






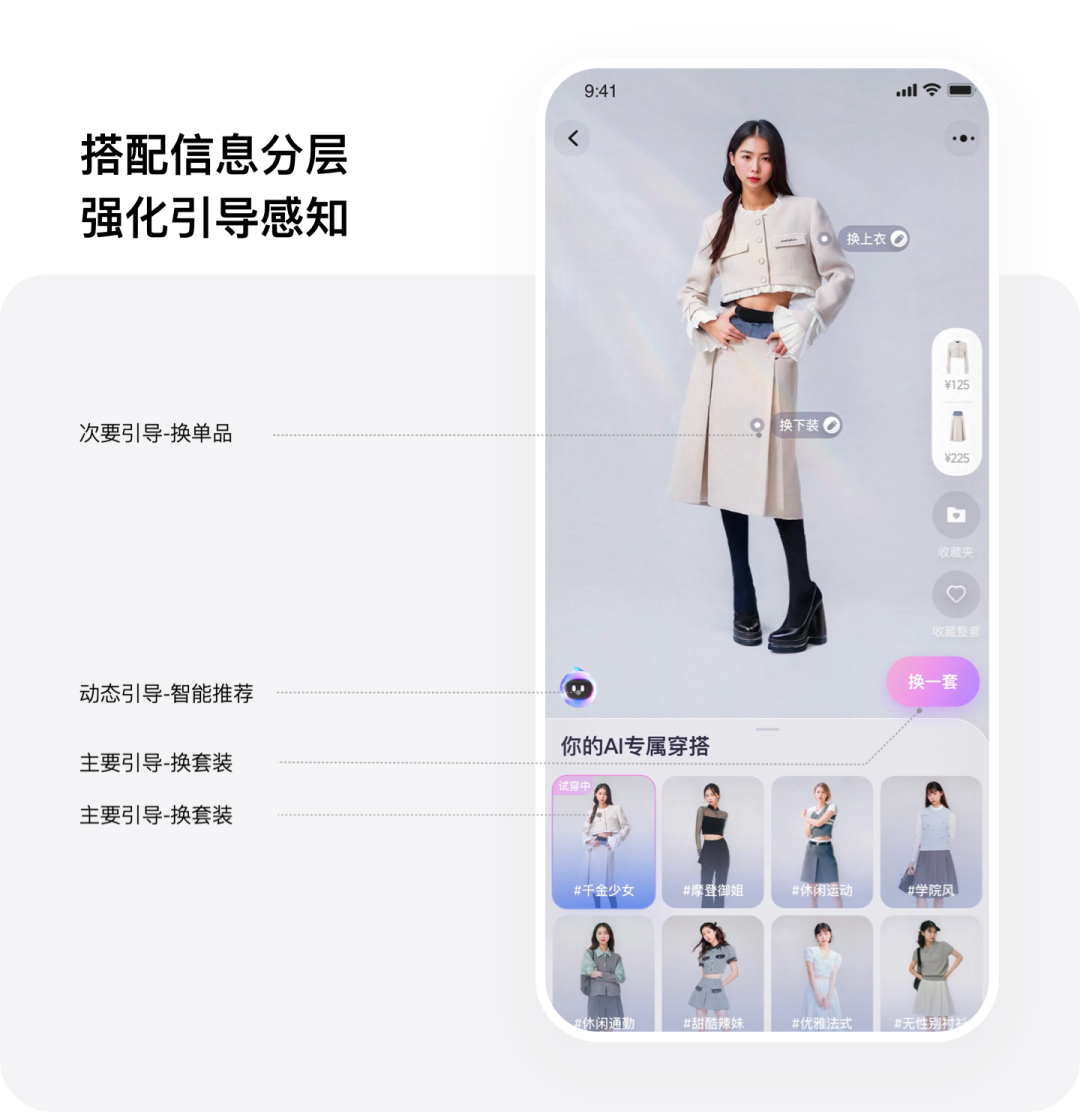
 ifashion,上传自己的照片即可体验AI试衣~
ifashion,上传自己的照片即可体验AI试衣~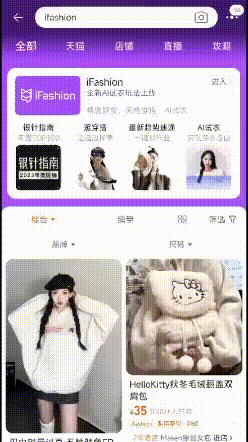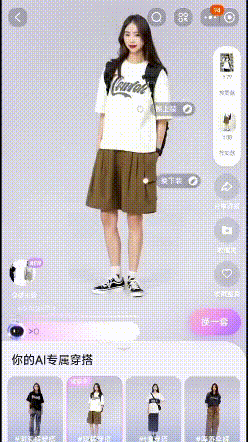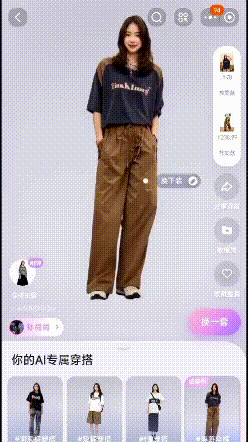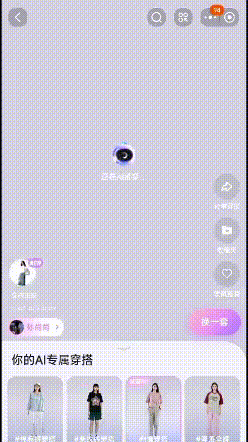

在AI试衣间功能的背后,阿里云瑶池旗下的云原生数据仓库AnalyticDB MySQL提供了高维向量低延时的在线向量召回检索服务,下面将进行介绍。

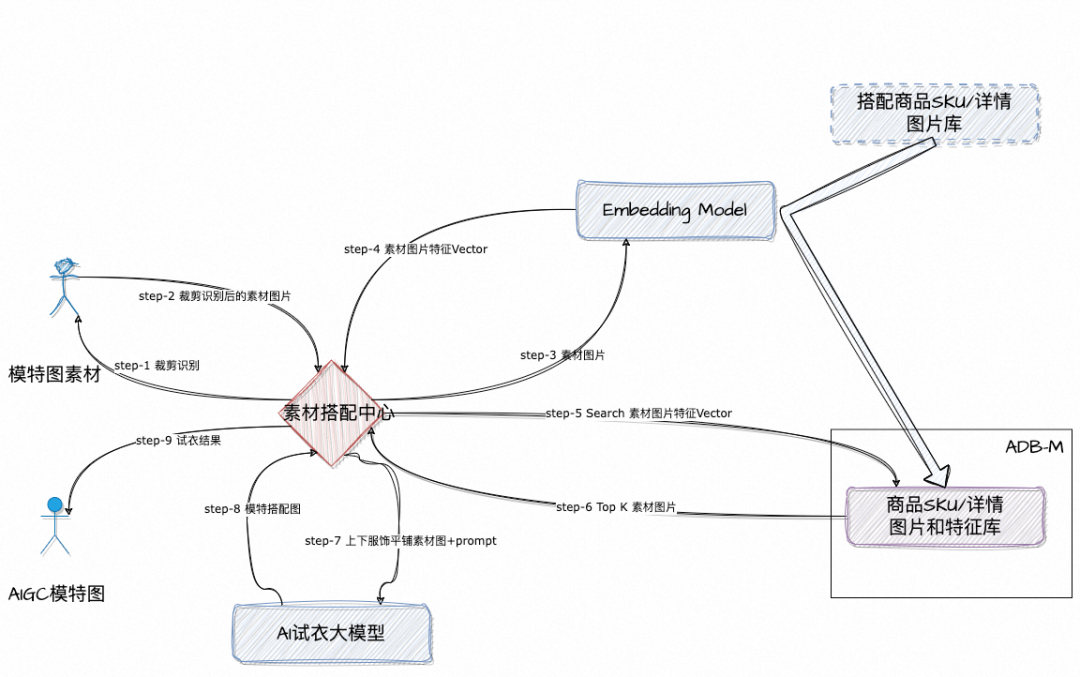
AnalyticDB MySQL可以管理和检索图片素材,可以根据商品图片类别,属性或者相似图片做多模检索图片,在支持图片相似性检索的同时,同时支持和结构化数据的标量融合,包括多表的关联查询。例如,检索和输入图片相似,并且满足价格在200-300元之间和3个月内(新款)上架的商品照片。为了方便展示,假设向量的维度使用了8维长度。
数据模型
CREATE TABLE products (product_id BIGINT COMMENT '商品ID',gmt_create DATETIME COMMENT '创建时间',gmt_modified DATETIME COMMENT '修改时间',image_url VARCHAR COMMENT '商品图片地址',price FLOAT COMMENT '商品价格',document JSON COMMENT '知识文档,json结构',status INT COMMENT '文档状态, 1审核通过,0未审核,-1审核不通过',feature ARRAY <float>(8) COMMENT '商品图片向量结果',PRIMARY KEY (product_id, gmt_create),ANN INDEX idx_feature(`feature`)) DISTRIBUTE BY HASH(product_id) PARTITION BY VALUE(`date_format(gmt_create, '%Y%m')`) LIFECYCLE 36 INDEX_ALL = 'Y';
准备数据
INSERT INTO products (product_id, gmt_create, price, image_url, feature)VALUES(6, NOW(), 288.00, 'https://xxx/img6.jpg', '[0.83891445,0.50359607,0.9299093,0.19440076,0.5789051,0.12121256,0.6587046,0.86555034]');
数据检索(向量召回)
上述条件2和3是结构化数据标量数值计算,条件1是非机构化相似性计算。业务场景期望3个条件可以在1个引擎同时完成,达到提升效率和降低维护成本的作用。这种场景通过AnalyticDB能够很方便支持,使用也很简单。
SELECT product_id, l2_distance(feature, '[0.83891440,0.50359607,0.9299093,0.19440070,0.5789051,0.12121256,0.6587046,0.86555034]') as dis, image_url, price, documentFROM productsWHERE l2_distance(feature, '[0.83891445,0.50359607,0.9299093,0.19440076,0.5789051,0.12121256,0.6587046,0.86555034]') < 10 -- 设定相似性阈值,排除一些差异性太大的结果AND gmt_create > DATE_SUB(NOW(), INTERVAL 90 DAY) -- 最近90天AND price between 200.00 and 300.00 -- 价格在200-300之间ORDER BY l2_distance(feature, '[0.83891445,0.50359607,0.9299093,0.19440076,0.5789051,0.12121256,0.6587046,0.86555034]')LIMIT 5; -- 最相近的top5
AnalyticDB MySQL除了提供实时OLAP多维分析和检索外,还提供向量召回功能,支持淘宝APP的AI试衣间场景,解决了引擎冗余的问题,把结构化数据和非结构化数据检索能力整合,适用于多模混合负载检索场景,降低了向量的使用和运维成本。
1. 人脸识别服务,支持高维人脸识别。
2. 以图搜图服务,即通过图片检索图片的应用服务。
3. 视频检索服务,即通过视频中的某些帧图片进行视频图片检索,来实现视频检索。
4. 声纹检索服务,即通过音频匹配音频的应用服务。
5. 推荐系统服务,即通过用户特征匹配实现推荐匹配的功能。
6. 基于语义的文本检索和推荐,通过文本检索近似文本。
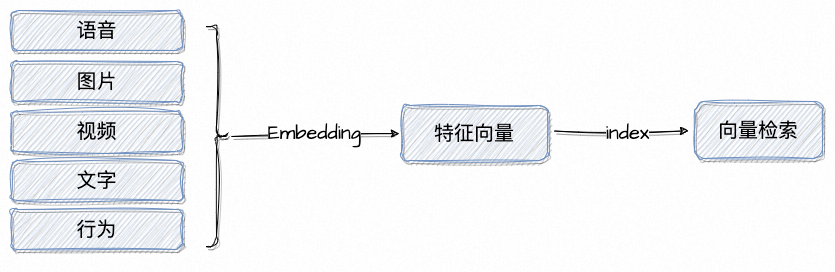
为了实现特征向量的快速检索,一般都会构建向量索引来实现。通常说的向量索引都属于ANNS(Approximate Nearest Neighbors Search,近似最近邻搜索),它不同于数字的等值或者字符串的term匹配,也不同于like或者全文检索的近似匹配,而是在最大程度上通过非结构化数据的相似度进行检索。
ANNS向量索引可以根据实现方式的不同区分为不同类型的索引,主要分为图索引和量化索引,其中图索引主要是HNSW和RNSW,量化索引主要是PQ、FLAT、SQ8和SQ8H等。为了能使ANNS向量索引能够更加方便地应用到实际的生产环境中,目前业界主要有两种实践方式。一种是单独将ANNS向量索引服务化,以提供向量索引创建和检索的能力,从而使其成为人工智能服务体系中的一部分;另一种就是在传统结构化数据库的基础之上,去融合ANNS向量索引的能力,从而使其能直接使用简单的SQL就能完成复杂的结构化数据检索,也能同时具备结构化与非结构化融合查询的能力。
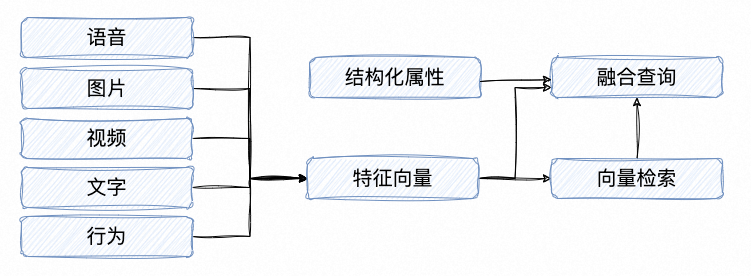
云原生数据仓库AnalyticDB MySQL是一款阿里云数据库团队自研的云原生数据仓库产品,支持向量和结构化数据的融合检索,在各种条件组合的查询的场景中,达到超过99%的召回率。它的数仓和湖仓提供了非结构化数据的存储和通用数据库检索服务。通过深度学习网络完成推理,可以将非结构化数据转化成向量,提供基于向量的相似性检索。
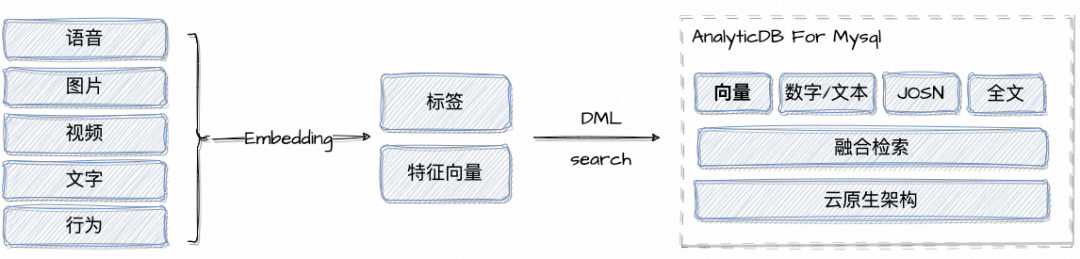
▶︎ 向量服务的Embedding服务可以支持插件式,提供Serverless/Function的向量Embedding服务,支持根据不同的业务场景选择不同的Embedding模型。
▶︎ 在相似度的召回率上提供可配置的选项,支持在QPS和召回率之间做一个更自主的灵活配置。例如除了支持人脸,声纹等需要高正确率的检索,也需要支持图片等素材更需要弹性的检索。



 点击 阅读原文 查看 云原生数据仓库AnalyticDB 更多内容
点击 阅读原文 查看 云原生数据仓库AnalyticDB 更多内容