




01
分析型数据库实时数据变更的挑战
存储结构:很多分析型数据库采用列式存储,这种方式优化了读取性能,但在插入和更新数据时需要更多的开销。因为当一个新的记录插入或者一个旧的记录更新时,可能需要重写整个数据文件。
索引和预计算:分析型数据库通常使用复杂的索引结构和预聚合计算,如位图索引和查询改写。这些优化提高了查询性能,但也增加了数据更新的复杂性和成本。
数据分布和并行处理:在 MPP 架构中,数据被分布在多个节点上,查询可以在这些节点上并行执行。这种分布式处理提高了查询性能,但在数据更新时可能需要跨节点同步,这可能会引入延迟。
02
StarRocks 做了哪些改进
自适应更新模式:维持列存的结构下,实现了列模式的更新方式。在整列更新的场景下只重写被更新的列,而不需要整行数据全部重写,极大的降低了数据更新时的 I/O 开销。
主键索引:基于主键的 bitmap 索引结构支持在查询和更新时可以高效的定位到某行数据所在的位置,配合 delete vector 可以实现基于主键数据的高效检索和更新。
主键索引落盘:在一定时间内没有被访问的主键索引会进行落盘操作,降低索引的内存占用。
03
Primary Key 更新原理
Copy on Write. 当一批更新到来后,需要检查其中每条记录跟原来的文件有无冲突(或者说 Key 相同的记录)。对有冲突的文件,重新写一份新的、包含了更新后数据的。这种方式读取时直接读取最新数据文件即可,无需任何合并或者其他操作,查询性能是最优的,但是写入的代价很大,因此适合 T+1 的不会频繁更新的场景,不适合实时更新场景。
Merge on Read.当一批更新到来后,直接排序后以列存或者行存的形式写入新的文件。由于数据在写入时没有做去重或者说冲突检查,就需要在读取时通过 Key 的比较进行 Merge 的方式,合并多个版本的数据,仅保留最新版本的数据返回给查询执行层。这种方式写入的性能最好,实现也很简单,但是读取的性能很差。
Delta Store.当一批更新到来后,通过主键索引,先找到每条记录原来所在的文件和位置(通常是一个整数的行号)。把位置和所做的修改作为一条 Delta 记录,放到跟原文件对应的一个 Delta Store 中。查询时,需要把原始数据和 Delta Store 中的数据进行 Merge。这里牺牲了部分写入性能来换取读取性能。
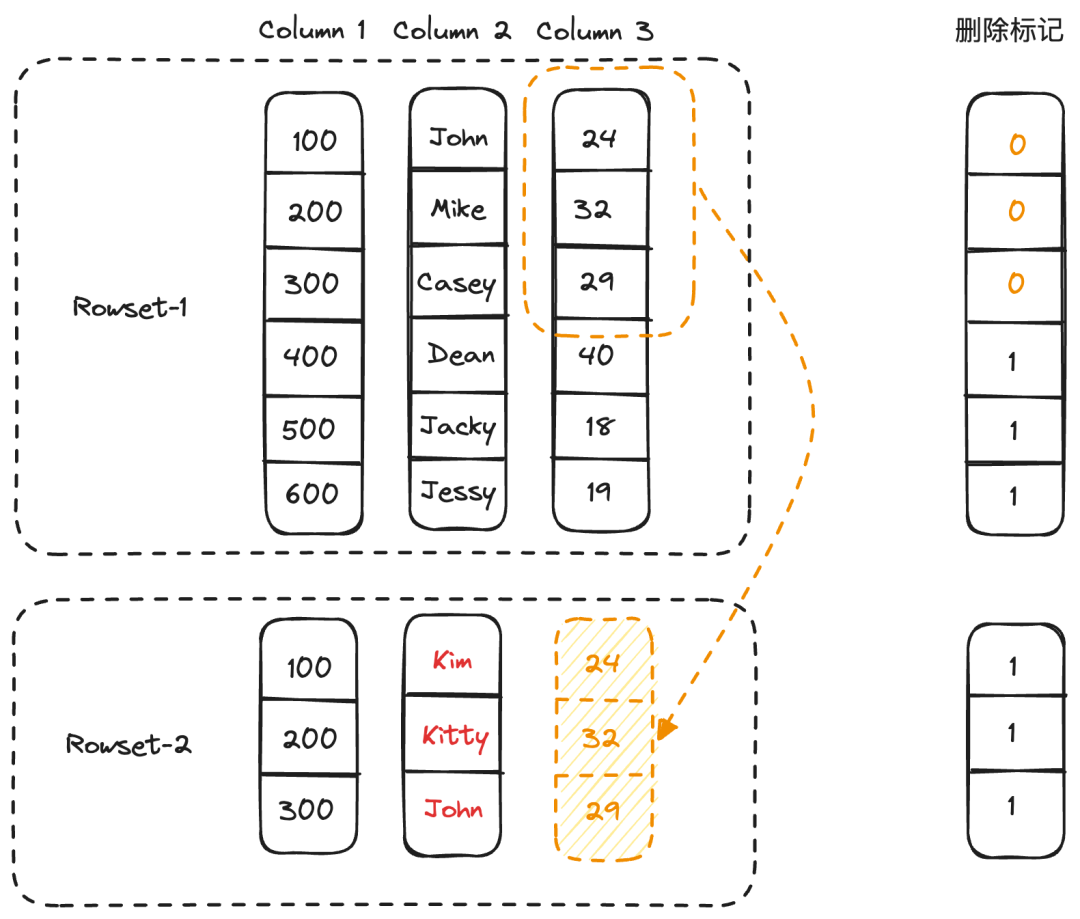
首先,我们通过 roaring bitmap 来管理和存储每一个列存文件对应的删除标记。比如一个文件中有 10000 行数据,其中 200 行被标记删除,则可以使用一个 bitmap 来标记被删除的行。一般都是很稀疏的,使用 roaring bitmap 可以高效存储和操作。roaring bitmap 在存算一体架构下会被存储到 Rocksdb 里,而在存算分离架构下则会被记录到对象存储文件中。同时,roaring bitmap 也会被缓存在内存中以便能够快速访问。 接着,我们引入了主键索引来保存主键到该记录所在位置的映射,用于在数据导入和删除过程中生成列存文件对应的删除标记。我们提供了两种不同的主键索引实现: 全内存索引。索引数据在数据导入进行时按需构建,一段时间没有持续导入时又会释放以节约内存。比较适合对于更新延迟有更高要求的场景。
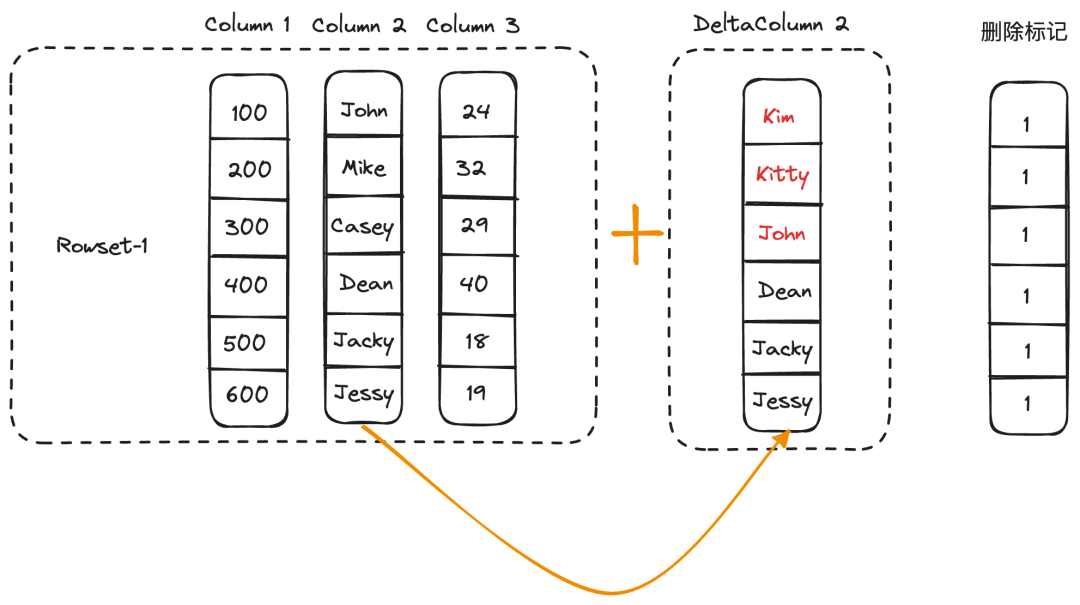
持久化索引。可以允许把部分索引数据持久化到磁盘以节约内存占用。针对当前主键索引的使用特点,比如批量操作,无并发,不需要范围查询等特点,我们设计了一套类似 LSM 的分层存储和 compaction 的机制的存储引擎,数据在文件中按 hash 分布编码。持久化索引做到了在节约内存的同时,查询和更新性能几乎接近全内存索引。 除了正常的全列更新和删除操作之外,主键模型还支持了部分列更新的能力。针对不同的数据更新场景,我们提供了两种不同的部分列更新实现,在不影响查询性能的同时,尽可能地降低部分列更新的开销,从而能够保证更新的实时性。 行模式。行模式比较适用于小批量的实时更新场景。实现方式是,在数据导入阶段,先生成只包含部分列数据的列存文件,到了事务提交阶段,通过主键索引找到对应行缺失的列数据,并回填到刚才生成的列存文件中,生成完整的列存文件。如下所示,部分列更新想要将<100, John>,<200, Mike>和<300, Casey>更新为<100, Kim>,<200, Kitty>和<300, John>,因此需要从 Column3 中读取对应的缺失列数据,并且将之前的行标记删除。 列模式。列模式适用于大批量的批处理更新场景。实现方式是,通过主键索引找到被更新的记录所在的源列存文件,读取文件中的原始列数据,在和更新数据合并之后生成和源列存文件一一对应的部分列文件,在元数据中建立文件之间的映射。在执行查询时,由于无需做 Merge 操作,因此不会影响查询性能。如下图所示,我们重新生成了对应 Column2 更新之后的 DeltaColumn2 列文件,后续在构建 Iterator 时,会使用DeltaColumn2 替换 Column2。
1/C%1/R%04
Primary Key 更新方式
01
01
02
02
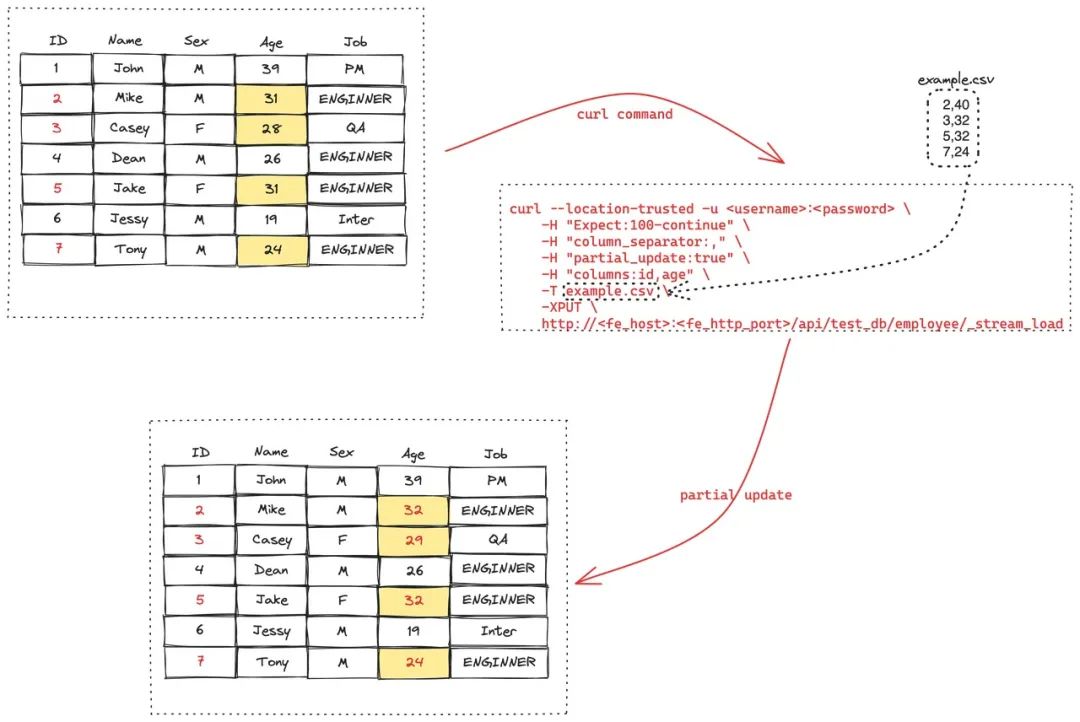
2,40
3,32
5,32
7,24
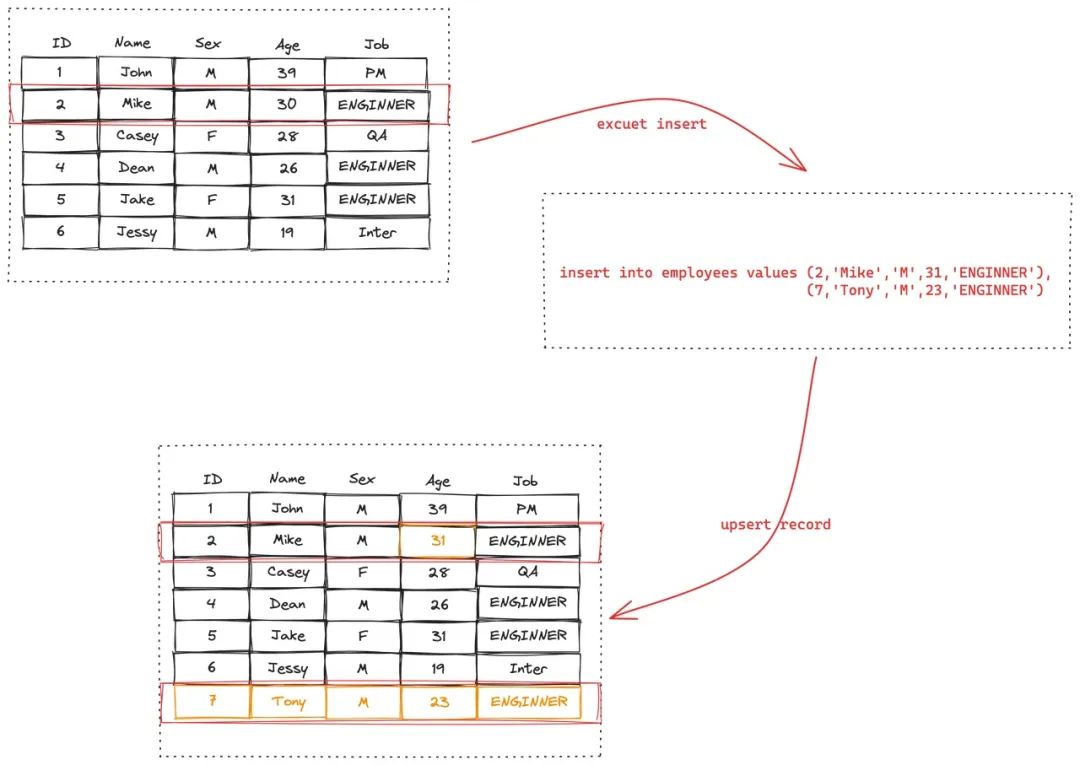
update employee set age = age+1 where id in (2,3,5,7)
03
03
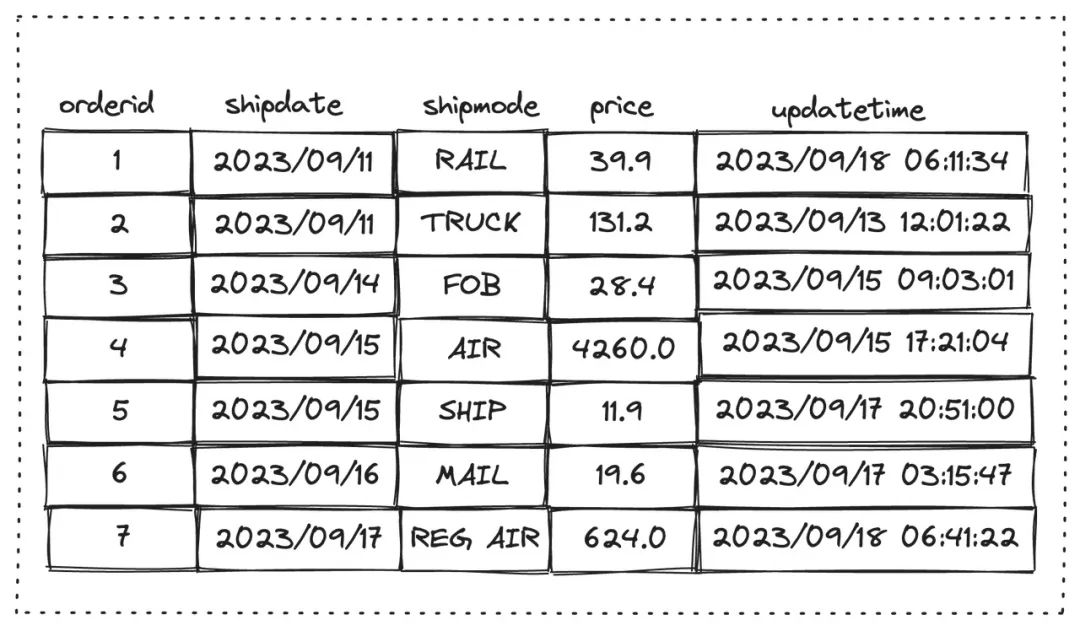
4,2023/09/15,AIR,4260.0,2023/09/18 00:21:04
6,2023/09/16,FOB,19.6,2023/09/18 00:15:47
7,2023/09/17,TRUCK,624.0,2023/09/18 00:41:22
8,2023/09/18,REG AIR,22.0,2023/09/18 10:01:27
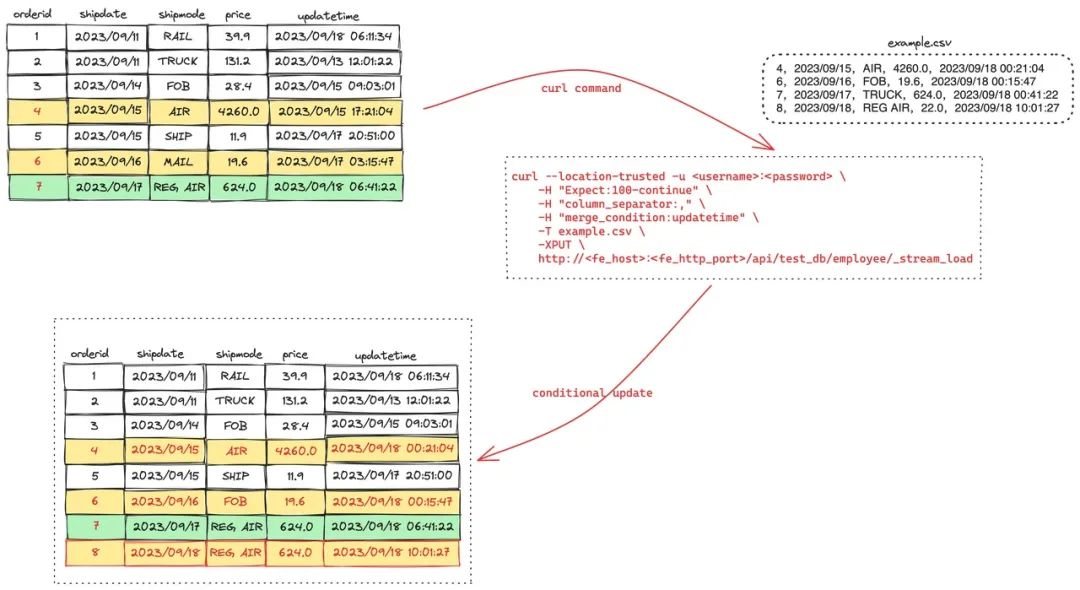
04
04
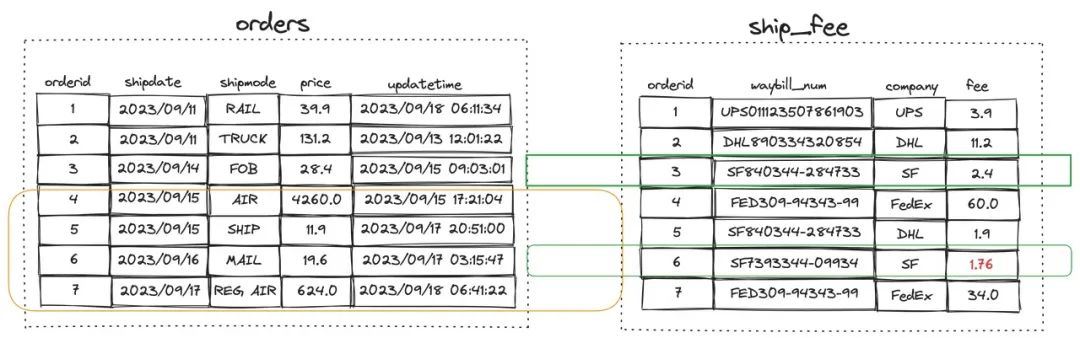
在 where 条件中使用 from 从句,实现单表或多表关联的数据更新
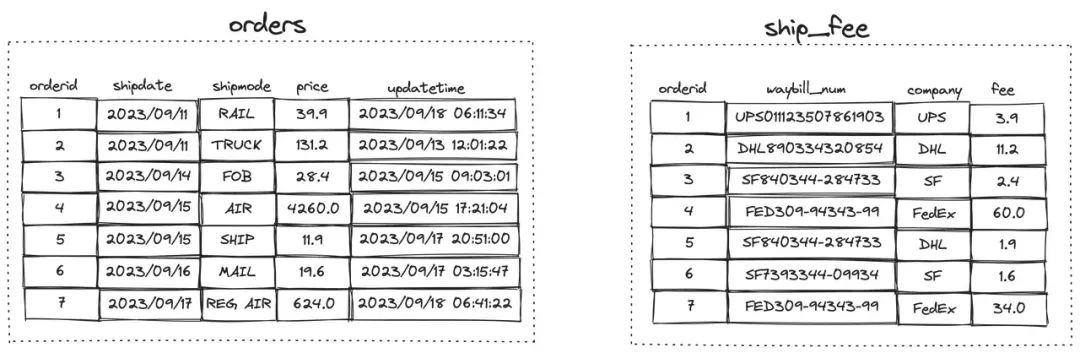
UPDATE ship_fee
SET fee = fee * 1.1 --Increase by 10%
FROM orders
WHERE orders.shipdate >= '2023/09/15'
AND ship_fee.company = 'SF'
AND ship_fee.orderid = orders.orderid;
使用 CTE
WITH increase_fee as (
SELECT * from orders
WHERE orders.shipdate >= '2023/09/15'
)
UPDATE ship_fee SET fee = fee * 1.1 --Increase by 10%
FROM increase_fee
WHERE ship_fee.orderid = orders.orderid
AND ship_fee.company = 'SF';
关于 StarRocks


文章转载自StarRocks,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
