





图源:https://www.forbes.com/sites/bernardmarr/2022/12/28/what-does-chatgpt-really-mean-for-businesses/?sh=33d1cd07d1e3
一年前,OpenAI 发布的 ChatGPT 在人工智能领域引起了轰动,并且影响逐步扩大到了更广泛的社会中。然而,由于 ChatGPT 并非开源,其访问权限由一家私人公司控制,其确切的架构、训练前数据和微调数据仍然是未知的。
ChatGPT 的封闭性会引发诸多问题,包括对其内部细节的了解缺乏可能难以准确评估其对社会潜在风险的影响,性能可能随时间变化影响可重复性研究,多次宕机可能引起访问中断,企业采用可能面临高昂 API 调用成本、服务中断、数据所有权和隐私问题,以及其他不可预测的事件。这些问题的存在为开源 LLM 提供了生机。开源 LLM 正迅速追赶,两者的差距正在逐渐缩小。如图1所示,一些最优秀的开源 LLM 在一些标准基准测试中已经超过了 GPT-3.5-turbo 的性能。
本文将总结对那些声称在各项任务上与 ChatGPT 持平或更胜一筹的开源 LLM 的评估结果,对大模型的趋势进行猜测,并且给出被社区广泛认可的最佳开源大模型实践。测评结果直接说结论,具体的内容可以到原论文中查看。希望能为未来的研究和商业应用提供参考。
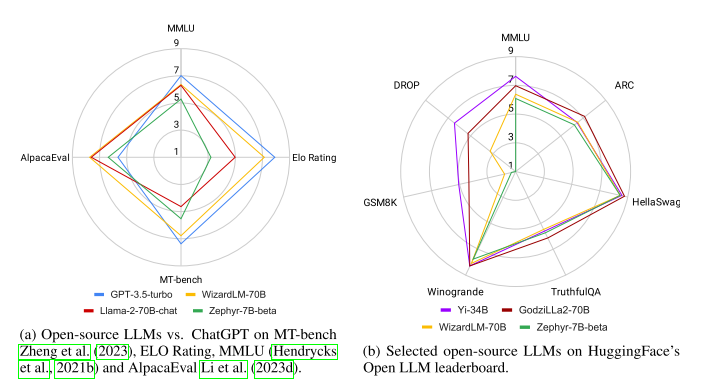
图1 不同开源llm在不同通用基准上的概述。
开源 LLM vs. ChatGPT vector search
对于一般功能,Llama-2-chat-70B 在某些基准测试中显示出优于 GPT-3.5-turbo 的改进,但在大多数其他基准测试中仍然落后。但有几个领域,开源 LLM 能够超越 GPT-3.5-turbo。
对于基于 LLM 的代理,开源 LLM 能够通过更广泛和针对特定任务的预训练和微调来超越 GPT-3.5-turbo。例如,Lemur-70B-chat 在探索环境和跟踪编码任务反馈方面表现更好。ToolLLama 可以更好地掌握工具的使用情况。Gorilla 在编写 API 调用方面优于 GPT-4。
对于逻辑推理,WizardCoder 和 WizardMath 通过增强的指令调整来提高推理能力。Lemur 和 Phi 通过对更高质量的数据进行预训练,获得了更强的能力。
对于长上下文建模,Llama-2-long 可以通过使用更长的标记和更大的上下文窗口进行预训练来改进选定的基准。
对于特定于应用程序的功能,InstructRetro 通过检索和指令调整进行预训练,改进了开放式 QA。
通过针对特定任务的微调,MentaLlama-chat-13B 在心理健康分析数据集中优于 GPT-3.5-turbo 。
对于值得信赖的人工智能,可以通过使用更高质量的数据进行微调、上下文感知解码技术、外部知识增强或多代理对话来减少幻觉。
还有一些领域,GPT-3.5-turbo 和 GPT-4 仍然是无人超越的。例如 AI 安全,由于 GPT 模型涉及大规模 RLHF,众所周知它们的表现更安全、更道德,这可能是商业 LLM 比开源 LLM 更重要的考虑因素。
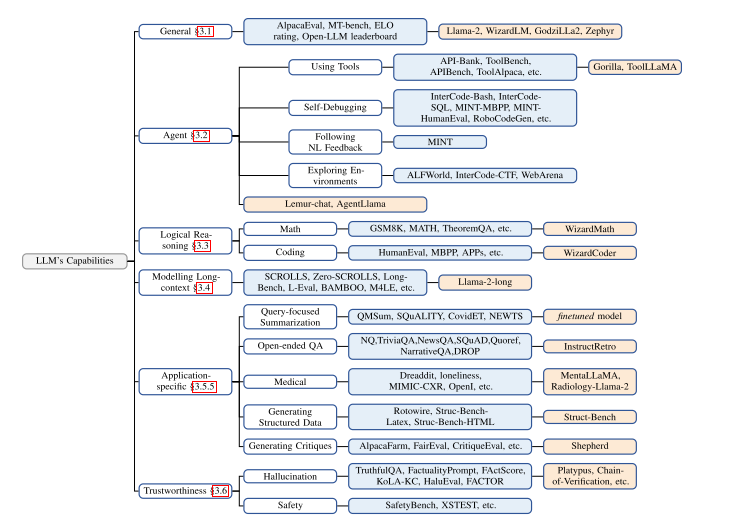
图2 LLM 的功能类型和最佳性能的开源 LLM。白框表示域,蓝框表示特定的数据集,橙色框表示开源的 LLM。
大模型何去何从 vector search
自从 Brown 等人证明冻结的 GPT-3 模型在各种任务中表现出零镜头和少镜头性能以来,推动LLM发展的努力不断增加。有两个主要研究方向:一是放大模型参数,如 Gopher、GLaM、LaMDA、MT-NLG 和 PaLM,达到了 540B 参数。尽管这些模型表现出卓越能力,但由于封闭源代码,广泛应用受限。另一个方向是研究对较小模型的预训练策略,如 Chinchilla 和 UL2。同时,对 LM 的指令调整进行了大量研究,包括 FLAN、T0 和 FLAN-t5。
一年前,OpenAI ChatGPT 的出现改变了 NLP 社区的研究重点,谷歌和 Anthropic 引入 Bard 和 Claude 来追赶 OpenAI。尽管它们在许多任务上与 ChatGPT 相当,但与最新的 OpenAI 模型 GPT-4 仍存在性能差距。由于这些模型的成功主要归功于人类反馈的强化学习(RLHF),研究人员致力于改善 RLHF。
为了推进开源 LLM 的研究,Meta 发布了 Llama 系列模型,引发了基于 Llama 的开源模型的发展。一些研究利用指令数据对 Llama 进行微调,包括 Alpaca、Vicuna、Lima 和 WizardLM。研究还探索了基于 Llama 的开源 LLM 在改进代理、逻辑推理和长上下文建模方面的能力。除了基于 Llama 的开发,还有许多团队致力于从头开始培训强大的 LLM,如 MPT、Falcon、XGen、Phi、Baichuan、Mistral、Grok 和 Yi。未来的方向包括开发更强大、高效的开源 LLM,使闭源 LLM 的功能民主化。
随着基础模型的发布,训练前语料库来源的透明度不足导致数据污染问题愈发明显。这影响对 LLM 真正泛化能力的评估。努力包括检测 LLM 的训练前语料库,研究基准数据与训练前语料库的重叠以及评估对基准的过拟合。建立标准实践、揭示训练前语料库细节并减少数据污染是未来方向。
基于人类反馈的强化学习应用于基于普遍偏好数据的对齐,但由于缺乏高质量、公开可用的偏好数据集和预先训练的奖励模型,只有有限数量的开源 LLM 使用了 RLHF 进行校准。未来的挑战包括在复杂场景中获得高质量、可伸缩的偏好数据。
在基本能力方面的突破中,人们在训练前通过改进数据混合方法来增强基础模型的平衡性和鲁棒性,但相关的勘探成本可能不切实际。超越 GPT-3.5-turbo 或 GPT-4 的模型主要基于知识蒸馏和额外的专家标注,未来可能需要探索新的方法,如无监督或自我监督的学习模式,以实现 LLM 能力的持续进步并减轻相关的挑战和成本。
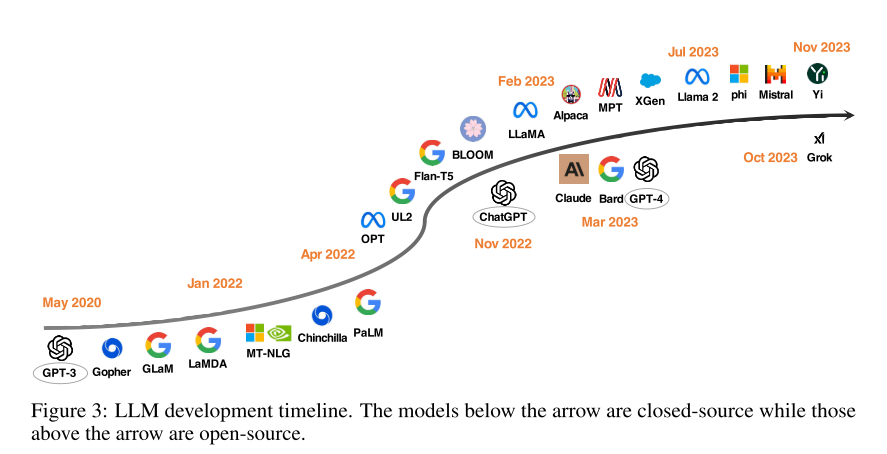
图3 LLM 开发时间轴。下方的模型是闭源的,箭头上方的模型是开源的。
最佳开源 LLM 配方 vector search
LLM 的培训涉及复杂和资源密集的实践,包括数据收集、预处理、模型设计和培训。尽管开源 LLM 的发布越来越普遍,但大多数主要模型的详细实践通常是保密的。以下是一些社区广泛认可的最佳实践:
1.数据预训练:使用数万亿数据 token 进行数据预训练,通常来自公开可访问的来源。从道德上排除包括个人信息在内的任何数据是至关重要的。微调数据虽然数量较少,但质量上乘。高质量数据的微调 LLM 在性能上表现更佳,尤其是在专门领域。
2. 模型体系结构:大多数 LLM 使用解码器转换器体系结构,但采用不同的技术来优化效率。例如,Llama-2 采用 Ghost 注意力来实现改进的多轮对话控制,而 Mistral 使用滑动窗口注意力来处理扩展的上下文长度。
3. 指令调优数据:监督微调(SFT)过程使用指令调优数据是至关重要的。数万个 SFT 注释足以获得高质量结果,数据的多样性和质量至关重要。在 RLHF 阶段,通常使用近端策略优化(PPO)算法,以更好地将模型行为与人类偏好和指令依从性结合,提高 LLM 的安全性。替代 PPO 的方法包括直接偏好优化(DPO),如 Zephyr-7B 采用的蒸馏 DPO 技术,在通用基准测试中展现出与 70B-LLMs 相当的结果,甚至在 AlpacaEval 上超过 GPT-3.5-turbo。
— 参考文献 —
https://arxiv.org/pdf/2311.16989.pdf
https://cobusgreyling.medium.com/chatgpt-is-one-year-old-are-open-source-large-language-models-catching-up-01794015682f
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

