




点击上方蓝字关注我们

本期的Tech Talk将主要介绍Global MVCC特性及其实现技术,期望能让大家在对于这一关键特性有认识的同时,对Klustron有一个更为深入了解。
为促进团队内外的沟通联系,我们Klustron团队的bbs论坛开始上线,欢迎各位同学使用!(链接:https://forum.klustron.com/,或者点击文末“阅读原文”,即可跳转)
论坛目前是测试版,可能还存在不稳定的现象,欢迎各位老师、朋友共享信息,如果遇到问题还请谅解。
1
Klustron简介:
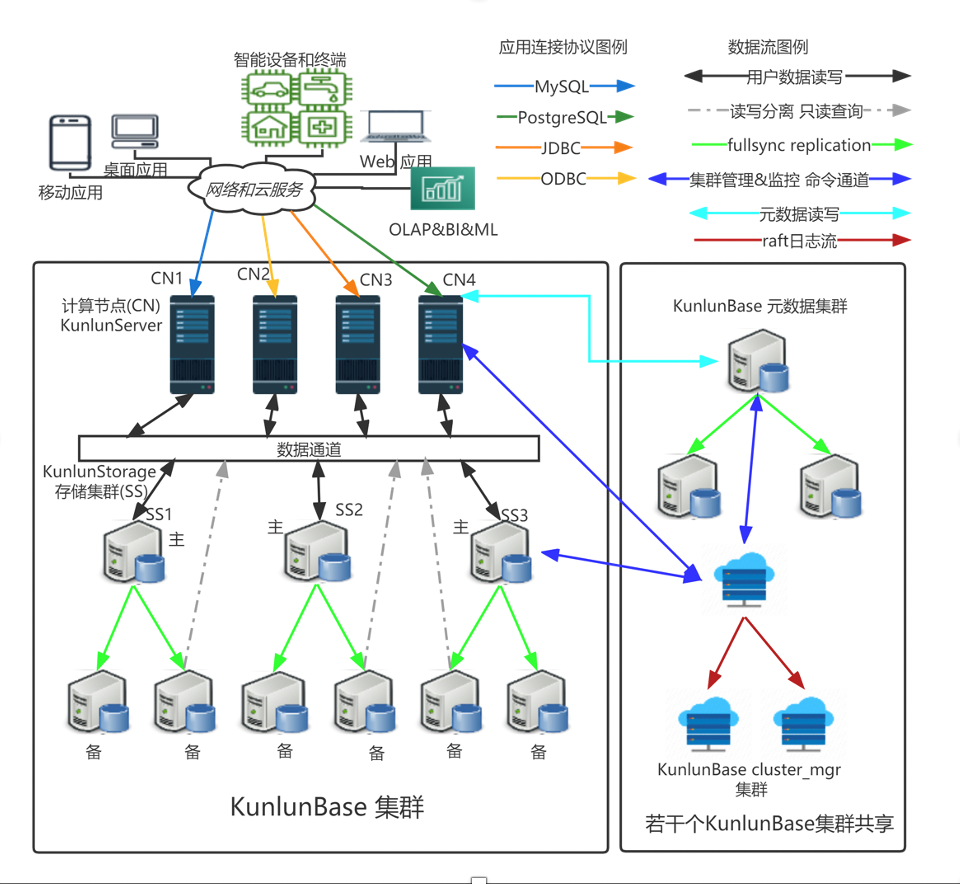
弹性伸缩的计算和存储能力 数据分区(partition): hash, range, list 任意数量和类型的分区列 数据分布(distribution) auto, random, mirror, table grouping 自动、柔性、不停服、无业务侵入、终端用户无感知 金融级高可靠性 自动处理软硬件和网络故障和机房整体故障 数据不丢不乱,服务持续在线 确保RTO < 30秒 & RPO=0 自动发现主节点故障并选主和主备切换 HTAP: OLTP & OLAP 互不干扰 OLTP为主:对应用软件等价于使用MySQL或PostgreSQL OLAP为辅:多层级并行查询实现高性能 多语言存储过程的弹性计算:ML,隐私计算 生态兼容性 支持PostgreSQL和MySQL 两种连接协议和SQL 语法 支持MySQL 常用DDL语法 支持JDBC,ODBC,常见编程语言的PostgreSQL和MySQL 客户端connector 全方位多层级安全性 加密存储和传输 多层级访问控制机制
2WHY
Why?
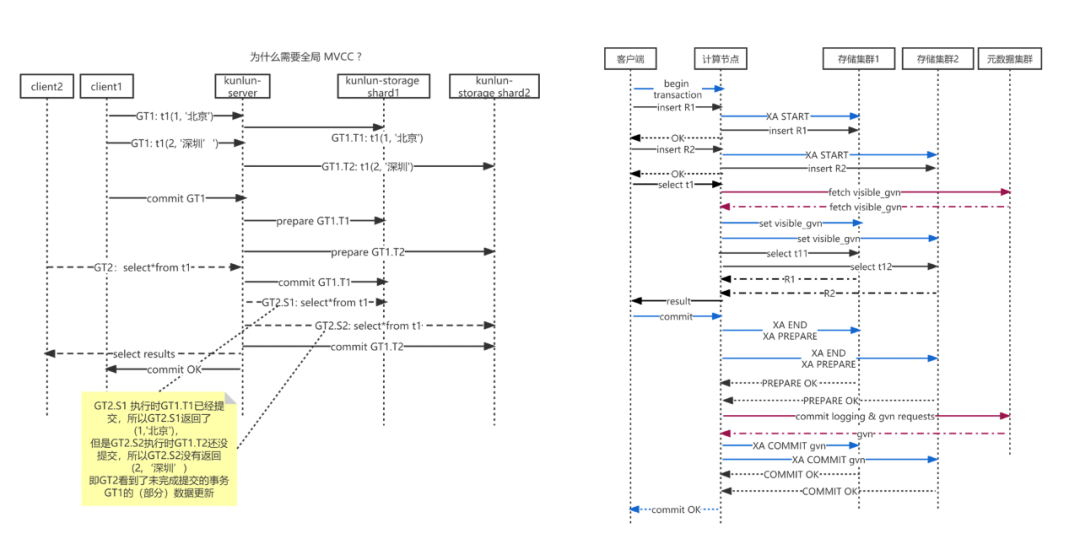
我们先来看看分布式事务的读一致性问题,如下图所示
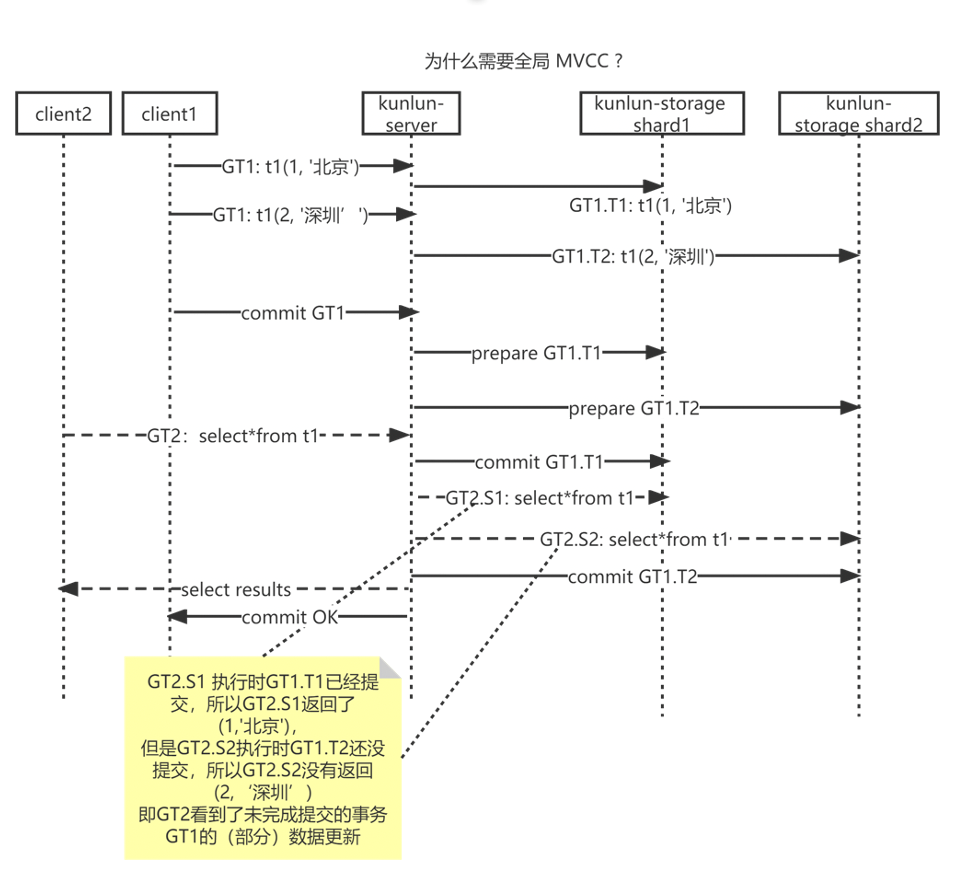
正在提交的分布式事务GT1
写入多个 shard (shard1 GT1.t1 & shard2 GT1.t2)
分两阶段提交
正在运行的SELECT(GT2)
读取到GT1.t1在shard1的更新
未读取到GT1.t2在shard2的更新
这就造成了只能读取事务的部分数据的不一致情况。
为了解决这个问题,Klustron实现了Global MVCC,其原理主要是通过建立全局快照来获取当前事务的可见数据。
3
Global MVCC原理及实现
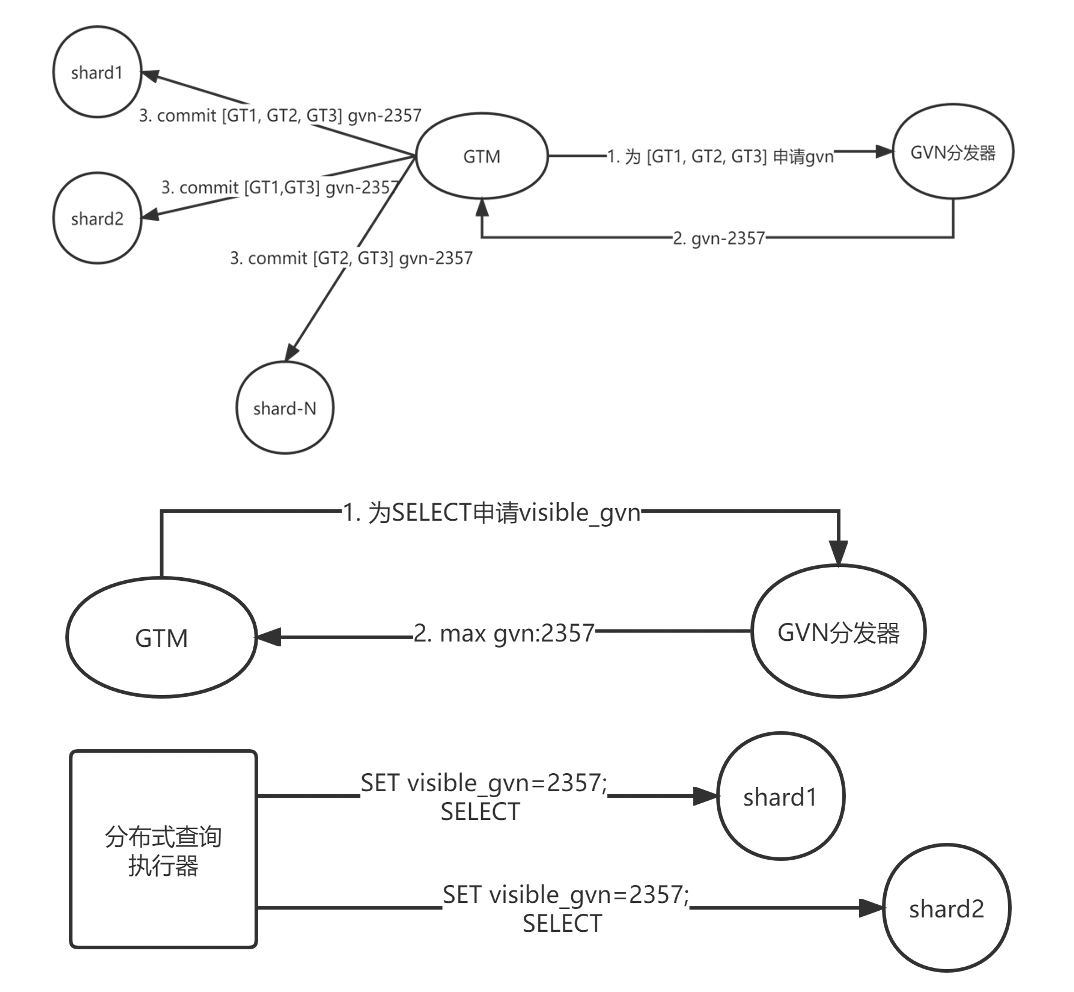
首先是上层计算节点部分,如下图所示,首先需要为所有的分布式事务获取和设置全局版本号,然后再通过全局版本号来建立全局快照。
而在下层的存储节点,通过修改MySQL InnoDB存储引擎的相关部分实现对全局快照的支持。如下图所示,我们主要修改了InnoDB的事务可见性判断流程。
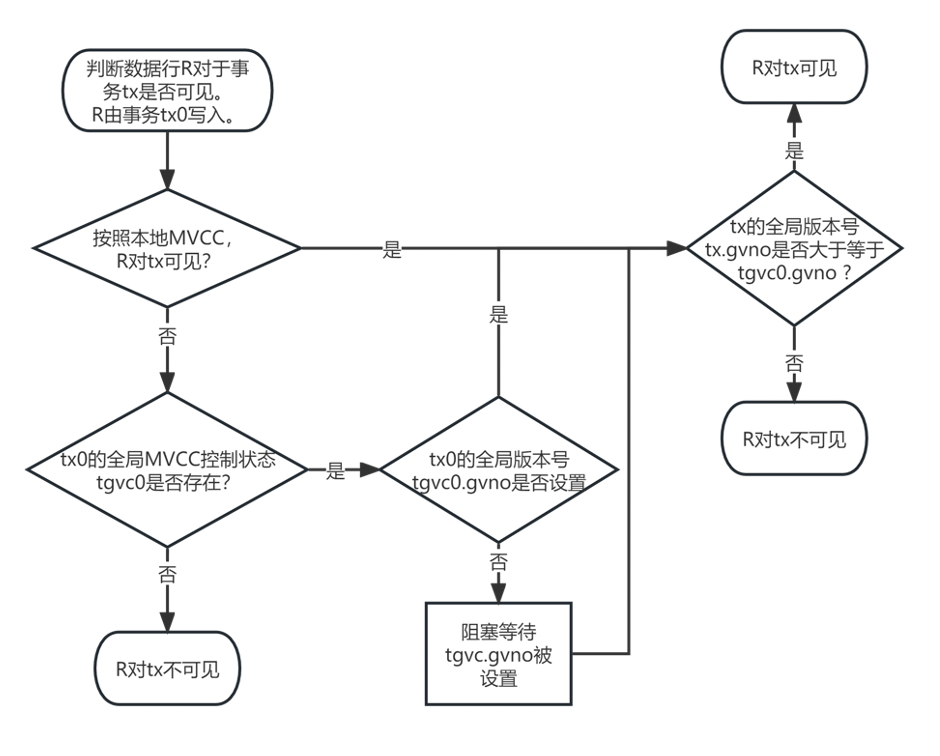
全局可见性判断算法:仅针对XA事务的更新
先做局部可见性判断
局部可见未必全局可见
小于local_xmin 的一定可见
局部不可见未必全局不可见
获取快照时尚未启动的一定不可见
全局版本号对比
全局不可见怎么办?
用undo log生成更老的行版本
上述改动完成后,我们再来对比一下修改前后的流程差异,如下图所示,通过全局版本号和全局事务快照,我们就能避免事务的一致性问题。
最后,我们来分析一下Global MVCC的性能代价。由于Global MVCC的一些关键流程会带来一定的时间和资源代价,所以,会有一定的性能损失。根据我们的测试和分析,其性能损耗在5% - 10%,属于可以接受的范围。
综合分析如下:
计算节点:
未增加新的已有的时间开销
分配GVNO:随XA COMMIT 语句发放一个整数,存入tgvc_cache中的tgvc
忽略不计
获取全局快照:网络收发开销
每个SELECT语句(RC)或者每个事务(RR)获取一次
从元数据集群sequence取得当前值 select currval(‘global_mvcc_seq’)
分配全局快照:随SELECT语句下发一个整数
忽略不计
存储节点:
tgvc管理:忽略不计
Global MVCC 可见性判断逻辑:整数比较
少量READ等待设置全局版本号:等待时间通常 < 20ms
覆盖索引查找:页头部max_trx_id:上一次更新本页的事务
以前:readview 可见本页所有行(rv.m_up_limit_id > max_trx_id),则直接返回索引行。
现在:上述成立并且如果max_trx_id > local_xmin, 必须回表以便查找。
回表查找的比例略有增加
purge:保留undo log直到global mvcc不再需要由global_xmin 的上升来推动
4
Q&A

