




赛题名称:CCL23古籍命名实体识别 赛题类型:自然语言处理、实体识别
赛题信息
命名实体识别(Name Entity Recognition)任务旨在自动识别出文本中人名、地名、机构名等事件基本构成要素的重要实体。古籍文献的命名实体识别是正确分析处理古汉语文本的基础步骤,也是深度挖掘、组织人文知识的重要前提。
因此,我们基于“二十四史”,设计了涵盖人名、书名、官职名等多项的实体知识体系,建构了覆盖多个朝代的历时、跨领域的数据资源,完善古籍命名实体识别任务的建立。
本次古籍文献的命名实体识别评测,通过发布全新的基于“二十四史”的训练和测试数据集,提供统一的评测提交平台,以此推动技术的突破和发展,助力古籍资源的智能开发与利用。
评测数据
本次评测提供官方评测数据集“古籍命名实体识别 2023”(GuNER 2023),由北京大学数字人文研究中心组织标注,语料来源是网络上公开的部分中国古代正史纪传文本。数据包括供参赛队伍进行模型训练与调优的训练集,以及评测参赛队伍的模型性能的封闭测试数据集。同时,各参赛队伍可以自行使用其他公开的人工标注数据集和伪造数据集。
训练集以“二十四史”为基础语料,包含 13 部书中的 22 卷语料,随机截断为长度约 100 字的片段,标注了人名(PER
)、书名(BOOK
)、官职名(OFI
)三种实体,总计 15.4 万字(计标点)。各实体的标注要求详见标注规范。
https://fv4nltk75z.feishu.cn/sheets/shtcndkC7azQo2Tdb5R6h9Nz9Vh
评测数据集格式为文本文件,参赛队伍可根据模型需要进行转化处理。其中训练集数据样例如下所示,每行为二十四史原文中的一个段落,段中每一个实体以“{
}
”标识,“|
”后为实体类别。测试集数据近包含原文内容,参赛队伍需要提交在测试集文本上的实体识别结果文件,格式与训练集一致。
{輔元|PER}兄{希元|PER},{高宗|PER}時洛州{司法參軍|OFI},{章懷太子|PER}召令與{洗馬|OFI}{劉訥言|PER}等注解{范曄|PER}{後漢書|BOOK},行於代。先{輔元|PER}卒。
{友倫|PER}幼亦明敏,通{論語|BOOK}、{小學|BOOK},曉音律。{存|PER}已死,{太祖|PER}以{友倫|PER}為{元從馬軍指揮使|OFI},表{右威武將軍|OFI}。
评价标准
本次评测的测试数据集采用封闭方式给出,即仅给定原古文文本,需要参赛队伍训练模型对文本中的命名实体进行自动识别和标注,并将结果文件上传至在线评测平台,获取评测指标得分。
本次评测使用 准确率(Precision)、召回率(Recall) 和 F1 作为评价指标。
开放赛道:参赛队伍可使用 ChatGPT、文心一言、ChatGLM 等大模型。评测提交地址为:https://tianchi.aliyun.com/dataset/151111 封闭赛道:参赛队伍禁止使用大模型。仅允许使用拥有开源 License(如 GPL、BSD、MIT、Apache 等)。评测提交地址为:https://tianchi.aliyun.com/dataset/151499
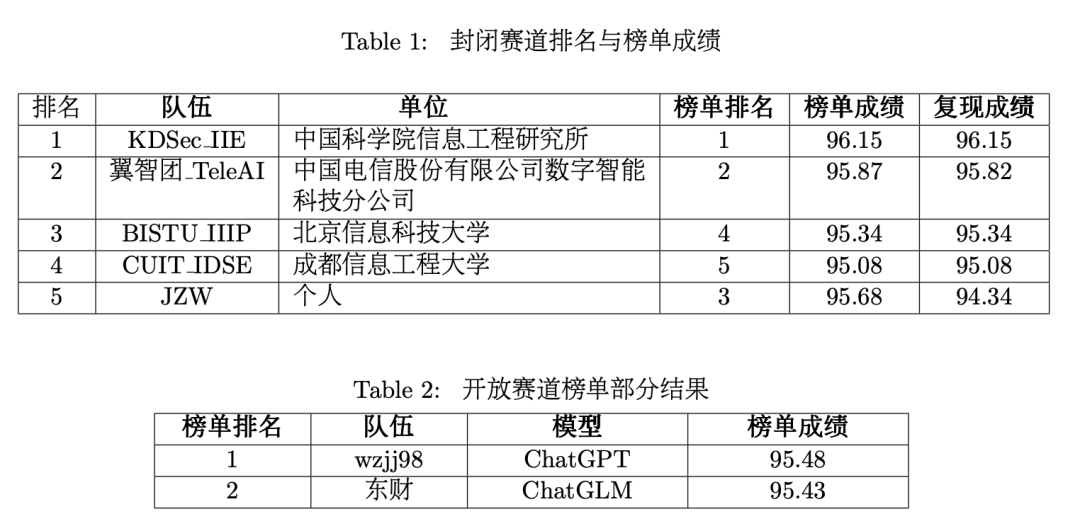
评测结果总结
本次评测于2023年4月10日开启报名,共吸引了127支队伍报名参与,体现了行业对古文自然语言处理技术的关注。
第一名的参赛队伍KDSecIIE所使用的预训练模型是RoBERTa,预训练参数来自于在古文数据上训练的Roberta-classical-chinese-large-char,是GuwenBERT的改进版本。此外,该队伍设计了Token-wise感知的序列标注和Span-level感知的实体识别两种框架,融合两种框架的实体预测结果,集成多个结果以提升识别性能。其中,Span-level感知的框架是穷举输入句子中所有满足最大实体长度限制的实体Span,进而计算每个Span在每个实体类型标签下的概率分布。同时,从信息论的视角显式地约束实体特征的表达,即最大化实体上下文特征与标签之间的互信息,以及最小化冗余信息。
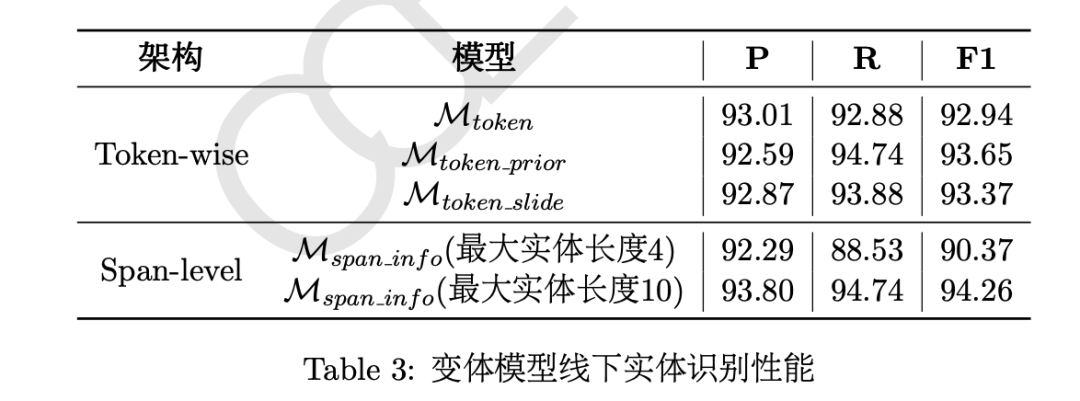
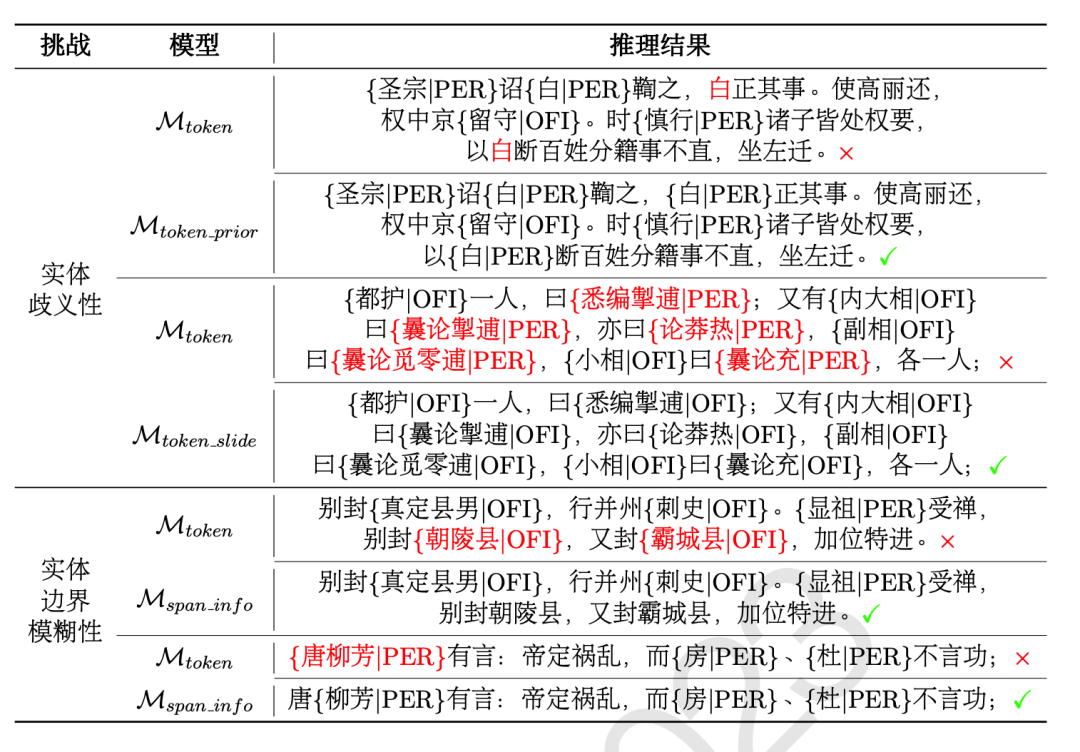
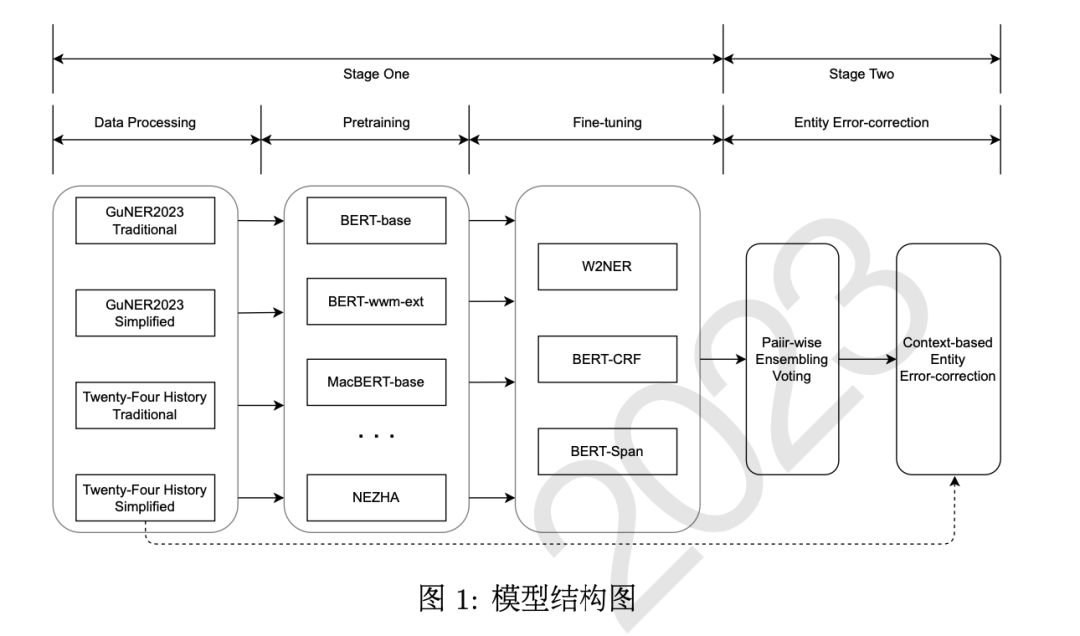
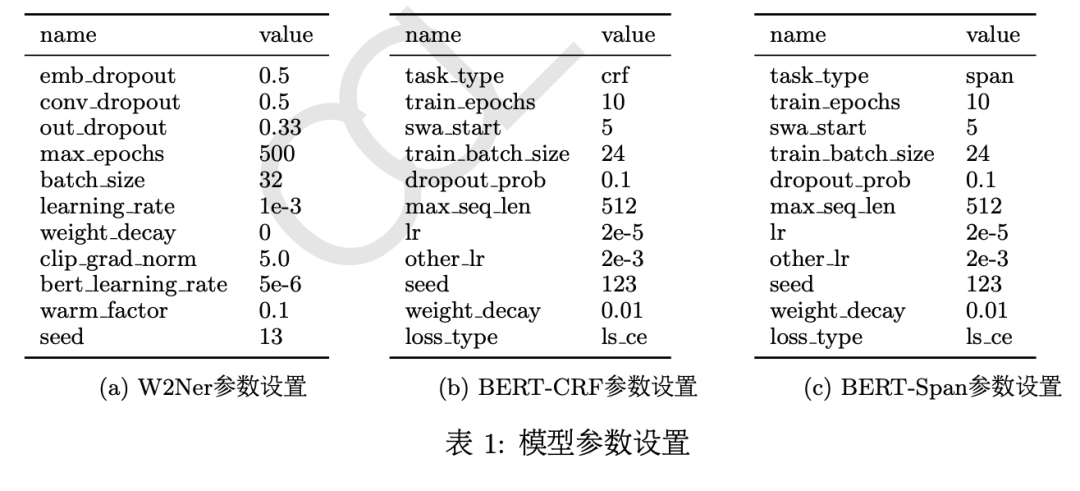
第二名的参赛队伍翼智团-TeleAI基于BERT、 ERNIE、GuwenBERT和MengziBERT等预训练模型,使用未标注的“二十四史”文本进行领域持续训练,然后使用GuNER2023训练集进行任务持续预训练,再使用W2NER、 BERT-CRF和BERT-Span进行微调,实验结果表明基于字级别特征的W2NER可以更好地捕获词语之间的联系,实体识别性能最好。最后基于上下文信息融合多个模型的实体识别结果,进一步提升了模型性能。
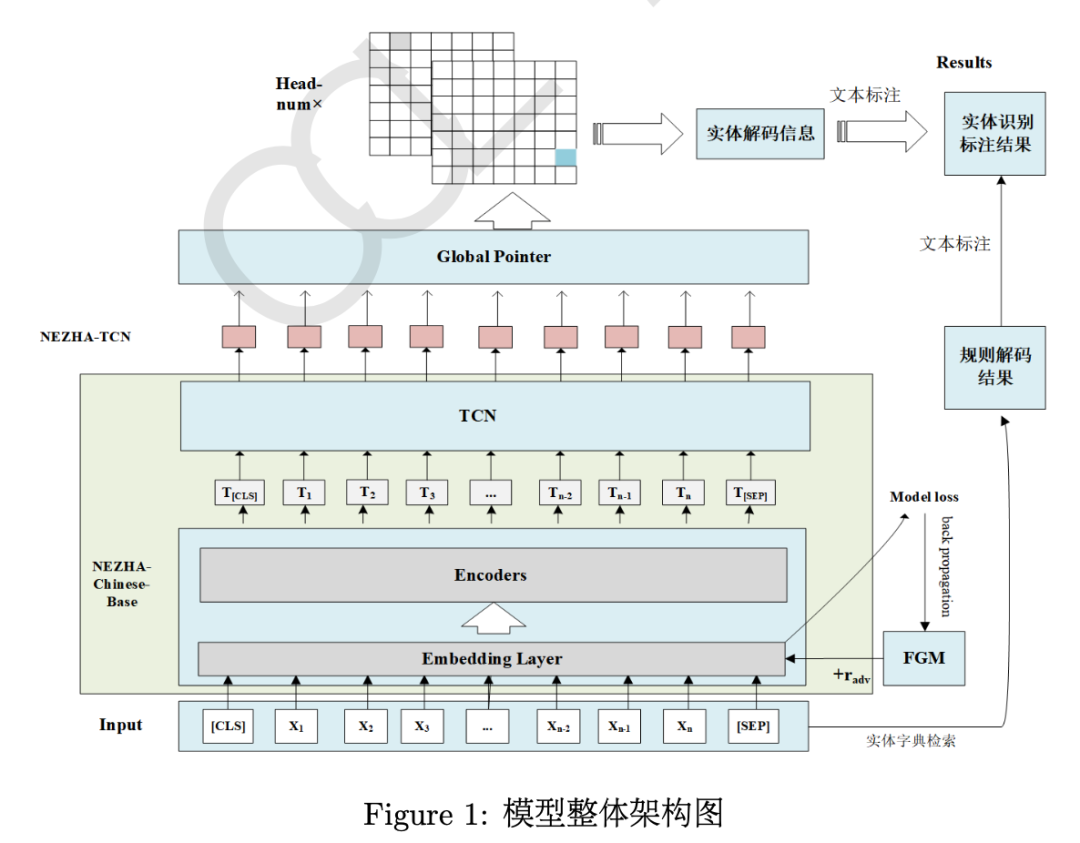
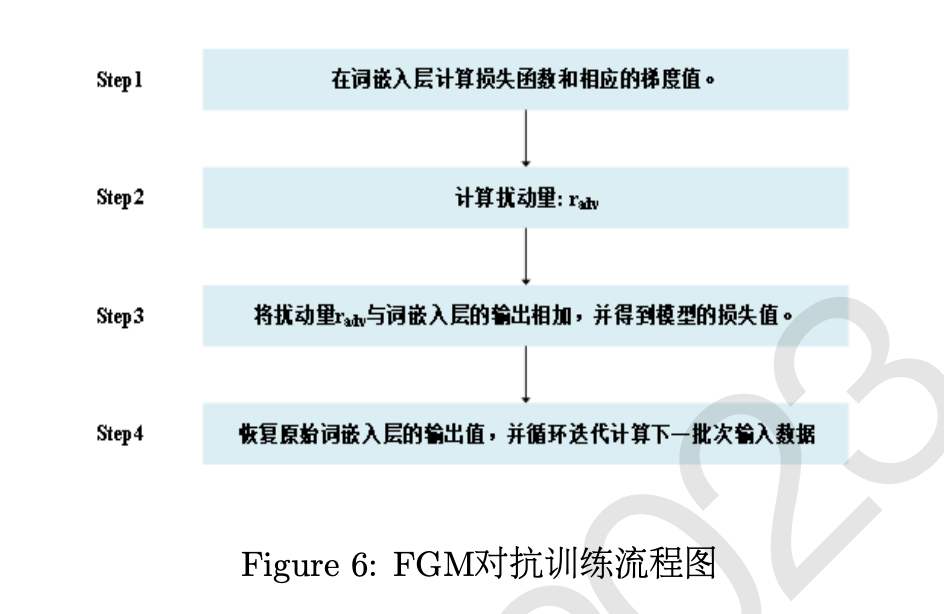
第三名的参赛队伍BISTU -II所使用的预训练模型是NEZHA-Chinese-Base模型,相较于BERT采用相对位置编码词向量,可以更好地挖掘文本中的字符关系。在其后接入两层的时序卷积神经网络用于挖掘局部时序关联语义信息,并基于未标注的“二十四史”文本进行持续预训练。解码层使用全局指针网络以更准确地识别实体边界,得到实体预测结果。同时为了增强模型的泛化能力,使用对抗学习方法中的快速梯度法在模型训练过程中添加干扰信息,以提升模型性能。该队伍没有融合多个模型的识别结果,但在后处理阶段结合规则改善了漏标、错标的常见错误,矫正模型输出,提升评测结果。
第四名的参赛队伍CUIT IDSE所采用的的方法也是基于预训练模型BERT在未标注的“二十四史”文本上进行领域持续训练和任务持续训练。同时在模型训练中也使用对抗学习方法添加干扰信息,提升模型的泛化能力。解码层使用全局指针网络,同时融合多个模型的识别结果,也使用了基于规则的后处理方式,矫正模型输出以提升性能。
第五名的参赛队伍JZW使用了预训练模型BERT 获取输入文本的表征,同时提出基于提示学习思想的PromptNER模型,将与实体类别有关的提示词(人、书、职)进行串联和联合编码,增强实体与类别的语义交互。解码层采用全局指针网络,基于Span预测在每个提示词上的概率分布,即可得Span对应的实体类别。该队伍同时也使用了对抗学习方法增加干扰信息,提升模型的泛化能力和性能。
队伍:中国科学院
队伍:中国电信
队伍:中国工商银行
💖私聊小助手,报告PDF汇总💖
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

