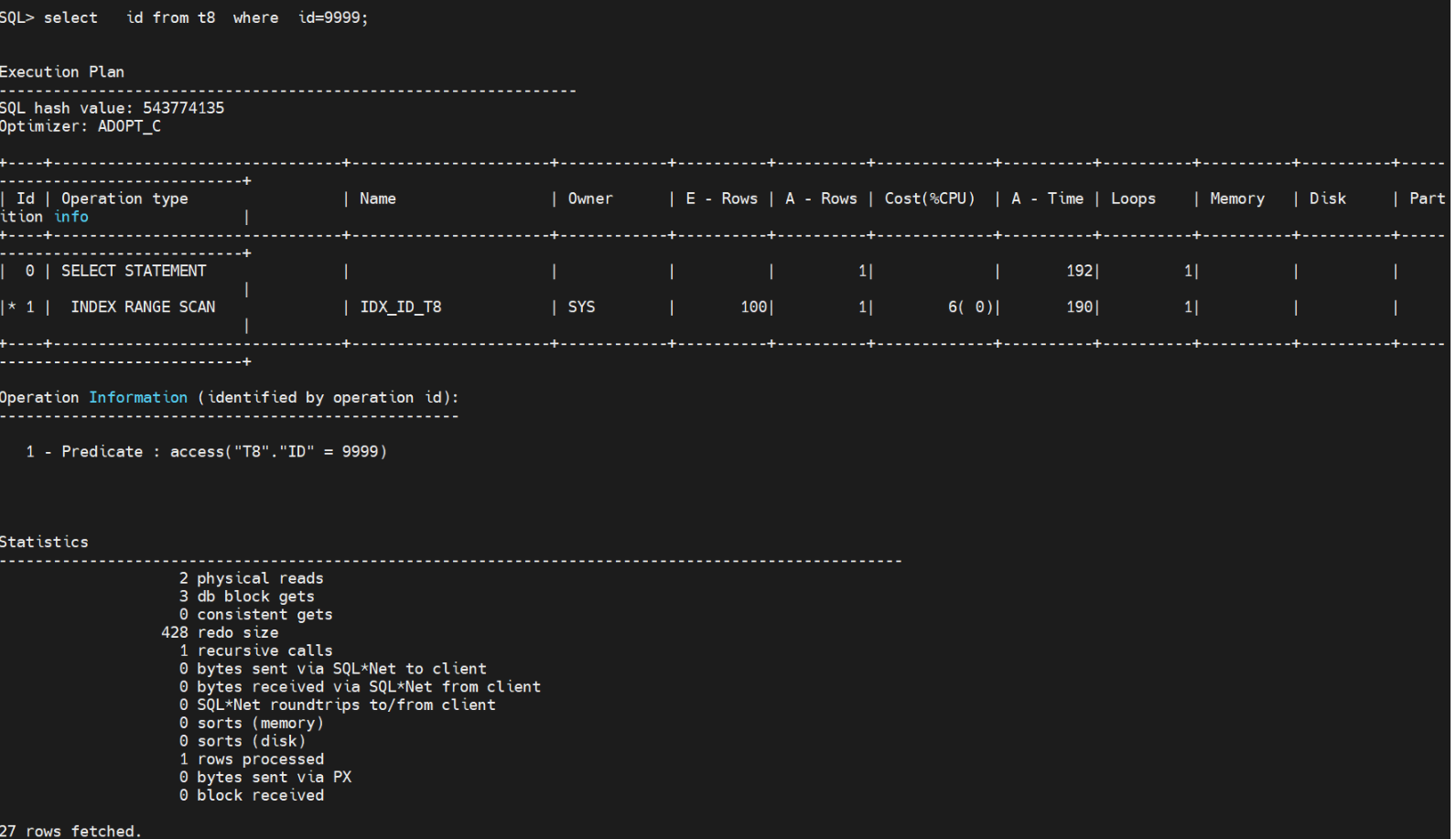
select id from t5 where id=9999; T5一万行的数据,索引查找花了2个db block
select id from t8 where id=9999; t8总共有1000万的数据也只是花2个物理读与3个逻辑读 ,与一万的数据差1000陪,但是索引提升的效果是惊人的。
用例六
基于part_t表派生part_t2表,part_t2表插入1倍多的数据,part_t表是小表,part_t2表是大表。 查看顺序和不同优先级、不同HINT指定下的扫描算子、块消耗、行消耗、行扫描。
create table part_t2 as select * from part_t;
insert into part_t2 select rownum,rownum+1,rownum+2 from dual connect by rownum<=2100000;
ALTER SESSION SET statistics_level=ALL;
set autotrace traceonly;
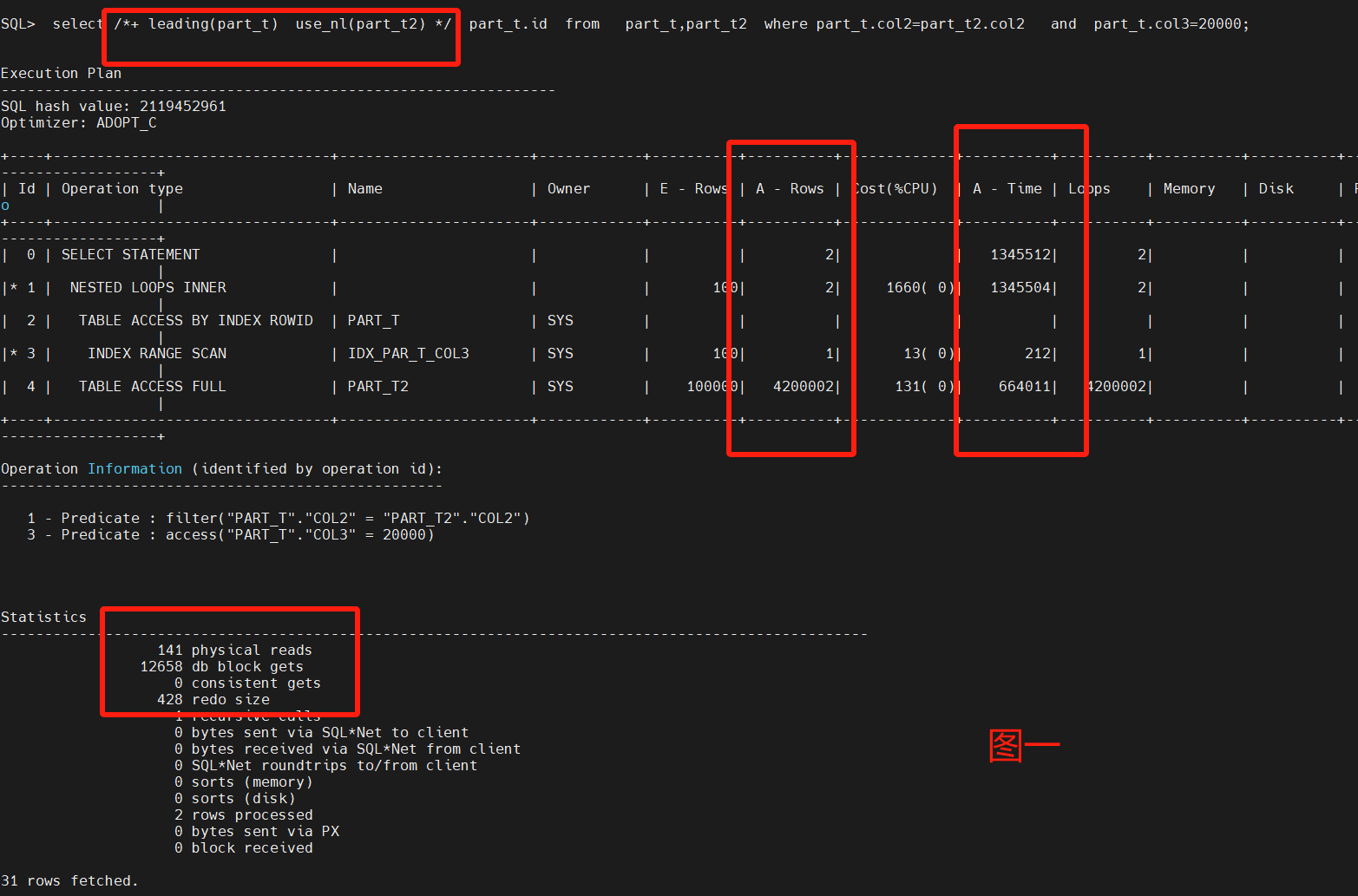
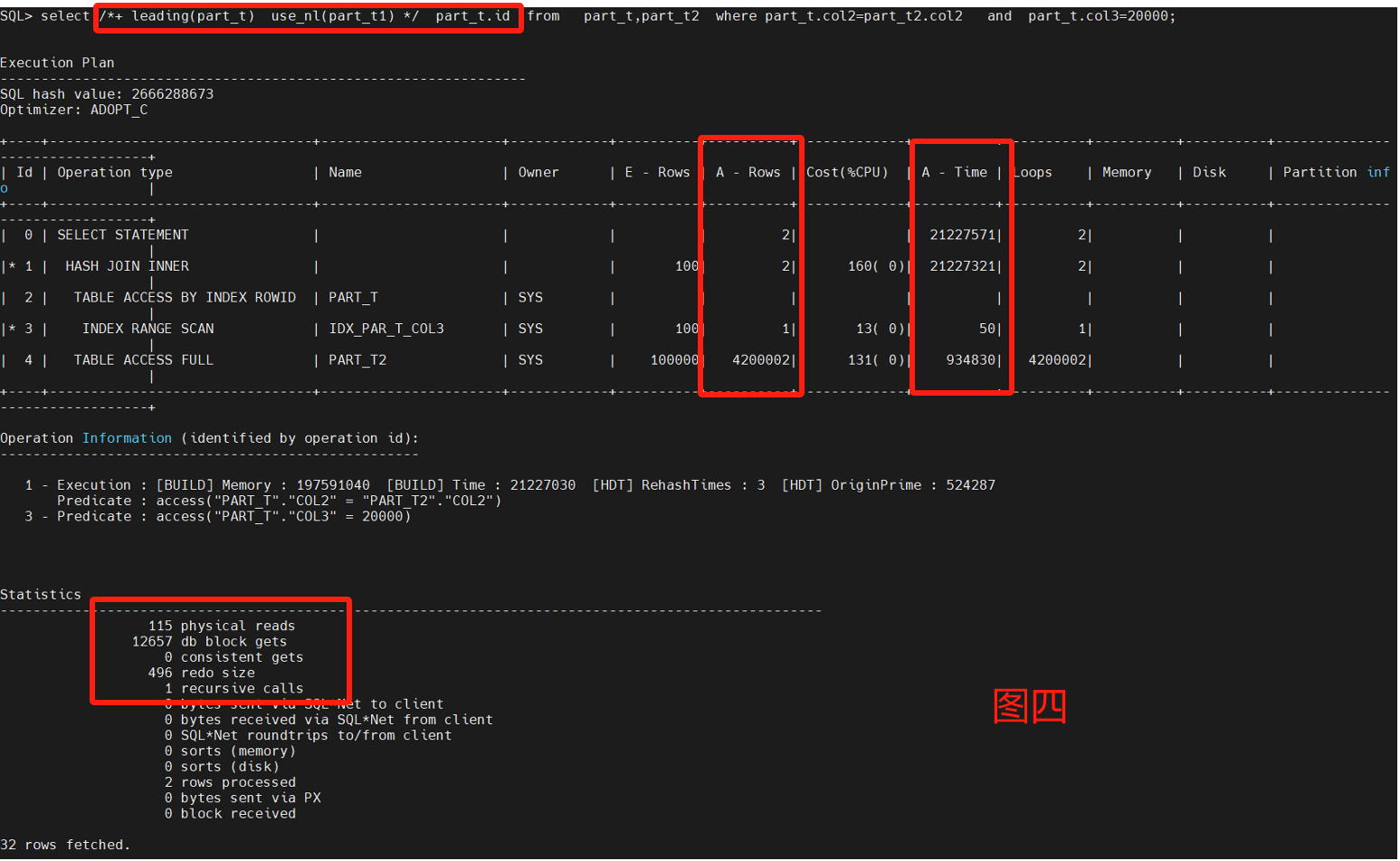
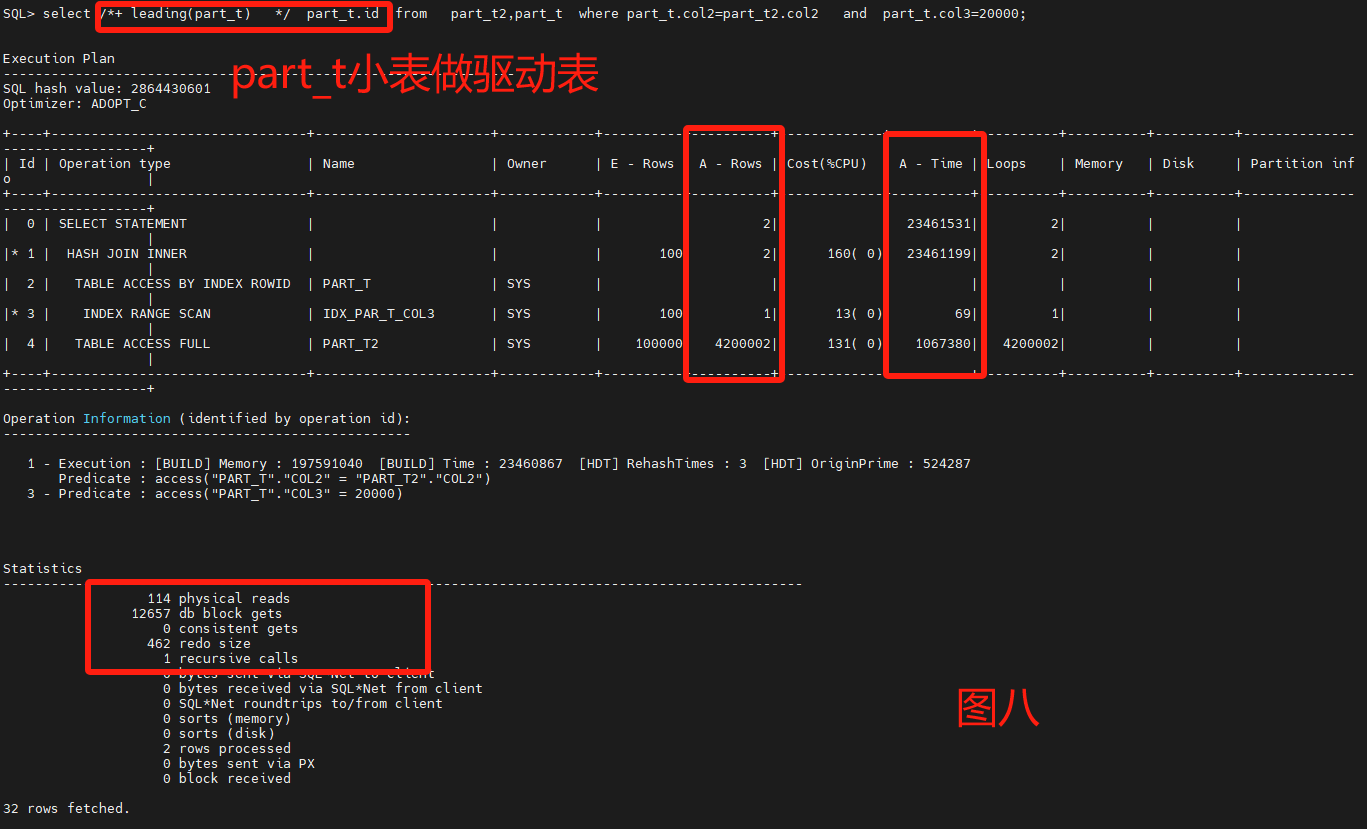
select /*+ leading(part_t) use_nl(part_t2) */ part_t.id from part_t,part_t2 where part_t.col2=part_t2.col2 and part_t.col3=20000;
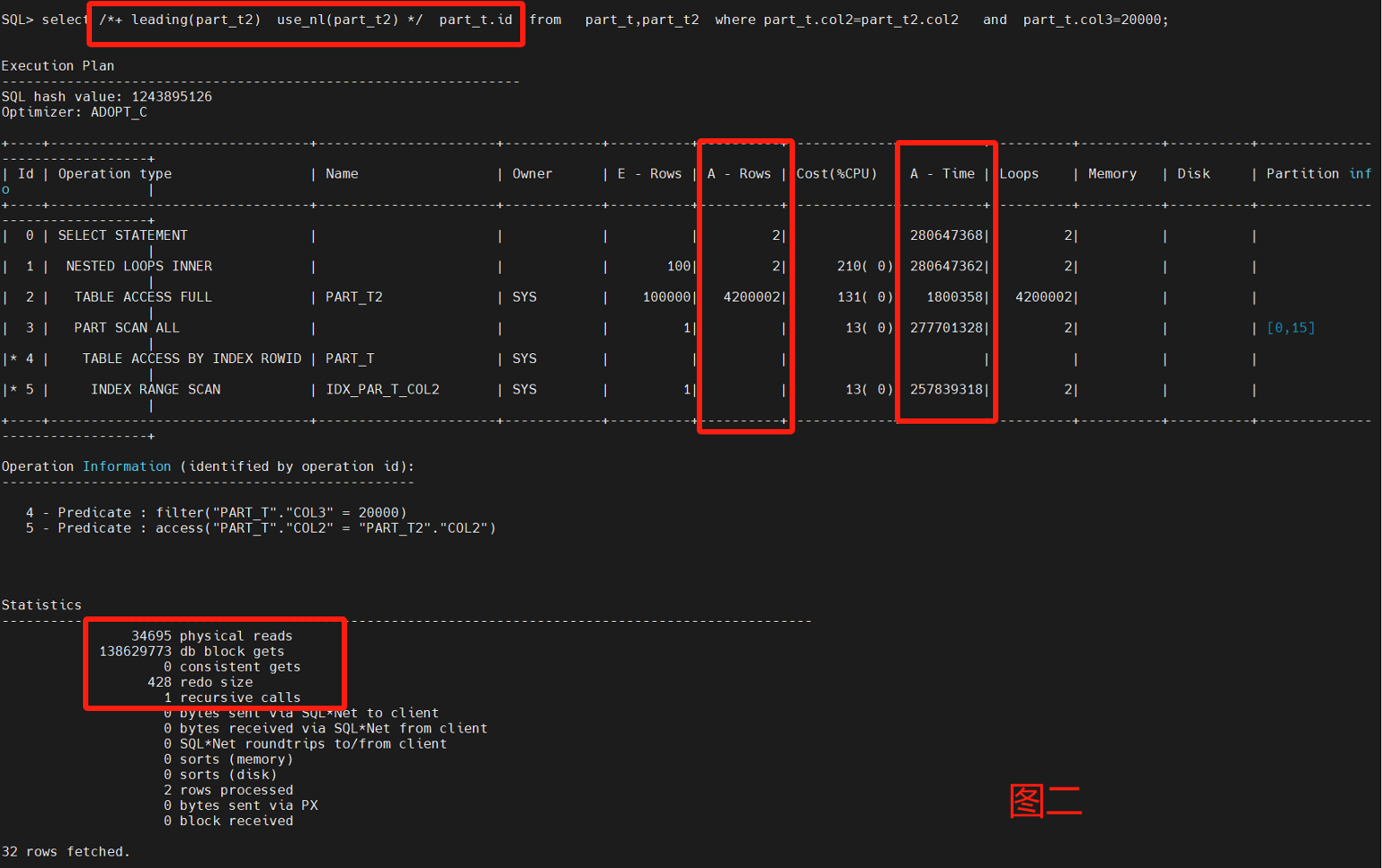
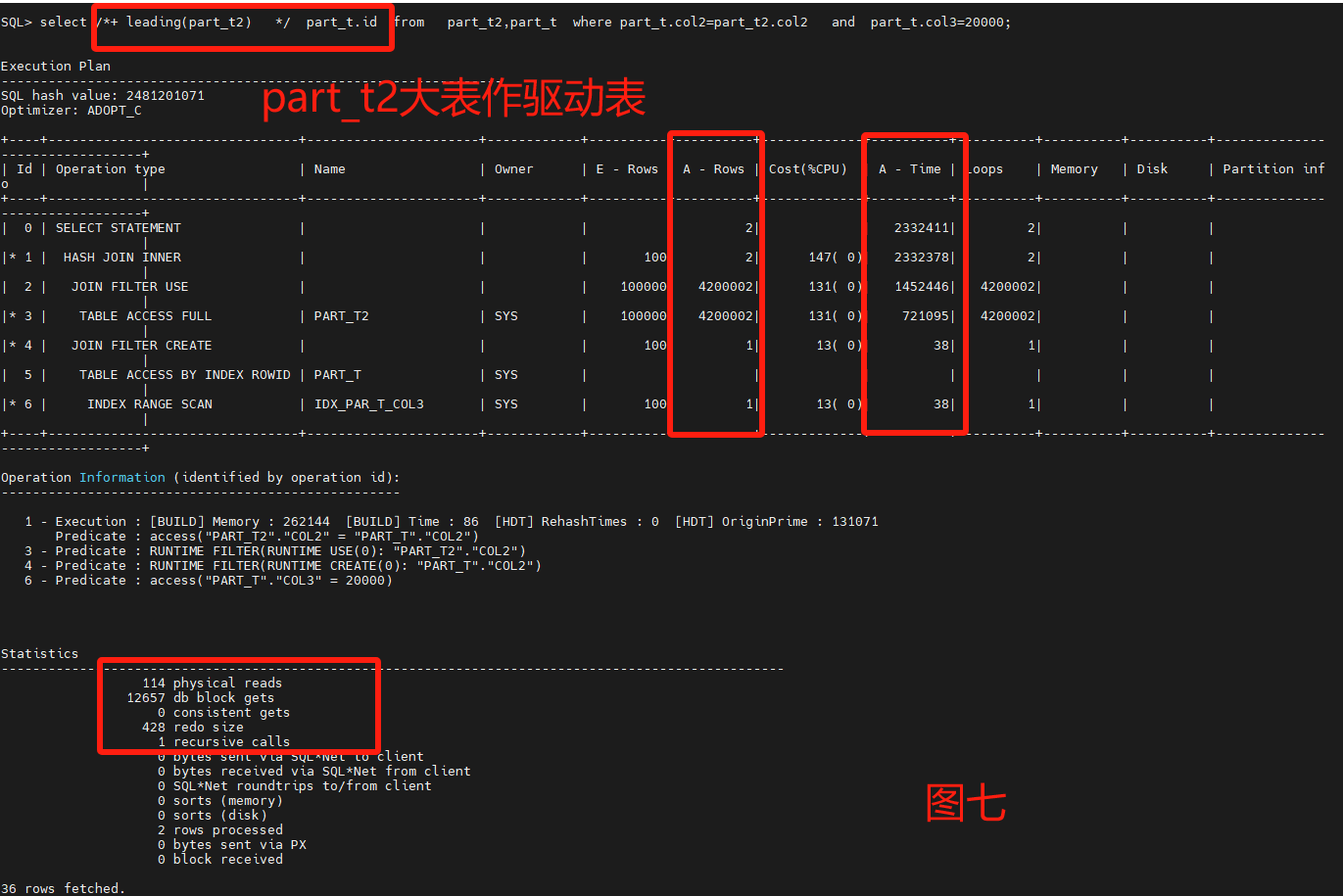
select /*+ leading(part_t2) use_nl(part_t2) */ part_t.id from part_t,part_t2 where part_t.col2=part_t2.col2 and part_t.col3=20000;
drop table part_t2 purge;
drop table part_t purge;
select /*+ leading(part_t2) use_nl(part_t1) */ part_t.id from part_t,part_t2 where part_t.col2=part_t2.col2 and part_t.col3=20000;
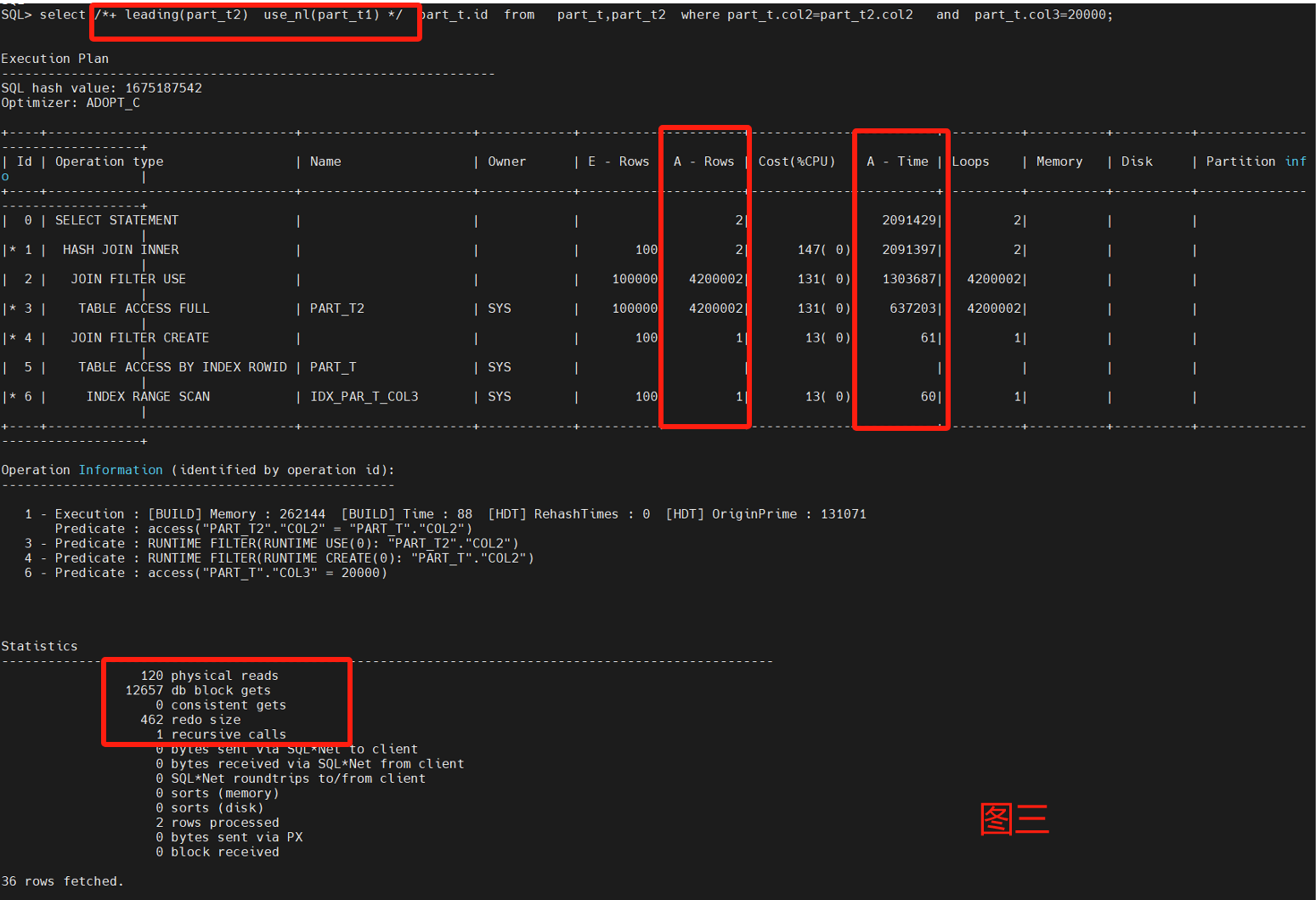
select /*+ leading(part_t) use_nl(part_t1) */ part_t.id from part_t,part_t2 where part_t.col2=part_t2.col2 and part_t.col3=20000;
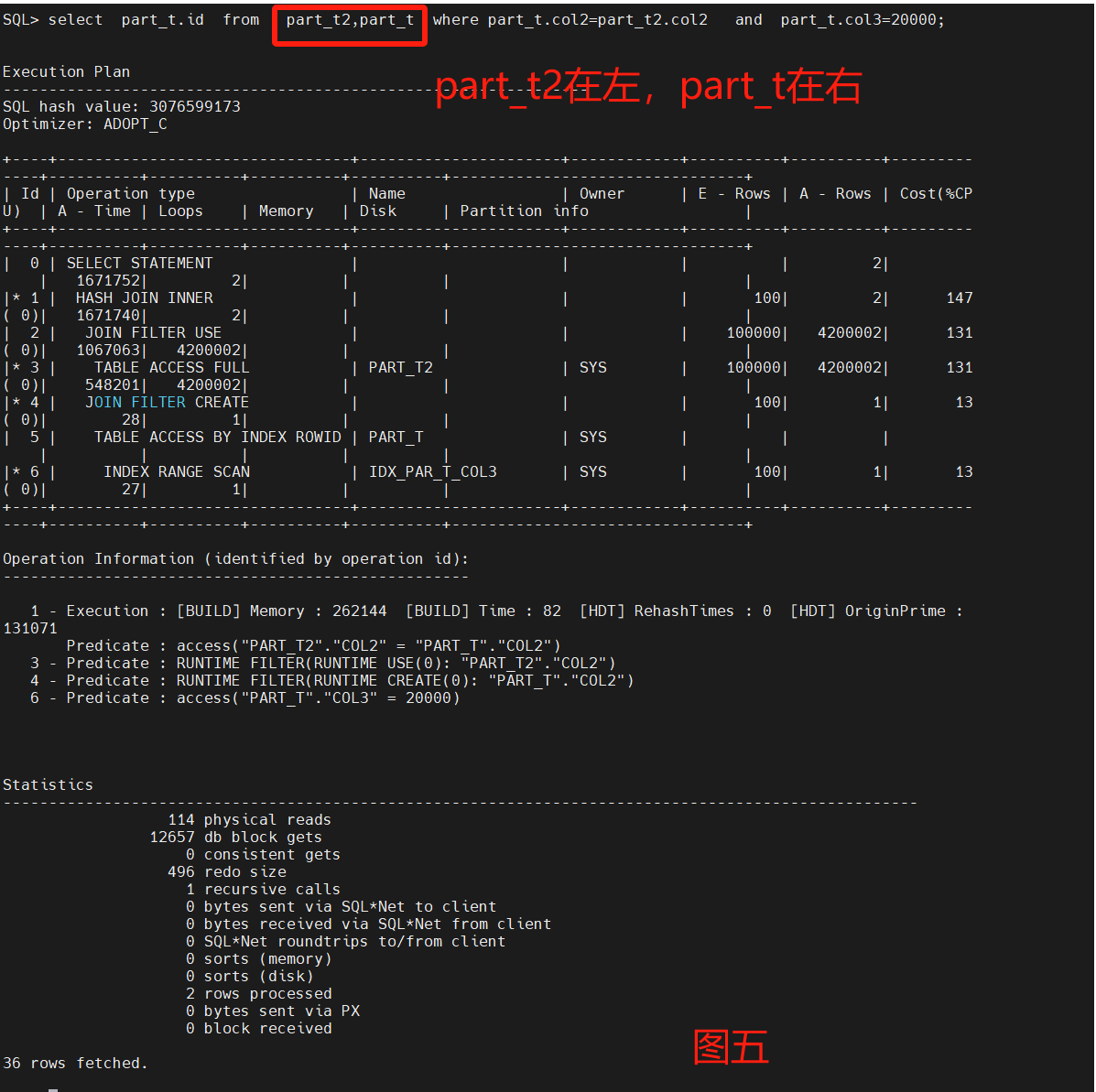
select part_t.id from part_t,part_t2 where part_t.col2=part_t2.col2 and part_t.col3=20000;
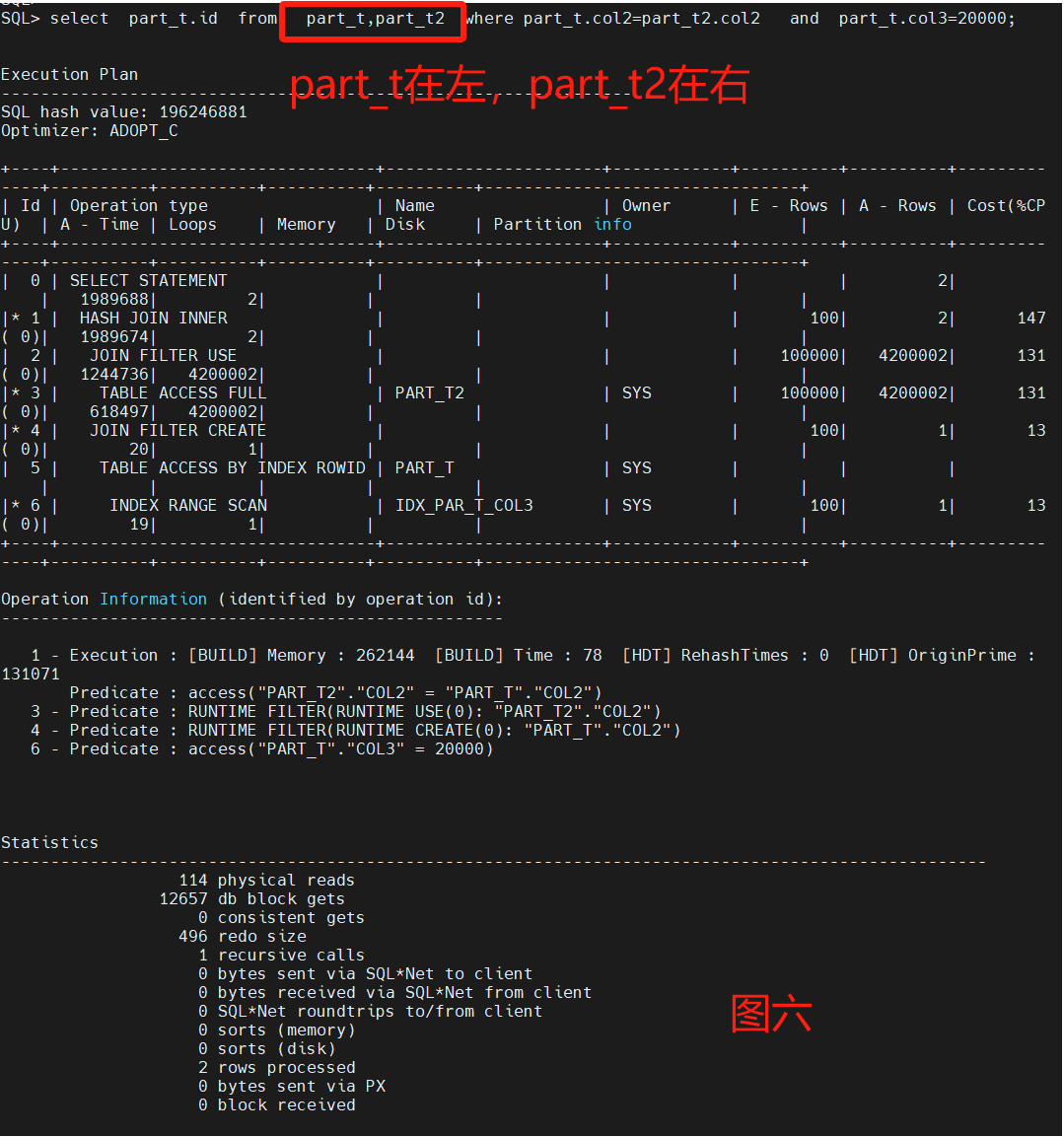
select part_t.id from part_t2,part_t where part_t.col2=part_t2.col2 and part_t.col3=20000;
测试实验中出现YashDB的一个锁,记录YashDB的锁破解如下
SQL> drop table part_t purge;
YAS-02024 lock wait timeout, wait time 0 milliseconds
SQL> select * from v$LOCKED_OBJECT;
XEXT XNODE XSN OBJECT_ID SESSION_ID LMODE
-------- -------- ------------ --------------------- ---------- ---------
53 9603 1 2257 22 TS
SQL> SELECT sid,serial# FROM V$SESSION WHERE sid IN (22);
SID SERIAL#
-------- ------------
22 4963
1 row fetched.
SQL> ALTER SYSTEM KILL SESSION '22,4963';
Succeed.
主要采用了嵌套循环来做两表的测试,不用leading和不同nl的呈现不同的走向,性能调优重点看Statistics以及A-Row、A-Time。
通过8图对比,leading是否选择小表对性能很关系,默认不加HINT也能跑出一个不错的性能,把大表和小表优先权倒置,优化器也能识别区分。
最后4图都是一样的Statistics,但是不一样的A-Row和操作连接,图2是最差的路径选择,消耗了最多的物理读和逻辑读,图8是最优路径的结果,原因是A-ROW是最小的。
原始SQL什么也不定指定,接近图8的性能。
总结
不能说YashanDB吊打Oracle,也不能说YashanDB离Oracle还有十万八千里,Oracle能实现的功能,YashanDB都具备。
- YashanDB的优化器与Oracle的大同小异,性能判断来于 从硬盘里读【physical read】,从缓冲区里读 【db block get | CONSTSTENT GET】。
- 如果你是ORACLE DBA,SQL语句整体优化按照Oracle风格去调整优化,没有很大的出入。
- YashanDB还加了一些物理参数例如Memory 以及Disk,目前没有这方面的输出,仍在TODo进程中,相信后期会有很大的改善。
- 为了启用Statistics,YashanDB需要输入
ALTER SESSION SET statistics_level=ALL; - user_ind_statistics表的统计更新,需要人为执行某包下的存储过程DBMS_STATS.GATHER_INDEX_STATS去触发,这点对个别工程师可能体验不好,因为Oracle12c不需要执行这一步就已经更新统计数据了,YashanDB这方面应该与Oracle 12c对齐,统计数据自适应,搜集对象的统计数据应该是后台某个钩子函数干的事,加上有对比,建议跟上。
- 简单的两表的测试,YashanDB对比Oracle12c,YashanDB优化器路径与Oracle12C大致相同。
结论,每个数据库的优化器都是不一样的,更复杂的语句和更复杂的环境,呈现多条路径选择,测试中我们看到YashanDB是基于CBO的优化,以后TODO的路线还会把CPU消耗和内存放进来,增加优化器的选择,我们拭目以待。
