




最近公司在忙将MySQL上的数据同步到适合AP的分布式数据库中.又因原来在使用大数据Hadoop架构会有出现数据不一致的情况,所以就想找找数据比对的工具。但没有找到适合自己环境的工具,所以就想自己写一个小工具达到数据比对的效果
先上导图
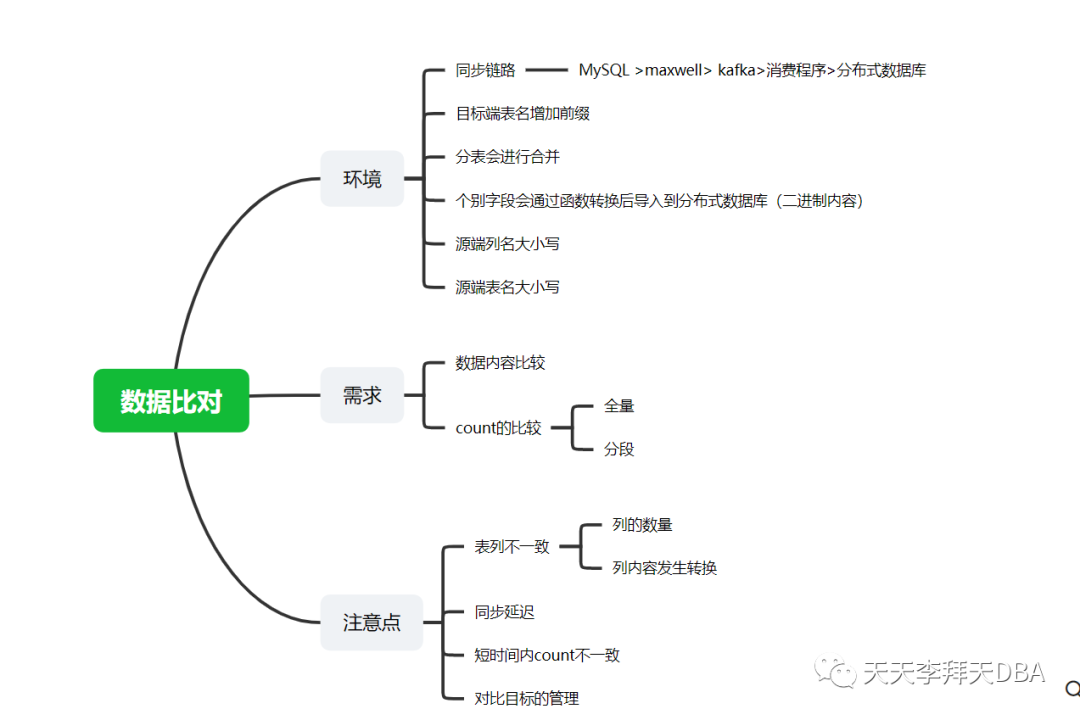
环境
同步链路: MySQL > Maxwell > Kafka > 消费程序 > 分布式数据库 因为我们是将多个业务数据库汇聚到一个库中,因此在原表名基础上加了前缀 源端有分库分表操作,因此在目标端会将多个表汇总到一个表中 源端表的列中存放的是二进制内容,但分布式数据库中暂不支持类似功能的转换函数 如 to_base64()
以方便应用查询。 因此在插入目标端前就进行了转换源端表名有大小写之分且大小写敏感 列表有会到小写之分
需求
虽然对数据一致性要求肯定是完全一致(数据库不支持功能进行转换除外),但我们的数据比对却不是希望像大部分比对工具那样进行全量比对。毕竟数据量摆在那里,我们想要的效果是尽可能及时的发现数据的不一致性问题,尤其是那些因为增量同步链路中程序问题导致的全局规律性的不一致问题。
因此我们就是从增量数据的比对下手。总体来说有两类
进行count结果的对比 对行的具体数据对比
进行count 结果的对比
整张表的count 通过where 条件过滤后进行count : id生成是具有一定规律例如id的部分是与时间有关的; 又或者某列是时间类列。 通过统计前一天或前N天进行count 对行的具体数据对比;
我是通过将源端表按照第一列(
where order by 1 desc limit 100
)进行倒叙排序抽出100行,再从中随机抽出10行,去目标端查出对应数据,在程序中生成MD5
值得比较。
根据各业务类型的表选择使用哪种或者多种方法进行比较
注意点
表名增加前缀 表列不一致,因此在进行行数据比较时需要以源端列名及列顺序为依据进而生成MD5值 同步延迟。延迟的原因多种多样,比如同步周期、源端数据库所在的数据中心与目标端不在一处。因此在比较时或是设置延迟获取数据,或者增加 where
过滤条件在中小表进行全表 count
是没有设置延迟获取时间进行比较的,因为延迟同样可能会导致count
值不等的问题。对此增加了比对次数的机制,只要有一次成功就代表成功对比目标管理,我这里是做了一个元数据表,定时获取源端表信息。通过该表来控制校验对象,同事通过程序配置文件中的忽略表参数来配合控制
不足
这里肯定有很多不足,目前想到的有
全表 count
肯定会因为延迟导致count值不准而误报的问题在从源端获取100行中,是依靠 排序第一列进行筛选的,但如果第一列为字符串或字符串与整数结合,就可能导致获取的100行数据无法达到获取最新数据的目的 没有考虑到 update
操作的方法还有就是列数据进行转换后进行同步,又因该表数据量极大,导致只能通过配合 where
进行范围count
进行比较这个程序默认表第一列为主键且为单一主键的表结构。没有一个对源端表信息分析的过程(分析主键有哪些) 对数据库本身性能监控,如数据库压力大就不去检查。
上面这些问题,有的有大概的解决思路,有的还毫无头绪,因为时间短也只能留到后面在进行完善解决了。
上面就是我对这次写的比对工具的一个记录了。有时候想我做数据比对其实并不想每次都全量比对。只想比较一部分数据或者增量数据就可以但又想尽快且成本小的知道数据同步出现了问题。但好像并没有类似的工具,可能别人觉着这里面灵活性,不确定性太多,也可能这样的需求并不多吧。
如果觉着有收获请点赞转发。谢谢!! ^_^!
文章转载自天天李拜天DBA,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
