




关键字:
KingbaseES、插件、分析工具、plsql_plprofiler、人大金仓、KingbaseES
在开发和维护大型数据库应用程序时,性能优化是至关重要的一环。KingbaseES数据库作为一个强大的关系型数据库管理系统,提供了许多工具来帮助开发人员优化其代码和查询。其中plsql_plprofiler是一个特别有用的分析工具,它可以帮助开发人员分析和优化PLSQL代码的性能。本文将介绍分析工具plsql_plprofiler的功能、用法和简单使用案例,以帮助相关开发人员来利用该工具提升数据库应用的执行效率。
什么是plsql_plprofiler?
plsql_plprofiler是KingbaseES 的一个扩展插件,作为一个性能分析工具,它专门用于分析PLSQL代码的执行性能。它可以找出代码中的性能瓶颈,发现执行时间较长的代码部分,以帮助开发人员分析性能相关的问题,进而优化PLSQL代码,提升性能。
plsql_plprofiler的功能
plsql_plprofiler支持对所有PLSQL对象的分析,具体包括函数分析、存储过程分析、包分析、触发器分析、嵌套函数分析、匿名块分析和object type分析等。在分析过程中,它可以为这些PLSQL对象生成分析信息,此信息包括对象的oid、调用堆栈、调用次数,还有语句所在行、每行代码的执行次数、该行代码在多次执行中消耗的最长时间以及执行该行代码所花费的总时间等。
plsql_plprofiler中的数据共享方式分为本地和全局两种。其中,本地模式的监控数据不共享,仅当前会话可见;全局模式的监控数据是共享的,所有会话都可见。此处的本地是指用户只分析自己所写的代码,全局是指可以分析整个数据库上连接的所有用户的代码。
plsql_plprofiler的用法
用户如果想在KingbaseES数据库中使用插件plsql_plprofiler来分析本地的PLSQL对象,一般需要以下几个步骤:
- plsql_plprofiler的加载:在使用该插件前,需要先在数据库中加载该插件。KingbaseES数据库默认将它添加到了 kingbase.conf 文件的 shared_preload_libraries 中,重启数据库时会自动加载该插件。因此用户只需要在客户端工具输入以下命令来创建plsql_plprofiler插件即可。
/*创建plsql_plprofiler插件*/
create extension plsql_plprofiler;
- 清理之前的分析数据:首先调用pl_profiler_reset_local 函数来清理之前本地存储的所有分析信息,为创建本次的分析信息做准备。
/*清理本地数据*/
select pl_profiler_reset_local();
- 启动分析器:调用pl_profiler_set_enabled_local函数来启动plsql_plprofiler的本地分析器。
/*启动本地分析器*/
select pl_profiler_set_enabled_local(true);
- 运行待分析的PLSQL程序:分析器启动以后,用户可以在数据库中运行需要分析性能的PLSQL代码,比如调用一个函数或者存储过程等。
- 关闭分析器:代码运行完毕后,同样调用pl_profiler_set_enabled_local函数来关闭plsql_plprofiler的本地分析器。该函数通过设置参数来选择分析器的开启或关闭。
/*关闭分析器*/
select pl_profiler_set_enabled_local(false);
- 分析数据:关闭分析器以后,用户可以调用plsql_plprofiler提供的相关函数来进行具体的数据分析工作。例如调用pl_profiler_linestats_local 函数来查看本地对象的执行信息,调用pl_profiler_callgraph_local 函数来查看执行时的调用堆栈关系等。
/*查看本地对象的执行信息(可选步骤)*/
select * from pl_profiler_linestats_local();
/*查看执行时的调用堆栈关系(可选步骤)*/
select * from pl_profiler_callgraph_local();
plsql_plprofiler的使用案例
下面通过一个简单的案例来展示plsql_plprofiler的功能和用法。
假设我们有两张表employees和performance用来分别存储员工的基本工资和奖金,
还有一个存储过程cal_salary来通过员工的id计算该员工的总薪酬,该存储过程的代码如下所示:
\set SQLTERM /
CREATE OR REPLACE PROCEDURE cal_salary(employee_id NUMBER) AS
DECLARE
v_basic_salary NUMBER;
v_bonus NUMBER;
v_total_salary NUMBER;
BEGIN
/*从employees表中获取基本工资*/
SELECT basic_salary INTO v_basic_salary FROM employees WHERE id=employee_id;
/*从performance表中获取奖金*/
SELECT bonus INTO v_bonus FROM performance WHERE id=employee_id;
/*计算总薪资*/
v_total_salary := v_basic_salary+v_bonus;
/*将总薪资更新到employees表中*/
UPDATE employees SET total_salary = v_total_salary WHERE id = employee_id;
END;
/
\set SQLTERM ;
现在,我们使用plsql_plprofiler工具来分析该存储过程的执行信息。
(1)创建plsql_plprofiler
create extension plsql_plprofiler;
(2)清理本地数据
select pl_profiler_reset_local();
(3)启动本地分析器
select pl_profiler_set_enabled_local(true);
(4)调用存储过程,计算id为7的员工的总薪酬
call cal_salary(7);
(5)关闭本地分析器
select pl_profiler_set_enabled_local(false);
(6)调用pl_profiler_funcs_source函数来查看该存储过程的源码
select * from pl_profiler_funcs_source(pl_profiler_func_oids_local());
其中,函数pl_profiler_func_oids_local返回本地已执行plsql对象的OID数组,用来为函数pl_profiler_funcs_source传递参数。执行该语句之后,可以看到已执行对象的源码信息如下:
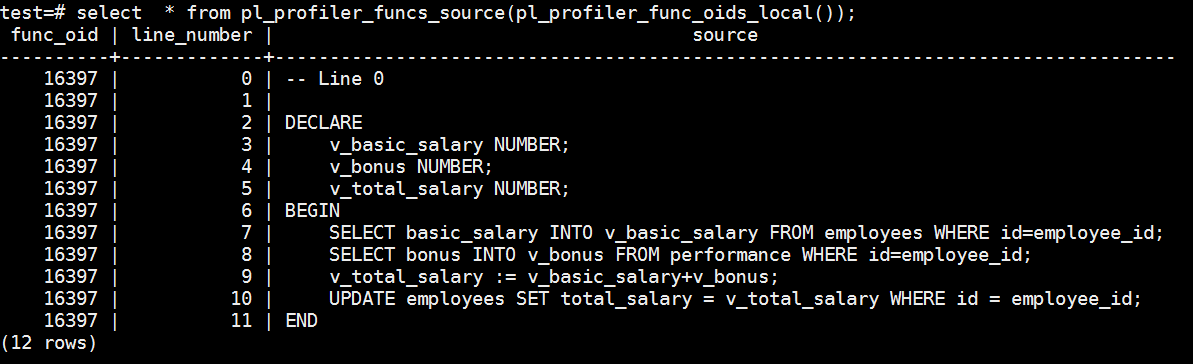
- 调用pl_profiler_linestats_local 函数来查看存储过程的执行信息
select * from pl_profiler_linestats_local();
执行该语句后,我们可以看到执行信息如下:
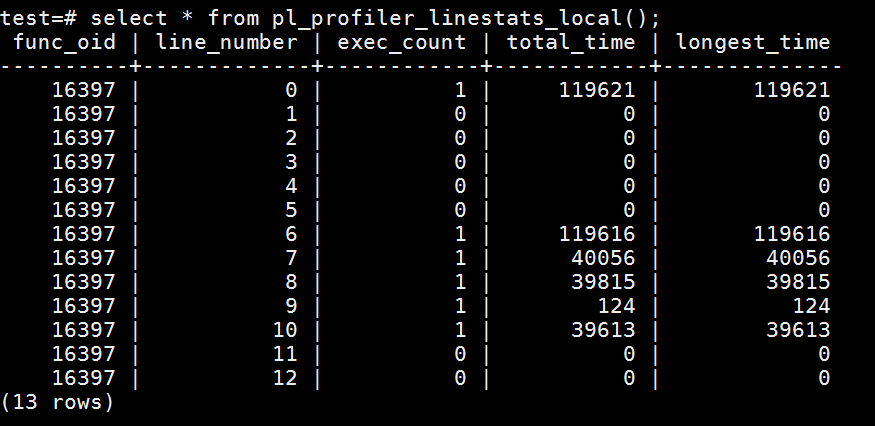
从该表中可以看出,该存储过程执行最耗时的是第7、8行和第10行,分别对应存储过程中的两个SELECT语句和UPDATE语句。需要说明的是,这里的第6行对应的是BEGIN,它是指整个BEGIN...END块的总执行时间。
为了更加清晰地看到每行代码的执行时间,我们可以将函数pl_profiler_funcs_source和pl_profiler_linestats_local联合起来使用,例如:
SELECT L.func_oid::regproc as funcname,
L.func_oid as func_oid,
L.line_number,
sum(L.exec_count)::bigint AS exec_count,
sum(L.total_time)::bigint AS total_time,
max(L.longest_time)::bigint AS longest_time,
S.source
FROM pl_profiler_linestats_local() L
JOIN pl_profiler_funcs_source(pl_profiler_func_oids_local) S
ON S.func_oid = L.func_oid AND S.line_number = L.line_number
GROUP BY L.func_oid, L.line_number, S.source
ORDER BY L.func_oid, L.line_number;
经过上面的查询语句后,可以看到清晰的执行信息如下:

通过这些执行信息,我们可以确定SELECT语句和UPDATE语句是该存储过程的性能瓶颈。为了优化性能,我们可以尝试使用连接来代替单独的查询,从而减少数据库的查询次数。优化后的存储过程改写如下:
\set SQLTERM /
CREATE OR REPLACE PROCEDURE cal_salary(employee_id NUMBER) AS
DECLARE
v_total_salary NUMBER;
BEGIN
/*使用连接JOIN来代替单独的查询,以减少数据库的查询次数*/
SELECT e.basic_salary + p.bonus INTO v_total_salary
FROM employees e JOIN performance p ON e.id = p.id
WHERE e.id=employee_id;
UPDATE employees SET total_salary = v_total_salary WHERE id = employee_id;
END;
/
改写存储过程以后,采用跟上面类似的步骤去重新分析该存储过程的执行过程,可以得到如下的执行信息:

从上表中可以看出,经过优化后,该存储过程的执行速度得到了显著的提升。
注:本文只是介绍了KingbaseES的分析工具plsql_plprofiler的最简单用法,关于更详细的使用方法可以参考KingbaseES的官方手册。
