




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
2)OMS 全量校验前,停 Oracle ADG 日志应用,使源端数据处于静态,OMS 追平后再发起全量校验。当采用 ADG 作为同步源时,OMS 增量校验仅解析 ADG 端归档日志。
2.1 确认版本信息
2.2 开启并检查ADG实时应用
alter database recover managed standby database using current logfile disconnect;
set line 300 pagesize 5000
select name,db_unique_name,open_mode,database_role,protection_mode,switchover_status from gv$database;
set line 500 pagesize 1000
select THREAD#, SEQUENCE#, to_char(FIRST_TIME, 'YYYY-MM-DD HH24:MI:SS'), to_char(COMPLETION_TIME, 'YYYY-MM-DD HH24:MI:SS'), ARCHIVED, APPLIED, DELETED, STATUS from v$archived_log
where status = 'A'
and APPLIED = 'NO'
order by 1 desc, 2;
2.3 Oracle主库交叉切归档,并确认ADG延时追平、归档应用完
alter system archive log current;
alter system archive log current;
alter system archive log current;
set line 500
select name,value from v$dataguard_stats where name in('apply lag','apply finish time');
set line 500 pagesize 1000
select THREAD#, SEQUENCE#, to_char(FIRST_TIME, 'YYYY-MM-DD HH24:MI:SS'), to_char(COMPLETION_TIME, 'YYYY-MM-DD HH24:MI:SS'), ARCHIVED, APPLIED, DELETED, STATUS from v$archived_log
where status = 'A'
and APPLIED = 'NO'
order by 1 desc, 2;
2.4 停ADG实时应用,保持源端静止
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
2.5 发起OMS全量校验
1)启动全量校验
2)全量校验组件优化
limitator.platform.threads.number
limitator.select.batch.max
limitator.sql.execmax.noactive.time
limitator.table.diff.max
-Xms64g -Xmx64g -Xmn32g -Xss512k
task.checker_jvm_param
limitator.verify.oracle.rowid.querydst.withpartition=false
2.6 全量校验完成,校验结果分析
1)登陆OMS主机,进入OMS Docker容器
docker ps
docker exec -it <oms容器名> bash

2)切换进校验目录
diff文件:保存校验不一致的记录明细 /home/ds/run/{全量校验组件 ID}/verify/{subId}/{dbname}/diff/{table_name}.diff sql文件:存放在目标端执行的订正sql /home/ds/run/{全量校验组件 ID}/verify/{subId}/{dbname}/sql/{table_name}.sql

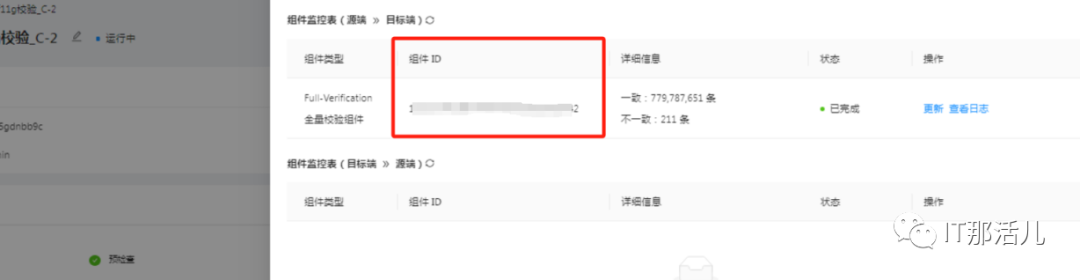
3)对OMS校验结果分析
--执行check_diff.sh脚本汇总校验结果:
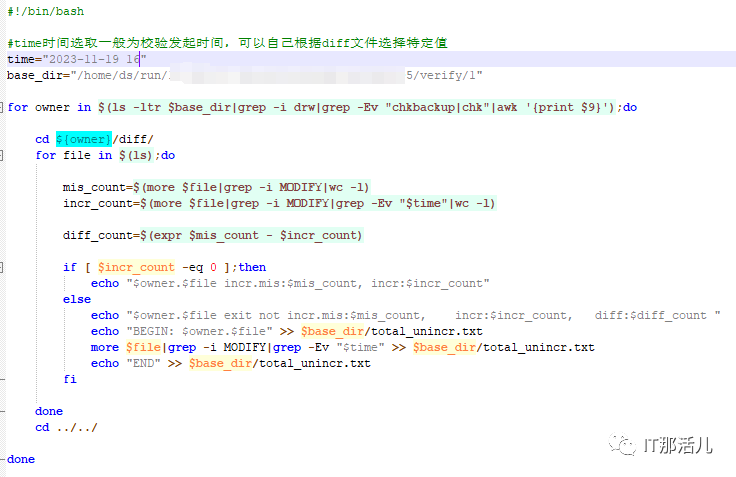
nohup sh check_diff.sh > check_diff.sh.out &
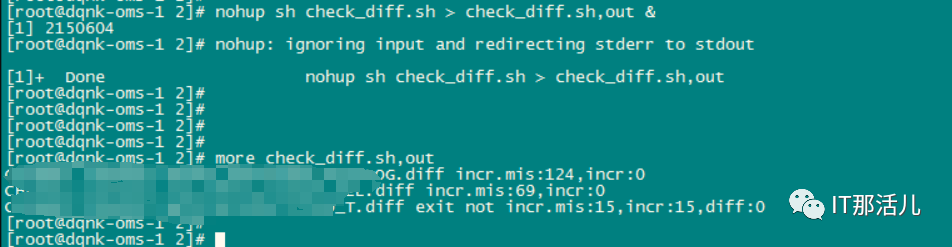
more diff.sh.log|awk '{if(NF>3){print $0}}'

more total_unincr.txt|sed -ne '/BEGIN: owner.table_name/, /END/p'|grep -Ev "BEGIN|END"

more total_unincr.txt|sed -ne '/BEGIN: owner.table_name/, /END/p'|grep -i MODIFY|awk -F 'rowid":"' '{print $2}'|awk -F '","' '{print $1}'

2.7 全量校验结果分析脚本
#!/bin/bash
#time时间选取一般为校验发起时间,可以自己根据diff文件选择特定值
time="2023-11-19 16"
base_dir="/home/ds/run/10.***.***.***-9000:90256:0000000042/verify/2"
for owner in $(ls -ltr $base_dir|grep -i drw|grep -Ev "chkbackup|chk"|awk '{print $9}');do
cd ${owner}/diff/
for file in $(ls);do
mis_count=$(more $file|grep -i MODIFY|wc -l)
incr_count=$(more $file|grep -i MODIFY|grep -Ev "$time"|wc -l)
diff_count=$(expr $mis_count - $incr_count)
if [ $incr_count -eq 0 ];then
echo "$owner.$file incr.mis:$mis_count, incr:$incr_count"
else
echo "$owner.$file exit not incr.mis:$mis_count, incr:$incr_count, diff:$diff_count "
echo "BEGIN: $owner.$file" >> $base_dir/total_unincr.txt
more $file|grep -i MODIFY|grep -Ev "$time" >> $base_dir/total_unincr.txt
echo "END" >> $base_dir/total_unincr.txt
fi
done
cd ../../
done
本文作者:冯俊鸿(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
