




概述
本文详细讲述clickhouse-kafka-connect项目“有且仅有一次”语义的实现方案和案例实践总结。该项目基于Kafka connect框架和ClickHouse新特性KeeperMap(状态存储)、实现基于exactly-once语义的kafka数据实时同步到clickhouse的功能;该项目基于ClickHouse官网JavaAPI实现支持所有数据类型(包括复杂数据类型:Map/Tuple/Json等);该项目遵循Apache2.0 License。
实现方案
所谓exactly-once语义:即Kafka所有数据不重复且不丢失地同步到ClickHouse。说起来简单,但是实现该语义确实是不小的挑战。通常的处理流程就是:读Kafka、写ClickHouse、记录Offset。其中,写ClickHouse与记录Offset的顺序至关重要。
1.At-least-once语义:先写ClickHouse、再记录Offset;前者成功、后者失败、重启。2.At-most-once语义:先记录Offset、再写ClickHouse;前者成功、后者失败、重启。
那么,该方案是怎么实现exactly-once语义的呢?
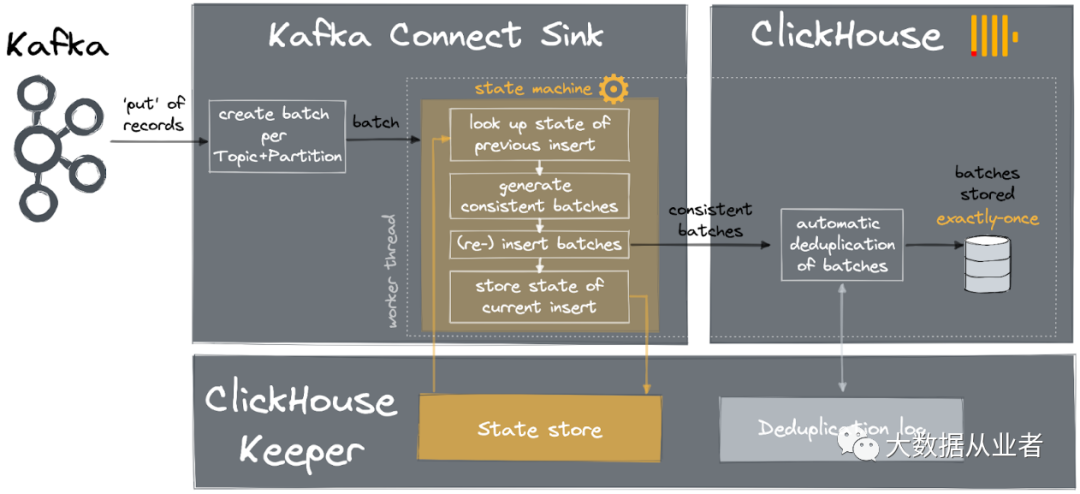
上图示例对应单个worker单个thread,单个线程对应于单个topic/partition。对于每个topic/partition中的每个batch, 状态存储记录信息如下:
1.当前batch的minOffset、maxOffset。2.当前batch写入ClickHouse之前,设置BEFORE标志;写入ClickHouse之后,设置AFTER标志。
每次处理batch数据时,先查询当前topic/partition记录的上述信息。如果记录信息为AFTER标志,表示上次写入ClickHouse成功;如果记录信息为BEFORE标志,表示上次写入ClickHouse失败。如果没有任何记录信息,表示该topic/partition首次处理, 这种情况是最简单的场景:
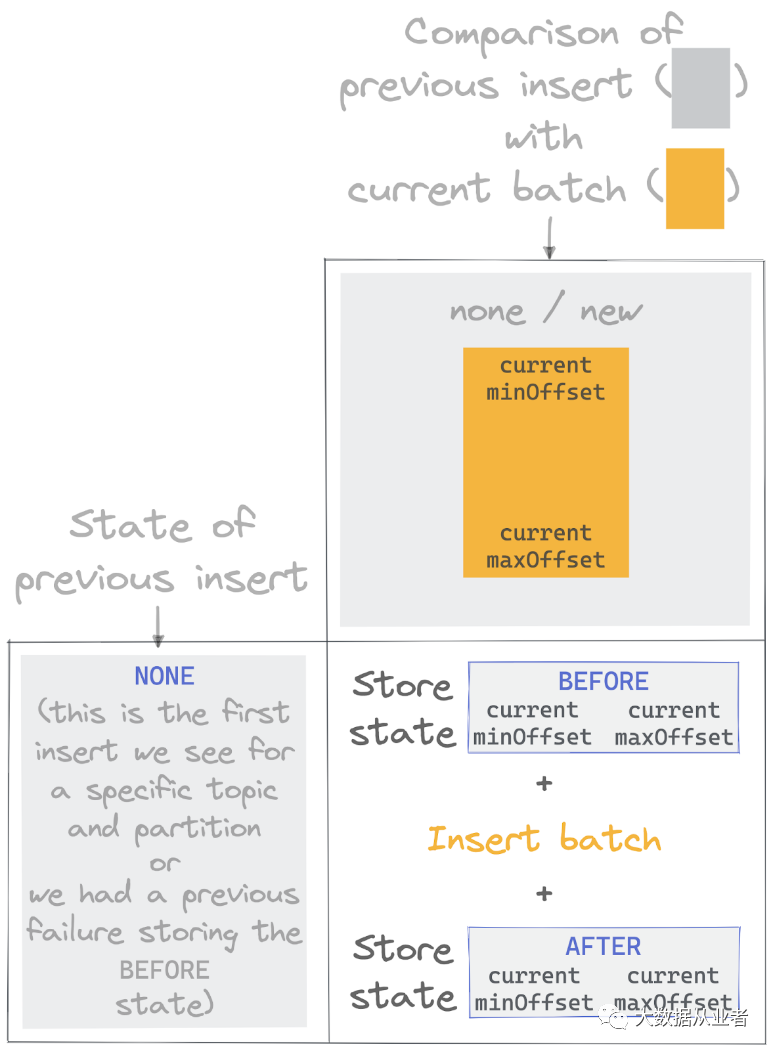
如上图所示,Insert batch之前先设置BEFORE标志、之后再设置AFTER标志。对于后续的inserts, 状态存储有每个topic/partition的记录信息。当将以前的状态与新批次进行比较时,根据设置了BEFORE或AFTER标志,存在4种可能结果、2种操作:
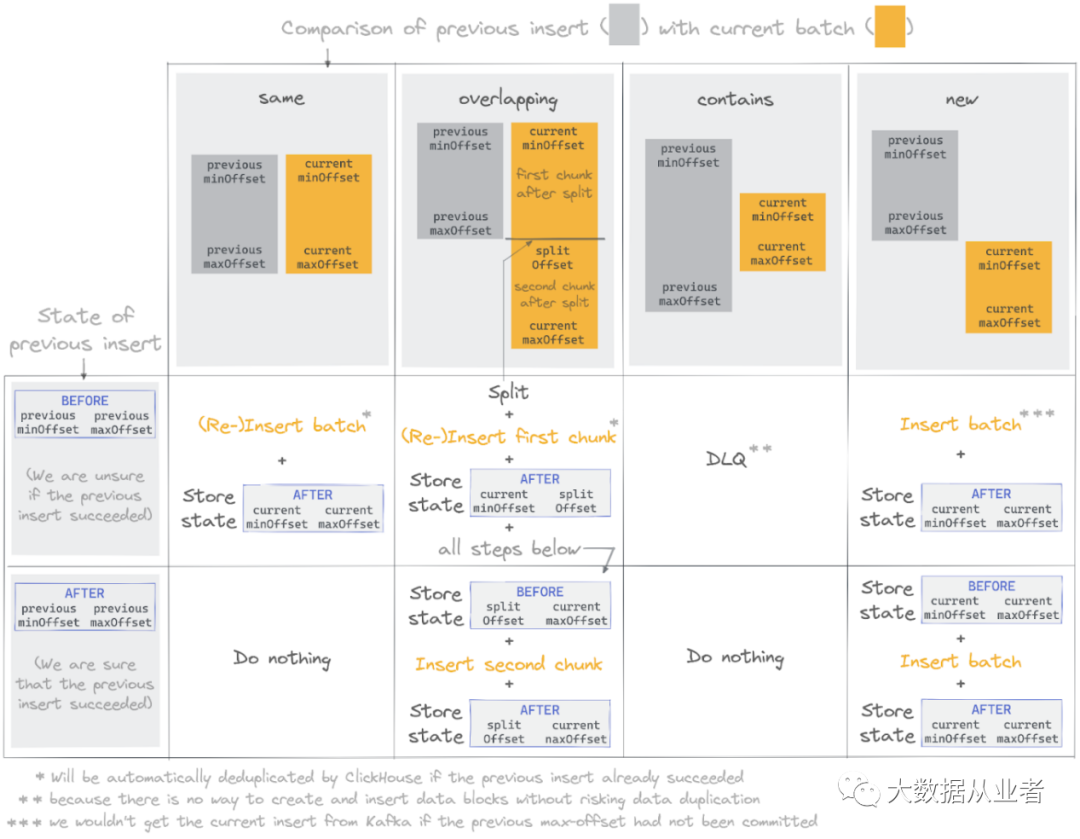
1. Same – 之前的min-offset、max-offset与当前batch相同。如果标志是BEFORE,则Inert batch、然后设置AFTER;如果标志是AFTER,丢弃当前batch。
2.Overlapping – 之前的min-offset与当前batch相同,但是之前的max-offset比当前batch小。该情况下,当前batch会切分为两个chunks。如果标志是BEFORE,则Insert first chunk、设置AFTER、设置BEFORE、Insert second chunk、设置AFTER;如果标志是AFTER,则设置BEFORE、Insert second chunk、设置AFTER。
3.Contains – 之前min-offset、max-offset范围包括当前batch。如果标志是BEFORE,则加入DLQ死信队列;如果标志是AFTER,则丢弃。
4.New – 属于最常见的情况。之前max-offset + 1等于当前batch min-offset。如果标志是BEFORE,则Insert batch、然后设置AFTER;如果标志是AFTER,则设置BEFORE、Insert batch、然后设置AFTER。
实践案例
1.安装ClickHouse RPM

rpm -ivh clickhouse-common-static-23.7.5.30.x86_64.rpmrpm -ivh clickhouse-server-23.7.5.30.x86_64.rpmrpm -ivh clickhouse-client-23.7.5.30.x86_64.rpm
注意:安装server时设置的默认密码,ClickHouse客户端连接server时需要使用(我这里设置为felixzh)。
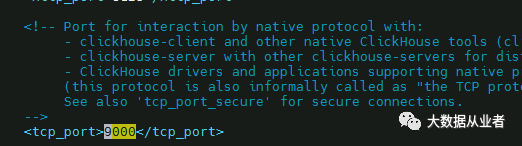
2.修改服务端口
默认端口:9000,如有需要,可自行修改
3.修改配置文件config.xml
chmod 744 etc/clickhouse-server/config.xmlvim /etc/clickhouse-server/config.xml
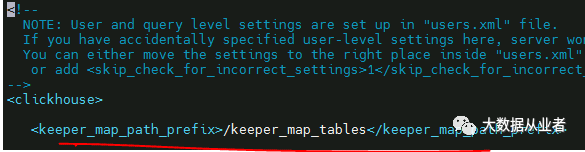
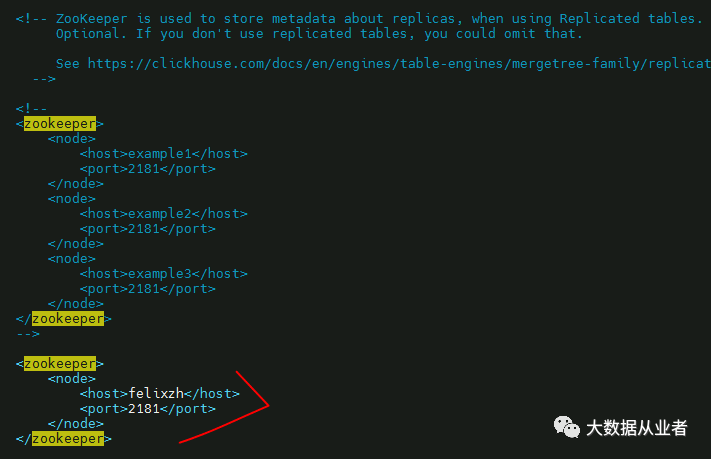
4.启动ClickHouse服务
systemctl start clickhouse-serversystemctl status clickhouse-server
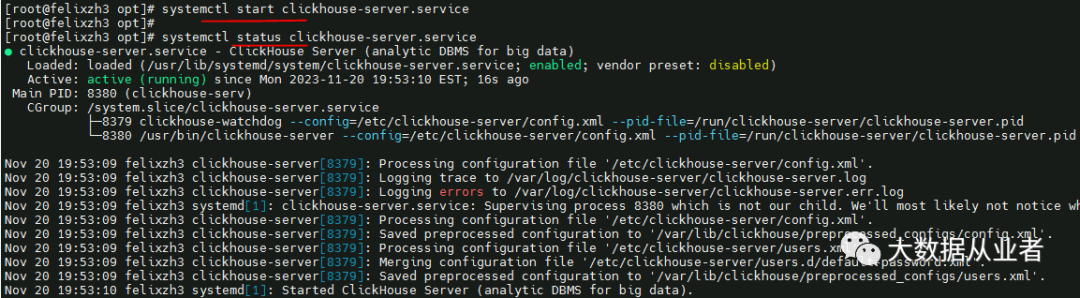
如果启动失败,可以查看日志排查:
/var/log/clickhouse-server/ clickhouse-server.err.log
5.客户端登录
clickhouse-client -u default --password felixzh --port 9000
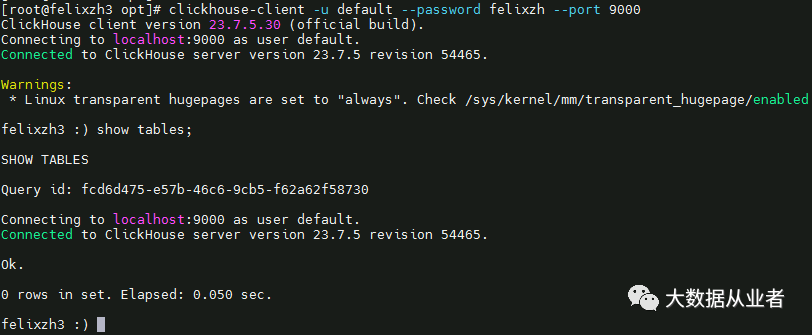
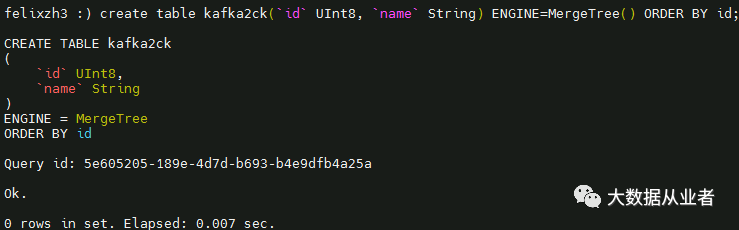
至此,ClickHouse部署、配置、启动完成。创建后续测试表kafka2ck:
create table kafka2ck(`id` UInt8, `name` String) ENGINE=MergeTree() ORDER BY id;
6.clickhouse-kafka-connect改造
https://github.com/ClickHouse/clickhouse-kafka-connect
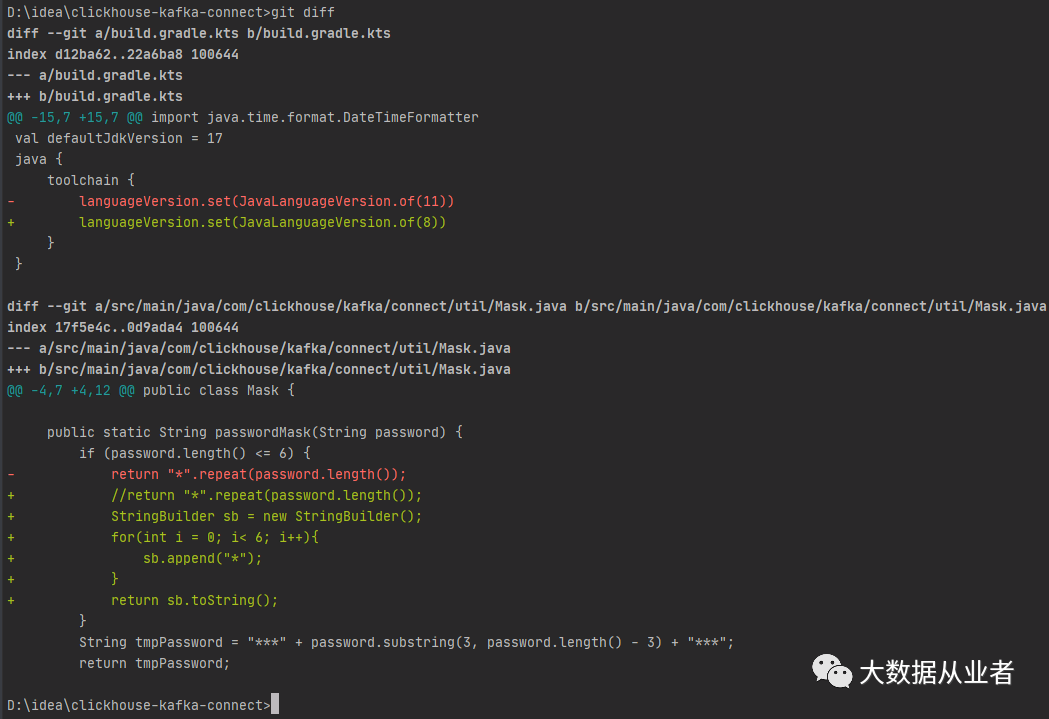
项目基于Java11开发,如果需要使用Java8,简单修改即可,如下:
源码编译:gradle clean build
将clickhouse-kafka-connect-v0.0.18-confluent.jar拷贝到kafka安装目录libs/目录。
7.Kafka节点,准备配置文件
vim config/connect-standalone.properties
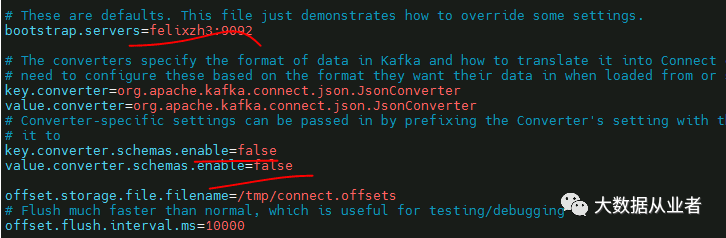
vim config/connect-ck-sink.properties
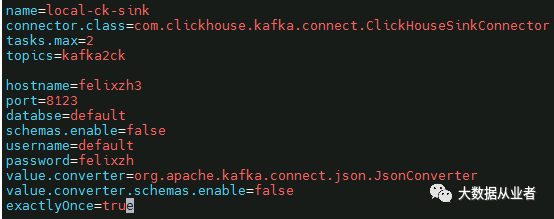
8.启动kafka-connect集群
bin/connect-standalone.sh config/connect-standalone.properties config/connect-ck-sink.properties
9.Kafka写入测试数
{"id":1,"name":"felixzh"}

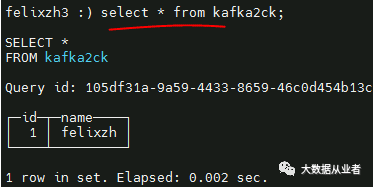
10.ClickHouse查询数据
select * from kafka2ck;
总结
至此,clickhouse-kafka-connect项目“有且仅有一次”语义的实现方案和案例实践介绍完成!
