




比赛标题:X光安检图像识别挑战赛2023 比赛类型:计算机视觉、物体检测
https://challenge.xfyun.cn/topic/info?type=Xray-2023
赛事背景
X光安检是目前在城市轨交、铁路、机场、物流业广泛使用的物检手段。使用人工智能技术,辅助一线安检员进行X光安检判图,可以有效降低因为安检员经验、能力或工作状态造成的错漏检问题。在实际场景中,因待检测物品的多样性、成像角度、重叠遮挡等问题,X光安检图像检测算法研究存在一定挑战。
赛事任务
本赛事的任务是:基于科大讯飞提供的真实X光安检图像集构建检测模型,对X光安检图像中的指定类别的物品进行检测,识别出物体的位置和类别。

数据说明
此次比赛提供带标注的训练数据,即待检测物品在包裹中的X光图像及其标注文件。
本次比赛标注文件中的类别为9类,包括:刀(knife)、钳子(tongs)、玻璃瓶(glassbottle)、压力容器(pressure)、笔记本电脑(laptop)、雨伞(umbrella)、金属杯(metalcup)、剪刀(scissor)、打火机(lighter)。
比赛提供的X光图像及其矩形框标注的文件按照数据来源存放在不同的文件夹中,图像文件采用jpg格式,标注文件采用xml格式,各字段含义参照voc数据集。voc各字段含义对应表为:
方案分享
第一名
团队通过分析比赛任务的特点,如小目标、目标稀疏和类别不均衡等问题,提出了一系列优化方案。
首先,在基础模型选择上,采用了CBNet VR,并使用公开的预训练权重进行初始化训练。 其次,在标签分配策略上,采用了最新的2022年提出的方法,解决了微小目标识别问题。此外,团队还进行了多种数据增强,包括随机裁剪、填充、缩放和粘贴等,以解决类别不均衡和目标稀疏的问题。 在集成策略上,采用了NMS、WBF和SoftNMS等方法,提高了检测框的精确度。
团队还进行了多个实验,选择了最优的模型和参数,并在初赛的第二阶段进行了半监督学习,通过生成尾标签进行模型微调,最终取得了不错的成绩。
未来,团队计划将数据增强和类别分配策略应用到单阶段检测器中,并进行模型的量化压缩,以进一步提升性能。
第二名
团队SSWY在本次比赛中取得了一些成绩,并对赛题进行了详细的分析和数据统计。我们发现大部分目标的长宽比都比较正常,小目标和图像多尺度是存在的问题。

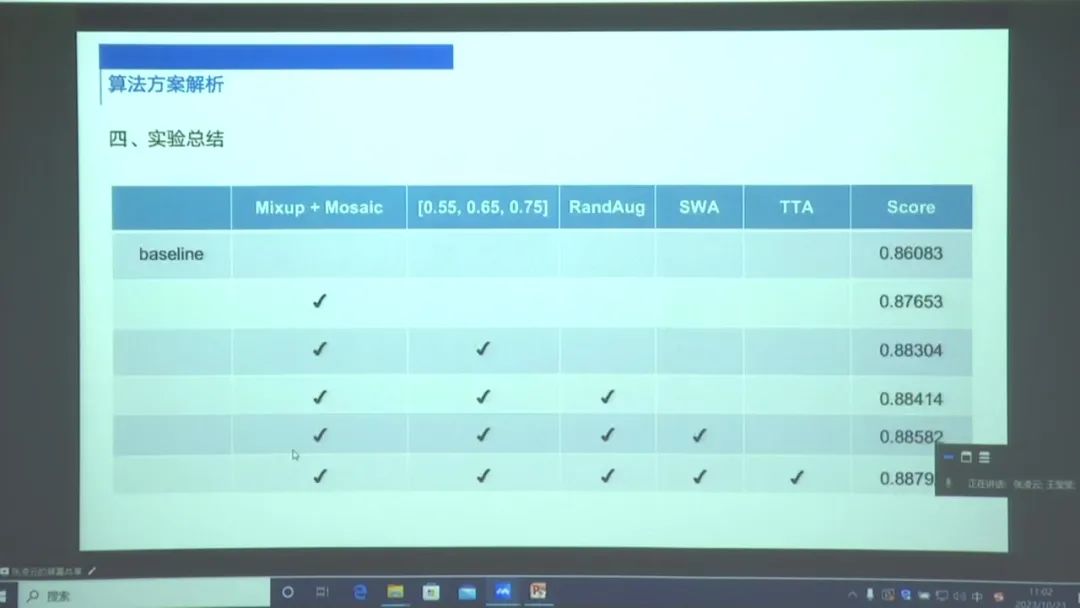
为了解决这些问题,我们采用了Swing Transformer加CP-NET v2的方案,其中Swing Transformer能提取图像多尺度特征,而CBnet V2在检测头加入了FPN操作,对小目标和图像多尺度都有增强收益。 此外,我们还对Baseline方案进行了优化,包括常规的数据增强和更强的数据增强技巧,如MESA、BaseR和Rand Augment。在训练完成后,我们还采用了SWA微调策略和增加CBNET V2检测头的预值来提高模型输出的预测精度。 在推理方面,我们使用了softNNS替换NNS方法,并采用了多尺度TTA的推理。我们的实验结果表明,数据增强是主要的收益来源。
在下一阶段的优化中,我们计划使用更大的模型,进行模型的量化和蒸馏,以及尝试更多的模型结构。总的来说,我们的比赛方案在解决赛题问题上取得了一定的成绩,并有一些优化的思路。
第三名
我们的团队目前只有我一个人,我毕业于华中科技大学,并且在20和22届的一个挑战赛中获得了冠军。我还参与了国内外的其他一些比赛。在任务分析方面,主要是由于成像情况的问题,比如光照和遮挡,导致目标检测会出现漏解和误解的情况。
当前的主要技术挑战是数据不足和误报率高的问题,需要不断优化算法提高准确率。 在数据分析方面,我们发现X光安检赛的主要问题集中在密集遮挡、目标多角度、小目标识别和正样本偏少等四个方面。我们需要不断解决这些问题,提高检测器的精度。 在训练数据集的分析中,我们发现类别不均衡的问题,九类目标中类别分布极不均衡。对于Bounding Box的分析,我们发现目标的宽高比主要集中在0.5到2之间,因此选择0.5、1和2的Anchor Rate作为通用检测器的设置是合理的。 在模型设计方面,我们选择了精度较高的Two Stage方式作为基线方案,具体选择了Cascade RCDN作为基线。 在Backbone的选择上,我们比较了Swim Transformer、Convernext和HOR-Net三种模型,最终选择了HOR-Net,因为它是一个纯卷积结构,兼容各种卷积变体,并且速度较快。 在训练技巧方面,我们采用了一些有效的增强策略,如mix up auto-augmentation、多次度训练、随机翻转、随机旋转90度、soften MS等,同时解决了类别不均衡的问题,引入了额外的数据集EDS进行预训练,以提升整个数据集的质量和精度。 此外,我们还引入了基于多模的标签蒸馏的方式来提高模型的精度。在推理阶段,我们训练了四个模型,分别是HOR-NET、Convernext、Swing Transformer和Cascade R-CN的ResNet X101,然后使用WPF进行集成,得到soft标签,最后再对HORNet进行增留,得到最终的模型权重。
在复赛阶段,我们主要借助增流的方式提升模型精度,并尝试了不同的预测策略,选择soft label作为标签,最终取得了0.887的成绩,排名第三。未来的研究方向是拓展到更多类别的目标检测和通用分割,以及多任务学习和多模态大语言模型的发展。
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

