




赛题名称:标书实体抽取挑战赛 赛题类型:自然语言处理 赛题任务:对给定的非标采购文件进行实体抽取
比赛地址:https://challenge.xfyun.cn/topic/info?type=physical-extraction-of-tender
视频答辩地址:https://www.bilibili.com/video/BV1nb4y1T7kr?p=1
赛事背景
目前,能源行业在非招标采购业务过程中,标准化不够、结构化不足,难以满足自动化评审,为促进非招标采购业务无人自动化评审,开展采购业务标准化、评审因素结构化治理,进而研究采购文件、报价文件、资质证照和业绩合同等文档的智能解析与结构化,实现评审过程自动化、智能化,提升采购效率,实现降本增效。
通过本次比赛,推动参赛者对非标采购文件进行智能解析和结构化处理,提取关键信息,促进自动化评审。我们希望通过这样的方式,激发行业创新,推动非招标采购业务的标准化和智能化发展研究。
赛事任务
本次比赛需要参赛选手对给定的非标采购文件进行实体抽取,衡量标准是抽取非标采购文件实体要素准确率。该比赛的研究内容包括学术文档的版面分析、要素抽取及语义理解等,要求参赛选手能够将非标采购文件里定量定性的技术指标和非定量定性的详述类指标信息识别与提取。
评审规则
本次比赛为参赛选手提供了50份能源行业非招标采购业务的采购文件脱敏数据作为训练数据,50份作为测试集。
评估指标
任务采用F1-score进行评价,抽取的实体要素完全一致视为准确提取。
优胜方案
第一名
第一名的方案通过数据处理、模型训练、实体预测和后置规则处理等步骤,结合OCR识别和实体抽取模型,以及一些规则过滤,实现了对非标采购文件中实体要素的准确抽取。 通过不断优化和尝试不同的方法,达到了较高的准确率。
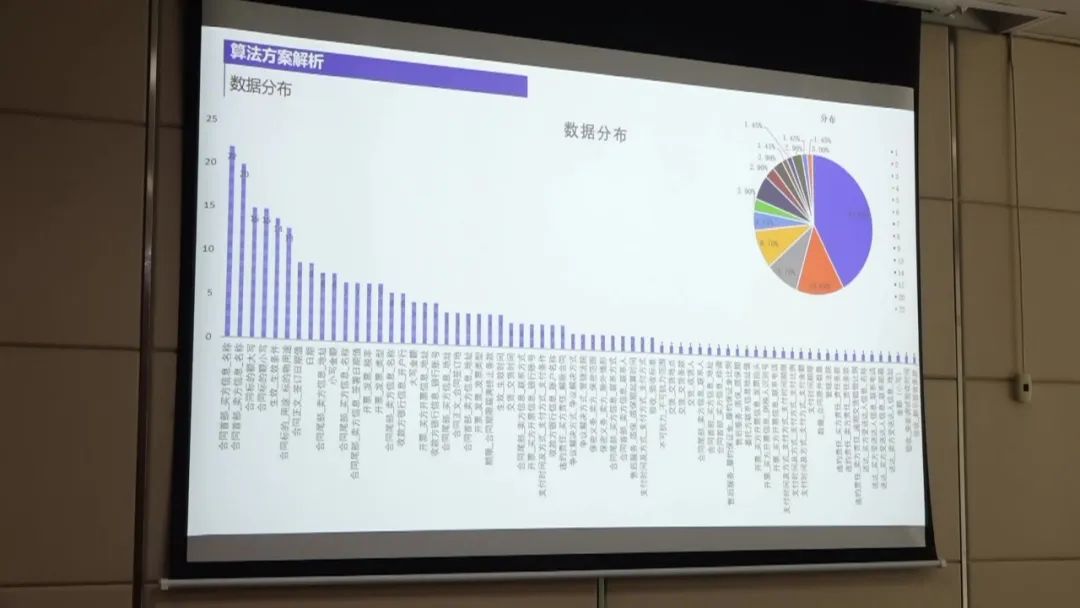
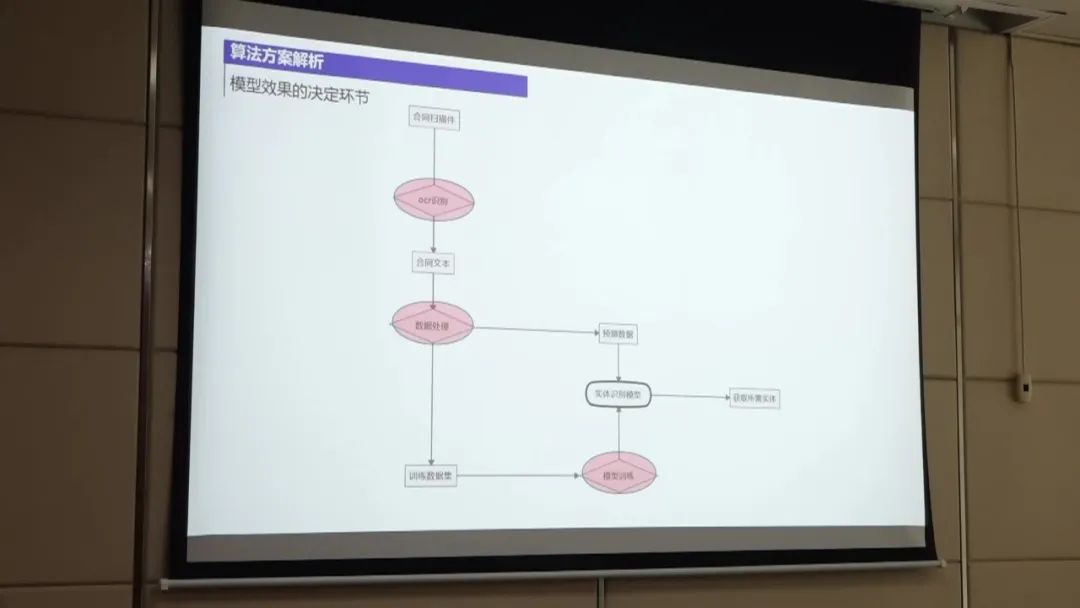
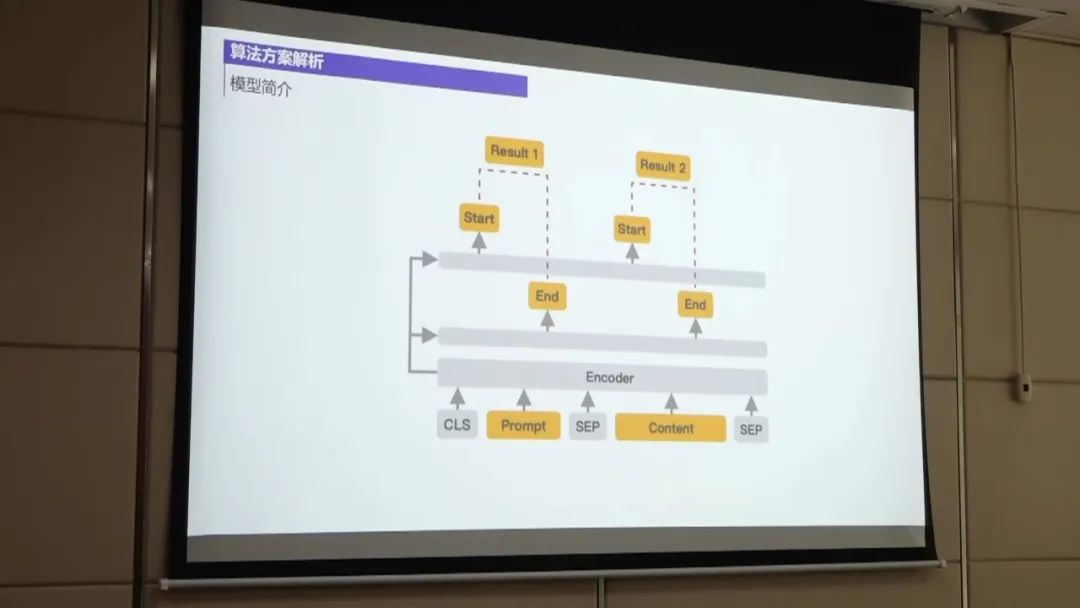
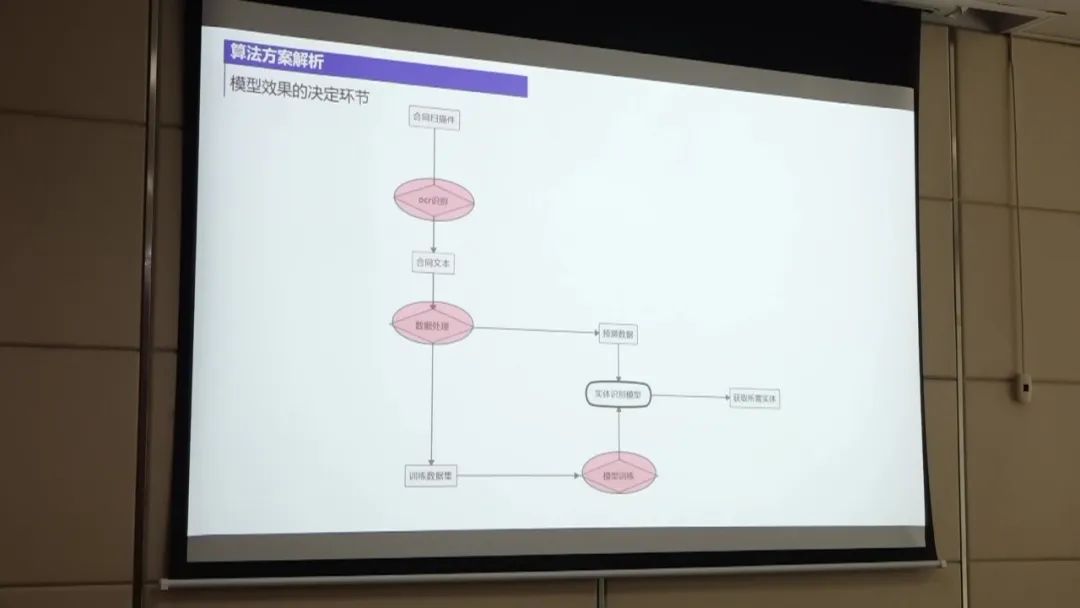
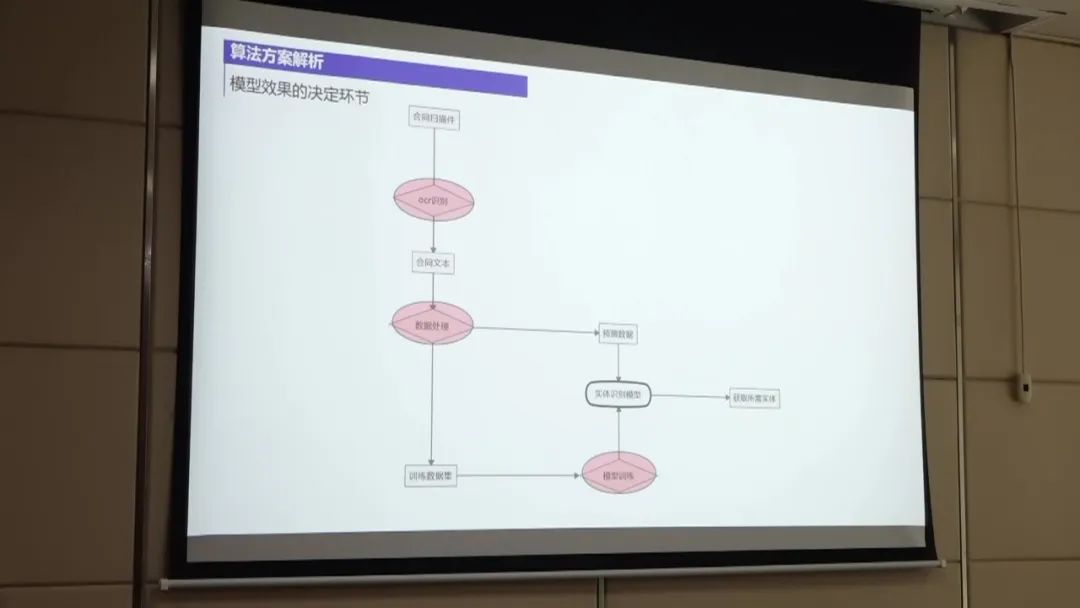
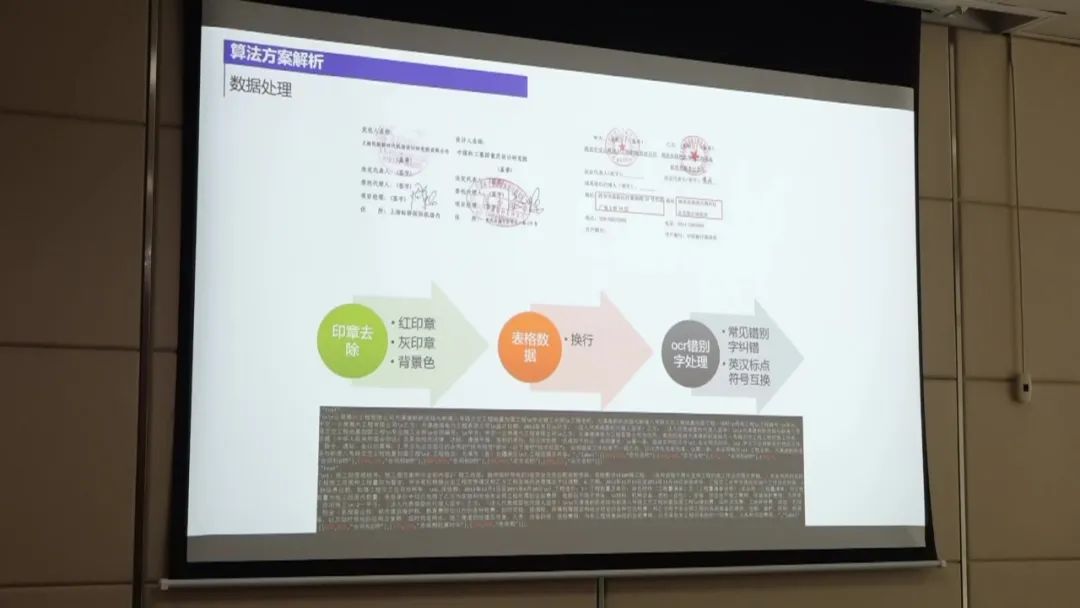

第一名的方案主要包括以下几个步骤:
数据处理:首先,将扫描件通过OCR技术转换为合同文本。然后,对合同文本进行处理,包括对标签进行整合和边界进行整合,以降低数据的不平衡性。此外,还对OCR识别结果进行纠正,通过构建样本集来发现OCR识别错误,并进行调整。 模型训练:使用UIE模型进行实体抽取的训练。UIE模型是一种抽取式模型,通过结合边界名和文本来抽取结构化数据。 在训练过程中,对数据进行微调以提高模型的性能。 实体预测:使用训练好的实体抽取模型对待抽取的非标采购文件进行实体预测。 通过将OCR识别结果与给定的标签文本进行匹配,从中提取出实体信息。 后置规则处理:对实体预测结果进行后置规则处理,以进一步提高准确率。 例如,对金额和公司名称进行规则过滤,只保留符合规则的实体。 性能优化:为了进一步提高性能,可以尝试使用大模型进行训练,并进行数据增强。 此外,还可以尝试模型融合的方法,将多个模型的预测结果进行综合,以获得更好的效果。
第二名
第二名的方案通过OCR处理、要素名称统一、大模型微调等步骤,结合多种OCR方法和字典映射,以及对模型进行微调,实现了对非标采购文件中实体要素的准确抽取。 通过进一步优化OCR处理、版面分析和模型的prompt设计,可以进一步提升方案的准确率和效率。








第二名的方案主要包括以下几个步骤:
OCR处理:首先,使用开源库、自研OCR和百度OCR等多种方法对给定的PDF进行OCR处理,将其转换为文本格式。 这些方法各有优劣,开源库部署方便但效果较差,自研OCR稳定性强但部署困难,百度OCR效果好但需要付费。为了综合考虑效果和成本,综合采用了多种方法进行OCR,并进行人工整合。 要素名称统一:由于给定的要素名称可能存在不一致的情况,为了保证模型的理解和抽取准确性,构建了一个一一对应的字典,将相似的要素名称统一为同一个名称。 例如,将"大写金额"、"合同标的额大写"和"合同总金额"统一为"大写金额",以确保抽取结果的一致性。 大模型微调:选择了清华大学的ChatGLM2模型作为基准模型,大小为6B。通过微调基准模型,使用50个训练样本进行SFT数据的构建,以更好地适应任务需求。 微调后的模型输出更符合所需的数据格式,即输出一个字典。相比直接使用大模型进行任务,微调后的模型更倾向于输出较短的文本,减少了对长文本的处理,提高了效率和稳定性。 后续优化思路:针对OCR部分,可以进一步提升准确率,特别是对手写字体、表格和有换行的文本的识别效果。 对于版面分析,目前的方法没有充分利用位置信息,可以根据要素的特定位置进行定位,提高抽取效率。此外,对于大模型的prompt设计,可以给模型提供解释和示例,以帮助模型更好地理解实体内容。最后,可以将实体抽取任务与阅读理解任务结合,将其转化为一个阅读理解任务,进一步提升模型的抽取能力。
第三名
第三名方案通过拆页、分块、后处理和构建QA问答对等步骤,对非标采购文件进行实体抽取。 在数据处理和模型选择方面,团队采用了简单有效的方法,并通过模型融合提高了准确性。


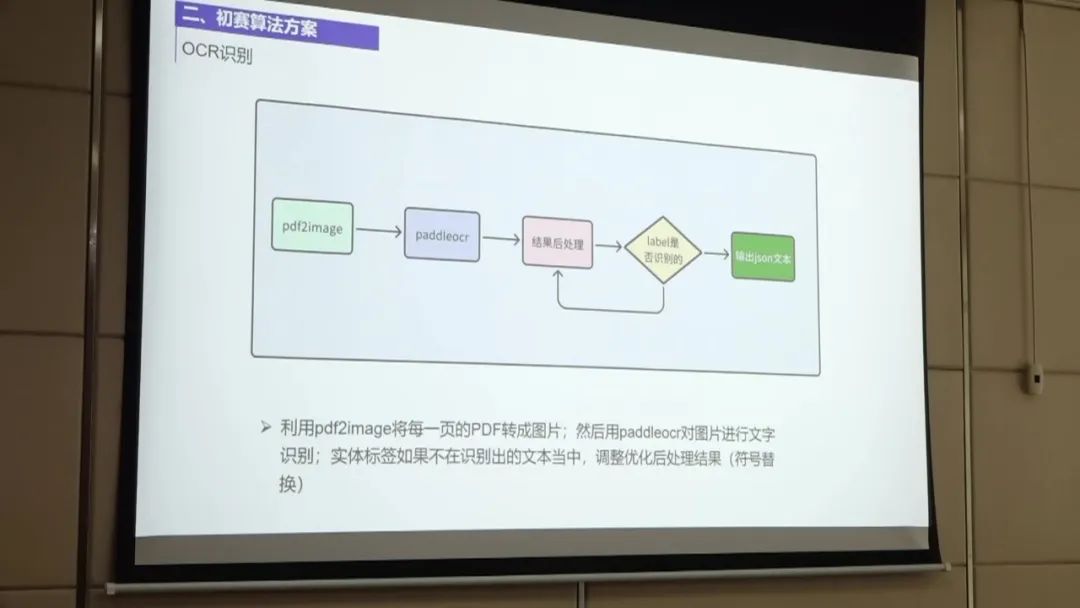

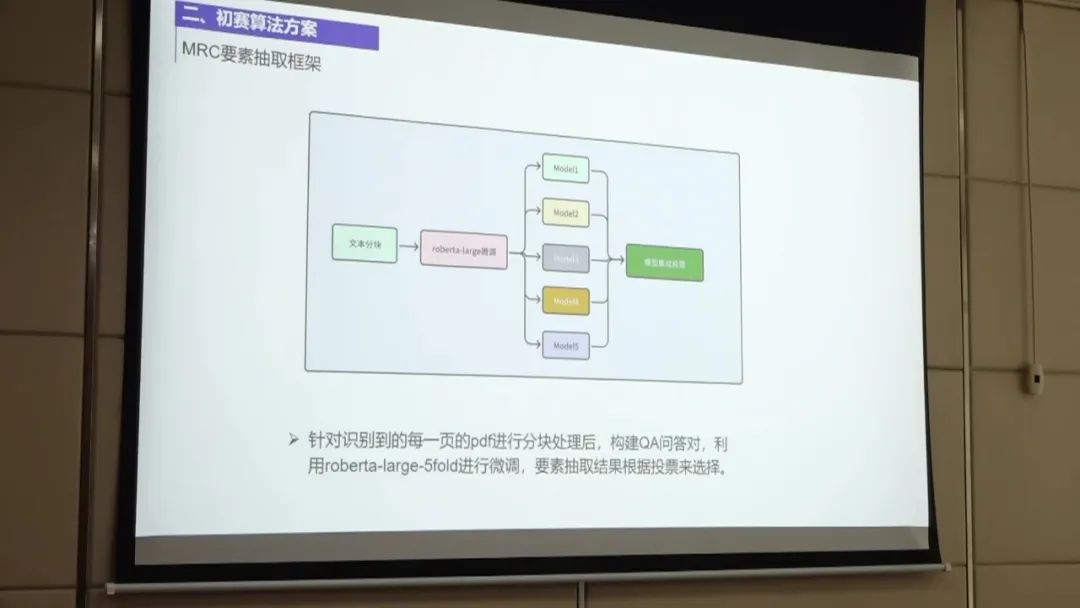
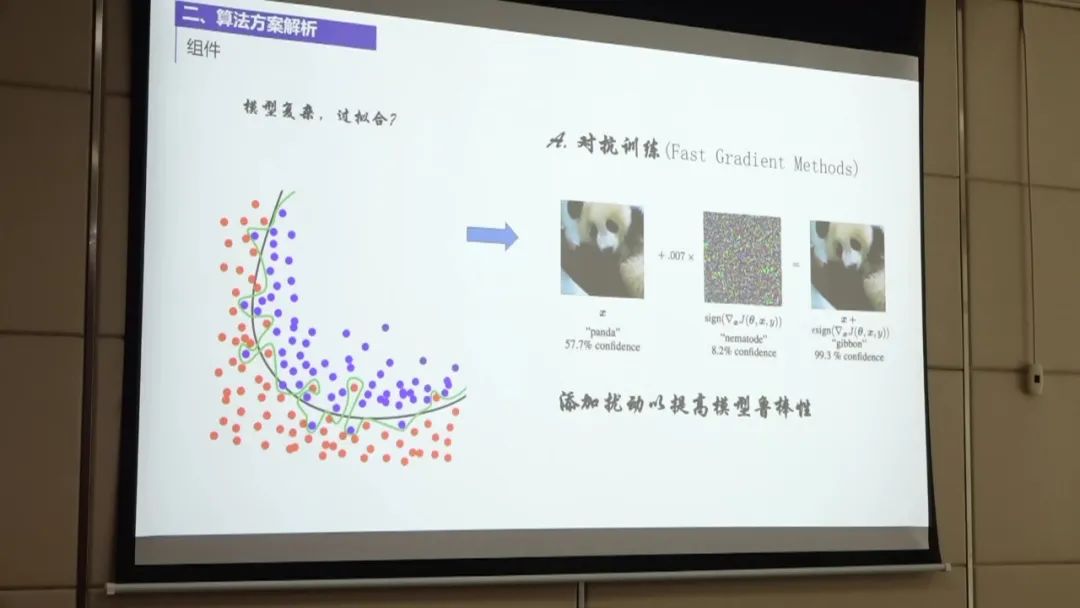
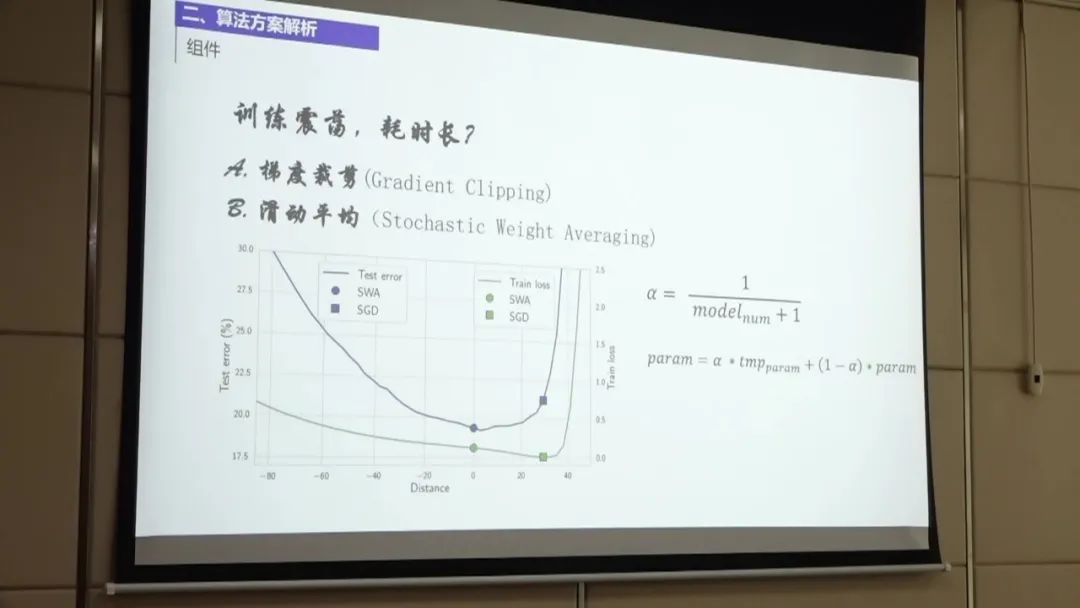
第三名的方案主要包括以下几个步骤:
数据预处理:首先,团队对非标采购文件进行拆页,将pdf文件拆分为单独的页码。然后,对每一页进行分块处理,将文本分成多个块,以便后续构建QA问答对。 OCR后处理:团队使用了开源的Paddle-OCR工具对识别结果进行后处理。主要优化了金额的识别,因为OCR可能会将金额中的点识别为逗号,需要进行转换。 此外,还对标点符号进行了优化,包括大小标点符号和中文英文符号的转换。通过这些后处理步骤,团队将OCR识别结果与训练级给出的标签对齐,准确率达到84%。 构建QA问答对:团队根据每一页的文本块构建QA问答对。对于每个文本块,团队取510个字符作为问题,并在上下文中多取100个字符以保留上下文信息。 这样可以避免后续抽取过程中的问题。对于一些较长的文本块,团队进行分块处理,以构建更准确的QA问答对。 数据处理和模型选择:团队在数据处理和模型选择方面采用了较为简单的方法。使用了NER模型进行分块和微调,并尝试了对抗训练和SWA方法进行模型优化。 在模型选择方面,团队发现五折和两折的效果差别不大,最终选择了五折的模型进行处理。 模型融合:在模型融合方面,团队将五折中的答案进行合并,并通过投票融合的方式选择投票数最高的答案作为最终结果。
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

