




文|徐辉
编辑整理| 曾辉
讲师介绍

徐辉
三禾一信息科技 研发工程师
公司及产品介绍
三合一信息科技有限公司专注于工业互联网行业的大数据和人工智能领域。目前,我们公司拥有六款主要产品,包括物联网平台、数字孪生、专域数驱、大数据平台、工业算法平台以及低代码平台。
DataLink大数据平台

产品结构图
数据接入层
我们的数据接入层主要包括离线采集平台和实时采集平台。离线采集方面,我们主要基于SeaTunnel的Spark引擎,而实时采集则依赖于Flink CDC或者接通Kafka数据源,以及直接从物联网平台获取数据。
数据平台层
数据平台层包含数据加工平台(即数据开发)、实时计算平台、AI算法平台和数据资产平台。
目前,我们正在调研一款开源的数据资产平台产品。后面如果有朋友有兴趣的话, 也可以一起交流一下。
数据服务层
数据服务层由标签管理服务和数据服务组成。至于应用层,虽然在此未全部展示,但包括了报表和数据挖掘等多个方面。
平台架构
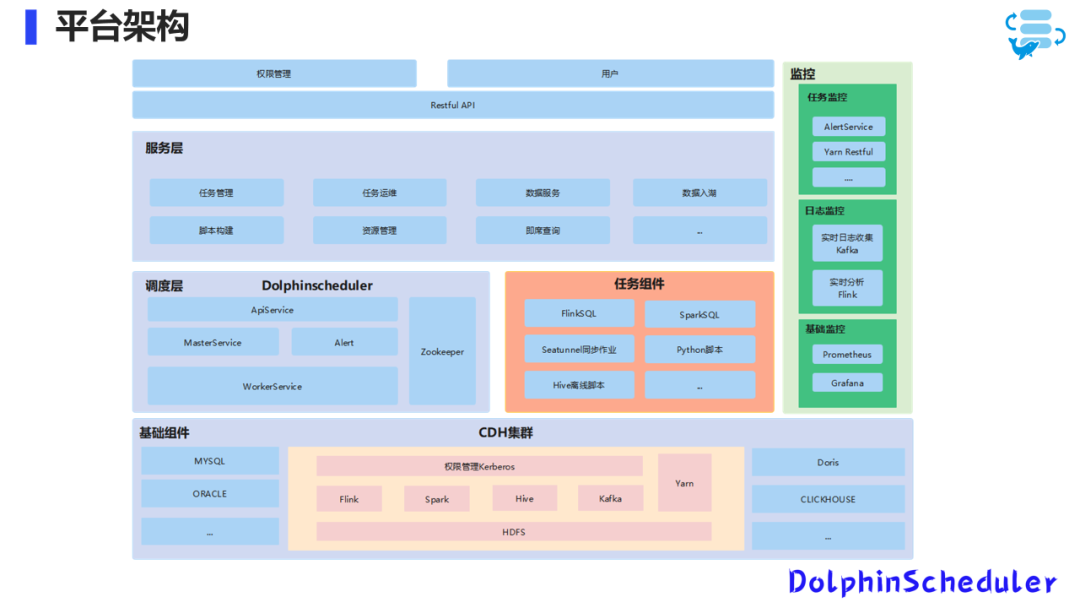
接下来,我将分为五大块介绍我们的平台架构:服务层、调度层、任务组件、基础组件及监控。
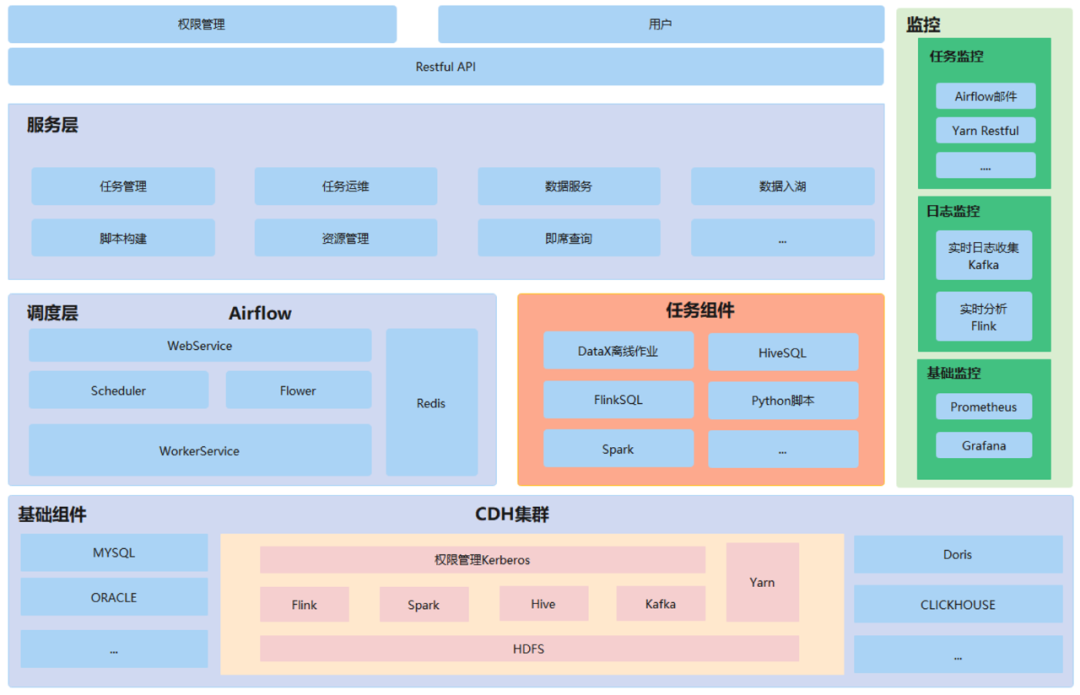
基础组件包括MySQL、Oracle、PostgreSQL等关系型数据库,以及像Doris、ClickHouse等OLAP数据库。我们的数据底座是基于CDH集群构建的,其中包含Flink、Spark、Hive、Kafka、Yarn等组件。
调度层
我们之前的架构使用的是Airflow,但由于遇到的一些痛点,我们后来替换为了Apache DolphinScheduler。任务组件方面,我们使用的是DataX离线任务来进行数据同步,以及HiveSQL、FlinkSQL、Python脚本和Spark等。
服务层
服务层主要负责任务管理、运维、脚本构建、资源管理、数据服务、数据入湖和即席查询等功能。
监控
监控分为任务监控、日志监控和基础监控。我们之前使用Airflow的邮件进行任务监控,实时任务提交到Yarn上面,现在的话主要还是通过Yarn Restful来监控实时任务的运行状况。
日志监控方面,我们实时收集数据到Kafka,并利用Flink进行实时分析。我们也有离线的日志监控方案,比如使用ELK,数据在ES上,我们可以用离线同步把ES的数据,同步到数仓, 直接再进行离线的分析。
基础监控方面,我们使用Prometheus和Grafana。
调度架构介绍
之前的调度框架主要是由K8s+Airflow+Celery+Redis+Mysql+NFS组成,整个架构的运行流程,比如说NFS是其实是做DAG的目录共享,通过就是把脚本上传NFS,然后它会共享到Airflow的每个节点上面去。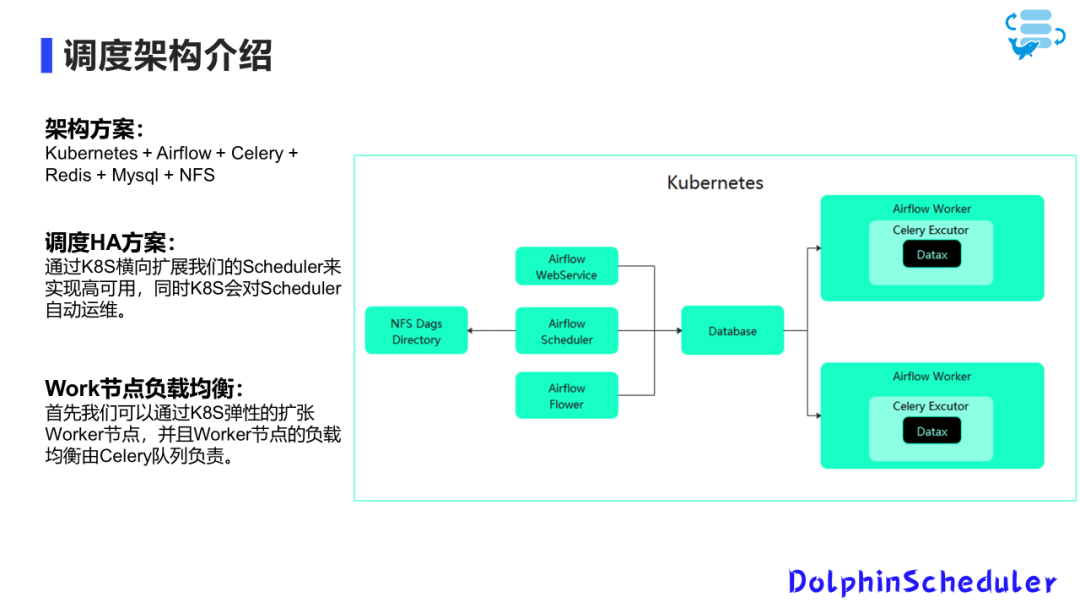
Airflow Scheduler会定时的去DAG的目录上面去扫一下,把脚本解析成任务和DAG。然后把它入到数据库里面,这个时候在前端其实就可以在页面上查询到任务。Airflow Flower主要就是Celery任务里面 work运行的状况。
调度系统的升级和选型
我们曾面临多个挑战,例如Airflow的二次开发成本较高、性能问题以及镜像过大等。


调研选型
回到合肥之后,我对DolphinScheduler进行了深入的调研。首先,要了解任何工具,必须对其架构有基本的认识。
DolphinScheduler架构
从官方获取的DolphinScheduler架构图显示,其核心特点是多Worker多Master的高可用架构。这一架构明显地体现在其Web UI界面上,通过Restful API调用APIService。
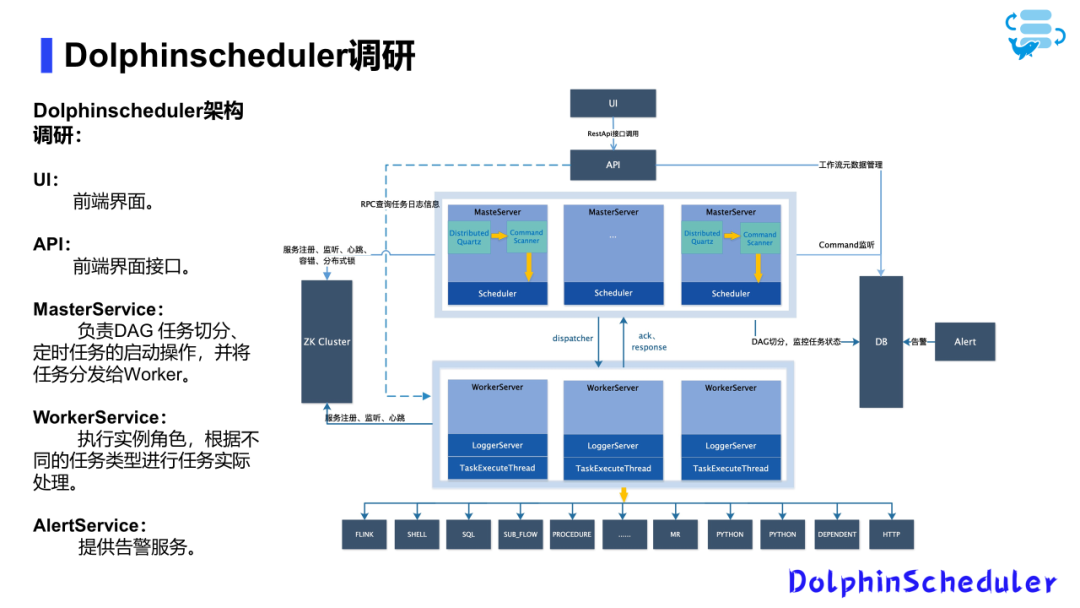
例如,工作流的创建、删除、编辑等操作都会被记录到数据库中。执行任务后,会产生任务实例和相应的日志。
APIService可以与WorkerService进行交互,后者包含LoggerService。
Master主要负责任务的DAG切分及定时任务的启动,并将任务下发给Worker执行。
Worker执行任务(如Flink、SQL、Shell等)后,将结果反馈给Master。如果任务出错,AlertService会触发相应的告警。整个集群通过Zookeeper实现高可用。
功能调研
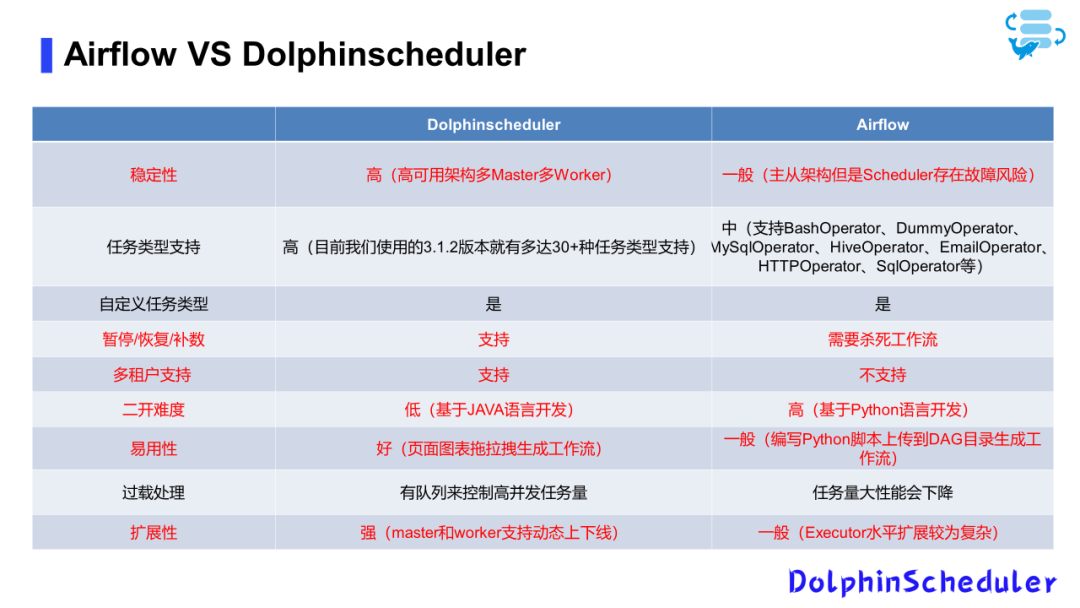
架构的优越性并非唯一考量点,功能同样重要。DolphinScheduler支持DAG,提供丰富的任务类型支持(目前约30种),并支持自定义参数,非常适用于离线场景的增量处理或数据补录。
开发方式简单,基于界面拖拉拽即可生成工作流,无需编写代码。此外,它还支持多租户功能和告警模块,与国内流行的企业通讯平台(如企业微信、钉钉、飞书)集成良好,实现告警功能。
决定更换调度框架
综合考虑后,我们决定更换调度框架,选择了Apache DolphinScheduler。其多Worker多Master的高可用架构,简易的开发方式,多租户支持等特性是我们采用它的主要原因。
任务类型与自定义功能
DolphinScheduler支持30多种任务类型,并且支持自定义任务类型。对于正在执行的工作流,需要先终止当前任务才能执行补数操作。支持多租户功能,这对于我们主要使用Java的团队而言是一个重要的考量点。如果需要基于Python进行开发,可能会增加一些复杂性。
应用性与扩展性
在应用性方面,DolphinScheduler提供了代码编写和界面拖拉拽两种方式。在扩展性方面,由于基于Zookeeper注册,对集群的扩展变得相对简单,只需配置相应的工作节点并在Zookeeper中注册即可。
总的来说,Apache DolphinScheduler以其强大的功能和灵活的架构,为我们构建数据平台提供了坚实的基础。
基于Apache DolphinScheduler构建数据平台
我们对DolphinScheduler的源码进行了深入的研究和理解,并自主开发前端,集成了多种插件。

平台工作流程
我们的平台主要基于DS(DolphinScheduler)构建,主要包括离线数据集成和离线数据开发。平台的工作流程如下:
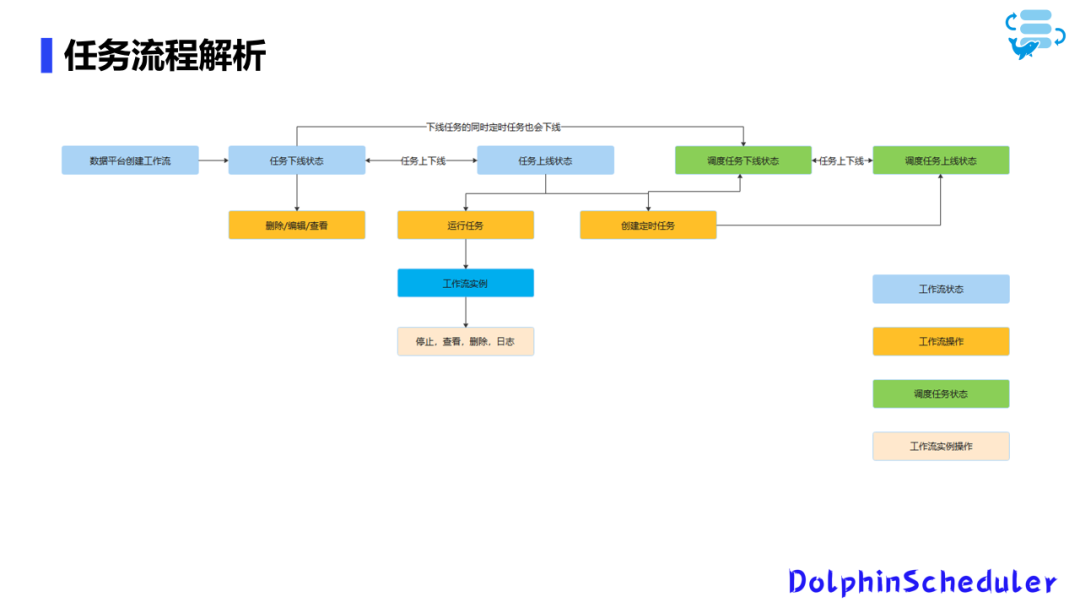
任务创建与管理:在平台页面上操作,发起创建请求。创建的任务默认为下线状态,可进行编辑、删除和查看等操作。 任务上线与运行:任务上线后,可以运行或创建定时任务。运行任务将产生工作流实例,允许进行停止、查看、删除日志等操作。 定时任务管理:创建的定时任务可以直接上线。在定时任务状态下,任务可自由上下线。需要注意的是,任务从上线状态改为下线时,相应的调度任务也会随之下线。
插件集成与应用
插件使用:初始版本使用的是DS 3.0 Alpha版,该版本不稳定,主要是因为ST插件的集成。但经过bug修复,我们成功用它替换了DataX。目前,我们在DS插件集成方面积累了丰富的经验,欢迎有相关需求的公司与我们交流。 数据集成与开发:数据集成任务本质上是单节点的DS任务,可以进行各种调度操作。数据开发则涉及拖动数据集成任务,并与其他组件相连,最终生成工作流。工作流任务根据项目需求分配到不同的project中。
用户体验优化
任务创建流程简化:为提升用户友好度,我们优化了任务创建流程。用户可以在页面上直接选择数据源(支持多种数据源),选择源端和目标端,勾选所需字段。平台底层基于Spark实现离线集成,支持自动建表等功能。 技术支持:平台支持多表同步和整库同步。除了基础的数据集成任务外,我们还在页面上引入了扩展转换组件,比如过滤器等,来构建更复杂的数据开发任务。这些功能已由社区支持,并部分开源。
以上为我们基于DS构建的数据集成和开发平台的主要特点和流程,旨在提供高效、灵活的数据处理能力。
平台现状和未来规划
当前状况
目前,我们的平台已经支持了包括实时离线OLAP数据源、服务数据、数据资产等多种场景。
我们正积极探索数据标准化和指标平台的建设。对于这些领域,我们欢迎有相关经验的朋友与我们交流和共同探讨。
技术应用
离线处理:目前,我们主要使用SeaTunnel来替代DATAX,主要作业类型包括Spark、Python、Shell、ST等。 实时处理:在实时数据处理方面,我们主要以Flink为核心。应用场景包括实时数据同步和风控报警,特别是在工业环境中对设备如温度、湿度等实时监控至关重要。
未来规划
数据挖掘平台:我们计划开发数据挖掘平台,目前有两个初步想法: 基于DolphinScheduler,封装Spark节点,将Spark算法集成进平台。用户通过拖拽界面操作实现数据挖掘任务。 使用SeaTunnel,其底层也基于Spark。我们计划将机器学习算法作为转换组件集成,用户可以通过页面上的拖拽表单构建工作流来实现数据挖掘功能。 实时风控平台:考虑到实时风控场景的普遍性,我们打算基于Flink CEP构建一个实时风控平台。由于Flink SQL的开发门槛较高,我们计划提供一个更为友好的用户界面,让客户能够通过表单和拖拽方式轻松生成任务。
我们期待未来平台的发展能够更好地服务于客户,同时欢迎业界朋友加入我们的探索和创新之旅。非常感谢大家的聆听,希望我的分享能给大家带来启发和帮助。如果大家对我们的平台或者相关技术有兴趣,欢迎与我们联系交流。

