





一、SQL 查询优化器
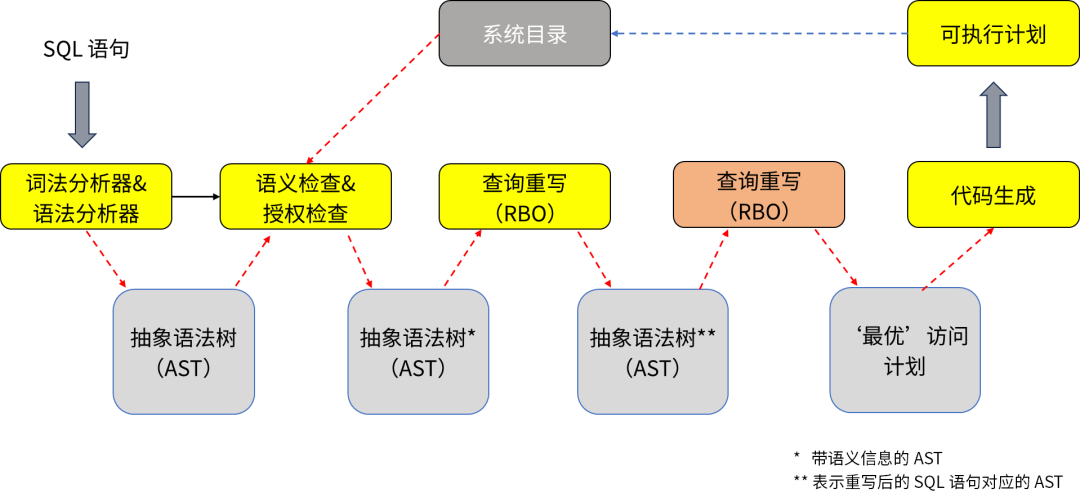
基于规则的优化算法: 基于规则的优化方法的要点在于结构匹配和替换。 应用规则的算法一般需要先在关系代数结构上匹配一部分局部的结构,再根据结构的特点进行变换乃至替换操作。
基于成本的优化算法: 现阶段主流的方法都是基于成本(Cost)估算的方法。给定某一关系代数代表的执行方案, 对这一方案的执行成本进行估算,最终选择估算成本最低的方案。尽管被称为基于成本的方法,这类算法仍然往往要结合规则进行方案的探索。基于成本的方法其实是通过不断的应用规则进行变换得到新的执行方案, 然后对比方案的成本优劣进行最终选择。
二、查询优化的基本原理
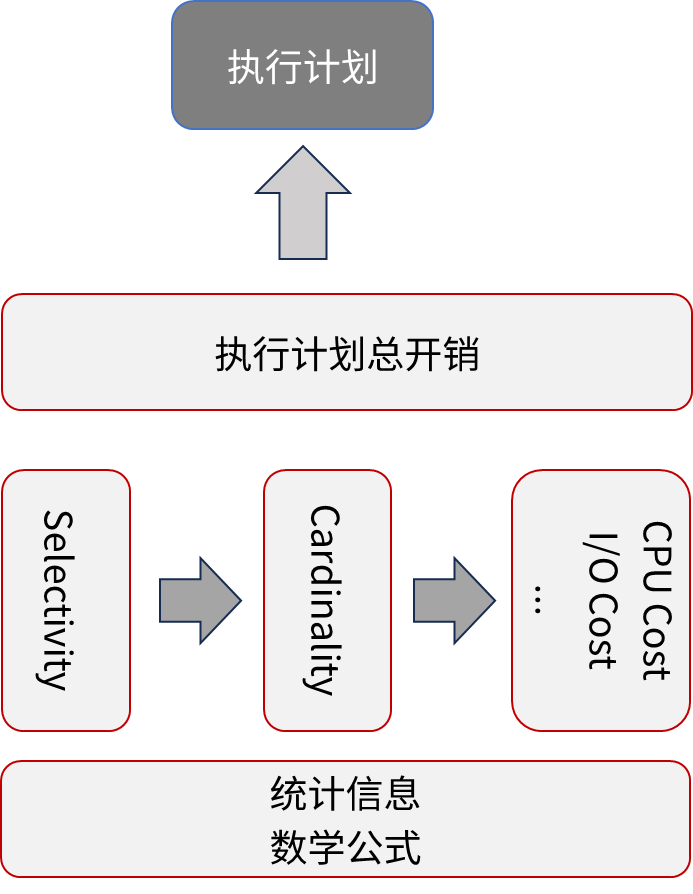
SQL 查询可以转化为关系代数; 关系代数可以进行局部的等价变换,变换前后返回的结果不变但是执行成本不同; 通过寻找执行成本最低的关系代数表示,我们就可以将一个 SQL 查询优化成更为高效的方案。
自底向上搜索:从叶子节点开始计算最低成本,并利用已经计算好的子树成本计算出母树的成本,就可以得到最优方案; 自顶向下搜索:先从关系算子树的顶层开始,以深度优先的方式来向下遍历,遍历过程中进行剪枝。
三、Cascades 查询优化器
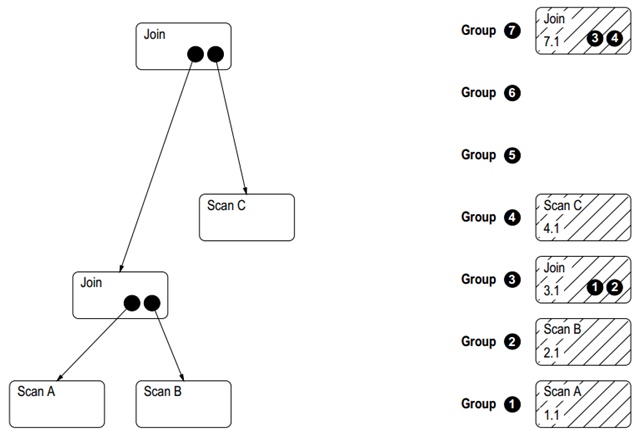
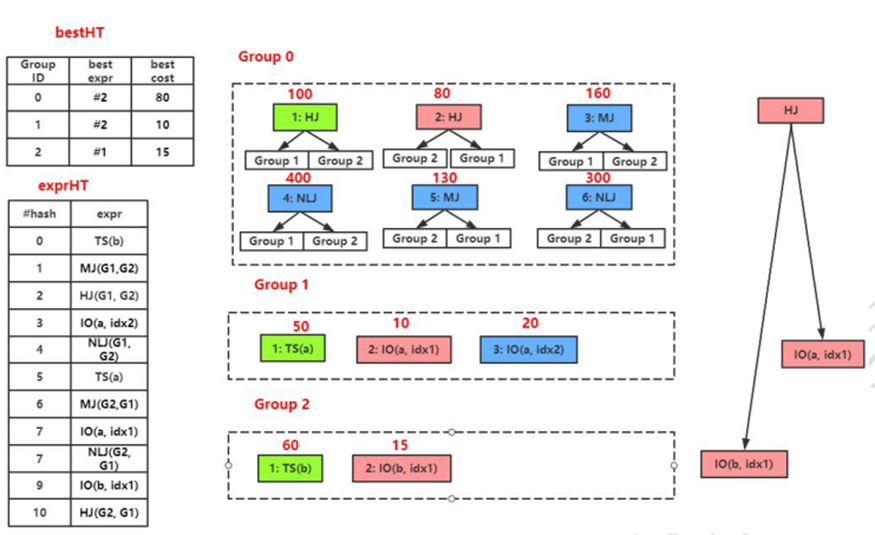
Expression:Expression 表示一个逻辑算子或物理算子。如 Scan、Join 算子; Group:表示等价 Expression 的集合,即同一个 Group 中的 Expression 在逻辑上等价。Expression 的每个子节点都是以一个 Group 表示的。一个逻辑算子可能对应多个物理算子,例如一个逻辑算子 Join(a,b),它对应的物理算子包括{HJ(a, b), HJ(b, a), MJ(a, b), MJ(b, a), NLJ(a, b), NLJ(b, a)}。我们将这些逻辑上等价的物理算子称为一个 Group(组)。注:HJ 表示 HashJoin 算子,MJ 表示 MergeJoin 算子,NLJ 表示 NestLoopJoin 算子; Memo:由于 Cascades 框架采用自顶向下的方式进行枚举,因此,枚举过程中可能产生大量的重复计划。为了防止出现重复枚举,Cascades 框架采用 Memo 数据结构。Memo 采用一个类似树状(实际是一个图状)的数据结构,它的每个节点对应一个组,每个组的成员通过链表组织起来; Transformation Rule:是作用于 Expression 和 Group 上的等价变化规则,用来扩大优化器搜索空间。
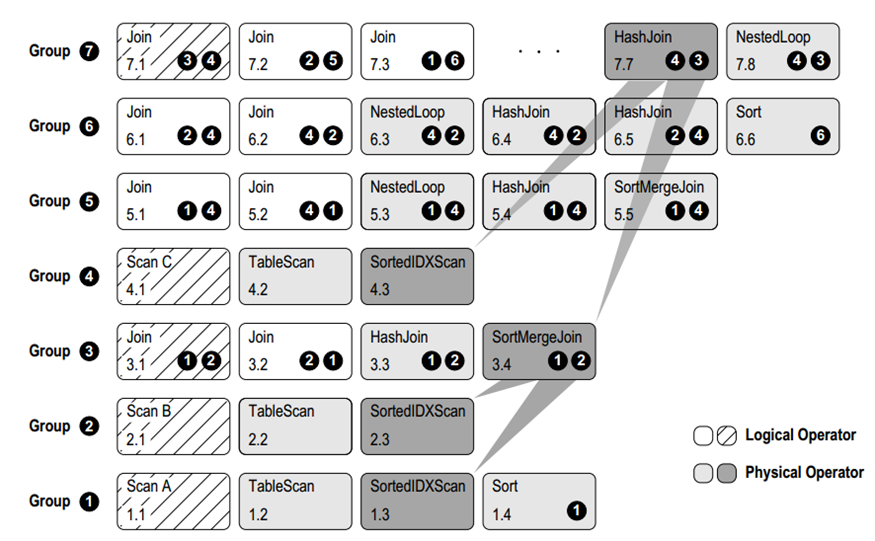
对于一个逻辑算子,其所有基于关系代数的等价表达式保存在同一个 Group 内,例如 join(A,B) -> join(B,A); 在一个 Group 内,对于一个逻辑算子,会生成一个或多个物理算子,例如 join -> hash join,merge join,NestLoop join; 一个 Group 内,一个算子,其输入(也可以理解为subplan)可以来自多个 Group 的表达式。
END
往期推荐

文章转载自KaiwuDB,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
