




前 言
子图匹配(Subgraph Matching)作为图模式挖掘问题的一个重要任务,在现实生活中的许多领域都有着广泛的应用,例如:社交网络分析、道路交通分析、化学分子式合成、生物蛋白质作用网络、金融欺诈检测等等。此外,子图匹配还是图数据库进行图查询的一个核心算子,因此提高子图匹配的效率是一个热点问题。
由于子图匹配是一个NP-hard的问题,当数据图的规模很大时,串行算法的执行效率是不令人满意的。为了提高子图匹配的性能,借助于硬件的支持是一个很自然的想法。GPU具有大规模并行计算的能力,利用其对子图匹配进行加速可以获得良好的效果,在GPU上有基于DFS和基于BFS的不同子图匹配算法:前者具有良好的内存开销,但并行能力不足;后者可以有效支持大规模并行,但存储开销很大。
因此,近来的子图匹配算法针对上述情况,一般采用DFS-BFS混合的框架进行子图匹配,本文主要调研了三篇GPU上采用DFS-BFS混合框架的子图匹配工作,对其设计理念和技术要点进行了简要的介绍。

问题定义
GPU框架
如今,GPU已经被广泛地应用于现代计算机中。如下图所示,我们从硬件层面和软件层面两个角度来介绍GPU的架构:
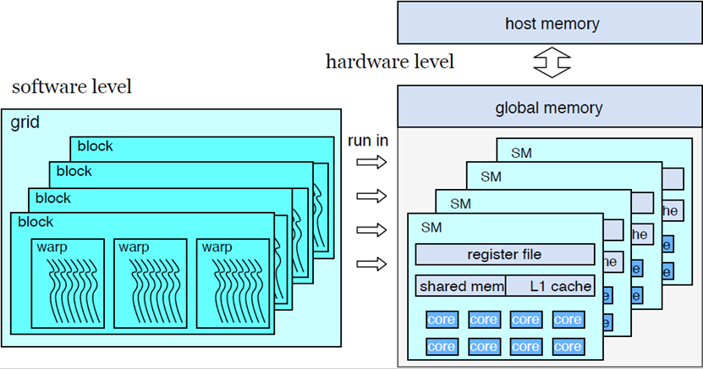
从硬件层面上看,一个GPU是由许多相对独立的硬件单元组成,这个硬件单元被称为流多处理器(SM,Stream Multiprocessor)。每个流多处理器都与其他流多处理器并行运行。对于每个流多处理器,它都由大量的计算核(Core)构成,这些计算核可以并行地执行大量线程,这是GPU具有大规模并行计算能力的基础。除了这些计算单元,每个流多处理器还包含一些片上存储单元,包括片上寄存器、L1 cache和共享内存(Shared Memory)。共享内存仅对流多处理器内部的线程可见,不能被其他的流多处理器直接访问,虽然每个流多处理器配备的共享内存有限,但其访问速度是寄存器级别的,是低延迟、高带宽的存储介质,因此利用好这部分内存对访存优化起着重要的作用。最后,整个GPU还配备一个全局存储,称为Global Memory或者Device Memory,这个全局内存的存储容量较大,具有高带宽和高访问延迟的特点。由于全局存储的访问速度远远慢于局部存储的访问速度,因此针对GPU的设计要考虑尽量减少访外的代价。除此之外,全局存储还通过PCIe总线跟CPU端相连,进行主机端到硬件设备端的数据传输。
从软件层面上看,当GPU运行时,GPU会启动核函数(Kernel)。此时,每个流多处理器上的线程都会被组织成block的形式,每个block又会由多个warp组成,每个warp内部包括了32个线程。一个block中的线程间可以进行通信,也可以共享数据,但是不同的block之间进行数据通信就需要花费额外的代价。要注意的一点是,block是逻辑上的线程组概念,并不是严格对应于流多处理器,一个block只会被分配到一个流多处理器上,但一个流多处理器可以同时执行多个block。warp作为GPU上调度的基本单元,是GPU编程模型中的重点关注对象。warp内部的线程是按照单指令多线程(SIMT)的方式执行的,这也代表了warp内部的线程在处理相同任务时是效率最高的。如果存在分支指令,那么warp内部会产生线程发散的问题,即执行不同分支的线程不能并行执行,需要互相等待,影响多线程并行的性能。此外,GPU对全局内存的访问是以warp为基本访问单元的,内存事务读取的长度一般为128字节。如果warp中的线程是以连续和对齐的方式去访问数据,那么就可以用更少的访存事务请求获得数据,如果是离散地去访问,那么就需要多个事务才能完成,大大降低访存的性能。
PARSEC
通常,DFS会导致不规则的内存访问模式,并涉及回溯,从而导致GPU的线程发散问题,这使得早期GPU上基于DFS的子图匹配算法性能较差。 而虽然BFS以增加内存需求为代价更好地利用GPU并行性,但由于其庞大的中间结果存储开销,不利于解决大图问题。 因此如果可以将BFS与DFS混合,在搜索树前几层使用BFS,增大并行性,在后续层级使用DFS,以固定内存的使用,可能会得到两者兼顾的效果。
另一方面,在GPU上实现DFS也存在一些难点:
GPU需要细粒度并行性以有效利用硬件资源,细粒度的并行化使并行化过程变得复杂,使GPU对负载不均衡更加敏感。 GPU对递归没有有效的支持。由于GPU具有大量线程,每个线程只能拥有一个小的内存堆栈,这不足以在典型的递归算法中存储大量的中间结果,限制了递归的深度。 与CPU相比,有限的GPU内存容量可能不足以跟踪并行遍历搜索树和子树的大量线程的执行状态。
因此,为了解决上述问题,PARSEC提出了三个优化方案:
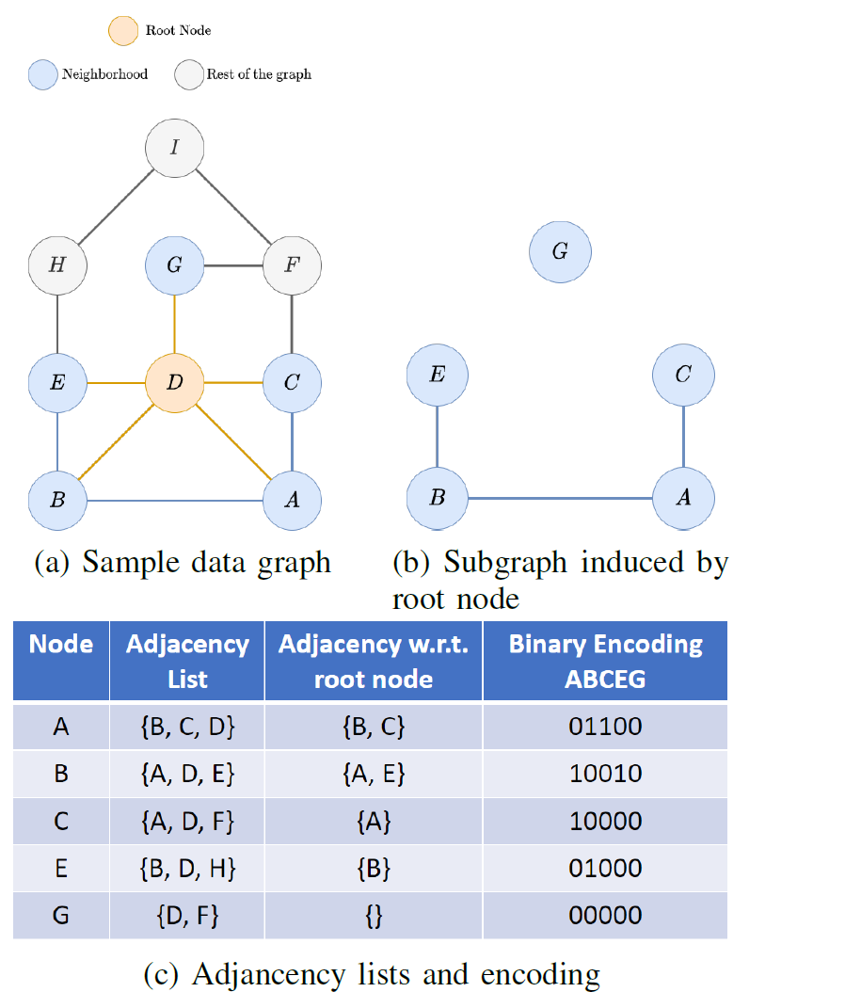
利用在团问题中常用的诱导子图的概念来减少集合求交的开销,使用二进制编码来表示诱导子图,以显著减少求交开销和降低内存需求。具体来说,引入中心点(Central Node)的概念。中心点是查询图中与其他顶点全都有边相连的顶点,其检查过程发生在查询预处理阶段。在遍历搜索树之前,构建相对于中心点的诱导子图,并利用其简化的邻接表来处理所有后续列表求交。通过对诱导子图进行二进制编码表示,可以将集合求交操作转换为按位与(AND)操作,例如下图的例子:
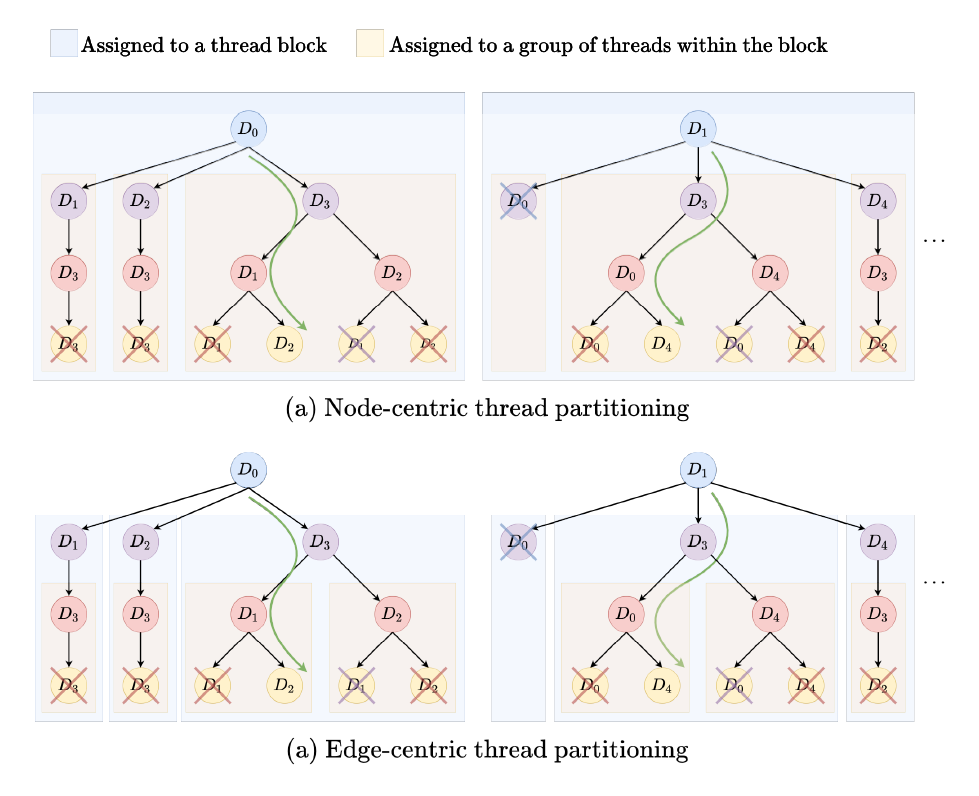
利用分层线程组织结构来为线程组分配各自的搜索子树,以提高GPU利用率和负载均衡。对于具有高度数节点的数据图,需要进行更大的交集操作,可以为每个Block分配更多更大的线程组。对于度数较小的图,每个Block的规模可以变小,从而使用更多的Block进行并行。对于前几层使用BFS提高并行度,后续使用DFS以减少内存的使用,分层并行策略示例如下:
采用了带有显式堆栈管理的迭代树遍历。这种迭代设计允许一组线程在遍历它们的搜索子树时共享堆栈资源。即递归转非递归,使得一组线程可以协作遍历。
PARSEC的实验效果也证明其有效性,并且可以支持的图规模也达到了36亿条边,具体的实验细节可以参考原文。
cuTS
cuTS[2]是SC 2021的一篇工作,其希望解决的问题有三个:
基于BFS的子图匹配产生的中间结果数目过大。
基于DFS的子图匹配过程中线程间工作负载不均衡。
多线程进行并行写回操作时,存在并行写冲突的问题。
提出了基于trie的数据结构,可以减少所需的内存占用,同时保持良好的内存访问效率。
设计了一个高吞吐量、GPU架构的算法,提供良好的负载均衡和良好的数据重用。
实现了一种高效的集合求交的GPU核。
具体来说,cuTS观察到中间结果中有大量可以复用的重叠部分,因此可以对中间结果进行压缩以减少中间结果的存储开销。cuTS采用了一个具有前缀树压缩效果的存储结构,叫做cuTS。这是由于随着部分匹配路径的长度增加,使用相同前缀匹配路径的次数也会增加,因此更多的相同前缀会被复用。其结构如下图所示:
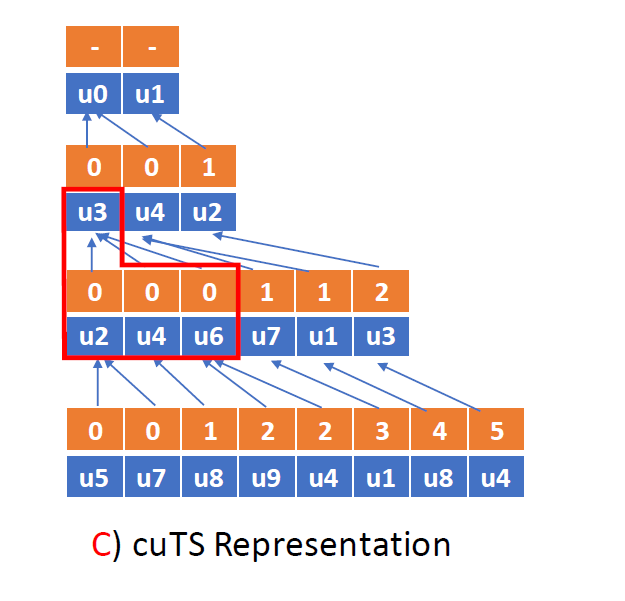
其中,橙色存储父顶点索引,称为Parent Array(PA),蓝色存储候选顶点ID,称为Candidate Array(CA)。这种数据结构可以避免线程间的写冲突是因为其显式地存储了父节点id;因此,两条路径的子节点可以以交错的方式写入,而不需要同一个邻居列表全部完成确定写回位置。随着部分路径的长度增加,cuTS的压缩比也越来越大,节约了许多存储空间。
而为了解决用一个warp处理单个部分路径会导致出现线程发散问题,cuTS采用将工作路径分组的策略。cuTS将工作路径分组到bin中,一个warp每次从bin中取多个路径一起处理。如:对于存储邻居列表长度为8的工作路径的bin,一个warp可以一次取4个进行处理。cuTS还随机化了部分路径的位置,通过这个简单的策略帮助实现了良好的线程内部和线程块负载平衡。
最后,cuTS同样采用了BFS-DFS混合遍历:首先,使用BFS生成大量初始部分路径,以提高并行度;然后,对所有初始部分路径进行划分,组成许多的chunk;最后,GPU每次处理一个chunk,每个chunk内部是DFS的。而chunk的大小的设置是一个Tradeoff的问题:chunk的大小变小时,容易使框架处理更大规模的图,但是也容易导致没有足够多的工作占用GPU内核。
cuTS的实验效果也展现了其在较小的数据图和查询图上的性能优势,但由于其使用的数据图规模较小,因此可能存在扩展规模的问题,具体的实验细节可以参考原文。
EGSM
GPU上的过滤(Filtering)阶段是不有效的,引入CPU上子图匹配算法的过滤策略可以大大减少枚举阶段的候选搜索空间。 GPU上基于BFS的子图匹配的内存开销限制了其扩展到大图的可能。 GPU上的算法大都使用固定的匹配顺序,不适应不同扩展的需要。借鉴CPU上如DAF[4]算法的自适应匹配顺序,可以减少最坏匹配顺序出现的可能。
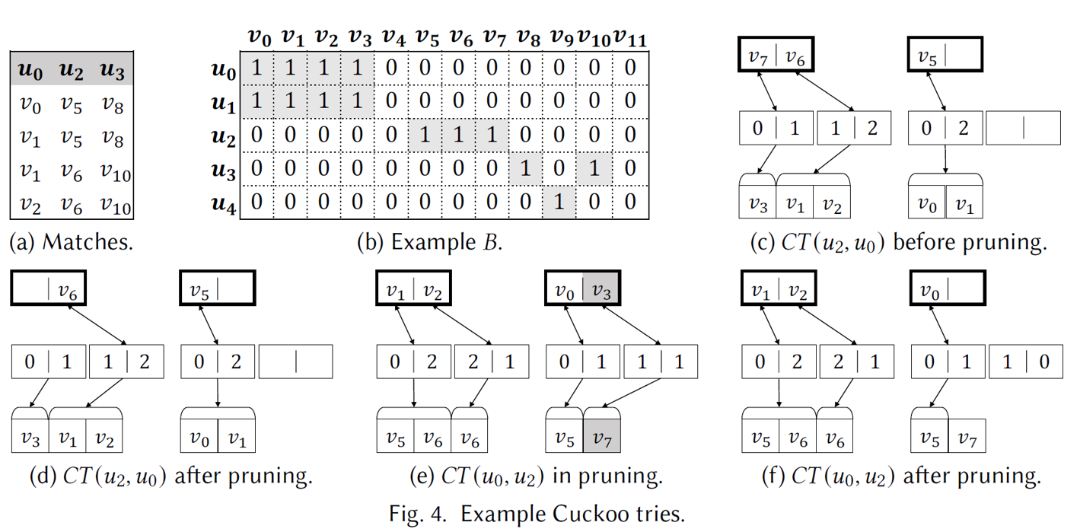
GPU上过滤阶段的不有效性是由于其缺乏辅助数据结构支持,本文提出了Cuckoo trie结构,用以存储侯选边,支持并行增删和随机访问。顾名思义,Cuckoo trie结构是基于cuckoo hashing技术,主要是采用bucketized cuckoo hashing,即多个key值可以被哈希到同一个桶中。对于每个边关系R(u,u’),EGSM生成一组CT(u,u’)和CT(u’,u)。每个CT结构包括三层:哈希表,偏移表和邻接表。如下图所示:
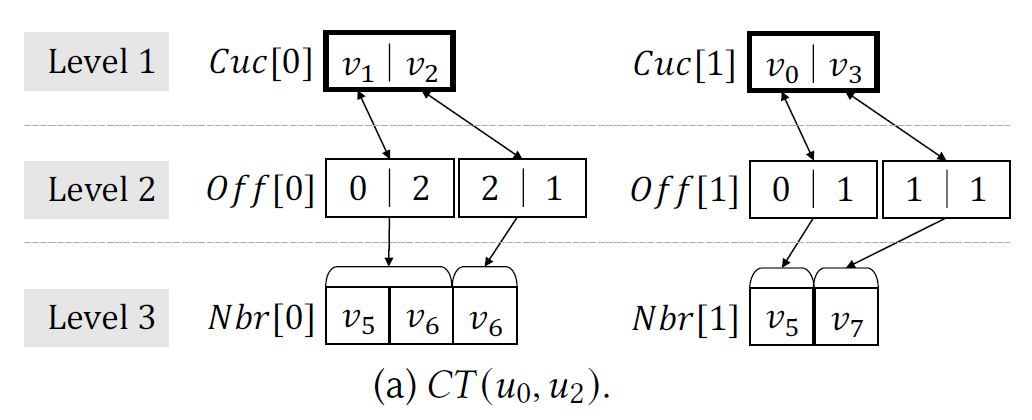
对于Level 1,黑色框代表一个桶,Cuc[i]代表不同的哈希表。Level 2的每一个元素的第一个值为偏移值,第二个值是一个点的邻居列表长度。Level 3是邻接表。在子图匹配执行时,一个warp的多个线程在顶层哈希搜索一个顶点,在底层连续访问不同邻居。假设一个顶点用32位存储,一次内存事务访问大小是256位,那么一个桶就可以容纳8个元素,一个warp一次可以对一个桶内所有元素进行并行查找。
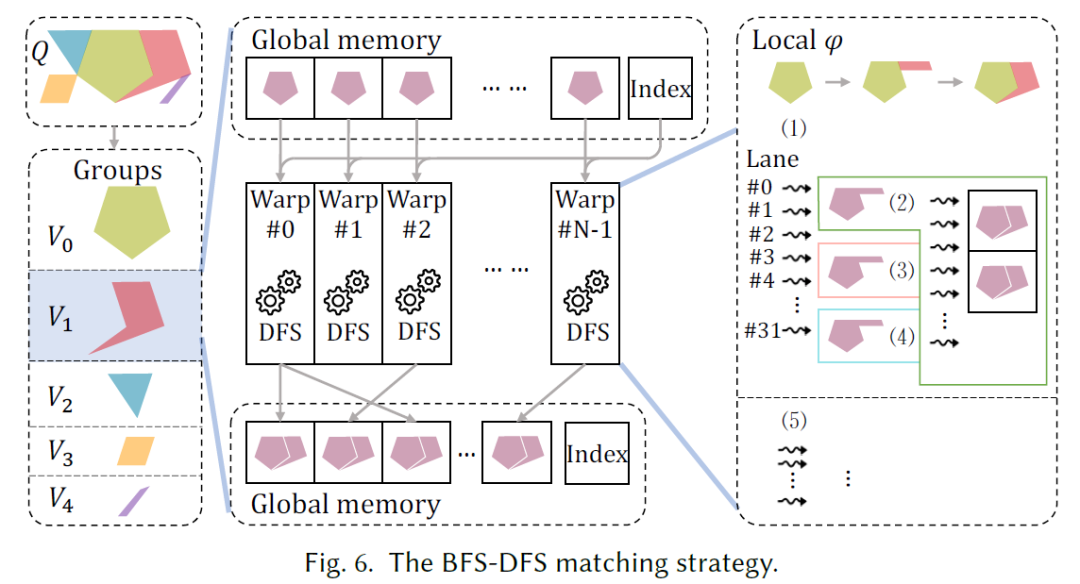
本文采用BFS-DFS混合策略。将查询图分组,一次扩展一组顶点(BFS),在每个组内部进行DFS匹配,如下图所示。对于具体的查询分组策略,EGSM采用一个贪心的方式进行划分。它首先将其按密度划分为2-Core和一些树,Core结构在树结构前执行。对于Core结构内部,clique结构会优先处理,然后通过clique又可以将Core划分为多个部分。在执行时,每个warp都具体负责一个中间结果的扩展。因此其存储开销本质上和BFS是一个量级,因此EGSM采用了一个内存管理机制:首先,使用两个区域轮流写,第i个group的中间结果可以覆盖第i-2个的中间结果;设置一个阈值,如果一个thread发现空间不足,回滚,将余下的group合为一个进行DFS,保证不会内存溢出。因此,与DFS相比,减小了搜索长度,缓解了负载不均衡,提高了平行度。与BFS相比,减小了中间结果的生成量和全局内存访问量。
在组内顶点枚举阶段采用一个自适应顺序,这个顺序是基于局部匹配信息的。如果是在线的每次都计算集合求交的基数估计,那么开销太大;而如果提前计算基数估计并存储在索引中,那么在每次扩展时都需要进行访存,访存开销太大。为了平衡上述情况,EGSM采用一个启发式的策略:它使用一个轻量级的基数估计来得到一个group内部顶点的匹配顺序,这个轻量级的基数估计是基于min property原则的,即集合求交的结果大小是受限于最小的那个集合的大小的。
总 结
参考文献
[1] V. Dodeja, M. Almasri, R. Nagi, J. Xiong and W. -m. Hwu, "PARSEC: PARallel Subgraph Enumeration in CUDA," 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Lyon, France, 2022, pp. 168-178, doi: 10.1109/IPDPS53621.2022.00025.
[2] Lizhi Xiang, Arif Khan, Edoardo Serra, Mahantesh Halappanavar, and Aravind Sukumaran-Rajam. 2021. cuTS: scaling subgraph isomorphism on distributed multi-GPU systems using trie based data structure. In SC ’21: The International Conference for High Performance Computing, Networking, Storage and Analysis, St. Louis, Missouri, USA, November 14 - 19, 2021. ACM, 69:1–69:14.
[3] Sun, Xibo and Qiong Luo. “Efficient GPU-Accelerated Subgraph Matching.” Proceedings of the ACM on Management of Data 1 (2023): 1 - 26.
[4] Myoungji Han, Hyunjoon Kim, Geonmo Gu, Kunsoo Park, and Wook-Shin Han. 2019. Efficient subgraph matching: Harmonizing dynamic programming, adaptive matching order, and failing set together. In Proceedings of the 2019 International Conference on Management of Data. 1429-1446.

END



