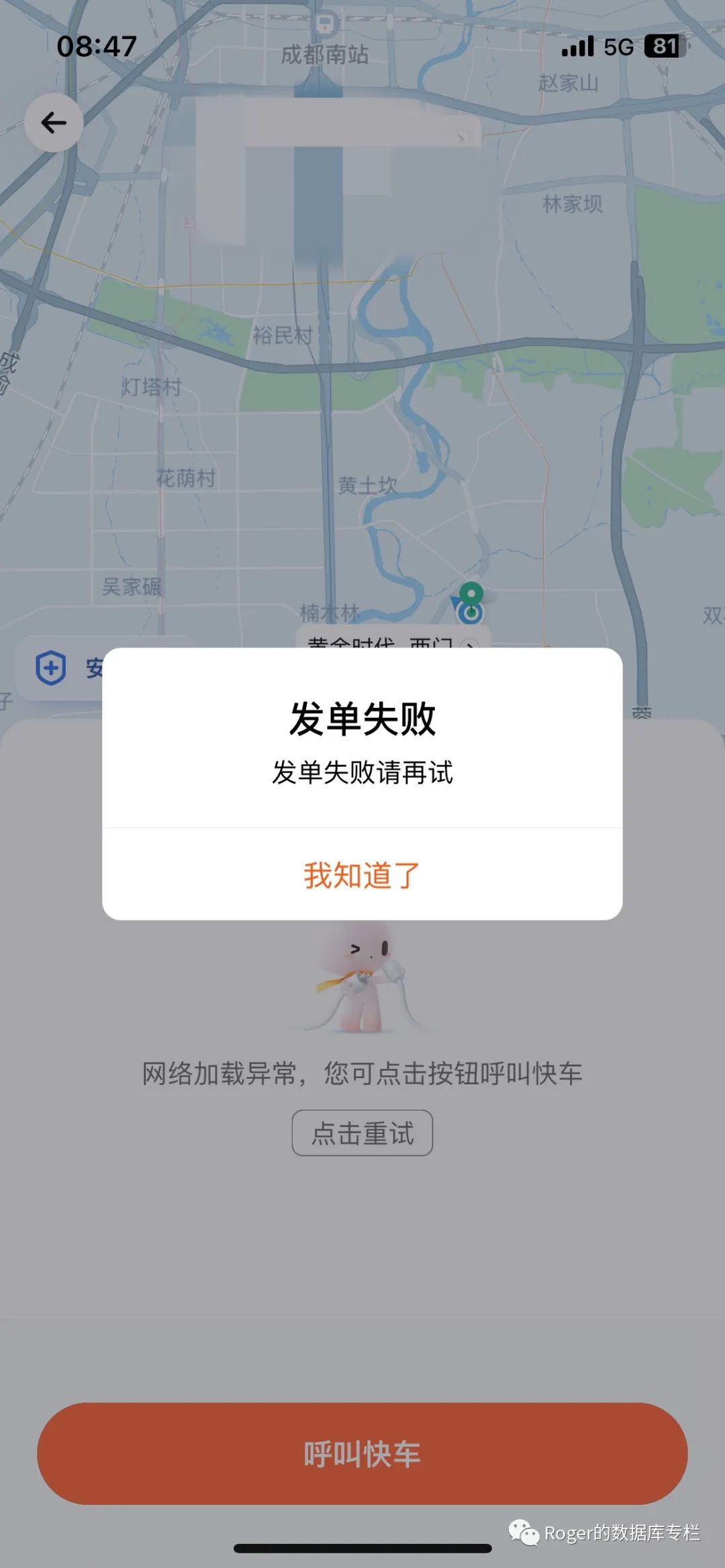
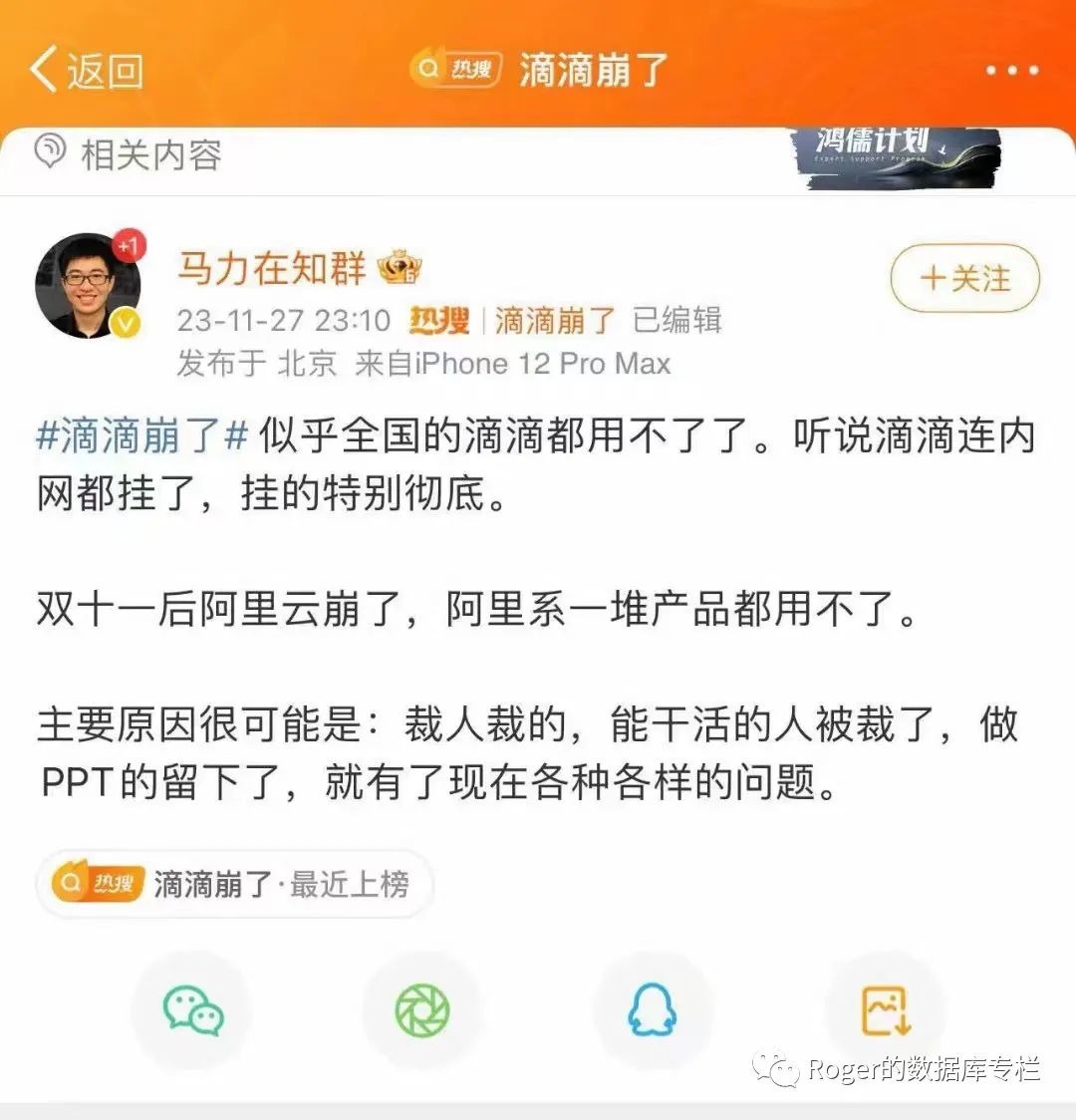
前段时间阿里云的大故障直接上了热搜,大家估计都还没缓过来,这几天滴滴打车平台又来一个P0 故障....这这这...直接导致我到客户现场晚了30分钟,最后无奈使用百度打车...
不知道为什么最近故障频发,小道消息说是人员优化了干活主流,留下了一些ppt忽悠高手.....刚看一个视频提到,按照滴滴的运营数据来看,一天多少3300w单,此次故障直接到手营收损失4个亿;根据滴滴的抽成比例平均25%来算,大概就是损失1个亿的利润呀!可怜的是运维的兄弟估计绩效全部要打C了....说到系统故障,实际上我们作为数据库厂商,每年也要经历多次故障,甚至是一些我方人员的失误而导致的。我们也曾经做过很多的努力和尝试,发现故障总是难以避免。这种其中有太多的原因,这里大概简单总结几点:1、 运维系统流程不规范、缺乏监管,缺乏AB角(这个范围很大很大)
2、技术人员技术能力不够,二线把关不管,导致变更方案漏洞百出3、高可用、备份方案形同虚设,从来没有进行过演练。对于第一点运维流程而言,实际上不同客户可能都有一套熟悉自己的流程系统,相对来讲,银行、电力等客户流程管控比较严格一些;所有操作都必须要有工单,操作行为需求提前审核报备,任何操作都必须要有回退应急方案等等。我们曾经也帮助过不少客户做过这些流程化方面的建设,取得了一些成果和收获。
其次现在不少技术人员对很多技术细节理解不到位,完全照搬,变更方案也没有经过二线团队严格审核或者审核不仔细等等,最终都会引发很多问题,这方面我曾经接触过HW的流程,平心而论,是非常给力的;整个流程形成全流程闭环,可追踪,可自动升级,每一级owner都对审批结果负责。
最后说到高可用和备份等方面,实际上互联网行业我认为这方面做的算是最好的了吧;但仍然会出现类似重大故障。实际上在传统toB行业中,很多客户高可用是形同虚设的,没有真正实践过,或者很多方案完全就不靠谱。曾经有见到有客户使用Goldengate做数据库级别异地双活的,大概率也是前些年被互联网的同城双活、异地多活等忽悠太多了。。
就拿我们所服务的上千家toB客户来讲,真正实现数据库同城双活的并不多,当然原因有很多,主要是投入成本太高,运维难度也大很多,整个tco就不那么经济了,其次我认为几乎99%的用户不需要。实际上现在不管是主流的Oracle、MySQL或者PostgreSQL,甚至是国产达梦、openGauss等数据库,应用设计合理,RTO都可以做到很低,甚至10s以内,完全是符合要求的。我们如果去真正统计因为故障影响业务的一些情况,你会发现绝大部分不是数据库本身,或者架构问题,而是应用SQL代码、人为误操作等原因,真正涉及到硬件或者数据库软件本身,比例是比较小的。数据库有高可用,但是需要定期进行演练。演练并不是说切过去,做做小样子就好了;实际上我们确实见过不少用户是这么干的,主中心切换到灾备中心,业务能正常启动,就切换回来了。这实际上是不可取的。要验证灾备份中心能不能承担业务,那么起码要稳定运行一周或者1个月吧。很多银行客户会进行季度演练,这是好事儿。不过客户,比如医疗,别说切换演练了,可能连容灾环境都没有;至于说备份,那么可能就是一个本地备份或者挂了一个NAS做rman或者定期数据逻辑导出备份。
对于如何去避免故障,需要做的事儿很多,我认为首先就要从流程体系、规则制度、操作规范等方面去考虑,这才是最为重要的,基本上可以避免99%的故障了。其次才是提高系统本身高可用能力,容灾备份能力。说到这里,我们这几天正在帮助一个客户做数据库恢复,大概10个TB左右,无备份,主要是因为备份太大空间不足等等。实际上上半年我们也做过一个类似case,客户数据库大概100TB左右,之前数据库小的时候,还可以用NBU之类的软件定期做个备份,然后随着数据量越来越大,后面备份跑不动了,一次全备就要好几天,这可咋整,实际上后面就没做了。。。当然,最后硬件故障后,就找到我们了。。。实际上这方面我们也有一些好的解决方案,比如ZDBM备份 一体机,利用CDM技术,100TB级别的库,可以在几分钟拉起数据库,快速恢复业务;最大程度降低用户损失。
年底总是故障高发期,大家要注意了,为了自己的绩效!