




赛题名称:中文空间语义理解评测 赛题类型:实体标注、关联分析 比赛官网:https://2030nlp.github.io/SpaCE2023/ 比赛数据集:https://github.com/2030NLP/SpaCE2023/tree/main/data
赛题介绍
空间范畴是人类认知中重要的基础范畴。理解文本中的空间信息不仅需要掌握词汇、句法语义知识,还需要用到常识或背景知识,调动认知能力来构建空间场景。
空间语义理解在自然语言处理领域受到了广泛关注,导航、文景转换等应用都要求机器能够理解自然语言中的空间信息。具备空间语义理解能力的机器应该能够判断空间信息的正常或异常与否,如“跳进”必须搭配一个表示空间内部方位的成分,所以“跳进山洞中”是正常的空间信息,“跳进山洞外”则存在异常。此外,机器还应该有能力将不同文本中全部的空间信息结构化地提取出来,并区分文本中空间场景的异同。
为了评测机器的空间语义理解能力,推进空间范畴的认知计算建模研究,我们于 2021 年开始连续两年举办了中文空间语义理解评测任务(Spatial Cognition Evaluation,简称 SpaCE)。今年,我们继续推出第三届中文空间语义理解评测(SpaCE2023),包含如下 3 个子任务:
子任务1,空间语义异常识别:识别给定中文文本中空间语义信息异常的文本片段。 子任务2,空间语义角色标注:基于给定的空间关系标注规范,对给定中文文本进行空间实体的识别与空间方位关系标注。 子任务3,空间场景异同判断:阅读两个在形式上相似且都包含空间场景信息描述的中文文本,对它们是否可以描述相同的空间场景进行判断,并说明判断的理由。
评测任务
子任务一:空间信息异常识别
子任务一的输入是一个存在空间信息异常的文本,如“我清晨去公园散步时,总能看见他站在电线杆里,手里提着菜篮”中,“他”的空间方位存在异常。按照常识,人只能站在电线 杆周围的区域,而不能在电线杆的内部。
机器需要使用S-P-E标注法描述并输出异常文本片 段,S指描述了空间方位信息的实体,P指空间实体的空间方位信息,可能涉及处所、起点、方 向等信息,E指空间义相关事件,是动词性单位,表达了S之于P的方式、目的或原因,如[S他, P在电线杆里, E站]。
文本片段的选取数量最多6个,即两个完整的S-P-E三元组;最少1个, 即S-P-E中的单个元素。表1 展示了对应数量的标注情形和示例,S1、P1、E1、S2、P2、E2是 具体使用的标签。
子任务 1 的输入包含 2 个部分:
qid:数据编号; context:存在空间语义异常的文本。
子任务 1 的输出包含 2 个部分:
qid:数据编号; results:异常文本片段。为了描述空间语义异常,最多可以选取 6 个文本片段,最少可以选取 1 个。每个文本片段包含 3 个字段,分别是角色(role)、文本内容(text)和字序数组 (idxes)。role的取值包括 S1 P1 E1 S2 P2 E2
,当文本片段个数不大于3时,role的取值包括S1 P1 E1
。
子任务二:空间语义角色标注
子任务二的输入是一段空间信息表述正常的文本,如“我清晨去公园散步时,总能看见 他站在电线杆下,手里提着菜篮”中,描述了“我”、“他”、“菜篮”的空间信息。
机器需要使 用STEP标注体系描述并输出文本含有的所有空间信息,STEP标注体系在S-P-E标注法的基础 上增加了时间信息(T)和空间事实性(F)的标注,描述的信息可概括为:“某空间实体在某 时,经由某事件,处于某种空间方位关系,这一命题的事实性为真/假”。该体系共含15个元 素,表2 是每个元素的含义。
子任务 2 的输入包含 2 个部分:
qid:数据编号; context:待标注的文本。
子任务 2 的输出包含 2 个部分:
qid:数据编号; results:空间实体及其空间方位信息,描述了“某空间实体在某时,经由某事件,满足某种空间方位关系,这一命题的事实性为真/假”的信息。共有 15 个语义角色(role)可供标注,
子任务三:空间场景异同判断
子任务三的输入是两个包含空间场景描述的文本。两个文本在形式上存在差异,除去差异 字符串,两个文本的其他部分完全相同,如“他站在电线杆下”和“他站在电线杆旁”只有方位词 不同。机器需要判断两个文本是否可以描述相同的空间场景,并输出一段文本,内容包含列出 差异字符串、说明空间场景相同或不同的理由。
子任务 3 的输入包含 3 个部分:
qid:数据编号; context1:包含空间场景信息描述的文本; context2:包含空间场景信息描述的文本。context1 和 context2 存在差异文本 C1 和 C2,它们在形式上存在差异。C1 和 C2 都是连续字符串,是合法的语言单位(词、词组、子句等),意义清晰且相对完整。context1 去除 C1 后剩下的部分,和 context2 去除 C2 后剩下的部分,在形式上完全相同。
子任务 3 的输出包含 2 个部分:
qid:数据编号; results:对两个文本空间场景异同的判断(judge)和理由(reason)。两个文本描述的空间场景相同时,judge 字段的值为"true",反之为"false"。reson 字段填写空间场景相同或不相同的理由,生成的内容至少涵盖以下三个部分: 指出 context1 和 context2 的差异文本 C1 和 C2; 判断C1和C2是否造成了空间场景的差异;
评测结果
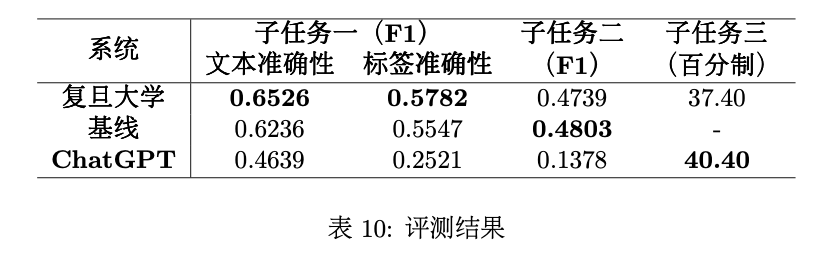
SpaCE2023共有12支队伍报名,最终1支队伍提交了测试结果。课题组也开发了子任务一、子任务二的基线系统,并测试了大语言模型GPT-3.5版本的应用ChatGPT在三个任务上的表现。
子任务一的模型与方法
复旦大学的参赛系统4使用阅读理解任务的范式来完成子任务一,将任务简化为对六个 文本片段的抽取,每个文本片段对应于一个标签。他们采用了deberta-chinese-large这个中文预训练模型,并对该抽取任务做微调,预测每个异常文本片段的开头和结尾。当 抽取的片段数量不足六个时,模型会把位置指向文本开头设置的标记。基线系统使用了预训练 模型BERT,采用了序列标注任务的范式,设置了一个序列标注层来判断每 个词所属的标签。
复旦系统的F1值略高于基线系统。具体到七种语料来源上,二者在人民日报、文学作品、 语文课本、体育文本以及其他上的表现仅相差1-4个百分点,但在地理百科上,复旦系统比基 线系统高出约10个百分点,在交通判决书上高出约50个百分点。
以“被告人宋某某驾驶牌号为 沪C9XXXX的小型轿车沿本区甘德路由东向西行驶至辰塔路向东右转”为例,抽取式的复旦 系统正确识别出[S1轿车, P1由东向西, E1行驶]和[S2轿车, P2向东, E2右转]的冲突之处, 而序列标注式的基线系统可能在子句较长的情况下,逐词标注会受到非目标词的干扰,标注 了“9X”、“轿车沿本”、“区甘”等不成词的片段。另外,在4-6个片段的数量上,基线系统也远 少于复旦系统。以6个片段为例,基线系统中仅出现了6次,而复旦系统出现了212次。
不过,序列标注式模型面对文本片段不连续的情况可能有一定的优势,如“塞到那个女学生座位四面”的 异常片段是“到四面”,复旦系统选取的区间包括了“那个女学生座位”,基线系统给出了“到生四 面”,更为接近答案。两个系统的文本准确性和标签准确性都仅约0.6,仍有待提高。我们考察了130道两个系 统的标签准确性都为0分的题目后,总结了机器表现较差的三个方面:1介词异常,如“骑自 (向)”、“由(从)头到脚”;2不常见但空间义正常的搭配,如“趴在窗户边”、“站在田埂 边”,机器认为这些搭配存在异常;3结合语境和常识才能发现的异常。比如,在上下文描述 房间内部环境的文本中,“房外又热又闷”存在异常。再如,“在蜂箱里忙碌的姚生”违反了人不 能在蜂箱内部的常识。这些异常机器都没有发现。
子任务二的模型与方法
子任务二中,复旦系统采用抽取加生成的方法,训练了一个deberta抽取器来抽取“空间实 体”元素,再训练一个CPT生成器(Shao et al., 2021)来生成剩余的元素。基线系统将子任务视 为事件抽取任务,先抽取触发词,即事件元素,再围绕触发词抽取与其相关的其他元素。
复旦系统的F1值接近但未超过基线系统。两个系统所采用方法的差别反映在空间实体的数 量差异上,复旦系统以空间实体为中心抽取其他元素,识别了2468个空间实体,而基线系统以 事件为中心抽取其他元素,不善于处理缺少触发词的元组,仅识别了1808个空间实体。测试集 共标注了3029个空间实体,其中约30%的元组缺少事件元素,从这一点看,以空间实体为中心 的抽取方法可能比较符合数据集的特点。
复旦系统仅考虑片段型元素,忽略标签型元素,没有输出事实性元素、距离标签和方向标 签。基线系统则没有输出时间标签和与距离关系有关的参照实体和距离元素。未来可进一步研 究标签型元素和低频元素的识别。
子任务三的指令与方法
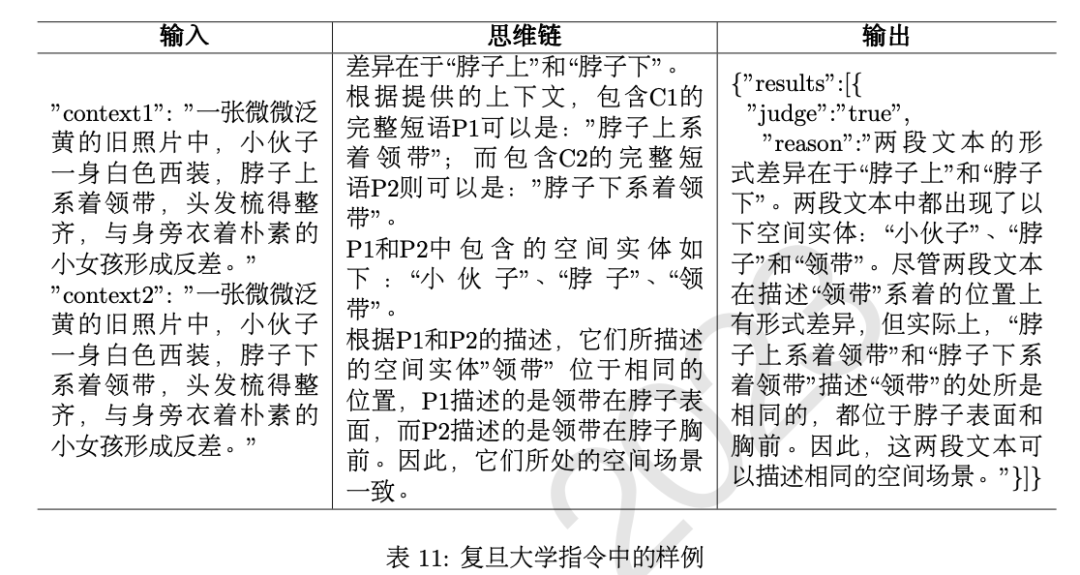
复旦大学使用了大语言模型来完成子任务三,在设计指令时结合COT(chain of thought,思维链)和few-shot方法,通过COT引导模型推理出更好的结果,然后提供1个空间场景相同的样例和1个空间场景不同的样例,帮助模型理解输出格式 以及推理的过程。
COT指令包含5个步骤:
找出两个文本的差异字符C1和C2; 找出差异字符所在的完整 短语P1和P2。有时仅凭差异文本不足以判断空间场景是否异同,所以扩展了判断空间; 找出短语中包含的空间实体; 判断空间场景异同; 选择模板进行输出。模板是课题组提供的参考模板。
两个样例均包括输入、思维链和输出三个部分,表11 展示了指令中空间场景相同的样例。最后,课题组使用提交的指令,在ChatGPT上运行了100道测试语料的结果,共有65题判断正 确,进入人工评分阶段,得分为37.40分。
ChatGPT的表现
SpaCE2023测试了GPT3.5版本的ChatGPT在数据集上的表现。子任务一的指令说明了S- P-E标注法。受限于ChatGPT可接受的输入长度,我们提供了5条样例帮助模型理解任务目标和 输出格式,这5条样例涵盖了5种语料来源和6种文本片段。子任务二的指令说明了15个元素的概 念,提供了3条样例,涵盖3种语料来源和9个元素。子任务三则直接提供10个样例以供学习,每 个样例包括语料文本、判断结果和按模板编写好的判断理由。样例涉及处所、方向、终点、位 置关系这四个要素,含5条正例和5条负例。对于子任务一和子任务二的输出,我们发现文本片 段的下标存在很多错误,所以用程序重新寻找了每个文本片段的下标。
子任务一的得分反映出ChatGPT仅找出了约46%与空间异常有关的片段,且并未有效掌 握S-P-E标注法。输出结果主要存在两个问题:1P信息的成分较为混乱,填写了许多不表示 方位信息的动词性成分和形容词性成分;2大量使用4-6个片段来描述异常,但填写的片段并 没有信息冲突。在接下来的工作中,子任务一的指令设计将描述每个元素可填入的语法单位, 规定每种文本片段的使用情况。
子任务二的F1值仅有0.1分。输出结果含有许多与空间语义无关的标注,如“他等父亲”标 注了空间实体“他”和事件“等”,说明没有理解任务目标。同一个标签也在同一个元组中使用多 次,如一个元组标注了两个及以上的空间实体,甚至出现“幻觉”,使用了规范以外的元素, 如“数量”、“状态”、“情感”等。子任务二的指令需要采用新的设计思路,如使用思维链的方式 让其找出所有空间实体,然后围绕每个空间实体寻找相关的元素。指令还应说明元素的使用限 制,提供更多用例展示元素的使用条件。
子任务三的输出中,共有71题判断正确,较好地理解了任务目标。人工评分阶段获 得40.40分,生成的文本主要存在两个问题:
与空间义无关。如“等潮水涨上来时才登上小岛”和“等潮水涨起来时才登上小岛”描 述的空间场景是相同的,ChatGPT给出的理由是“都描述了登上小岛的时间”,没有涉及潮水上 涨的方向。 直接将差异字符串作为解释。如“在名称中使用’示范区’字样”和“在名称前使用’示范 区’字样”描述的空间场景是相同的,但所作解释是“企业可以在名称中或名称前使用’示范区’字 样”,仍然没有说明相同的原因。在改进子任务三的指令时,可将模板槽位拆解为多个问答题的形式,引导大语言模型做出 更好地回答。
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

