




技术选型
01
01
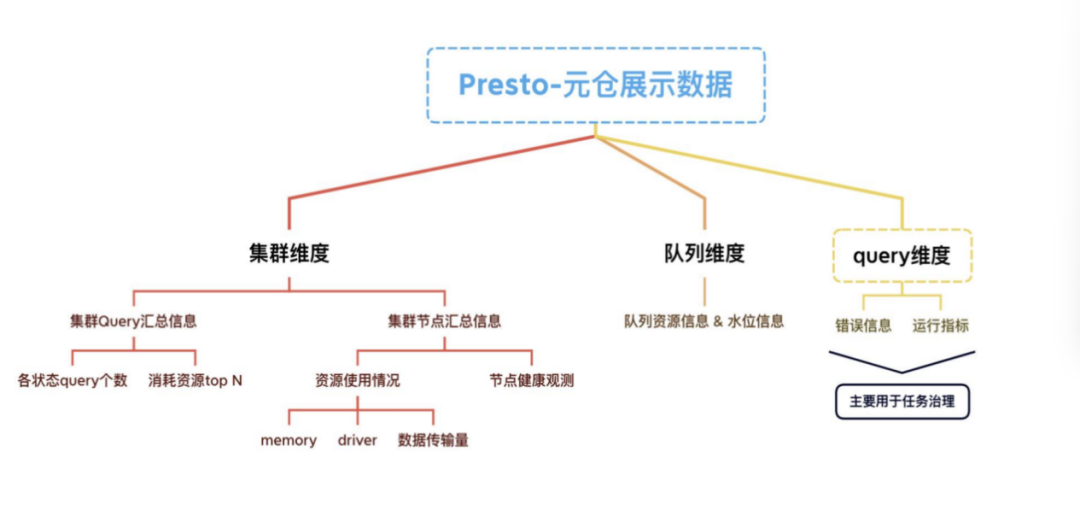
实时观测:能够实时观测到集群的指标数据,并在多维分析场景中实现秒级或亚秒级的查询返回。
复杂逻辑计算:支持复杂的逻辑计算,不需要将数据落库后打成大宽表的形式。有较高的灵活性,以便后期满足不同的需求,并在现有逻辑的基础上进行处理和分析。
存储及回放:能够存储半年甚至更久的数据,并支持数据的回放。
02
02
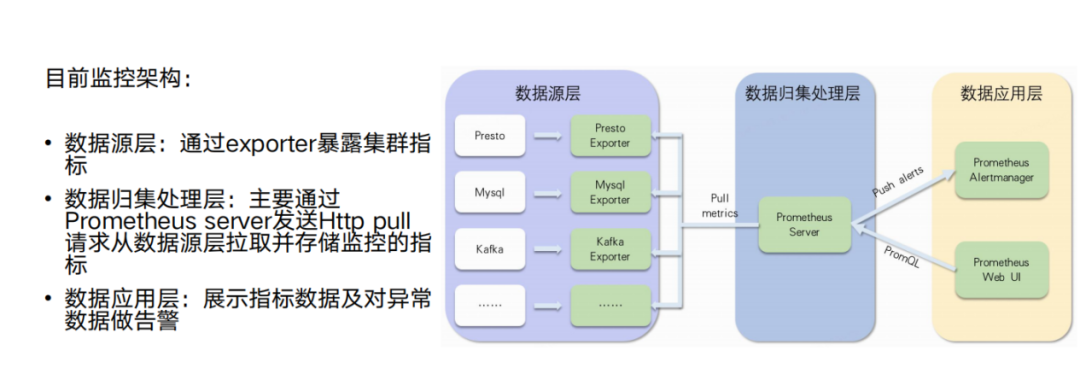
传统的数据湖技术在实时性方面普遍存在不足,Hudi、Iceberg 虽然可以达到分钟级的实时性,但要实现秒级的实时性可能仍然存在一些困难;
数据湖的远程 I/O 成本可能会较高,而数仓技术更多地采用本地 I/O,可以更有效地减少远程 I/O 的开销。
在数仓技术中,有一些成熟的加速手段,例如通过物化视图和索引等方式来提高查询性能。相对于数据湖技术,数仓技术在这方面更加成熟。
03
03
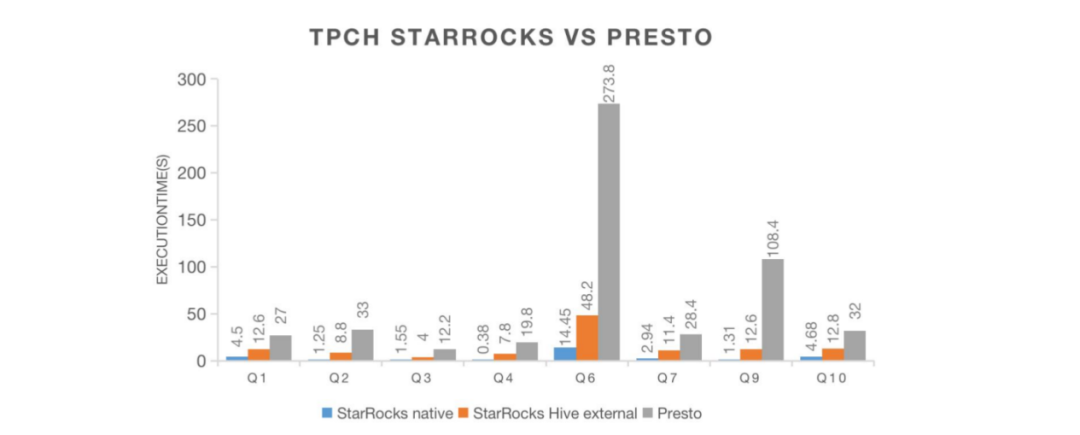
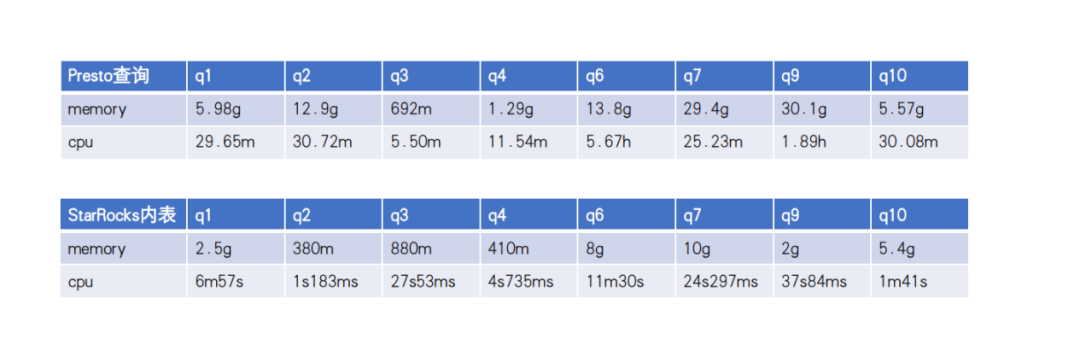
标准 SQL:StarRocks 支持标准 SQL,并兼容 MySQL 协议,这对于应用程序迁移来说是一个优点。而 ClickHouse 在标准 SQL 方面并不完全支持;
性能:StarRocks 的读写性能都较好,而 ClickHouse 在单机性能方面可能更强大;
StarRocks 可以很便利地通过多机多核的方式提高并发能力,而 ClickHouse 的并发能力相对较弱,默认的 QPS 大约为100;
JOIN 能力:StarRocks 的支持较好,可以建立星型或者雪花模型应对维度数据的变更,而 ClickHouse 的 JOIN 能力相对较弱,通常需要将数据处理成宽表进行查询;
运维:StarRocks 不依赖第三方组件,如果出现资源不足的情况,可以很容易地对 FE 和 BE 进行横向扩展。而 ClickHouse 依赖于第三方组件,如 Zookeeper 来构建集群,运维成本更高;
StarRocks 社区在国内活跃度相对较高,在我们对 StarRocks 进行调研和测试时,如果遇到问题,社区往往能够快速给出建议和回复;
04
04
05
05
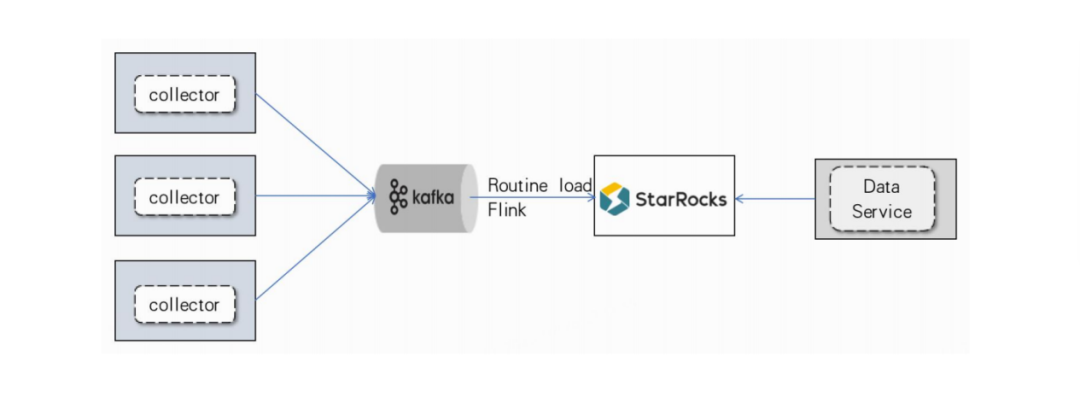
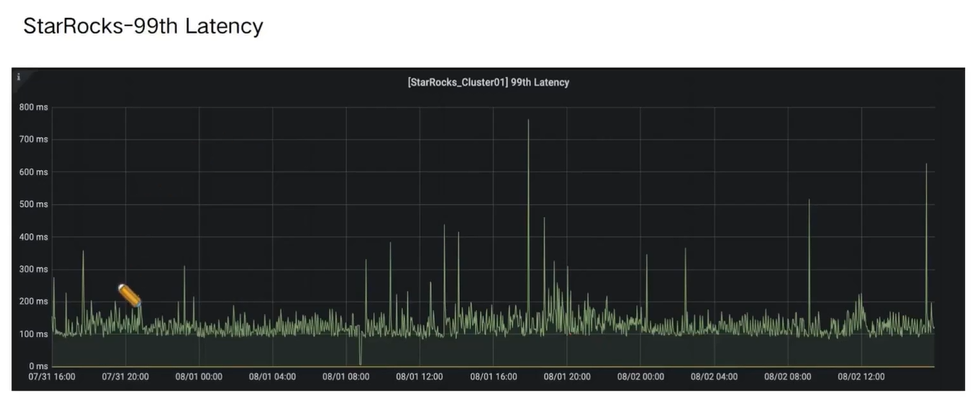
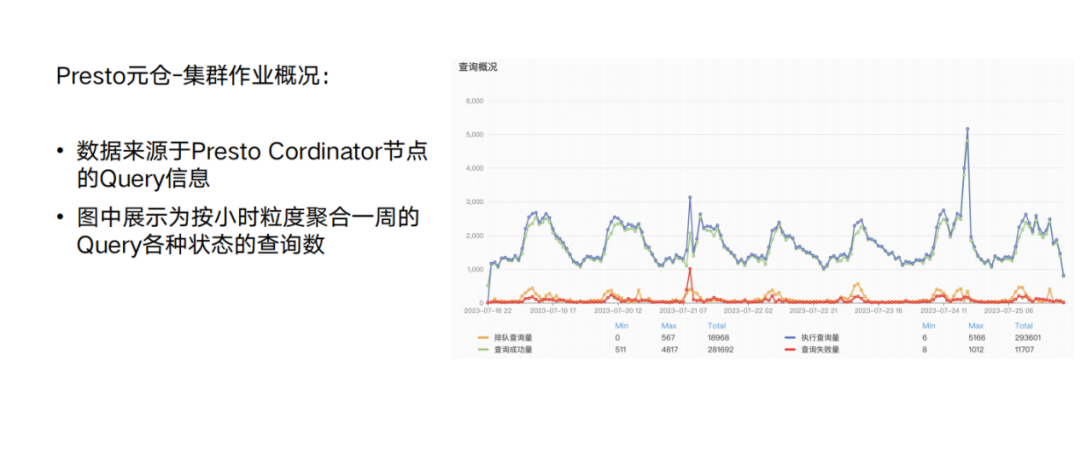
应用效果
未来规划
由于 StarRocks 在大数据元仓场景中表现非常出色,我们希望将其接入更多的业务场景,例如 BI 和 DQC 等。
解决权限、UDF 等问题,比如接入 Hive UDF,使 StarRocks 与其它引擎对齐。
目前的架构主要是以仓为中心,未来我们计划将半年或者更长时间的数据回流到数据湖中,从而实现湖仓一体化的架构。
开启 StarRocks 的一些加速功能,例如物化视图索引,以提升现有元仓查询的速度。
我们希望能够接入更多的组件,例如将 HDFS、Kyuubi 的大数据元信息纳入元仓体系中。
诊断系统方面,目前主要以 Spark 诊断为主。未来,我们希望能够支持更多类型的作业诊断,如 Presto 和 Flink 作业的智能诊断。此外,我们还希望将诊断系统与公司内部其他平台打通,为用户提供更专业的诊断建议。
关于 StarRocks


