数据3.0时代,通过大模型+数据,使得企业/开发者用更少的代码,或通过自然语言构建应用与交付业务的趋势已成必然。通过大语言模型的对话能力,直接挖掘、释放数据的价值,可以极大的降低数据使用者的门槛,爆发出更多的可能。
11 月《大模型时代下的数据新视界》创见工坊,邀请产、学、研的领域专家围绕大模型和数据衍生出的几大探索方向:向量数据库、LLM+Data、LLM+SQL、LLM+Tools 分享各自的技术探索和实践经验,共同探讨关键问题和发展趋势。接下来的几期内容将以文字版的形式分享给 DB-GPT 社区的同学,共同学习和探讨。


首先需要认识一下大模型,尤其是要从数据库的视角、数据管理视角去思考一下,大模型到底本质是什么?

要从战略上重视大模型,尤其是对于数据管理领域来讲。能不能利用大模型终结咱们数据库?大家可能很多人觉得这个有点太夸张,但实际上我觉得数据管理相对还是比较封闭的一个领域,大概率是可以借助通用大模型的很多能力,来完成数据管理历史的使命。
大模型,尤其是生成式预训练语言模型已成为通用人工智能技术发展的重要里程碑,引发了新一轮产业变革。生成式预训练语言模型也逐渐在向多模态、具身等其技术相融合,促使大模型不仅可以模拟人类大脑思维能力,还具备操控各种工具的能力,这些技术的共同发展促进了通用人工智能技术的进步。同时,通用人工智能技术为人类进一步发展提供了很多机遇,同时也带来了众多挑战。
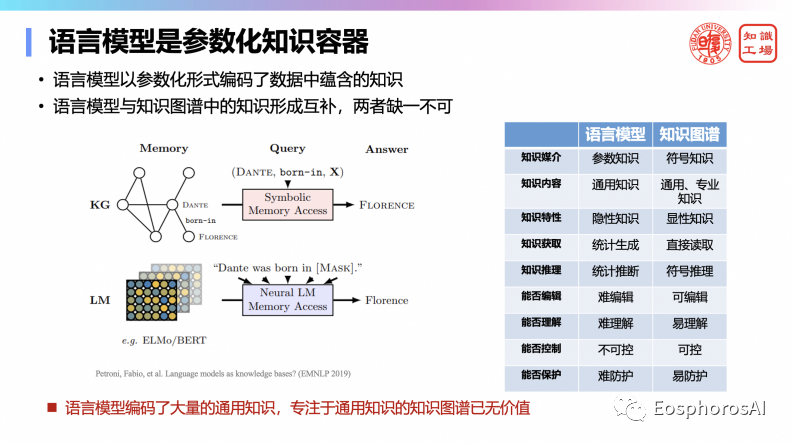
那么大模型意味着什么?它是一个参数化的知识容器,它里面提供了很多知识,它学到了很多知识。语言模型需要一些特殊的手段去提取其中的知识,即通过提供合理的提问获得知识。此外,语言模型和传统的知识容器(如数据库、规则库、知识库)在表达形式、知识内容、知识特性、知识获取、能否编辑、能否理解、能否控制、能否保护等方面都存在本质上的区别。那么这里就要不可避免的去提一下它跟知识图谱之间的关系,其实一直认为两者缺一不可。知识图谱存的是符号知识,易于理解,如三元组,可以是通用知识也可以是专业知识,且可以直接增删改,因此是可控的;而大模型存的是参数知识,道不清说不明,且是提炼之后的跨学科通用知识,无法直接编辑。此外,知识图谱通过符号进行推理,而大模型本质上是一个统计生成模型,根据条件概率进行推断。
虽然大模型编码了大量的通用知识,使得专注于通用知识的知识图谱已无价值,但并不意味着知识图谱没有价值,一些私域、需保护、需控制编辑的知识仍需交给知识图谱。因此在实际应用场景中,大语言模型与知识图谱中的知识需要形成互补,两者缺一不可。

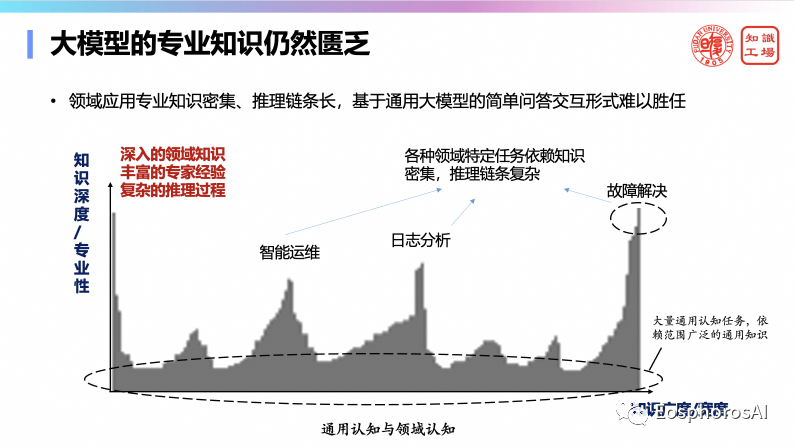
大语言模型的预训练机制决定了大语言模型学到的是跨学科知识,因此我们团队推出了一套针对语言模型领域知识评估的基准:Xiezhi-benchmark,该评测涉及12个学科门类,514个具体学科,2.5M道测试题。实验显示,与45个开源模型、2个非开源模型相比较,大模型的跨学科能力明显强于小模型。但相较于各个领域的顶尖人类而言,依然有较大差距。每个领域的专业人士平均水平可达0.78,而像GPT-4只可以做到0.4左右的水平。所以大模型更像一个通才,虽然学到了很多学科的知识,但专业度不够,垂直领域的专业知识还很匮乏。这是因为领域专业知识密集、推理链条长,基于通用大模型的简单问答交互形式难以胜任这类任务。这个是后面真正去用大模型来解决数据库的问题时候,一定要去解决的问题。
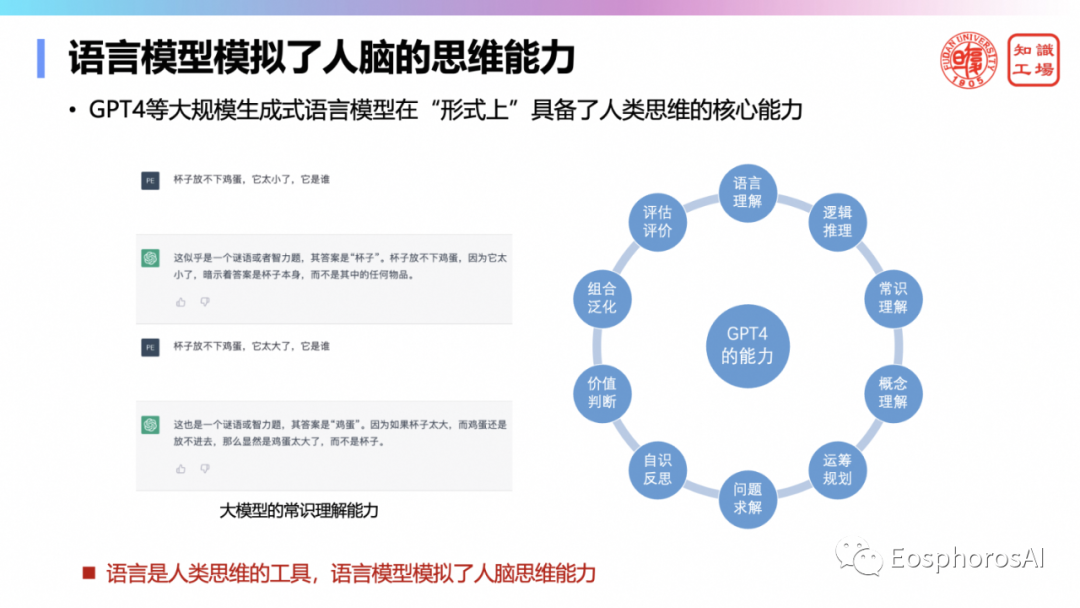
语言除了传递知识外,还是人类思维的工具,所以用语言预训练的大模型可以模拟人脑的思维能力,其在“形式上”已经具备了语言理解、逻辑推理、常识理解、概念理解、运筹规划、评估评测、组合泛化、价值判断、自识反思、问题求解等一系列人类思维的核心能力。比如你教会大模型某种药成年人服用剂量,然后你问23岁服用剂量多少?它就知道你23岁一定是成年人,就可以把这个剂量推荐给你。这都是基于大模型的通识能力。在利用大模型去解决数据管理里面的很多问题的时候,能够优先解决的一定是需要通识能力的那些场景。我会让同学们在利用大模型去做数据治理,我就跟同学讲,肯定是优先解决这些。如果数据库里面的内容是一些常识性的、通识性的,比如说百科知识,那么利用大模型来做它的数据治理,肯定问题不大。或者比如说你是个工商数据,发现工商数据很多小卖部的什么注册资本是一点几个亿,这肯定有问题,哪个小卖部商户个体户能一点几个亿的注册资本,这肯定是什么录入数据的时候小数点点错了。那你能不能利用大模型这种能力来做这种自动纠错呢?像以往做这种数据治理都是很困难,一定要写规则,可是规则你很难涵盖的全。但凡像这种场景能够利用上大模型的常识能力的,其实恰恰就是解决问题的机会所在。对于这种场景,是可以利用大模型的这种能力来解决。
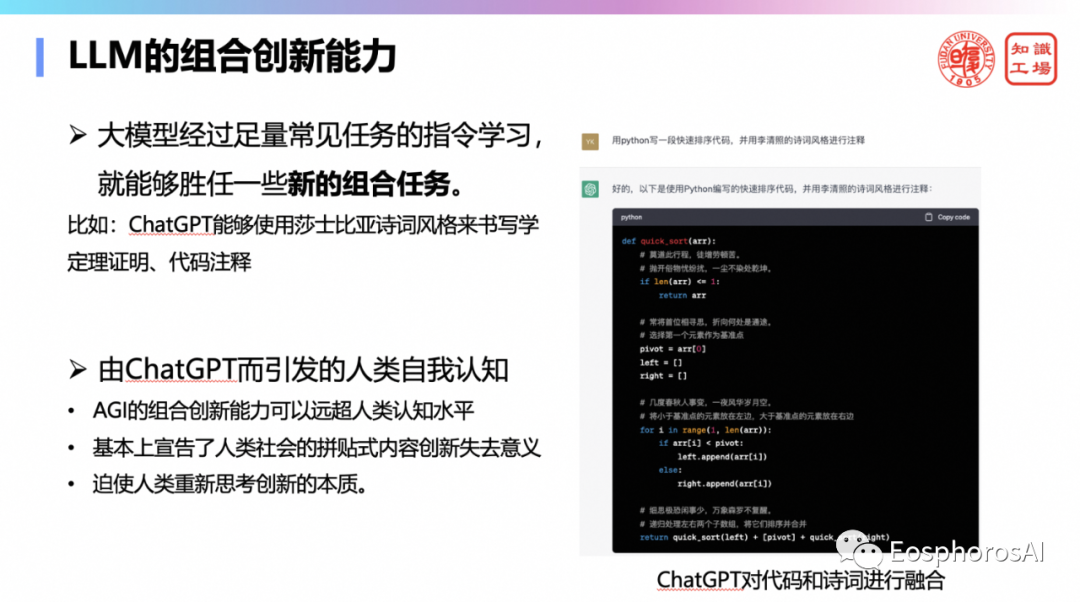
在这些能力中两个非常重要的能力分别为组合创新能力和评估评估能力,这也是大模型挑战人类智慧的两个突破口。
第一个重要能力:大模型的组合创新能力,即在经过足量常见任务的指令学习后,能够胜任一些新的组合任务。大模型的这个组合创新能力也是需要特别重要的。它在有了解决A任务的能力,有了解决B任务的能力,它往往会泛化出解决A加B任务的能力。所以它已经有了一定的组合泛化能力,这一点也是大家要去重视的。

第二个重要能力,评估评价能力。大家知道有很多小模型,传统的小模型往往要标注数据,标注数据往往是人来标。那么可不可以利用大模型的这种能力来做这种数据自动标注、评估?这个设计上大家已经看到有很多研究工作,相关实验证明 GPT-4 等模型在语义相关任务上已经具有了比人类更出色的评估能力。
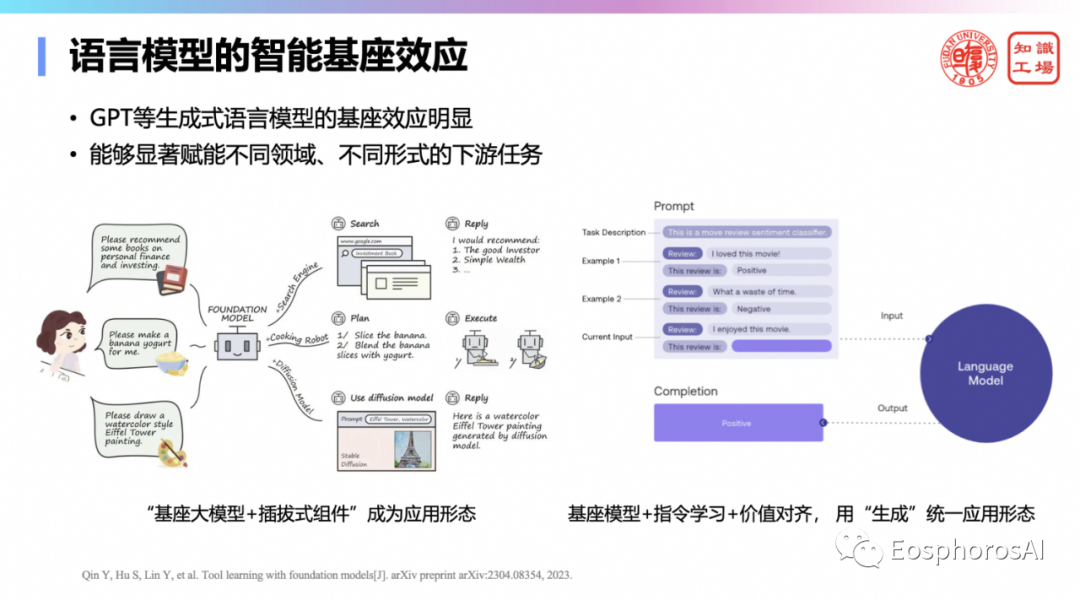
由于语言模型具备了丰富的知识和强大的能力,使其成为了一个新兴的智能基础,即任何应用程序通过接入大模型后,便能充分利用其能力和知识。目前,以“基座大模型+插拔式组件”为架构的应用形态已逐渐形成,包括机器人动作规划、图文生成等任务都已经引入了大模型,同样数据库系统也需要引入大模型。因为语言模型用“生成”统一了应用形态,能够显著的适用于不同领域、不同形式的下游任务。
我这里举了一个例子,比如说翻译,这个翻译的好还是不好,以前只能靠人工去来评价。今天可以大量的使用大模型来评价你这个翻译的好和坏。只要你能够把这个指令写的足够细致,步骤写的足够详细,这也是大模型给带来很大一个机会,大模型成为了智能的基座。
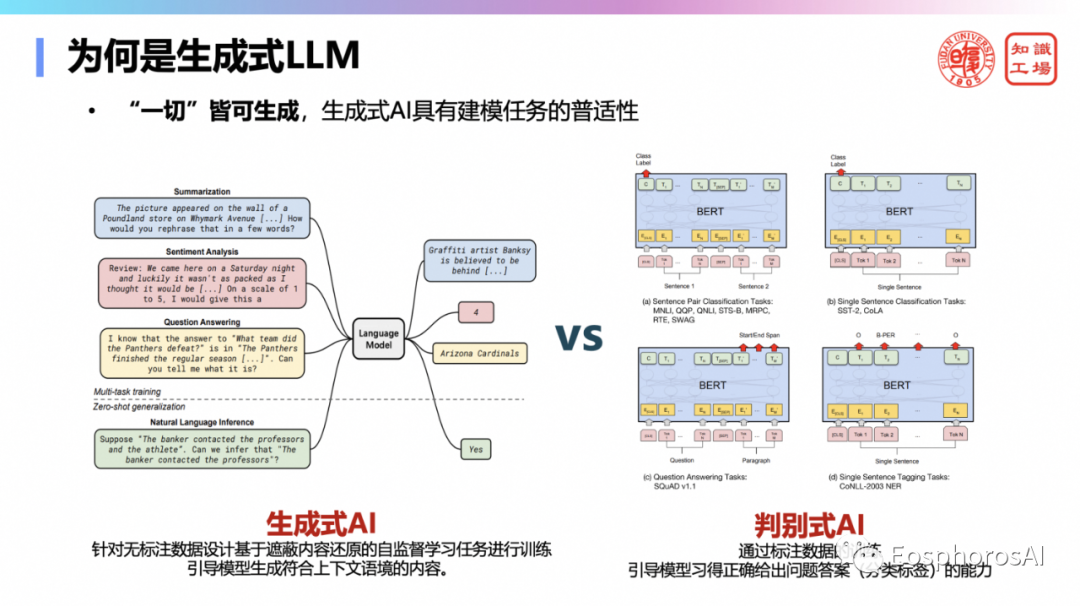
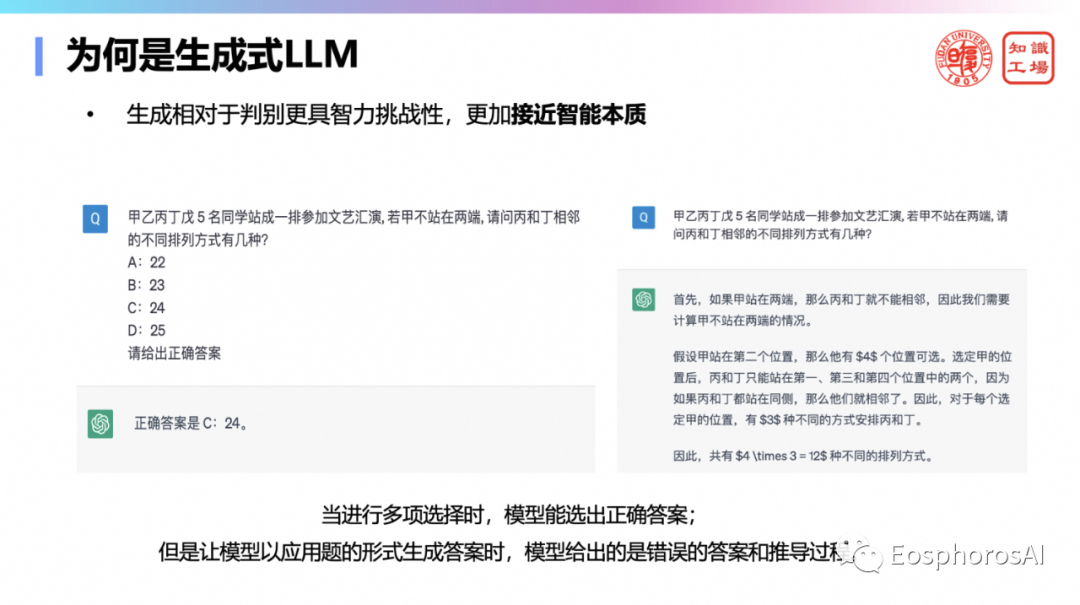
为什么是生成式语言模型胜出而不是判别式模型呢?相较于只给出答案的判别式模型,生成式语言模型不仅可以生成答案,还可以给出解释和推导过程。因此生成式模型更具治理的挑战性,更加接近智能本质,具有建模任务的普适性。“一切”皆可生成。

对世界来说,世界的存在不依赖“知识”,不依赖人类,只要合理生成世界就是一种智能。对大模型来说,它的智能本质上是一种情景化生成能力,即给定合理提示,能生成相关的答案。如在 zero-shot,few-shot 等场景,实验发现给的提示越丰富,越细致,大模型生成的结果就越好。
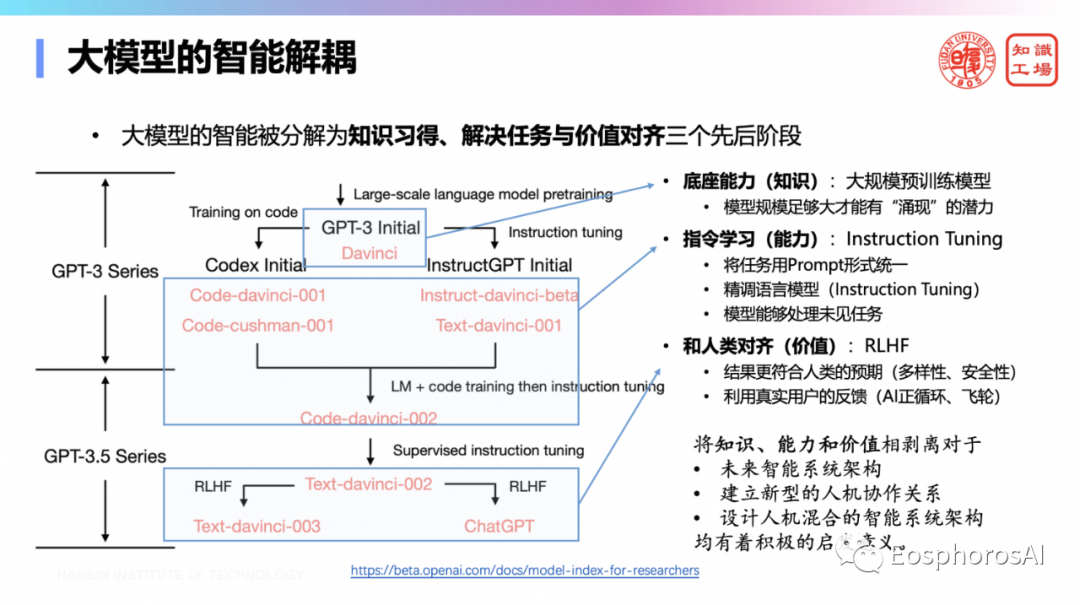
此外,大模型具备“涌现”能力,是因为大模型对智能进行了解耦,将其分成了知识习得、解决任务与价值对齐这三个阶段。这对未来智能系统架构的设计、建立新型的人机协作关系、设计人机混合的智能系统架构都有着积极的启发意义。知识习得对应大规模预训练模型的底座能力,即完成知识的积累。解决任务能力对应指令学习,即将所有任务用prompt形式统一,精确语言模型,使得模型能够处理未见任务。价值对齐对应人类社会,即利用真实用户的反馈让模型生成结果更符合人类的预期。
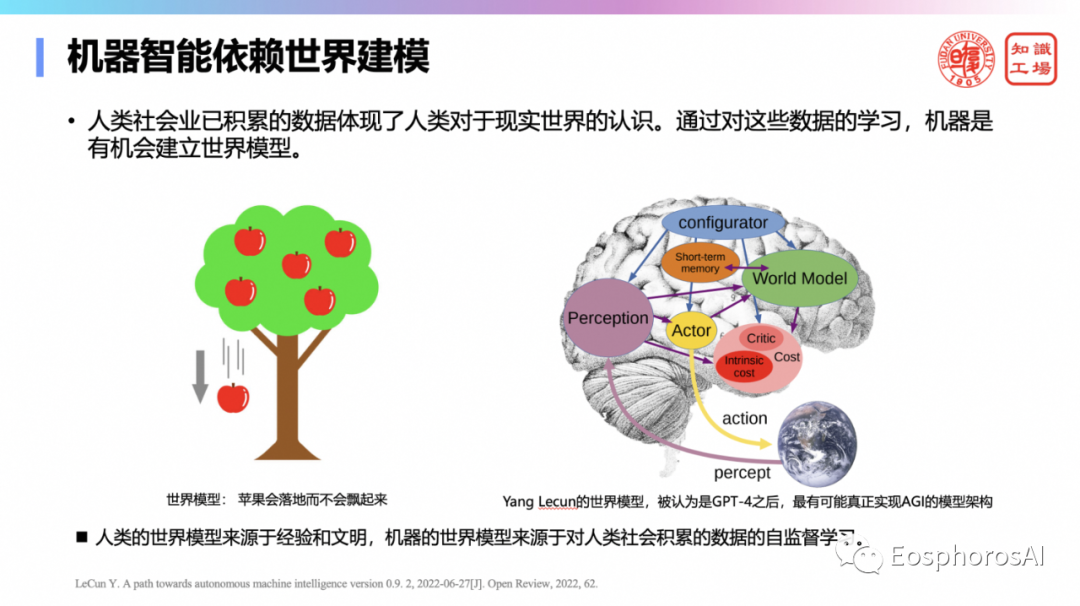
大模型本质上学到什么?它实际上就是学到一种世界建模的能力。比如说苹果上树上掉一个苹果,它一定要往地上落,而不是往天上飘?这就是一种世界建模的能力,最近的 MIT 的一些研究也在讲这件事,说大模型就是完成了世界建模。

人类的世界模型来源于经验和文明,机器的世界模型来源于对人类社会积累的数据的自监督学习。人类社会业已积累的数据体现了人类对于现实世界的认识,通过对这些数据的学习,机器是有机会建立自己的世界模型,但是机器需要通过物理世界和逻辑世界的共同建模才能真正理解人类语言。为了习得世界模型,语言模型可以采用遮掩还原的方式(Masked token prediction)进行训练,当然不仅局限在文本,图片、基因、日志等类型数据都可进行训练。
有的时候我就说这个叫大道至简,你说大模型这么强大的能力,它如何练出来的?结果用了一个最简单的这种,抠掉一个词让你预测这个词是什么,就是这个Masked token prediction 。最简单的任务往往炼制出了最复杂的东西,大模型我一直认为它就是一个工程,如果你只是追求效果,它这里面可能没有太复杂的这种科学问题。但这是工程,工程就是一定要把这活做细,一定要把脏活累活做好,这后面会讲的,就是把它要把数据本身做好非常重要。

可以说大模型出来之后,我是对数据管理领域特别兴奋。其实我很早以前就做数据库,但是我这么多年不做数据库了,为什么呢?因为我只觉得数据库里面很多问题,还是比较传统。可是为什么现在 chatGPT 出来之后,我觉得数据管理又会迎来第二波新的机会呢?因为看到了很多新的机会,大模型刷新了对很多问题的认识,刷新了数据管理领域的很多传统认识。
第一,大规模语言模型刷新了人类对于数据语义的认识,即语义是可以从数据中统计学习出来的。以前的数据管理领域的语义是什么?语义是声明式的,是由专家来 Declare ,声明这张表的语义是什么。但是大模型的语义是什么?大模型的语义是从数据里面自下而上学出来。它学到的这种数据之间的统计关联,它就是一种语义,完全是数据驱动学出来每个词的含义,不需要人再去什么声明这个语义了。
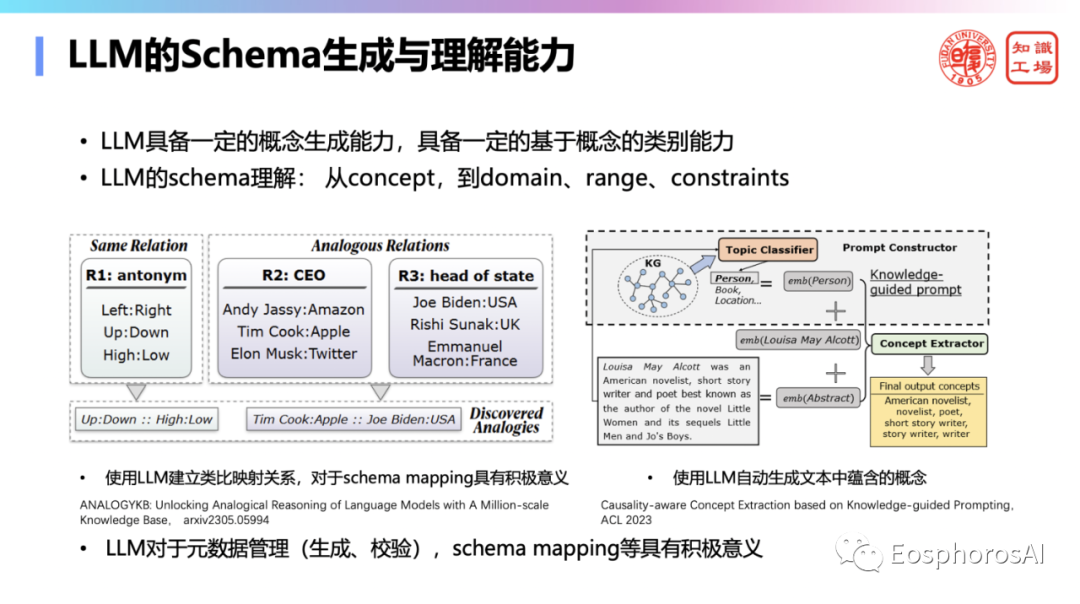
第二,大规模语言模型具备一定的概念生成能力,具备一定的基于概念的类别能力,对于元数据管理(生成、校验),schema mapping 等具有积极意义。数据管理领域离不开 schema,势必需要定义一张表的表格结构。现在大模型已经初步具备了一定的 schema 理解能力,这一张表大概在讲什么事儿?哪些字段之间有什么关系?目前在AI领域是已经有不少这种研究,在研究这个大模型是否能够生成概念呢?这个概念之间哪些概念与概念之间可以类比。
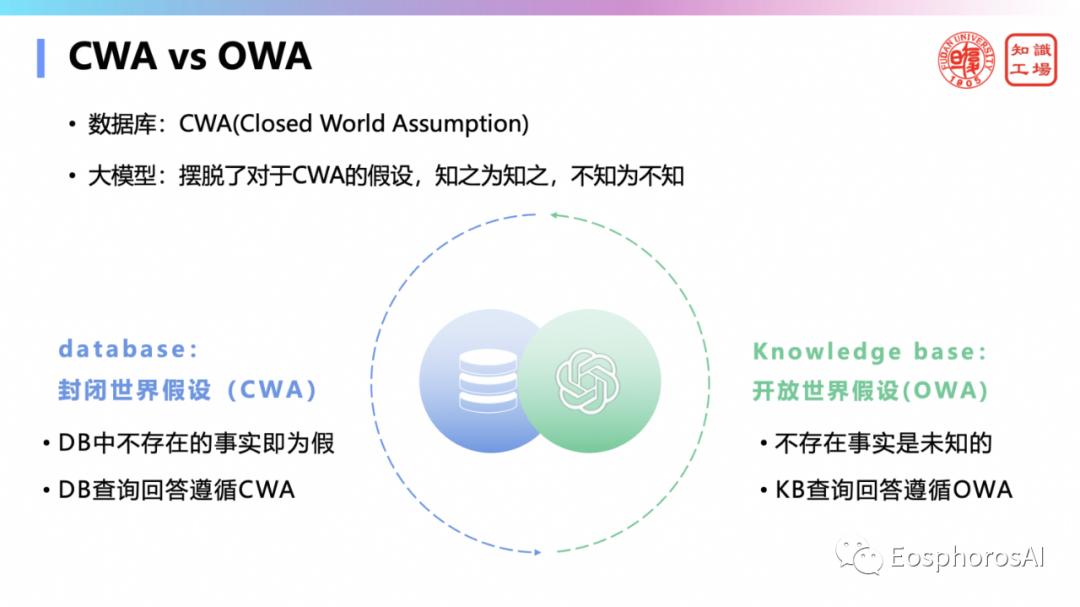
第三,数据库基于封闭世界假设,即数据库中不存在的事实为假,而大模型摆脱了封闭世界假设,大模型认为不存在事实是未知的,即知之为知之,不知为不知。比如,无论是数据库还是知识库,一直依赖查询和前提的假设。的数据库查询依赖的假设是什么?叫封闭世界假设,什么意思?就是这个查不到的就是不成立的。但是的知识库,一般的假设是什么?是开放式的假设,就是查不到的,也有可能成立是吧?
实际上有了大模型之后,这些假设都不需要了,大模型是如何做到的?现在你问大模型,如果它查不到,会说我不知道,不会说可能存在也可能不存在,因此摆脱了封闭世界假设和开放世界假设的要求。
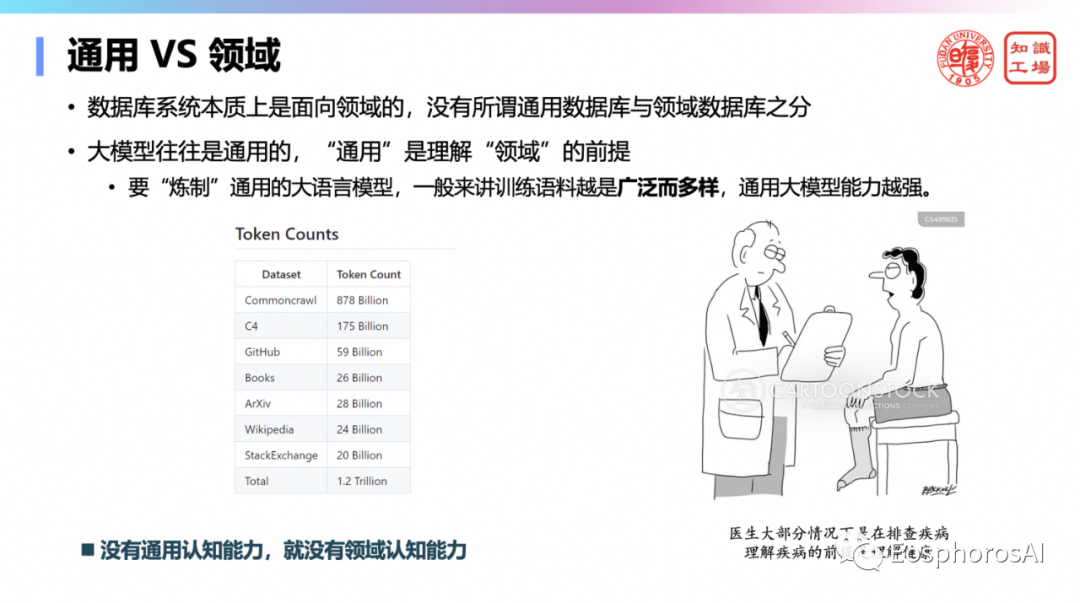
第四,大模型往往是通用的,因为“通用”是理解“领域”的前提,没有通用认知能力就没有领域认知能力。数据库本质上都是领域的,数据库系统可以叫通用数据库系统,但是某一个具体的DB,它一定是某一个特定主题的database。
但大模型本质上是通用的。以前的做领域的应用,实际上一直缺一个什么呢?缺一个通识能力这样一个前提。一个人打开一个数据库,就能够明白这数据库里的内容,有一个很重要的前提就是你有通识能力。其实的专业能力领域的认知能力是建立在通识能力前提之上的。比如说医疗,我经常说医疗的例子,这个医生要想能够看病,首先要了解什么叫健康。因为医生很多时候是在排除你是健康的情况,一个人如果不知道什么叫丑,是不可能真正理解什么叫美。也就是说你要理解某一个概念,恰恰先要理解概念之外的内涵,理解某一个领域恰恰先要理解领域之外的。大家会发现,你如果是去炼行业大模型,你一定要在行业大模型去配比数据的时候,配适量的通用数据,为什么?因为不能损失它的通用认知能力,这个背后都是有它的道理。专业认知能力、行业认知能力是建立在通识能力基础之上。今天大模型给带来全新的机会,让机器有了通识能力,机器只有有了通识能力,才有可能真正发展出专业认知能力。通识是专业认知的前提。因此,说大模型去理解数据库里的内容成为可能了,现在才成为可能,以前是做不到的,以前是因为没有这个通识能力,根本不可能做到专业认知能力。
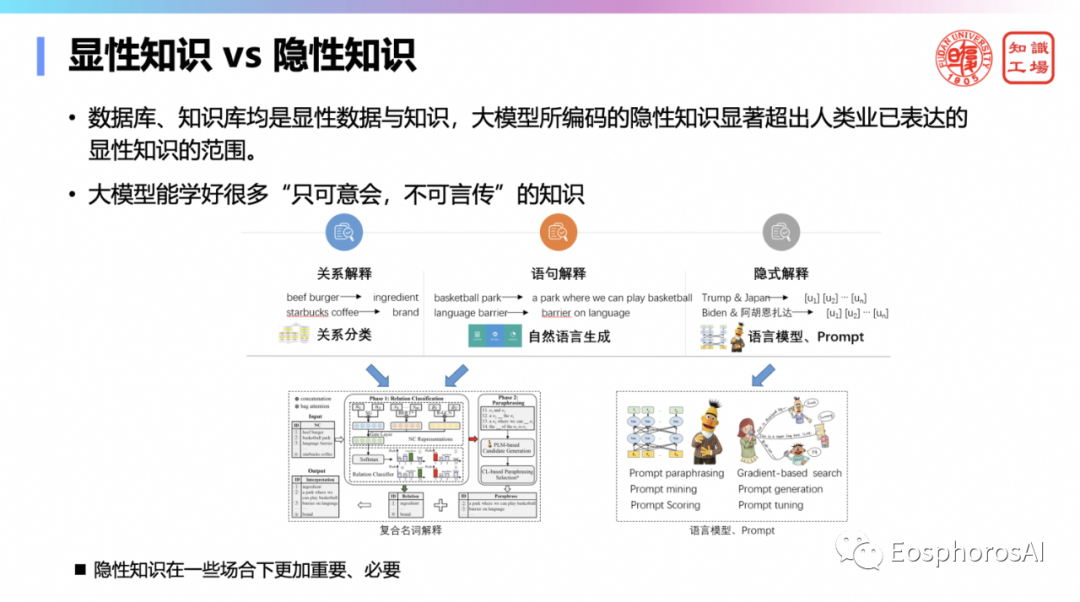
第五,隐性知识在一些场合更加重要、必要。如一位优秀教师的授课经验是隐式,很难将其用文字表述出来。而大模型能学好很多“只可意会不可言传”的知识。
大模型里的知识都是什么?是一种隐性的参数化表达。而数据管理全是符号化的,可理解可解释的。事实上你会发现其实人类社会也有很多事物,是很难用一种可理解的、可解释的符号显现的表达,比如,解释两个词的关系,当我给你的词是简单的叫beef burger,你可以用一个词来解释叫原料。这个beef burger之间关系是一个原料关系。当我给你两个词叫篮球和公园,你可以用一句话来解释们的关系。但是我给你两个人,比如说什么特朗普和拜登,当然这两个关系可能你已经很难用一句话来表达,你可能写一篇长篇小说也说不清楚。也就是说这个时候可能最佳的表达方式,就是这两个词在语言模型中的那一个参数化表示,可能是它的一个比较相对比较完整的表达,所以隐性表示可能是更自然的。
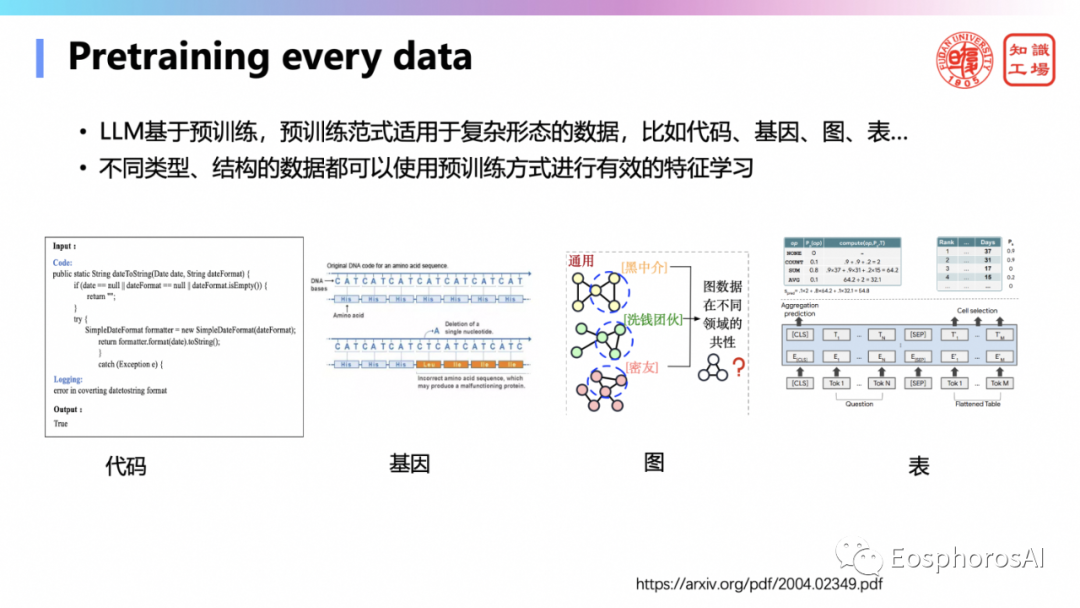
第六,Pretraining成为释放数据价值的一种非常重要的范式。只要数据能够被序列化,如代码、基因、图、表,就可将 pretraining 运用到这些数据上,使大模型具备对应的能力,释放其价值。所以任何异构、异质、不同模态数据都可以丢到大模型里进行炼制,实现价值变现,而不同模态、不同结构之间的数据对齐将成为关键问题。

只要能够把数据序列化,就可以利用语言模型的自监督学习机制来 pretraining 里面的数据,让 pretraining 的这个 foundation model 能够有效的表达数据中所蕴含的一些特征,才能够在下一个任务中表现出很多能力,这就是pretraining。那 pretraining 意味着什么?它就相当于以前说的异构多模态数据管理。以前的数据管理领域要针对不同的类型的模态的数据设计相应的数据管理机制,一直是很痛苦的一件事。将来有了 pretraining 之后,不管什么 data 都可以 pretraining ,相应的这种隐性的参数化的表达,所以 pretraining 有可能成为释放这种多模态异构数据的价值的一个非常重要的一种方式。
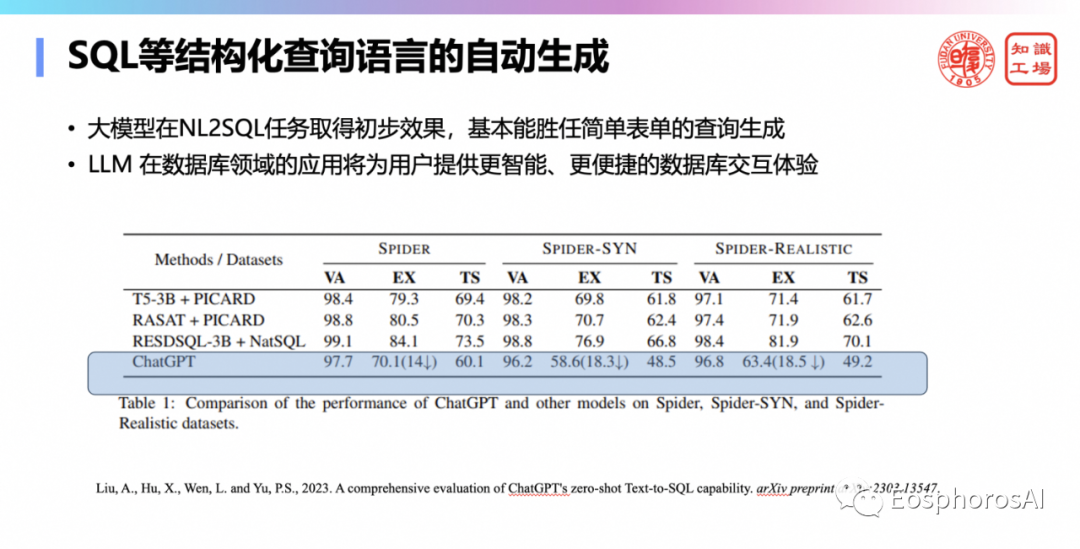
第七,自然语言的访问接口。以后结构化语言有可能已经完成了历史使命,将来 everything 都可以用自然语言来表达,结构化语言这个意义已经不大了。说自然语言已经可以消除人际沟通的这种鸿沟了,专业语言的这种表达鸿沟也可以消灭掉了,各种各样结构化语言基本上都可以用自然语言自动去生成,这个已经是不难,而且有很多落地的场景,当然这个落地的关键在于生成和提示策略。

第八,结构化数据理解。GPT-4 前段时间的一个发布,其中很重要的特点是对于结构化输出的支持,也就是让大模型能够理解各种各样的结构,像XML结构、json格式等各种各样的结构化表达,使大模型按照特定的格式进行输入输出。其实这个事情一直是很难的,也一直在做这个事儿。
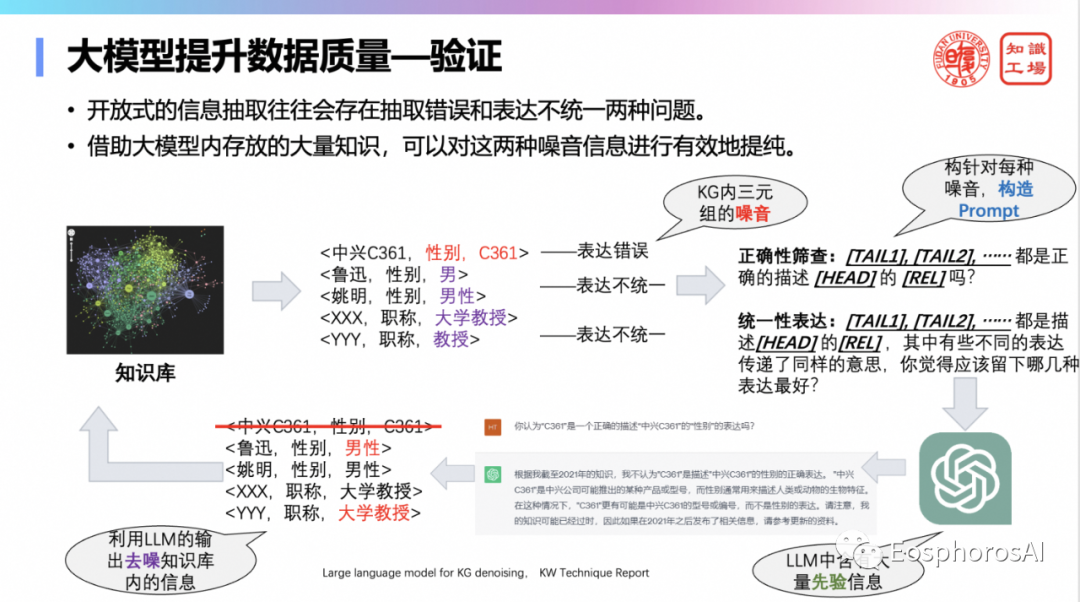
第一,数据质量管理。借助大模型内存放的大量知识,可以对错误信息和表达不统一这两种噪音信息进行有效地提纯。
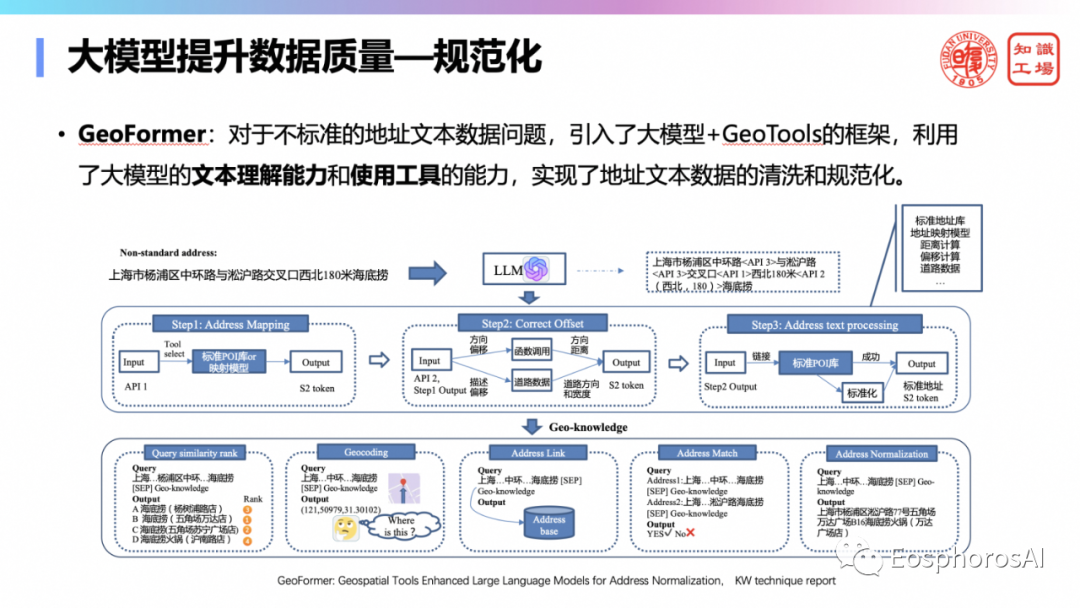
此外,结合大模型文本理解能力和工具使用能力,可以实现了地址文本数据地清晰和规范化。
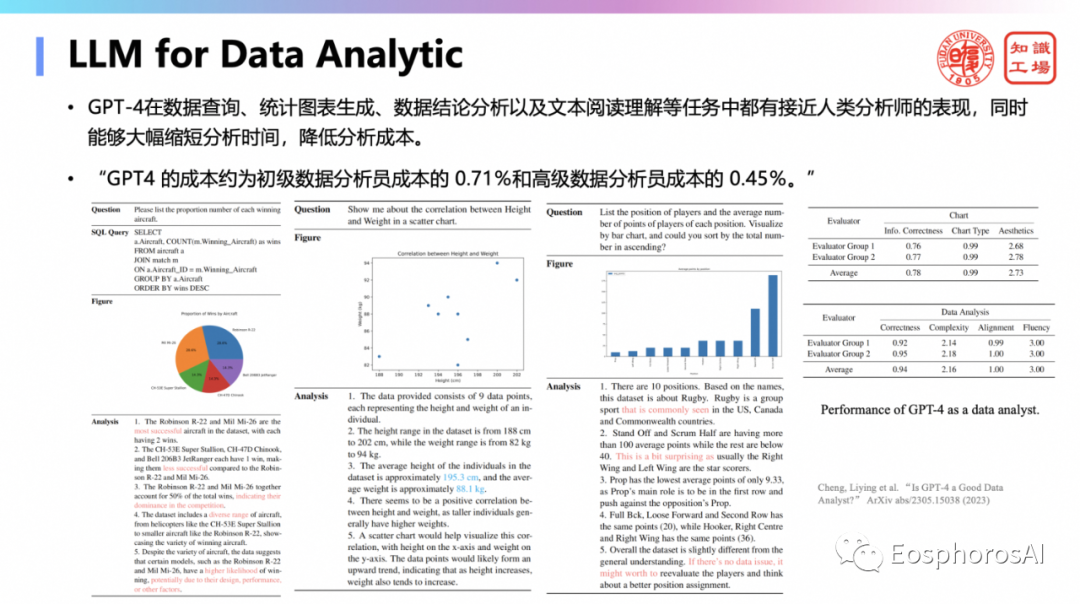
第二,数据分析能力。大模型在数据查询、统计图表生成、数据结论分析以及文本阅读理解等任务中都有接近人类分析师的表现,同时能够大幅缩短分析时间,降低分析成本。对于数据分析任务,大模型直接帮你生成相应的 python 的数据分析脚本,调用相应的工具来执行这个分析,然后直接呈现。code interpreter 后面的核心能力是什么呢?一个是代码生成,二个是API的生成。面向数据分析,做一些 Planning,做一些 agent,agent 可能将来是数据管理领域非常重要的一件事。将来可能会设计分析很多 agent。比如,数据分析的 agent,数据库运维的 agent,数据库优化的 agent,数据库诊断的 agent 等。大量的 agent 会在整个数据管理领域,将来可能就是在做各种的 agent。

另外一个就是对数据管理领域一个很重要的启发是什么?数据库关心的是 performance,但是 AI 一直是追求capability。实际上这两者之间是相互可以转换的,要把 AI 的能力转换成数据库的性能。这就是未来本质上 LLM + DB 本质上在做什么。

第三,数据库的智能运维工作。运维的数据库规模如此之大,比如,操控数据库、用 DDL 语言去建表、建索引、优化、配置数据库等,为了把数据库管理员从很繁重的数据库运维工作中解放出来,将来这些事情能不能完全自然语言,而且能不能让执行环境还能够跟人进行交互,在专家的反馈和调教下,让能够做智能化的数据运维。这里讲的是个操作系统的一个智能运维,其实本质上是一样,能够做到操作系统自运维,就可以做数据库系统智能运维。其实这个话题我觉得最早什么时候提的?最早两三年前我当时就在讨论的问题。但是几个大厂当时不敢做的问题,的确在 boat 时代这个事情做不好。但是到了 GPT时代,这个事情现在已经加速了,已经可以做的越来越好。我可以告诉大家,就现在整个像智能运维、智能诊断、智能优化,在网络领域、操作系统领域已经大量在做,而且效果已经非常非常显著。
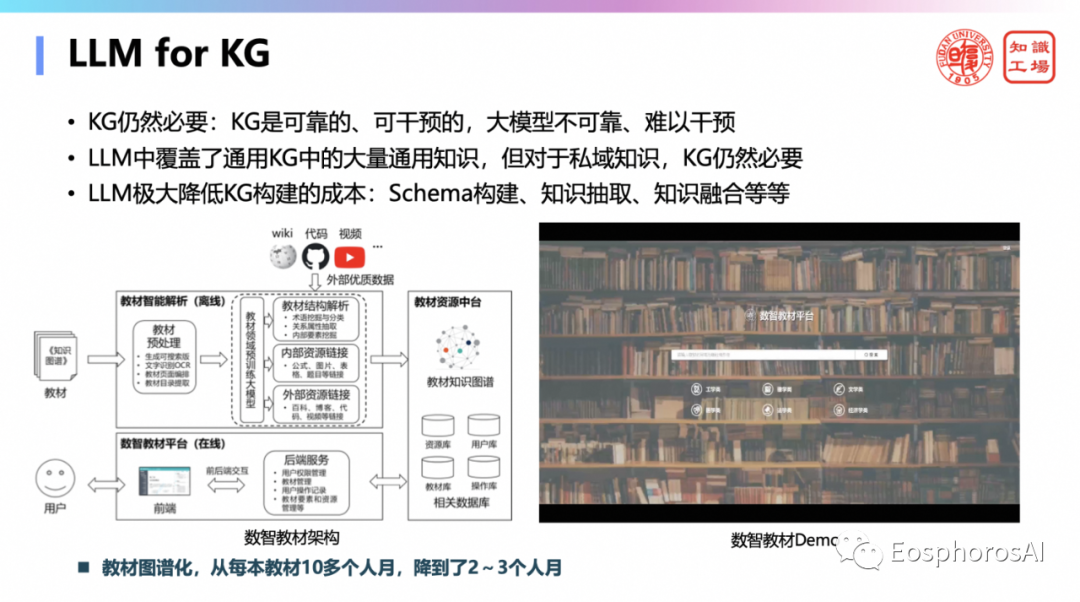
在数据库领域不可避免会要去谈一个问题,就是那个 KG,KG 还有没有没有必要?在 language model 刚兴起的时候,很多人说 KG 就没必要了,其实这是不对的,上面也说了 KG 仍然很重要,而且可以这么说,KG 里迎来了重大的发展机会,为什么呢?以前做一个 KG 构建,用传统小模型去构建 KG 实体识别关系抽取,其实代价很大,成本很高。而现在,比如做了个教材,把每一本教材里面的知识库给抽取出来,现在的成本从传统的十多个人/月降到了2到3个人/月。因此大量的使用 language model 作为 KG 的内核后,KG 的构建成本将极大的降低。那有 language mode 就不用构建 KG 了吗?不是的,在很多场合,大家对可控、可解释、可编辑是有要求的,还是需要先构出来 KG 然后人工干预后才能够上线。
上面部分主要是讲 language model for DB,那么反过来,DB/KB 对大模型有没有贡献呢?我认为 DB 或者 KB 对language model 也是有很重大的价值的。
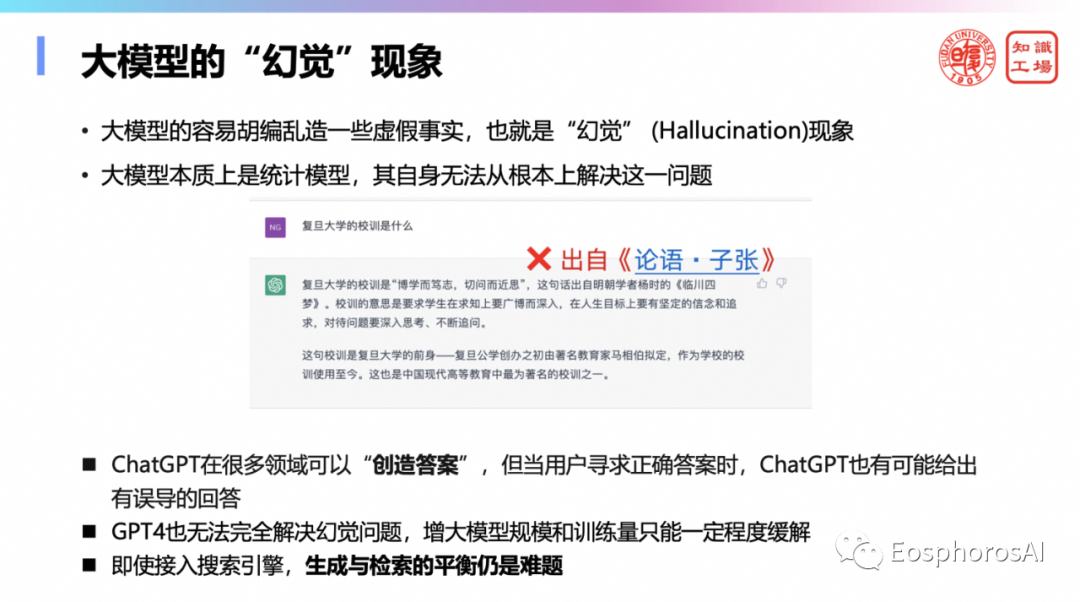

大模型也是存在一定缺陷的,如大模型容易出现“幻觉”现象,胡编乱造一些虚假信息,同时还缺乏“忠诚度”,即给定答案范围,大模型仍会“创造答案”。因此需要具有可控制、可编辑、可解释、可保护、可溯源等优良特性的数据库/知识库来弥补大模型在这些方面的不足。
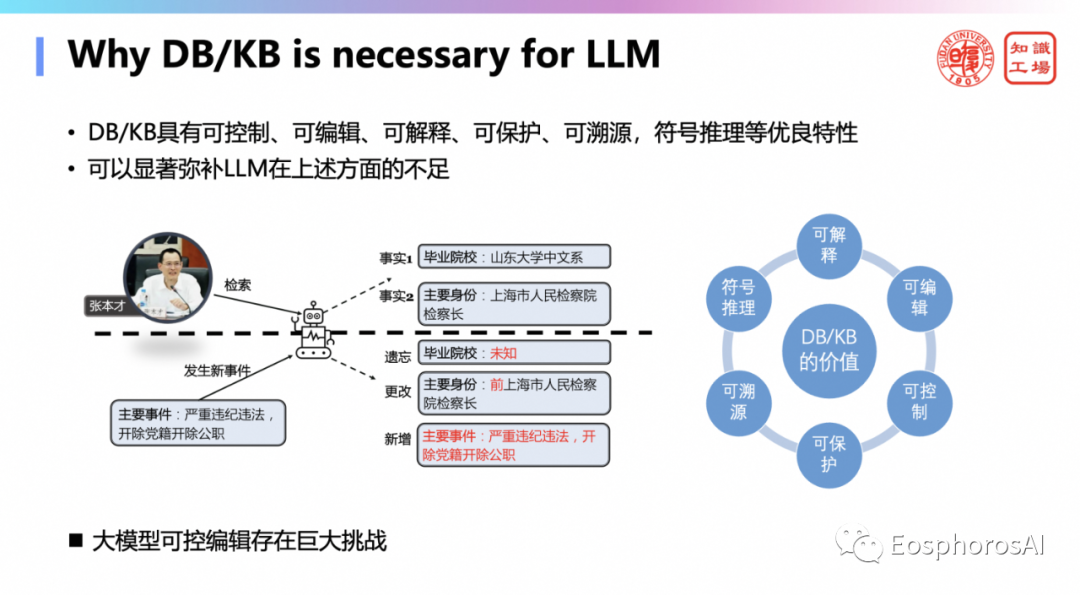
这里就说了,DB 和 KB 有一最重要的特性是什么?可控制、可编辑、可解释、可防护、可溯源,还有符号推理可理解,这些特性都是大模型不具备的。我这里举的例子就是政审领域,政治审核、政治审查这是很严肃的领域,一定要做到刚才说的可控、可编辑、可解释、可保护、可溯源。这些领域们绝对不敢轻易上大模型。比如,某领导有政治问题,结果还能检索出来这个领导,那这个就是非常严重的问题。网信办的《人工智能安全评估与核准管理办法》就是这个意思,只要出现类似政治上的错误,就要被关停至少一个月重新再炼,这个是很严肃的惩罚。因此在这些场合你必须要还是要老老实实用 DB 和 KB。
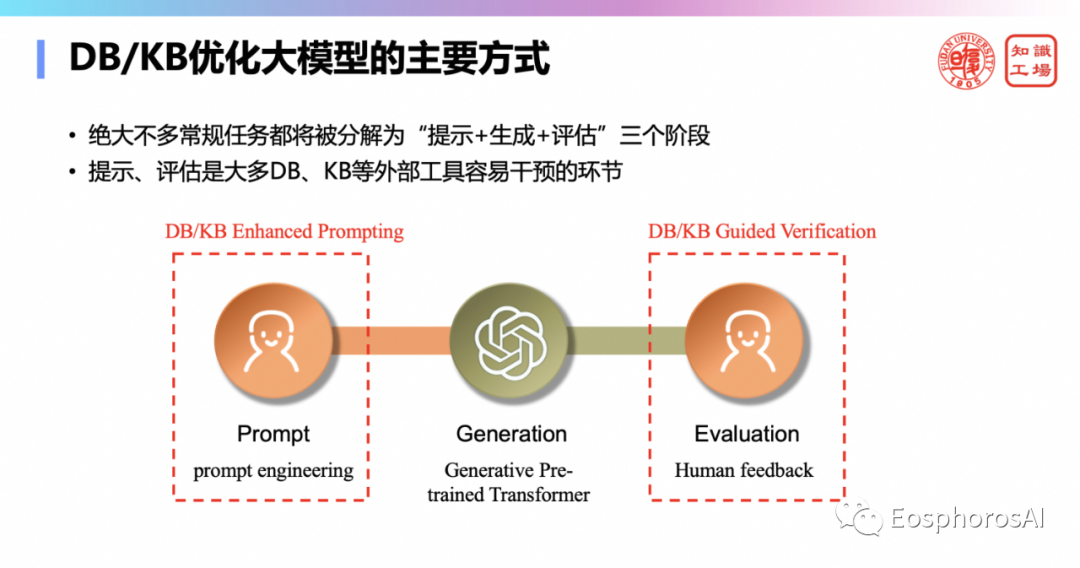
利用DB/KB做大模型的知识增强。可以分为以上三个阶段。

第一个就是提示阶段,比如,现在在做自然语言转SQL的时候,大量的会把DB的schema丢到提示里面,让大模型能够理解你的表格结构,这很有用,因此在提示增强要用到DB/KB。
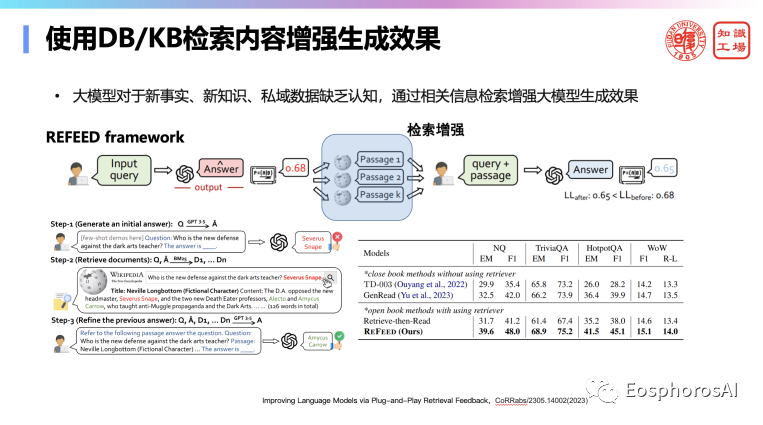
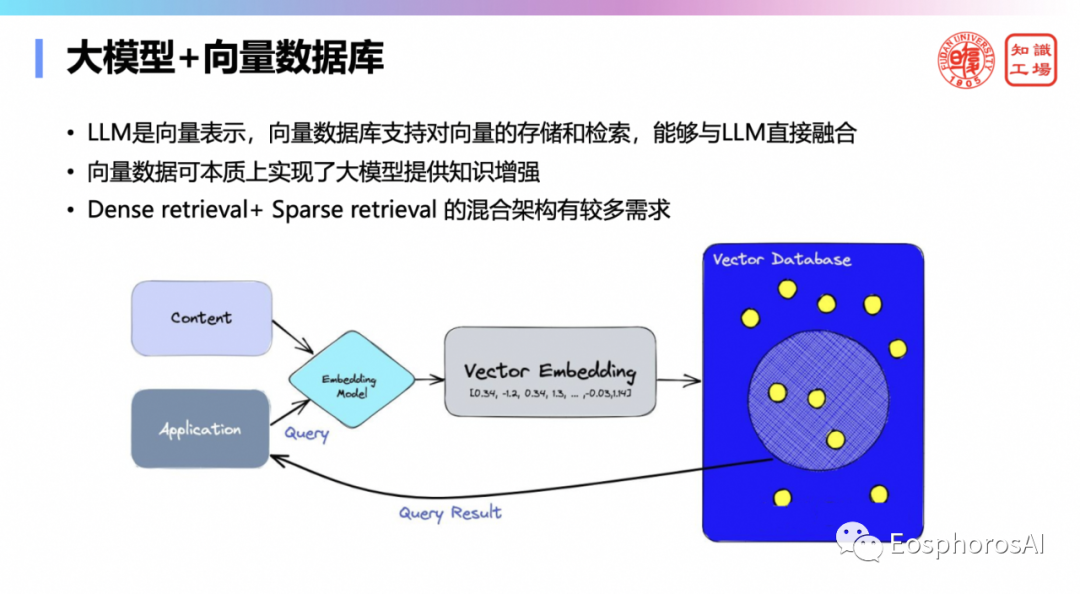
第二个就是生成阶段,生成这块可以用检索增强,有确保增强的这个生成。比如可以用向量数据库。
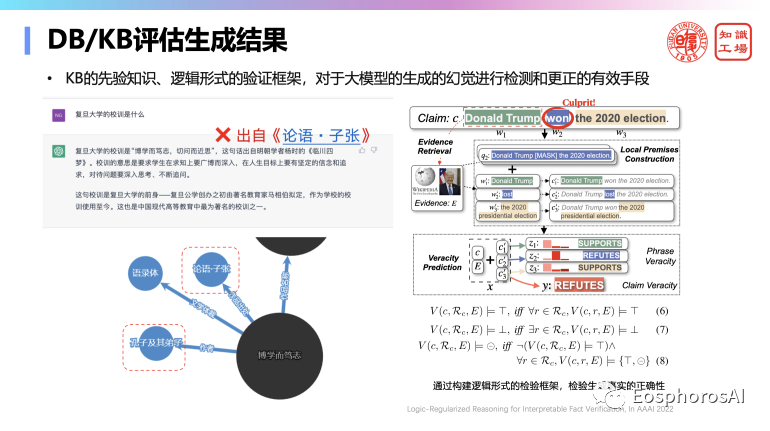
第三个就是验证阶段,生成的到底对不对?可以用传统的知识、规则、DB/KB 中的内容来进行验证。
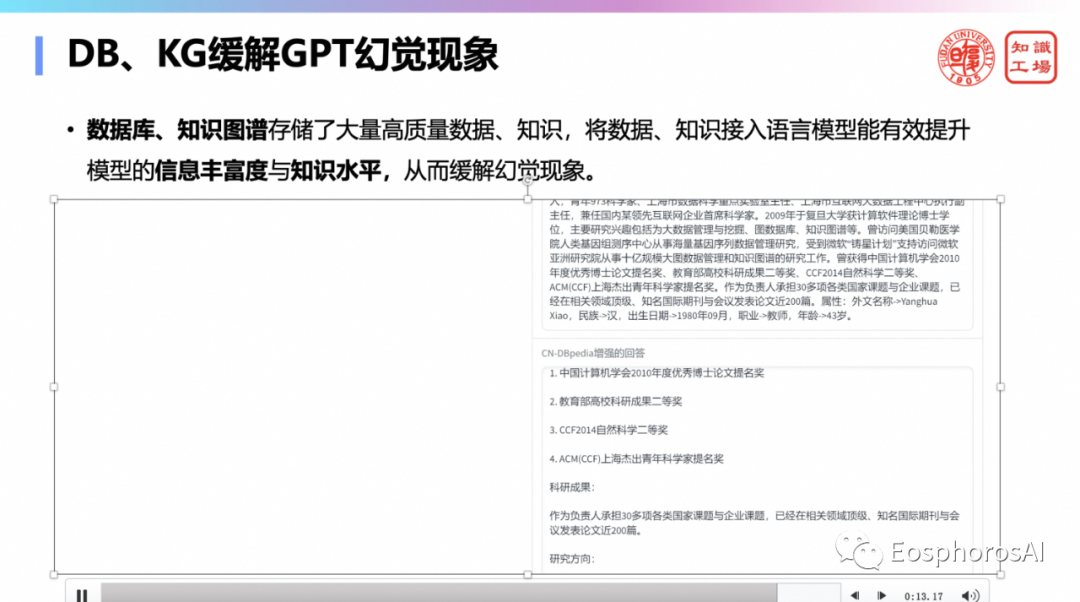
这里举一个例子来说明幻觉还是能够缓解的。如上图,如果我不去做知识增强,给我生成的这个简历,很多都是假的、胡编乱造的。但在知识增强之后,就会显著的解决这个幻觉问题,生成的还算是靠谱的,这个幻觉这问题基本上能解决。
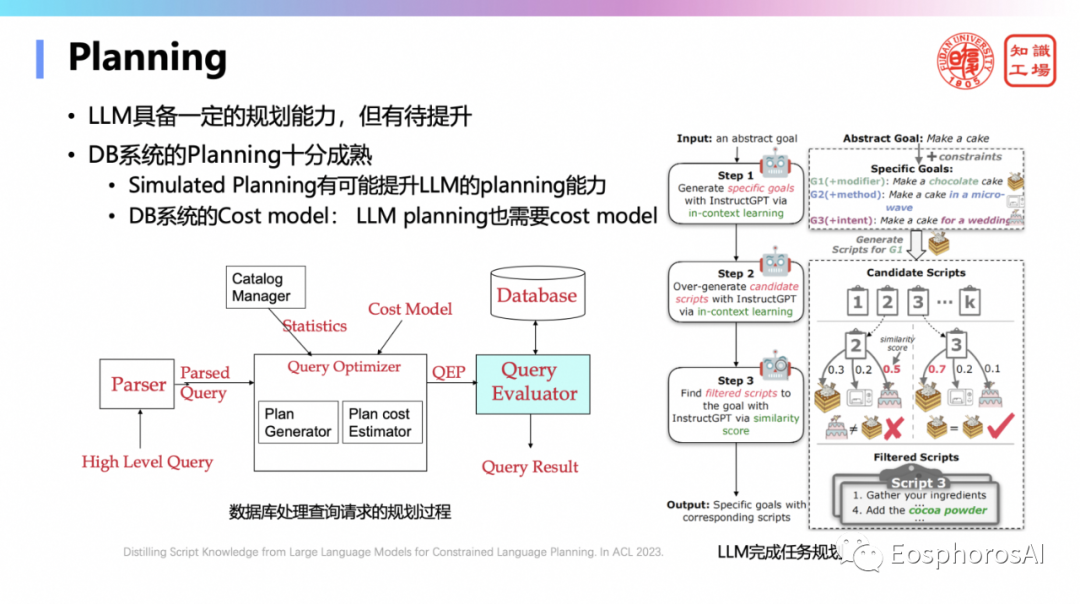
DB 对于对 LLM 还有很重要的意义在于 Planning 的能力,也就是规划的能力。DB 最重要、最核心的一个组件是查询计划生成器。Planning 的老祖宗在 DB,做研究一定要去追本溯源,早期那些专家是非常厉害的。Planning 是早期人工智能非常重要的一个研究问题,而它最重要的落地就在数据管理。能把一个计划生成做的这么好的,可能真的就咱们数据库管理,我还没见过第 2 个领域能把 Planning 做的这么好。数据库的每一个 query 的执行方案,就是一个非常好的 Planning的结果。我最近一直在想,能不能把数据管理里面这些 Planning 的结果,比如一个查询以及它相应的查询执行计划,拿过来去训练大模型,大模型因此具备非常厉害的 Planning 能力。这个不是不可能,完全有可能的,而且是完全合理的。为什么?因为最近大家知道用合成数据练大模型,一定是未来大模型竞争的一个焦点。那合成数据哪里呢?刚才说的就是一类合成数据。其实 SQL 的 Planning 生成,它是完全是基于关系代数生成的,关系代数有一套优化的理论以及相应的 Cost model 在指引它的 Planning 的生成。因此这一类的合成数据,是非常有价值的。众所周知,大模型只要在代码上预训练过,它的逻辑能力就会增强很多,那为什么不能在这种查询执行的方案上去预训练呢?这有可能是 DB 给 LLM 的一个重要的贡献。我告诉大家的是现在的大模型的判断能力是很弱的,还是经常会犯错的。去年就已经在大量的在研究大模型的这种 Planning 能力,实际上还是很弱,还经常会犯错。GPT-4 好一点,可能有百分之六七十,但实际上要使用仍然还是有距离的。
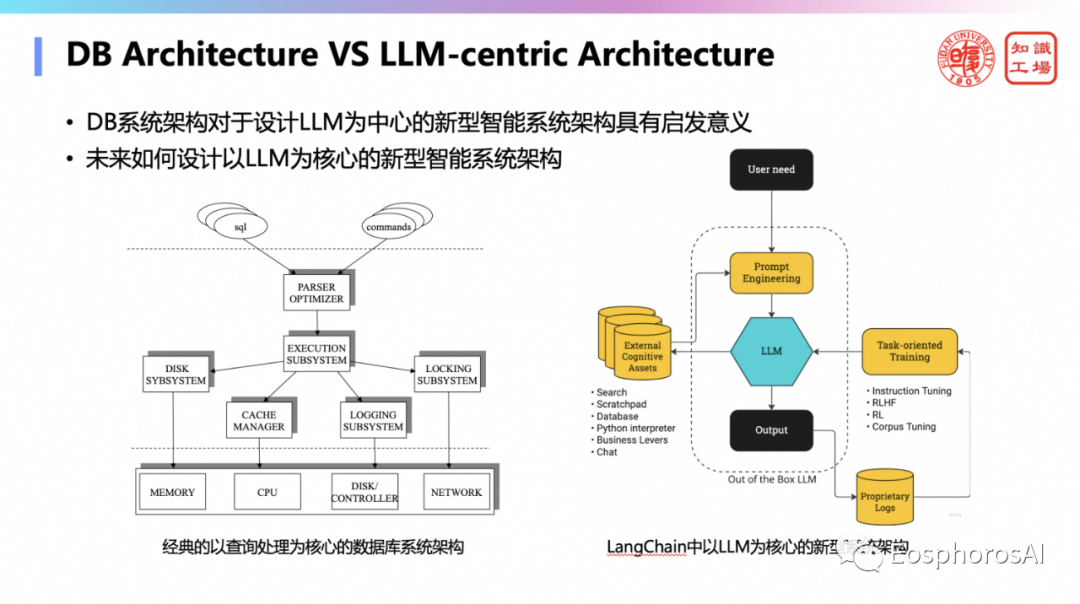
DB 对大模型的第三个重要意义就在系统的架构。DB 系统很复杂,有各个组件,各个模块,它是怎么去架构的?对于重新去架构一个以 language model 为核心的企业级信息系统,也是非常具有启发意义。DB 有一类研究,就只专注于研究system architecture,如何架构?如何分层?未来的大部分的信息系统或者智能系统一定是以 language model 为核心的,那这些系统如何去架构?这个大家可以去再去思考。

在数据管理领域,上文说过要把数据管理的传统问题给终结了。终结完了干嘛呢?那我是不是把自己的职业也终结了呢?不是。我是觉得大模型的活,将来就是数据库的活,就是做数据的人的活,我觉得数据管理领域未来可能大部分人要去做大模型的这个活。为什么?你看到一个大模型最终出效果,80%是在做数据,而现在都是做模型人在做数据,做模型人做数据是没感觉的、做数据是做不好的。前几天跟业界人沟通,我说 OpenAI 是一家很笨的公司,为什么这么说?要说做模型,肯定做不过谷歌。哪一家公司做机器学习模型能做得过谷歌?最先进的模型,最原创的模型全是谷歌做出来的。所以OpenAI 一定不是一家做模型的公司,是做数据的,它是为数不多的能把数据做好的,数据的治理、清洗、标注标签,这些方面是大模型 GPT-4 能出效果的关键。所以我评价一家公司大模型是否能做好,我就看你的数据团队做的好不好,你的数据团队专不专业。数据团队很专业,而且的确是做数据的人在做数据的话,你有可能你的模型做的非常好。反过来,如果一帮做模型的人在做数据的话,基本上我估计很危险,为什么?因为一个做模型的人笃信一个好的模型就能实现很多,但实际上大家看 OpenAI 的成功已经证明了数据更关键。
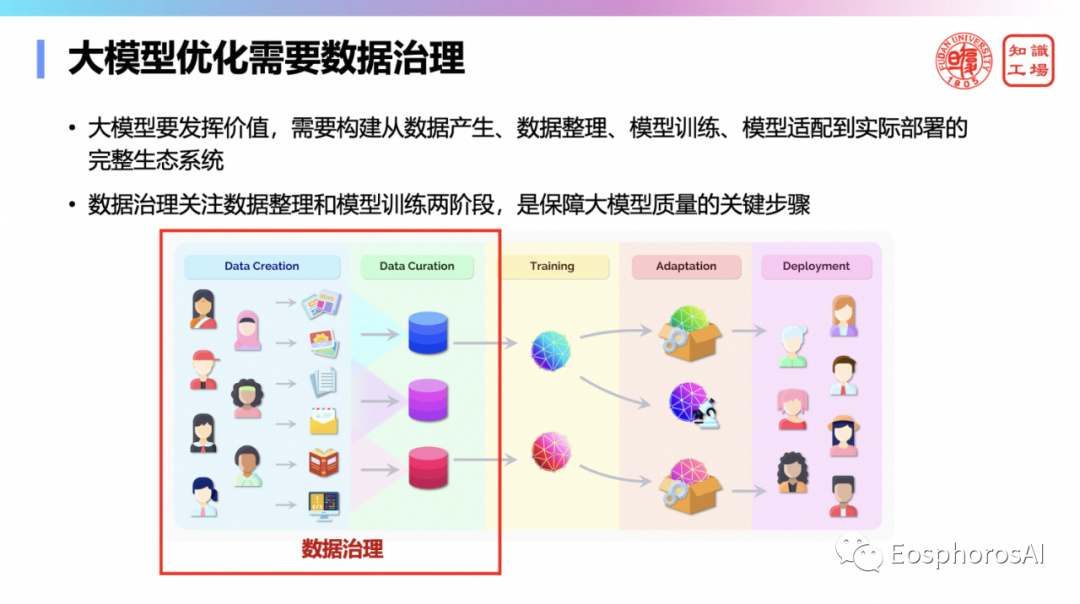
数据治理很重要,大模型存在人类偏见、隐私泄露、错误关联等、意识形态等问题
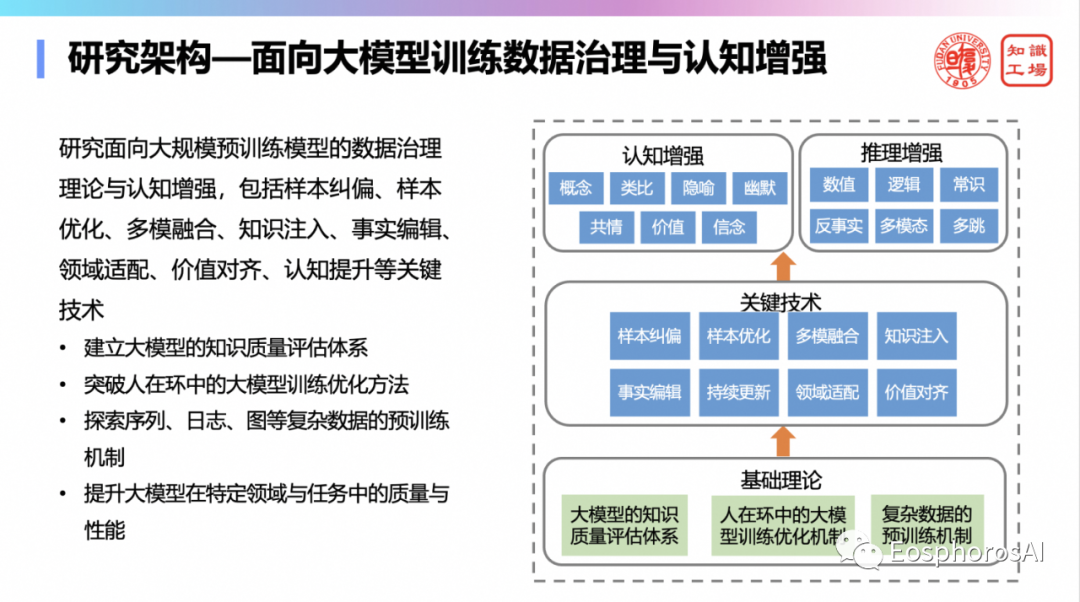
为什么 GPT-4 能出效果?为什么 OpenAI 的大模型就比咱们的好?国内大模型现在可能在某些指标上能超过,但是综合能力远远不如,很难超过。我是觉得 GPT-4 做了大量的有监督的 pretraining,做了大量的语料的标注工作,具体就不展开讲了。需研究面向大规模预训练模型的数据治理与认知增强的框架,思考如何建立大模型的知识质量评估体系;如何突破人在环中大模型训练优化方法;如何探索序列、日志、图等复杂数据的预训练机制;如何提升大模型在特定领域与任务中的质量与性能。
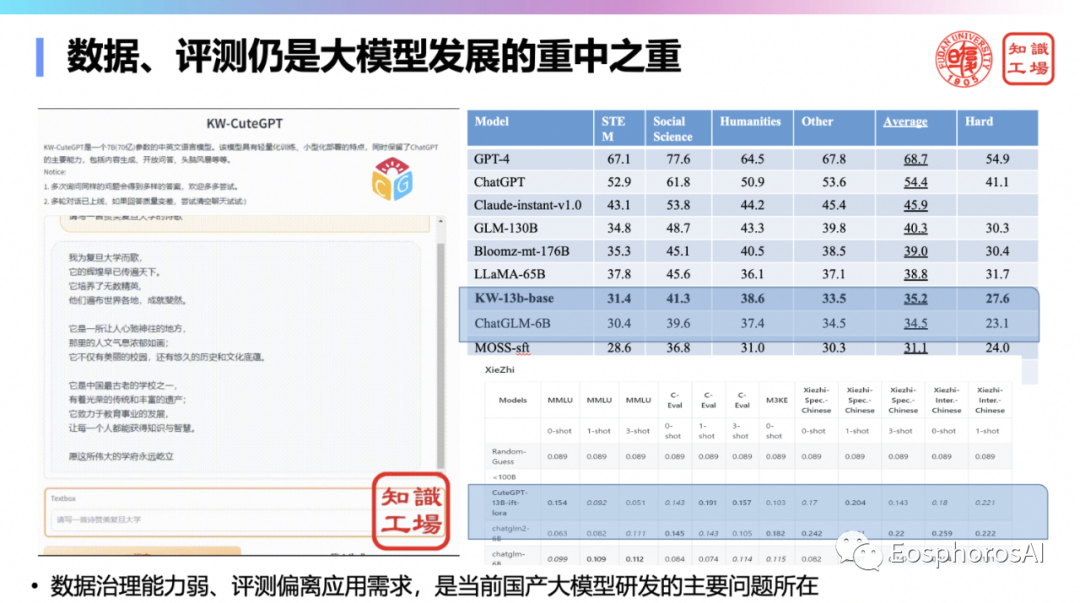
除了数据之外,评测也很重要。数据加评测,我认为可能是占大模型 90% 的工作。那如何做好评测,也是数据团队需要认真思考的。对当前国产大模型来说,数据治理能力弱、评测偏离应用需求是其研发过程中的主要问题。因此,还需将数据和评测作为大模型发展的首要任务。

最后用这一页来简单总结一下,在数据管理领域,数据库一直是确定性的,很少有人喜欢不确定性的,所以 DataBase 非常 Traditional,喜欢确定性,喜欢代数,不喜欢不确定。但实际上大模型恰恰走了一条不确定,它完全就是基于概率的,完全是一种不确定性的模型建模。要正式去拥抱,要从确定走向不确定,从分析走向综合,从还原走向综合,从分析走向融合。
https://github.com/eosphoros-ai/DB-GPT
https://github.com/eosphoros-ai/DB-GPT-Hub
https://github.com/eosphoros-ai/DB-GPT-Web