




谈到MySQL数据库表设计和SQL优化,都会了解要有索引,可以说MySQL就是索引的代名词。这话一点都不夸张。MySQL数据库底层的innodb引擎就是索引组织表。数据行的所有操作都是基本主键进行的。
数据库中定义的主键具备如下特性:
1、任何两行都不具有相同的主键值,保证唯一性。
2、每个行都必须具有一个主键值(主键列不允许NULL值)
目前来说MySQL的处理逻辑都是跟主键绑在一起。主键的重要度不言而喻。
官方说明
表中每一行都应该有可以唯一标识自己的一列,当没有设置主键的时候MySQL本身会生成隐藏的列做为主键。
-
When you define a PRIMARY KEY on your table, InnoDB uses it as the clustered index. Define a primary key for each table that you create. If there is no logical unique and non-null column or set of columns, add a new auto-increment column, whose values are filled in automatically.
当表上定义一个主键时,InnoDB使用它作为聚集索引。如果没有逻辑惟一的非空列或列集,则建议添加一个新的自动递增列,其值将自动填充。 -
If you do not define a PRIMARY KEY for your table, MySQL locates the first UNIQUE index where all the key columns are NOT NULL and InnoDB uses it as the clustered index.
如果没有为表定义一个主键,MySQL定位第一个UNIQUE索引,所有的键列都不是NULL, InnoDB使用它作为聚集索引。 -
If the table has no PRIMARY KEY or suitable UNIQUE index, InnoDB internally generates a hidden clustered index named GEN_CLUST_INDEX on a synthetic column containing row ID values. The rows are ordered by the ID that InnoDB assigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
如果该表没有PRIMARY KEY或合适的UNIQUE索引,InnoDB内部会在分配给一个6字节ID字段,作为隐藏的聚集索引,名为GEN_CLUST_INDEX 。行是按照隐藏ID为主键进行排序。因此,在插入新行时单调增加, 按行ID排序的行在物理上是按插入顺序排列的。
备注:聚集索引=主键=PRIMAYR KEY
表设计和SQL语句中的主键
在MySQL数据处理中,可以说主键就是大脑逻辑:
InnoDB引擎使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。
这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。
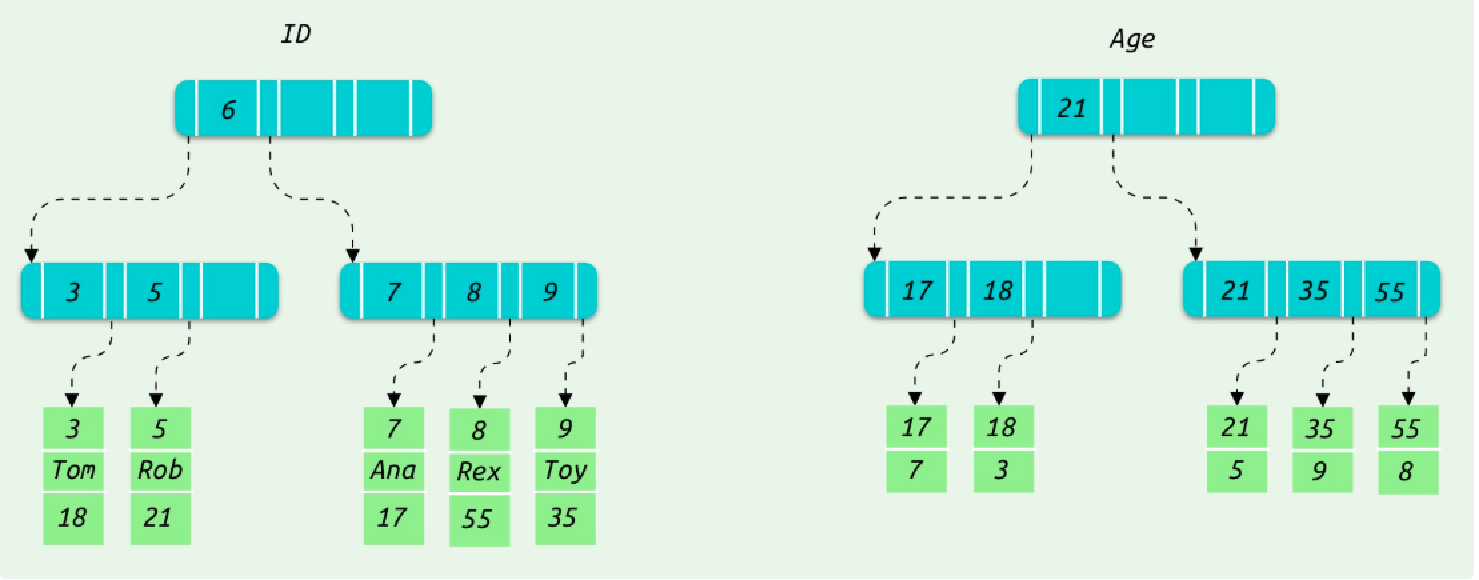
MySQL的数据结构和普通的查询如下:
#例如创建如下一张表:
mysql> CREATE TABLE users(
id INT NOT NULL,
name VARCHAR(20) NOT NULL,
age INT NOT NULL,
PRIMARY KEY(id)
);
mysql> INSERT INTO users(id,name,age)VALUES(3,'TOM',18),(5,'Bob',21),(7,'Ana',17),(8,'Rex',55),(9,'Toy',35);
#新建一个以age字段的二级索引:
mysql>ALTER TABLE users ADD INDEX index_age(age);
mysql>SELECT * FROM users WHERE age=35;
二级索引的检索过程:
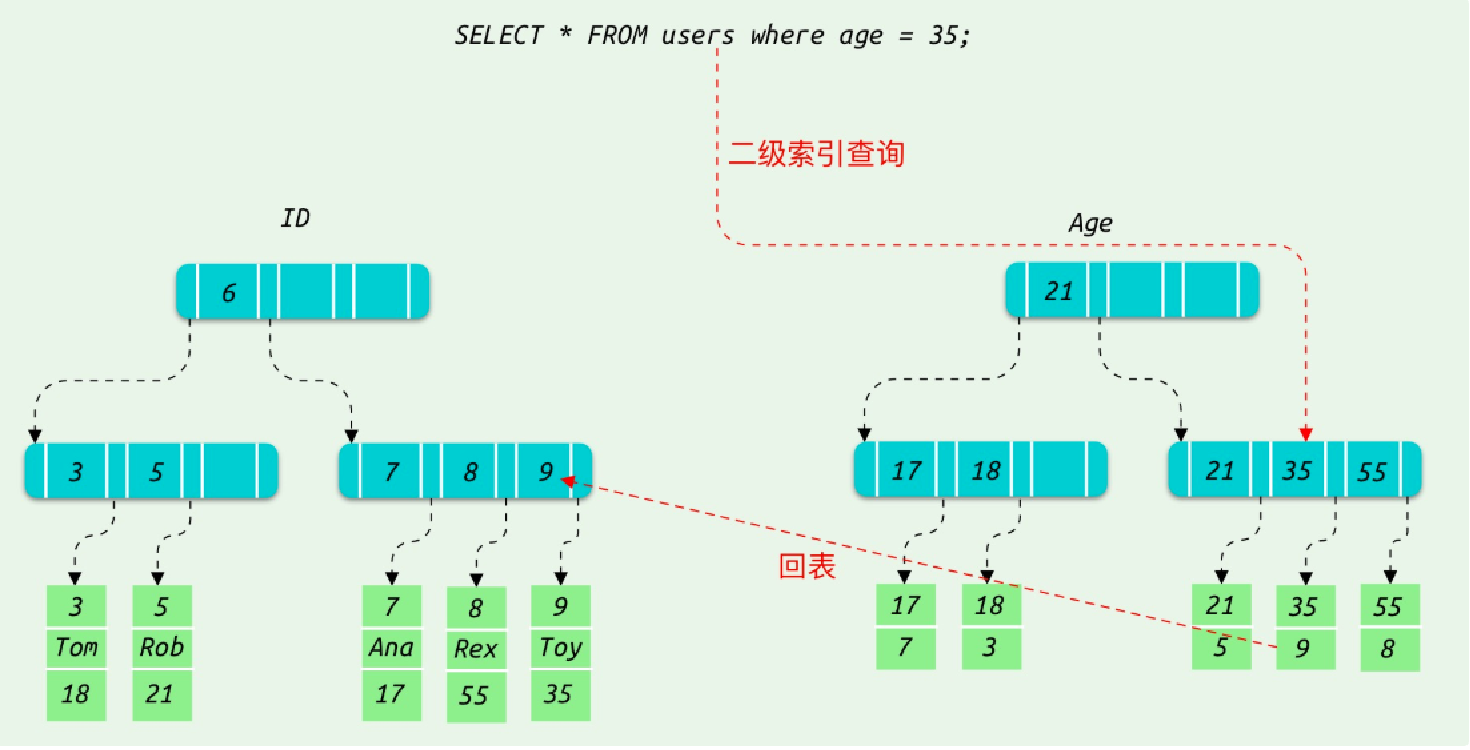
备注:二级索引是指定字段与主键的映射,主键长度越小,普通索引的叶子节点就越小,二级索引占用的空间也就越小,所以要避免使用过长的字段作为主键。
除此之外REPLACE INTO,ON DUPLICATE KEY UPDATE ,第三方mydumper单表逻辑导出并行方式都是依赖于主键或UNIQUE键。
高可用复制模式下主键
MySQL复制是逻辑复制,虽然有些差异,但等价于把SQL语句在另一个节点执行;
1.存在没有主键的表,导致备库应用每个Event 都需要全表扫描,导致大量的延迟。现在了解为什么主从复制延迟会经常碰到。
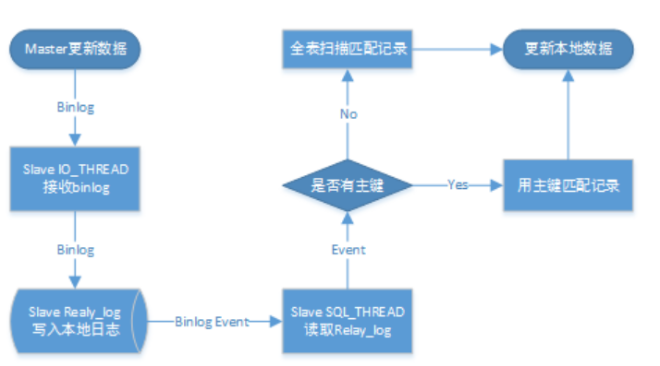
2.MGR里主键的必要性
要被组复制的每个表都必须有一个定义好的主键,或者一个等效的主键,其中等效的主键是一个非空的唯一键。这样的键作为表中每一行的唯一标识符是必需的,这样系统就可以通过准确地识别每个事务修改哪些行来确定哪些事务发生了冲突。
应该选择什么样主键
MySQL数据结构中理想状态下主键是什么样?
1、不更新主键列的值
2、不重用主键列的值
3、不在主键列中使用可能会更改的值
4、字段长度需要控制好,避免索引也频繁的分裂合并
1.自增主键
无特殊需求下Innodb建议使用与业务无关的自增ID作为主键:
1、如果表使用自增主键,以利于插入性能的提高。那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。

自增型主键设计(int,bigint)可以降低二级索引的空间,提升二级索引的内存命中率;
自增型的主键可以减小page的碎片,提升空间和内存的使用;
2、 如果使用非自增主键(如果身份证号,机构唯一代码等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置
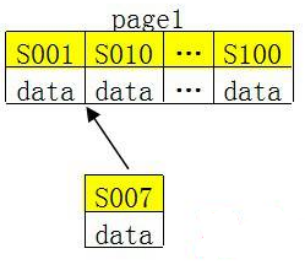
MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
3.使用自增长做主键的优缺点:
-
优点
1、很小的数据存储空间
2、性能最好
3、容易缓存 -
缺点
1、如果存在大量的数据,可能会超出自增长的取值范围。
2、可能不是连续的。5.7版本bug 重新启动,自增序列丢失问题
3、没有业务意义
4、很难处理分布式存储的数据表,尤其是需要合并表的情况下会存在冲突。
5、安全性低,因为是有规律的,容易被非法获取数据。
2.UUID生成的主键
UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符
- 经由一定的算法机器生成为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成UUID的算法。
- 非人工指定,非人工识别
UUID是不能人工指定的。UUID的复杂性决定了“一般人“不能直接从一个UUID知道哪个对象和它关联。 - 在特定的范围内重复的可能性极小
UUID的生成规范定义的算法主要目的就是要保证其唯一性。但这个唯一性是有限的,只在特定的范围内才能得到保证. - UUID通常以36字节的字符串表示,示例如下:3F2504E0-4F89-11D3-9A0C-0305E82C3301
- 时间戳+UUID版本号,分三段占16个字符(60bit+4bit),
- Clock Sequence号与保留字段,占4个字符(13bit+3bit),
- 节点标识占12个字符(48bit)
UUID 去除“-”: 32字节,但对于mysql 来说还是字段太长,字段基本无意义。
使用UUID做主键的优点:
1、出现重复的机会基本无
2、分布式环境下适合大量数据中的插入和更新操作
3、跨服务器数据合并非常方便
4、安全性较高
使用UUID做主键的缺点:
1、存储空间大(16 byte),因此它将会占用更多的磁盘空间
2、会降低性能
3、无法缓存大量数据
4、由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
5、对于更新UUID操作:UUID的无序和空间占的大小导致插入时候要耗费更多的时间去创建和维护索引
下面介绍下雪花算法:
SnowFlake算法介绍:
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:
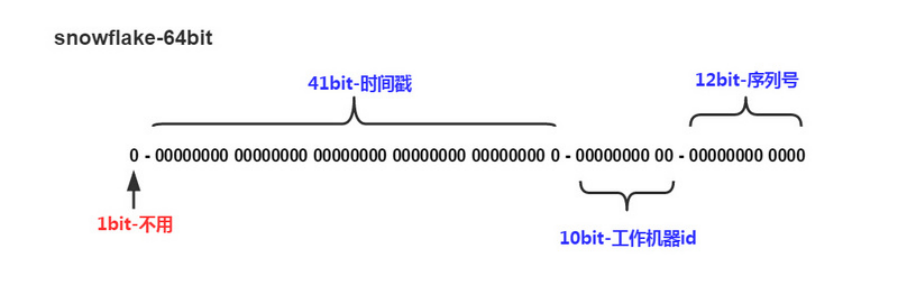

通过多从了解和收集信息: Twitter分布式自增ID算法snowflake算法生成id:Long类型占8个字
snowflake算法的好处:
- 生成的id是一个数字的Long类型
- 无需链接数据库或者redis,超高性能
snowflake算法的弊端:
- 每毫秒只能生成4096个id(内理论上最多可以生成1000*(2^12),也就是409.6万个ID)。
随着cpu不断的进步,每毫秒4096个id将不能满足。
可以不用担心,即便cpu性能超过了这个值,那么只需等待到下一个毫秒 - 每毫秒重新计数,空闲时间会浪费很多id空间。
-系统时间不可回退,回退将会导致id重复。另:系统时间可以前进,不受影响。
为了保证唯一性,业务UUID生成方式SnowFlake算法生成id:
SnowFlake算法生成Long类型占8个字节 可在前面加2个类型的业务字段
业务UUID=Long类型占8个字节+ 2个英文字节( 20个长度的UUID)
业务UUID=UUID去除”-”+ 2个英文字节( 32个长度的UUID)
3.业务含义的主键
通过架构规划定义的主键,应该是最有效的,利用率最高的。
比如订单方式:
地区+UNIX_TIMESTAMP+产品编号+随机号:SH+1637416219+P23+05
综合考虑建议使用业务主键,如uuid和自增主键使用的建议如下:
1、单实例下 ,并且数据量比较大(百万级)时,用自增长的,此时最好能考虑下安全性,做些安全措施。
2、单实例下,并且数据量没那么大,对速度和存储要求不高时,用UUID。
3、分布式的,那么首选UUID,分布式一般对速度和存储要求不高。
4、分布式的,并且数据量达到千万级别可更高时,对速度和存储有要求时,可以用自增长。
总结
总之主键对于MySQL来说,是非常重要的,每张表的设计的时,都应该把主键默认的加上,不管需不需要它。无主键的时候 可以选择自增型的主键。一个表必须要有一个主键,为方便扩展、松耦合,高可用的系统做铺垫。
①可以使用自增加主键 ID bigint(20) unsigned NOT NULL AUTO_INCREMENT,
②直接使用uuid
③按照业务考虑,自定义主键。 (snowflake+业务id)
④自定义有业务意义的主键
