




由李开复博士带队创办的零一万物于 11 月正式开源发布首款预训练大模型 Yi-34B。根据 Hugging Face 英文开源社区平台和 C-Eval 中文评测的最新榜单,Yi-34B 预训练模型以黑马姿态取得了多项 SOTA 国际最佳性能指标认可,成为全球开源大模型“双料冠军”。
10 月下旬,Kyligence 发布了《数据分析场景下的大模型能力评测框架(Kyligence LLM Benchmark for Data & Analytics)》。我们使用该框架对 Yi-34B 大模型进行了一轮评测,结果发现 Yi-34B 表现突出,其可以在更小规模参数、更少算力资源的情况下获得更好表现,详情如下:
Yi-34B 比一些参数规模更大的模型表现更佳,说明 Yi-34B 可以在更少算力之上有较好表现
在评测综合表现优异的大模型中,Yi-34B 是唯一的开源大模型
Yi-34B 在数据洞察方面表现突出,接近综合表现最好的 GPT-4
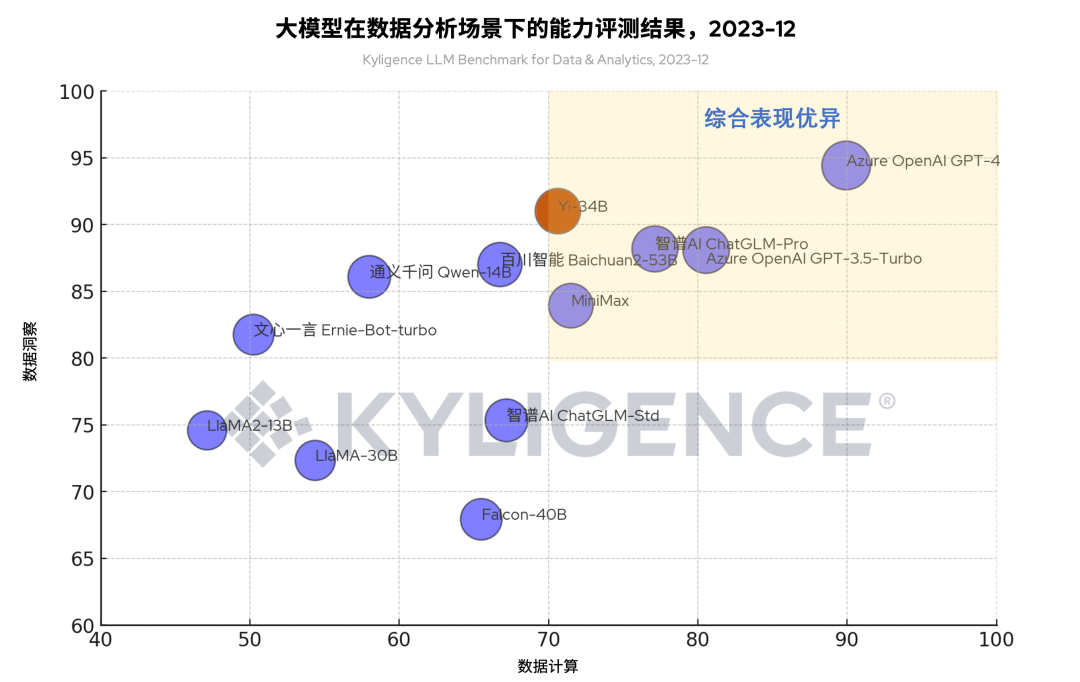
图 1 大模型在数据分析场景下的能力评测结果(棕色为 Yi-34B),2023-12
#01
关于评测框架

《数据分析场景下的大模型能力评测框架(Kyligence LLM Benchmark for Data & Analytics)》是由 Kyligence 推出的场景化大模型评测框架。这套框架是基于 AI 数智助理 Kyligence Copilot 在实际开发、落地等过程中总结的实际场景,从数据计算、数据洞察 2 个角度,共设置意图识别、指标匹配、代码生成(SQL)、代码生成(指标)、图表推荐、洞察生成、报告撰写等 7 个评测维度,对各个大模型进行实测评分。
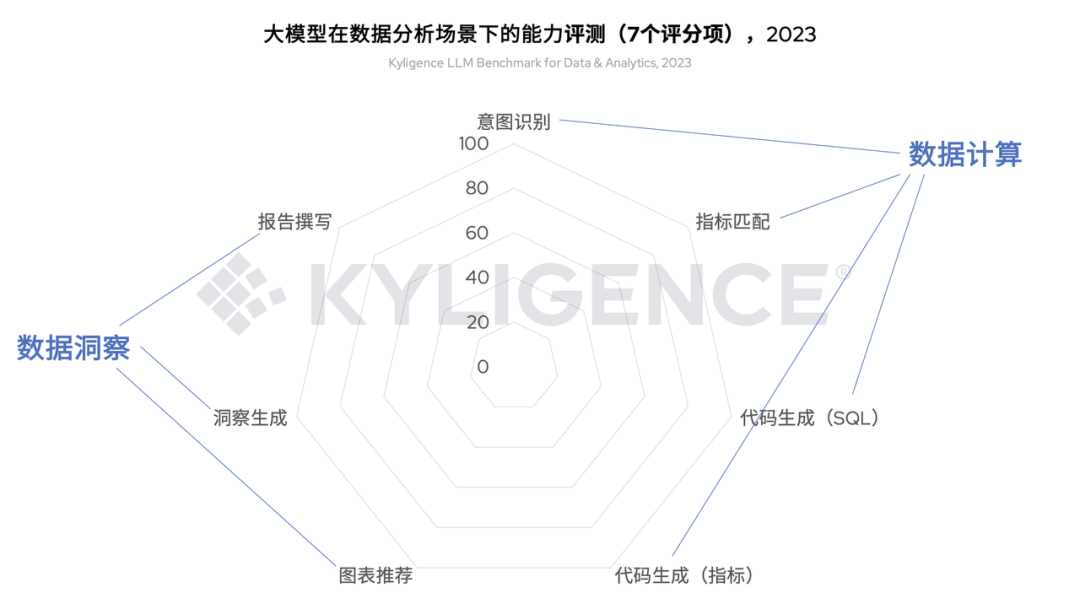
图 2 大模型在数据分析场景下的能力评测维度,2023-12
相比上一轮评测,我们在本轮新增了 Yi-34B、Llama-30B 两个模型。另外,由于测试数据集更新迭代,我们也对上一轮评测的大模型进行重跑,包括 Azure OpenAI GPT-4、Azure OpenAI GPT-3.5-Turbo、智谱 AI 的 ChatGLM-Pro 和 ChatGLM-Std、百川智能 Baichuan2-53B、通义千问 Qwen-14B、文心一言 Ernie-Bot-turbo、MiniMax、开源 Falcon-40B 和 LLaMA2-13B 等大模型。最终各模型评测结果如下表所示:
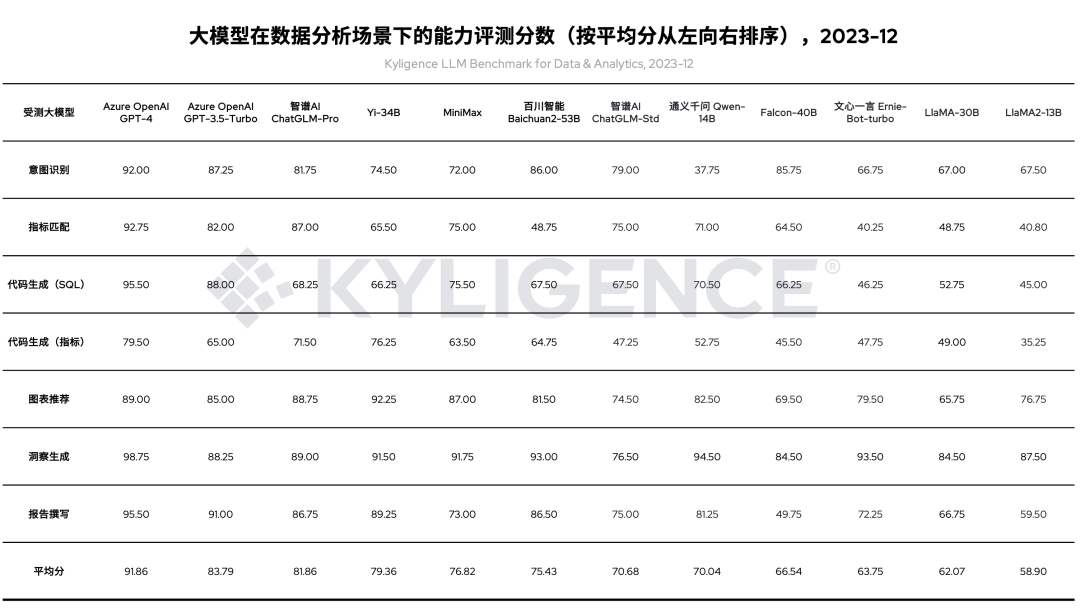
表 1 大模型在数据分析场景下的能力评测分数(按平均分从左向右排序),2023-12
#02
Yi-34B 评测分析
在本轮评测的众多大模型中,Yi-34B 位列前五,并归属于“综合表现优异”类别当中(如图 3 所示,综合表现优异类别位于右上象限)。根据这个评测结果,我们得出以下结论:
Yi-34B 比一些参数规模更大的模型表现更佳,说明 Yi-34B 可以在更少算力之上有较好表现
在评测综合表现优异的大模型中,Yi-34B 是唯一的开源大模型
Yi-34B 在数据洞察方面表现突出,接近综合表现最好的 GPT-4
图 3 大模型在数据分析场景下的能力评测结果(棕色为 Yi-34B),2023-12
接下来,我们从性价比、数据计算、数据洞察等多个角度进行更深入的分析。
1. 从“性价比”角度
从图 3 中可见,Yi-34B 和 Azure OpenAI GPT-4、Azure OpenAI GPT-3.5-Turbo、智谱 AI ChatGLM-Pro、MiniMax 等同属“综合表现优异”类别。但是在这几个模型中,Yi-34B 的参数规模最低,这说明 Yi-34B 对算力资源的要求更低,有助于节省硬件成本。除此之外,Yi-34B 是开源大模型,对于用户而言将节省模型采购费用,有助于降低整体成本(但还需考虑维护开源大模型所需的人力成本)。
图 4 所示为 30-40B 参数规模下部分开源大模型的评测结果对比,从结果可见,Yi-34B 比 LlaMA-30B、Falcon-40B 在数据分析场景下表现更优。
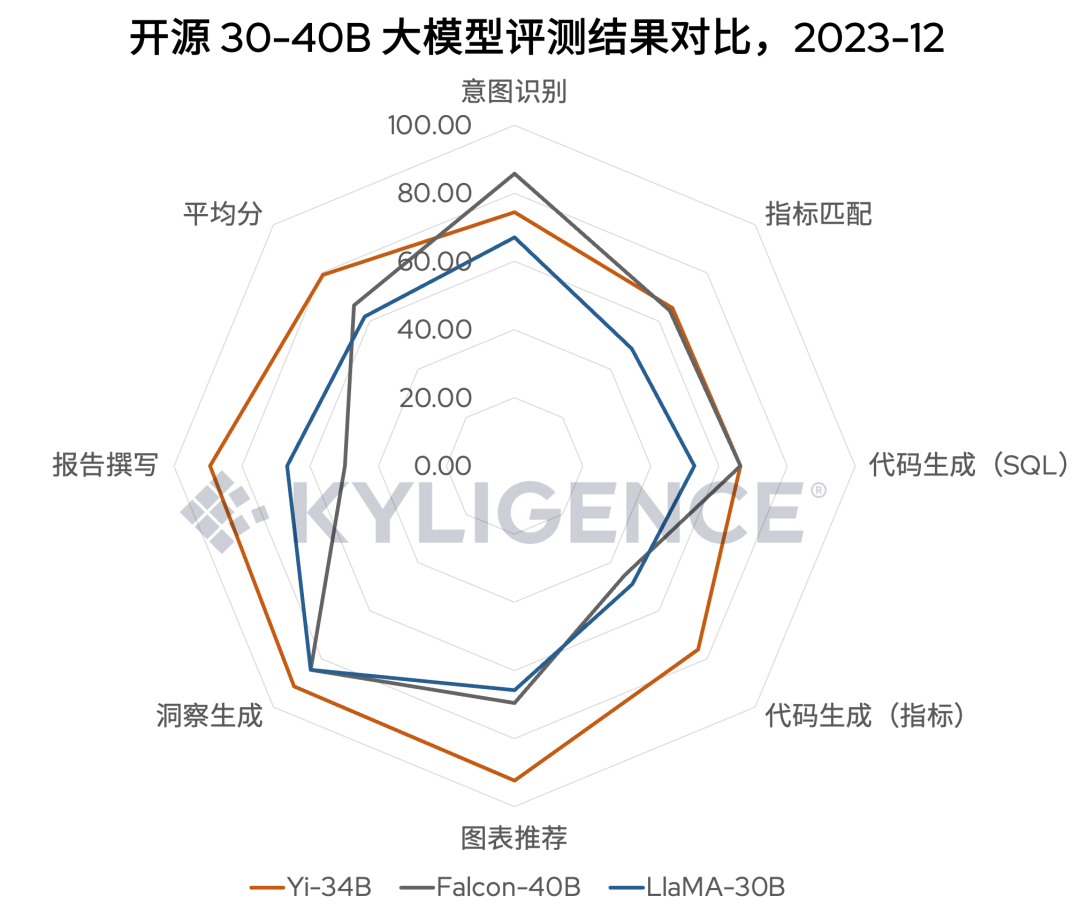
图 4 30-40B 参数规模下部分开源大模型的评测结果对比(棕色为 Yi-34B),2023-12
2. 从数据计算角度
从图 3 可见,Yi-34B 在数据计算角度的评分超过多数大模型,说明 Yi-34B 从理解用户意图到获取数据方面有较好的准确度保障。值得一提的是,图 5 是“代码生成(指标)”维度的评分,Yi-34B 在该维度分数较高,且超过 Azure OpenAI GPT-3.5-Turbo,仅次于综合表现最优的 Azure OpenAI GPT-4,这说明 Yi-34B 与指标平台集成来实现数据分析场景将有更好的表现。
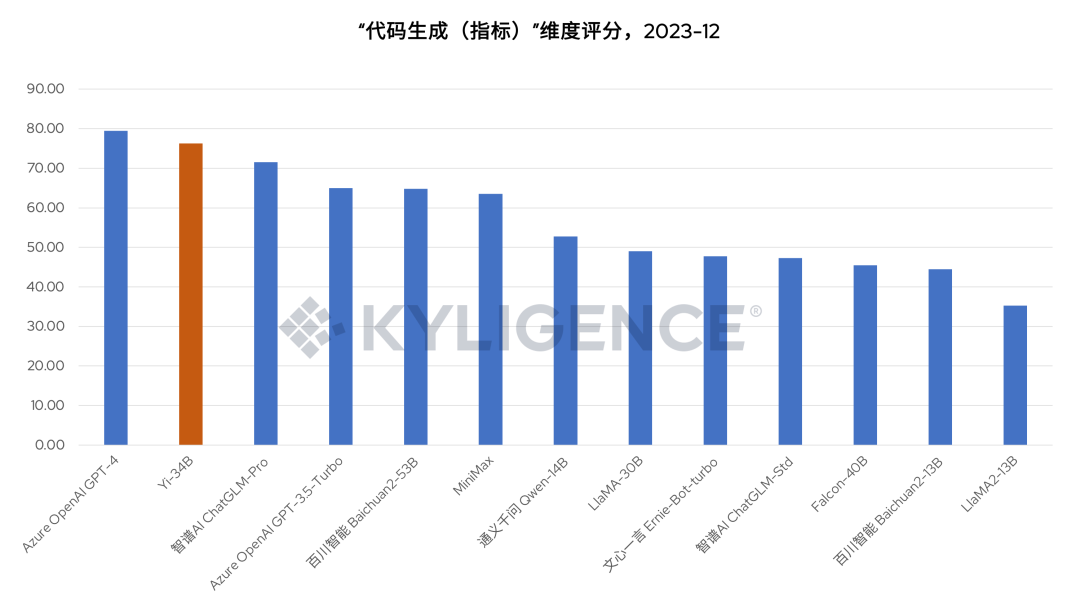
图 5 Yi-34B 与指标平台集成在数据分析场景表现更佳(棕色为 Yi-34B),2023-12
3. 从数据洞察角度
从图 2 可见,Yi-34B 在数据洞察的平均分超过多数大模型,接近综合成绩最好的 GPT-4,说明 Yi-34B 在获得数据结果后发现数据洞察、生成总结报告等方面,有相当出色的能力。尤其是“图表推荐”维度,如图 6 所示,Yi-34B 表现超过 GPT-4 位列第一,说明 Yi-34B 在根据数据特征推荐可视化图表等能力较为领先。
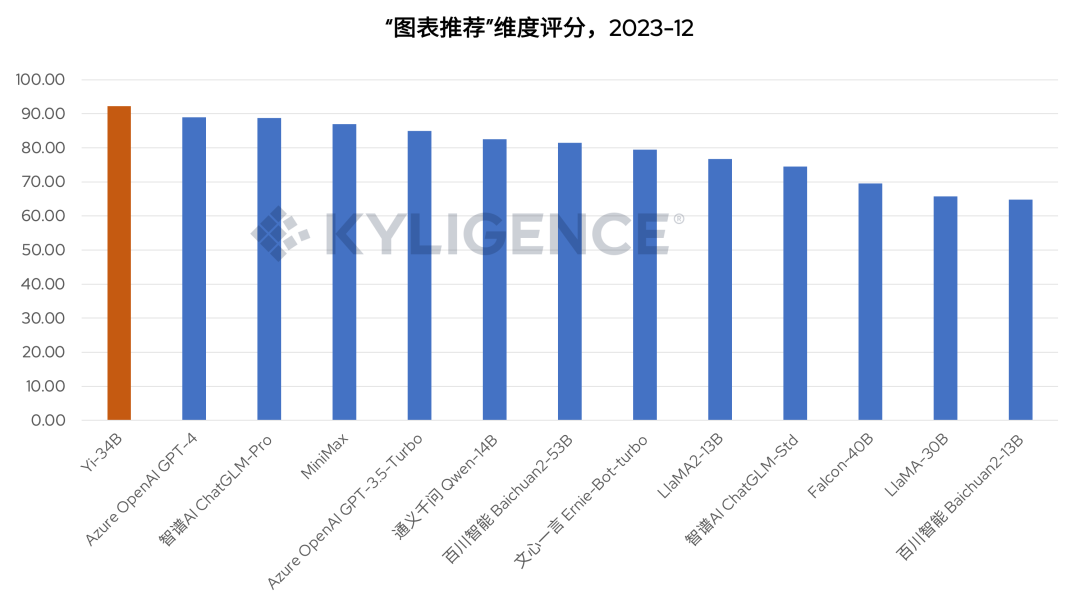
图 6 Yi-34B 在 “图表推荐”相关能力较为领先(棕色为 Yi-34B),2023-12
#03
Yi-34B 优化建议
1. 提升意图理解和指标匹配精准度
如表 1 所示,Yi-34B 在意图理解、指标匹配等方面表现欠佳,可能与预训练时使用的语料有关,为优化 Yi-34B 在该场景下的表现,可加入更多相关语料进行微调,以提升意图理解、指标匹配等过程的精准度。
2. 集成指标平台落地数据分析场景
如表 1 所示,Yi-34B 在“代码生成(指标)”维度评分比“代码生成(SQL)”维度评分更高,说明将该模型对接指标平台,并将用户的分析意图转化为访问指标平台的请求,将提升数据分析的准确性,因此建议企业落地时优先考虑这种架构。
#04
已知限制和情况说明
本次评测数据集基于 Kyligence Copilot 使用场景总结,可能不适用于企业所有数据分析场景
本次评测基于各大模型服务的默认配置,未进行任何调参;值得说明的一点是,对大模型服务进行调优可能进一步优化评测结果
本次评测针对不同大模型所使用的算力情况如下:
GPT-4 GPT-3.5-Turbo ChatGLM Baichuan2-53B MiniMax 文心一言均基于厂商提供的 SaaS 服务,算力资源不详
Yi-34B / Falcon-40B / LLaMa-30B / LLaMa2-13B / 通义千问 Qwen-14B 是基于对应的开源模型在实验室私有化部署了本地服务,算力为 4 块 NVIDIA RTX 4090 24GB 显卡
#05
结语
在本轮评测中,我们对 Yi-34B 大模型从不同角度进行深入评测和分析,并给出企业场景落地的优化建议。如果您正在对大模型进行技术选型,或正在探索大模型在数据分析场景的应用落地与优化方案,欢迎与我们联系沟通。

关于 Kyligence
跬智信息(Kyligence)由 Apache Kylin 创始团队于 2016 年创办,是领先的大数据分析和指标平台供应商,提供企业级 OLAP(多维分析)产品 Kyligence Enterprise 和智能一站式指标平台 Kyligence Zen,为用户提供企业级的经营分析能力、决策支持系统及各种基于数据驱动的行业解决方案。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售、医疗等行业客户,包括建设银行、平安银行、浦发银行、北京银行、宁波银行、太平洋保险、中国银联、上汽、长安汽车、星巴克、安踏、李宁、阿斯利康、UBS、MetLife 等全球知名企业,并和微软、亚马逊云科技、华为、安永、德勤等达成全球合作伙伴关系。Kyligence 获得来自红点、宽带资本、顺为资本、斯道资本、Coatue、浦银国际、中金资本、歌斐资产、国方资本等机构多次投资。

👇 点击「阅读原文」联系我们
