




在Spark 2.0当中,无论是直接使用SQL语句,还是使用DataFrame、DataSet进行Spark SQL程序的编写,程序最终都会转化为RDD的API接口。如图1所示:
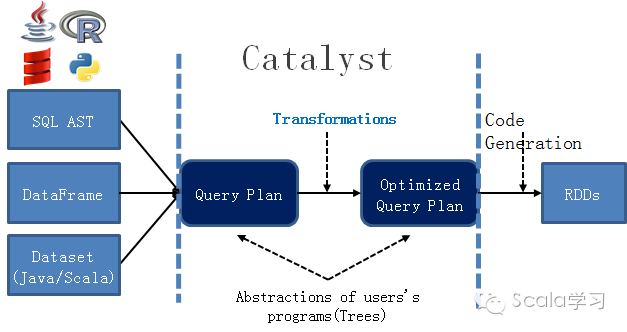
图1 Catalyst优化器
显然开发人员也可以直接通过RDD API接口进行Spark SQL相关逻辑对应的应用程序的编写,但我们知道RDD的计算特性由compute函数确定
def compute(split: Partition, context: TaskContext): Iterator[T]
通过上述这段代码可以看到,compute函数将分区(Partition)数据经过计算逻辑转换成Iterator[T],但因为返回的结果中存在泛型T,因而 Compute函数是一个Opaque Computation(不透明计算),数据类型为Opaque Data Type(不透明的计算),这种方式是非类型安全的。通过RDD的API接口来实现带来的好处是开发人员可以对程序的每步执行进行精确控制,但同样还存在其它一些问题,比如开发人员需要针对不同的应用场景进行应用程序的开发和优化,实际操作时这样是不现实的,程序的执行效率等严重依赖于开发人员的技能。 为解决这些问题,Spark 一方面引入DataFrame/DataSet这样的数据结构,来避免类型安全的问题,将语法错误和程序逻辑错误挡在编译期间而非运行期间,另外一方面通过使用统一的优化器(即Catalyst)来对程序进行优化。今天我们要详细说明的便是Catalyst优化器,Catalyst的具体作用如图2所示,图1中从Query Plan转换成Optimized Query Plan。
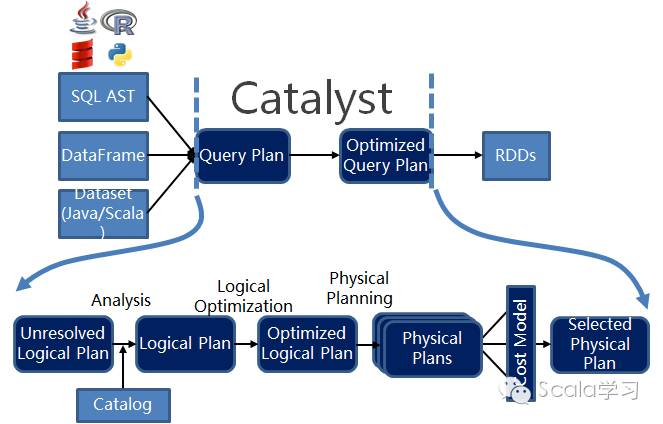
下面以Spark SQL中SQL语句的执行为例,说明Catalyst优化器的执行原理。下列代码给出的是Spark 2.0当中,如何使用SparkSession执行SQL语句:
//创建SparkSession对象
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
import spark.implicits._
case class Person(name: String, age: Long)
// 通过文件创建RDD对象并将其转换成DataFrame
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
// Register the DataFrame as a temporary view
peopleDF.createOrReplaceTempView("people")
// 直接执行Spark SQL语句
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
//触发Spark SQL程序的执行
teenagersDF.map(teenager => "Name: " + teenager(0)).show()
代码val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")中调用了sql方法,该方法的定义如下:
def sql(sqlText: String): DataFrame = {
//调用SessionState中的sqlParser成员变量将SQL字符串转换成未解析的逻辑执行计划(Unresloved Logical Plan
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
在执行时代码teenagersDF.map(teenager => "Name: " + teenager(0)).show()会调用DataSet的collect方法,具体代码如下:
private def collect(needCallback: Boolean): Array[T] = {
def execute(): Array[T] = withNewExecutionId {
queryExecution.executedPlan.executeCollect().map(boundEnc.fromRow)
}
if (needCallback) {
withCallback("collect", toDF())(_ => execute())
} else {
execute()
}
}
通过上述代码可以看到,它调用的是queryExecution的成员变量executedPlan的executeCollect方法,该方法会调用RDD的collect方法,从而调用SparkContext的runJob方法,触发程序在集群上运行。现在我们重点关注的是QueryExecution,因为它是Spark执行关系查询(Relational Query)的工作流程(WorkFlow),其核心成员变量如下:
//对未进行分析的逻辑执行计划,使用SessionState中的Analyzer成员变量进行分析
lazy val analyzed: LogicalPlan = {
SparkSession.setActiveSession(sparkSession)
sparkSession.sessionState.analyzer.execute(logical)
}
lazy val withCachedData: LogicalPlan = {
assertAnalyzed()
assertSupported()
sparkSession.sharedState.cacheManager.useCachedData(analyzed)
}
//对分析后的逻辑执行计划,使用使用SessionState中的Optimizer成员变量进行优化
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
//将优化后的逻辑执行计划转换成物理执行计划,使用的是sparkSession.sessionState.planner成员变量
lazy val sparkPlan: SparkPlan = {
SparkSession.setActiveSession(sparkSession)
planner.plan(ReturnAnswer(optimizedPlan)).next()
}
//使用prepareForExecution方法将物理执行计划转换成可执行的物理执行计划
// executedPlan should not be used to initialize any SparkPlan. It should be
// only used for execution.
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
//执行物理执行计划
/** Internal version of the RDD. Avoids copies and has no schema */
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
从上述代码可以看到,QueryExecution中大量引用的是SessionState中的成员变量,这里给出所有SessionState的核心成员变量,以说明整体执行过程,具体代码如下:
/**
* Internal catalog for managing table and database states.
*/
//数据库和表的字典表,可以通过Catalog来判断表是否存在、通过表名查找表、注册表、取消表等
lazy val catalog = new SessionCatalog(
sparkSession.sharedState.externalCatalog,
functionResourceLoader,
functionRegistry,
conf,
newHadoopConf())
/**
* Logical query plan analyzer for resolving unresolved attributes and relations.
*/
//逻辑执行计划的分析器,利用Catalog将Unresolved Logical Plan转化成Resolved Logical Plan
lazy val analyzer: Analyzer = {
new Analyzer(catalog, conf) {
override val extendedResolutionRules =
PreprocessTableInsertion(conf) ::
new FindDataSourceTable(sparkSession) ::
DataSourceAnalysis(conf) ::
(if (conf.runSQLonFile) new ResolveDataSource(sparkSession) :: Nil else Nil)
override val extendedCheckRules = Seq(datasources.PreWriteCheck(conf, catalog))
}
}
/**
* Logical query plan optimizer.
*/
//逻辑执行计划的优化器,通过若干规则对逻辑执行计划进行优化
lazy val optimizer: Optimizer = new SparkOptimizer(catalog, conf, experimentalMethods)
/**
* Parser that extracts expressions, plans, table identifiers etc. from SQL texts.
*/
//将SQL字符串转化成Unresolved Logical Plan
lazy val sqlParser: ParserInterface = new SparkSqlParser(conf)
/**
* Planner that converts optimized logical plans to physical plans.
*/
//将优化后的逻辑执行计划转换成物理执行计划
def planner: SparkPlanner =
new SparkPlanner(sparkSession.sparkContext, conf, experimentalMethods.extraStrategies)
现在我们来完整地梳理一下整个运行流程
1. 调用sparkSession.sessionState.sqlParser.parsePlan(sqlText)将SQL字符串转换成Unresolved Logical Plan(未解析的逻辑执行计划)
2. 调用sparkSession.sessionState.analyzer.execute(logical)将Unresloved Logical Plan解析为Resolved Logical Plan,其中Analyzer使用了Catalog,用于对缓存的表结构信息进行关联,以得到解析后的逻辑执行计划(Resolved Logical Plan)
3. 调用sparkSession.sessionState.optimizer.execute(withCachedData)将解析后的物理执行计划进行逻辑优化,以生成优化后的逻辑执行计划(Optimized Logical Plan)
4. 调用sparkSession.sessionState.planner.plan(ReturnAnswer(optimizedPlan))生成若干个物理执行计划
5. 调用queryExecution. prepareForExecution(sparkPlan)生成最终的可执行的物理执行计划
6. 最后调用executedPlan.execute()方法执行
最后,我们再看下面这张图,便可以理解整个Catalyst优化器的工作原理。
本文以Spark SQL中SQL语句的执行过程并结合源码级的分析说明了Catalyst优化器器的作用原理,本文试图给大家呈现整体的执行过程。在后续文章中,我将继续对Logical Plan、Optimized Plan等过程进行详细的介绍,敬请期待!
参考文献
1. 范文臣 Deep Dive Into Catalyst:Apache Spark 2.0's Optimizer
