




Spark应用程序当中有大量的API会触发Shuffle操作,如reduceByKey,groupByKey、intersection、cogroup等,熟悉MapReduce编程模型的朋友们都知道,Shuffle操作是典型IO密集型操作包括磁盘IO和网络IO,上游Map端的Task会将数据写入到磁盘文件(磁盘IO),然后下游Reduce端的Task会通过网络拉取(Fetch)这些数据(网络IO),不难看出Shuffle同样也是内存密集型及CPU密集型的操作。因此,在实际编程对性能有要求时,需要特别注意Spark Shuffle操作,作为Spark应用程序的“性能杀手”,必须对它有足够的了解,才能在实际应用中对程序进行全局或局部调优。
本文先将通过一个Spark应用程序示例引出Spark Shuffle,然后介绍程序的运行原理,以理解Spark Shuffle操作对程序调度运行的影响,在此基础上,对Spark Shuffle内核原理进行分析。本文并不是一篇源码解析类的文章,而是偏重于对原理的介绍,以使读者在后期能够深入源码,更进一步地理解Spark Shuffle的细节。
下面的示例用于求两个RDD元素的交集:
//构造一个RDD,分区(partition)数为2
scala> val rdd1=sc.parallelize(Array("Spark","Hadoop","Kudu"),2)
//构造一个RDD,分区(partition)数为3
scala> val rdd2=sc.parallelize(Array("Spark","Hive","Apache Kylin"),3)
//求两个RDD间的元素的交集
scala> val intersectionRdd=rdd1.intersection(rdd2)
intersectionRdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[23] at intersection at <console>:25
//触发执行Spark程序,生成JOB提交集群执行
scala> intersectionRdd.collect
res2: Array[String] = Array(Spark)
//打印RDD的Lineage关系
scala> intersectionRdd.toDebugString
res25: String =
(1) MapPartitionsRDD[28] at intersection at <console>:25 []
| MapPartitionsRDD[27] at intersection at <console>:25 []
| MapPartitionsRDD[26] at intersection at <console>:25 []
| CoGroupedRDD[25] at intersection at <console>:25 []
+-(1) MapPartitionsRDD[23] at intersection at <console>:25 []
| | ParallelCollectionRDD[21] at parallelize at <console>:21 []
+-(1) MapPartitionsRDD[24] at intersection at <console>:25 []
| ParallelCollectionRDD[22] at parallelize at <console>:21 []
可以看到程序中我们创建了两个RDD,然后通过intersection方法生成了一个RDD,但通过intersectionRdd.toDebugString打印RDD间Lineage关系可以发现:最终生成了8个RDD,主要原因是intersection方法调用会导致多个RDD的生成,查看源码可以看到:
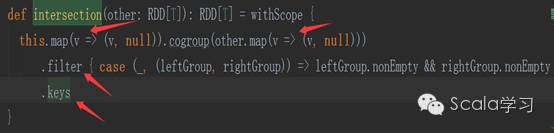
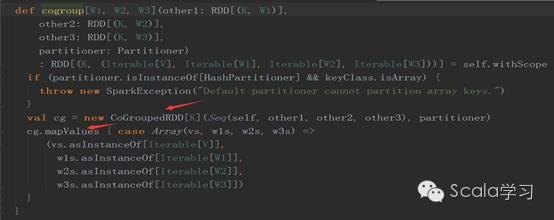
intersection方法先执行map方法(生成MapPartitionsRDD),然后再执行cogroup方法,cogroup方法会生成CoGroupedRDD和MapPartitionsRDD,查看cogroup方法的源码可以得到验证
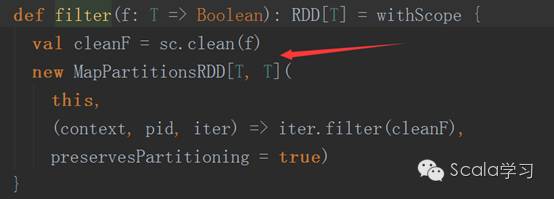
然后再执行filter方法,它也会生成一个MapPartitionsRDD
最后执行key方法,它仍然生成的是一个MapPartitionsRDD,察看keys方法的源码可以看到

这便是执行intersectionRdd.toDebugString时,会有下列Lineage关系的原因
(1) MapPartitionsRDD[28] at intersection at <console>:25 []
| MapPartitionsRDD[27] at intersection at <console>:25 []
| MapPartitionsRDD[26] at intersection at <console>:25 []
| CoGroupedRDD[25] at intersection at <console>:25 []
+-(1) MapPartitionsRDD[23] at intersection at <console>:25 []
| | ParallelCollectionRDD[21] at parallelize at <console>:21 []
+-(1) MapPartitionsRDD[24] at intersection at <console>:25 []
| ParallelCollectionRDD[22] at parallelize at <console>:21 []
这个例子虽然简单,但这段Spark程序中却蕴含了本文涉及的Spark Shuffle操作,在分析Spark Shuffle内核原理之前,先来理解Spark Shuffle操作对Spark程序调度运行的影响。
逻辑执行图,指的是Spark应用程序运行时的逻辑,类似数据库的逻辑视图,它是程序运行的一种抽象表达,前面例子的逻辑执行图如下图所示(为简单起见,分区中的数据用字母替代):
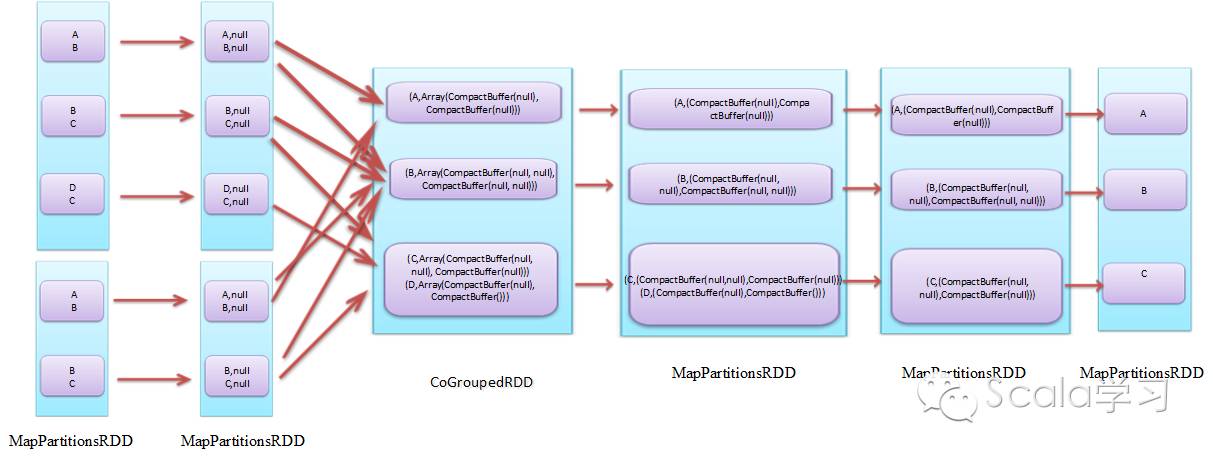
在前面我们提到intersection方法在执行时会调用cogroup方法,cogroup方法在执行时依赖于Spark Shuffle模块,反应在上图中就是MapPartitionRDD转换成CoGroupedRDD需要进行Spark Shuffle操作。
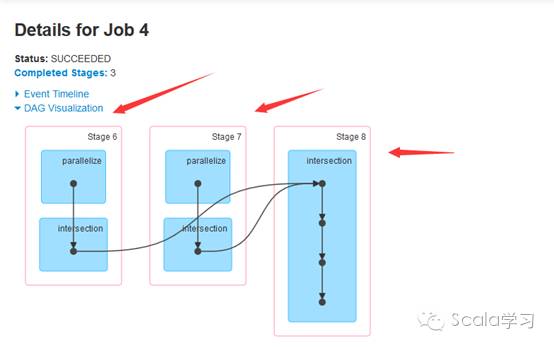
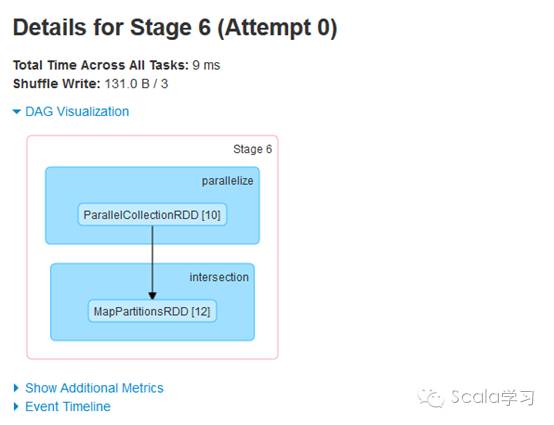
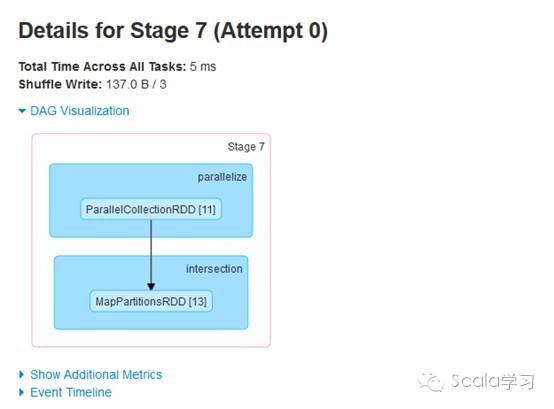
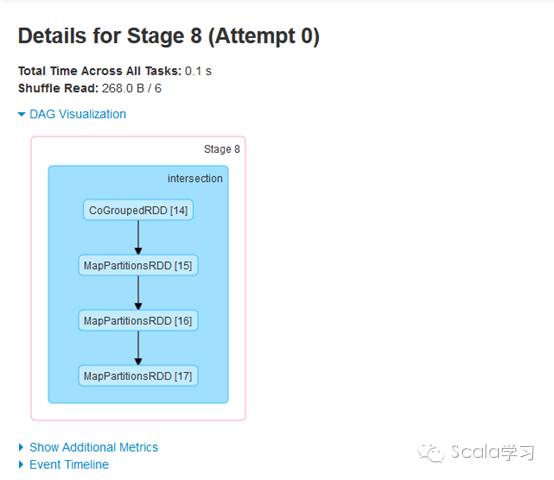
物理执行图指的是Spark在调度执行时对应的Stage划分及任务执行过程。在触发Spark任务执行时,Spark在调度时会根据方法是否需要进行Shuffle操作进行Stage划分,通过Spark 的Web UI界面可以查看Stage的划分情况,具体如下:
用一个带具体调度相关类的图进行更直观的表示,如下图所示
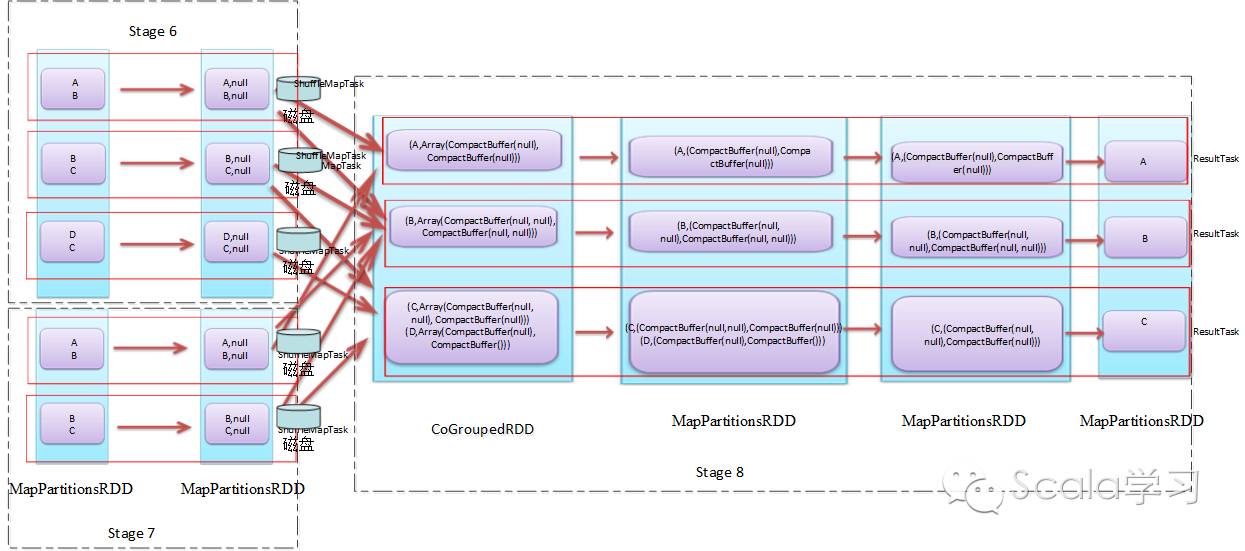
通过上图可以看到,应用程序被划分成三个Stage,分别为Stage 6、Stage 7及Stage 8(序号实际运行时由Spark调度器分配),事实上Stage与TaskSet对应,每个Stage根据分区数生成对应的Task,上游Task称为org.apache.spark.scheduler.ShuffleMapTask,下游Task被称为org.apache.spark.scheduler.ResultTask,这些Task的集合即为org.apache.spark.scheduler.TaskSet,在实际运行调度时不同的Task可以并行执行。可以看到,与普通的Spark Tansformation操作不同,Spark的Shuffle操作(即ShuffleMapTask)执行时的结果需要进行磁盘操作,会产生大量的临时文件,即Spark的Shuffle是网络IO、磁盘IO、内存及CPU密集型操作,这也就是它被称为Spark的性能杀手的原因。由此可见,理解Shuffle的原理对于Spark性能调优等具有十分重要的作用。
Spark Shuffle模块涉及的核心类图如下图所示
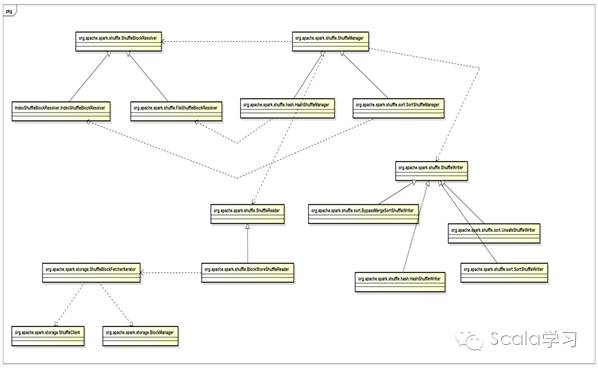
涉及的核心类包括
org.apache.spark.shuffle. ShuffleManager:Shuffle模块对外服务的接口,目前有两个子类分别是HashShuffleManager和SortShuffleManager,Spark 1.6.2 默认的ShuffleManager为SortShuffleManager
org.apache.spark.shuffle. hash.HashShuffleManager:Shuffle过程中数据根据Hash的结果写到对应Reduce分区对应的磁盘文件中,在写数据时不进行排序操作,对应的ShuffleWriter为HashShuffleWriter,这种ShuffleManger最大的缺点是会产生大量的磁盘文件
org.apache.spark.shuffle. sort.SortShuffleManager:Shuffle过程中根据实际需要进行排序操作,在写磁盘时将文件保存到同一个文件中,从而避免HashShuffleManager方式所带来的问题
org.apache.spark.shuffle. ShuffleWriter:Shuffle过程中Map端文件写入磁盘的服务类,目前有HashShuffleWriter和SortShuffleWriter两个子类。
org.apache.spark.shuffle.hash. HashShuffleWriter:参见HashShuffleManager
org.apache.spark.shuffle.sort.SortShuffleWriter:参见SortShuffleManager
org.apache.spark.shuffle.sort. BypassMergeSortShuffleWriter:Hash Shuffle的一种改进,用于处理不需要排序的Shuffle操作,直接将分区文件写入单独的文件,最后再将这些文件合并,以加快处理速度,不过这种方式需要并发打开多个文件,对内存的消耗较大。
org.apache.spark.shuffle.sort. UnsafeShuffleWriter: Tungsten-based sort,排序不基于Java对象,而是直接作用于序列化的二进制数据(serialized binary data)以减少内存开销和GC过载。
org.apache.spark.shuffle. ShuffleReader:Reduce端Shuffle文件读取类,目前只有BlockStoreShuffeReader一个子类
org.apache.spark.shuffle. BlockStoreShuffeReader:Shuffle磁盘文件读取类,可以读取HashShuffleWriter和SortShuffleWriter写入的磁盘文件
org.apache.spark.shuffle. ShuffleBlockResolver:Shuffle文件解析器,有IndexShuffleBlockResolver和FileShuffleBlockResolver两个子类
org.apache.spark.shuffle. IndexShuffleBlockResolver:用于解析Sort-Based Shuffle Writer写入的磁盘文件
org.apache.spark.shuffle. FileShuffleBlockResolver:用于解析Hash-Based Shuffle Writer写入的磁盘文件
org.apache.spark.storage. ShuffleBlockFetcherIterator:根据数据本地性原则获取数据,如果在本地,则调用BlockManager获取,如果不在本地,则使用ShuffleClient远程获取数据
org.apache.spark.storage.ShuffleClient: 数据不在本地时,用于远程获取数据。
org.apache.spark.storage.BlockManager:存储模块对外服务的类,数据在本地时直接进行数据的获取
Spark 1.2之前只有一种Shuffle方式,那就是Hash-Based Shuffle,对应Writer类为org.apache.spark.shuffle.hash. HashShuffleWriter,其原理如下图所示
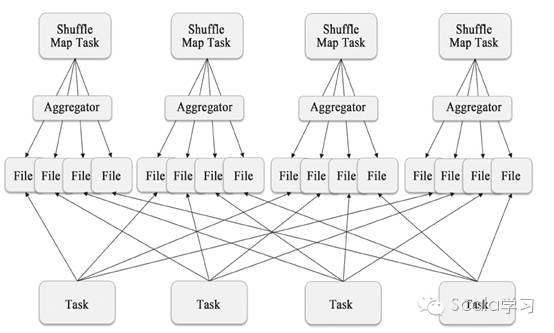
可以看到,每个ShuffleMapTask需要为下游的每个Task创建单独的文件,因此其创建的文件数为ShuffleMapTask数*Reducer数。如果ShuffleMapTask数为1000,Reducer Task数为500,则需要500000个文件,假设DiskBlockObjectWriter需要100kb内存,则需要50GB的内存,实际生产环境中, ShuffleMapTask与Reducer Task的数量可能更多,这给集群造成了极大的内存压力。为解决这个问题,Spark 1.6之前的版本还提供了Shuffle Consolidate Writer机制,如图6所示,可以看到这种机制需要的Shuffle文件数为CPU核数* Reducer数,但Spark 1.6之后,将这一功能移除,主要原因是sort-based shuffle writer的实现可以完全替代Shuffle Consolidate Writer且效率更高。具体参见https://issues.apache.org/jira/browse/SPARK-9808
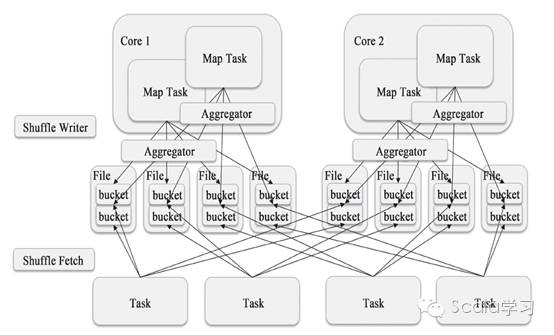
Spark 1.2之后,已经默认将HashShuffleWriter换成了SortShuffleWriter,其实现原理如下图
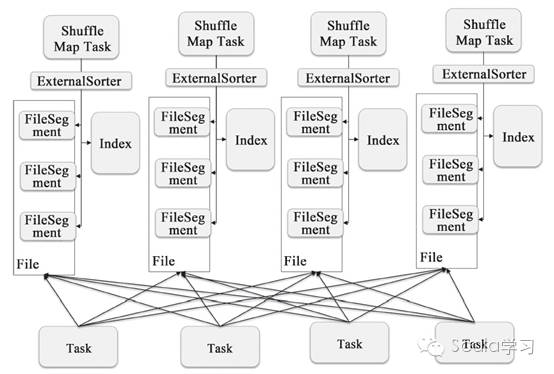
可以看到每个Shuffle Map Task不再为下游的每个Reducer生成一个单独的磁盘文件,而是只保存在一个文件当中,同时生成一个Index文件为下游的Reducer提供数据位置索引服务,这种方式可以有效地减少中间磁盘文件的生成,避免不必要的性能开销。这就是为什么将ShuffleManager默认设为SortShuffleManager的原因。
下面以SortShuffleWriter机制说明Shuffle Write过程,Spark Shuffle机制在SparkEnv中被指定,代码如下:
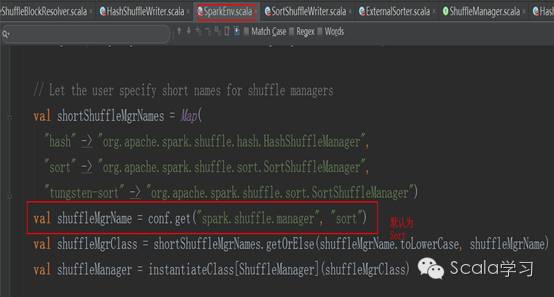
即默认使用org.apache.spark.shuffle. sort.SortShuffleManager,在进行Shuffle操作时,会运行ShuffleMapTask的runTask方法
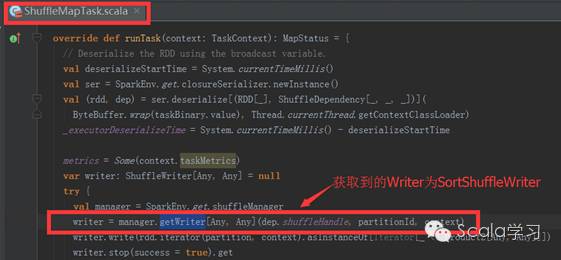
运行runTask方法时,代码writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)执行完成后将得到org.apache.spark.shuffle.sort.SortShuffleWriter, 然后再调用其write方法将RDD分区中的数据写入磁盘。
上游Map端的ShuffleWriter将数据落盘后,下游Reducer端的数据读取交由ShuffledRDD负责,具体读取通过ShuffledRDD的compute方法,其代码如下:
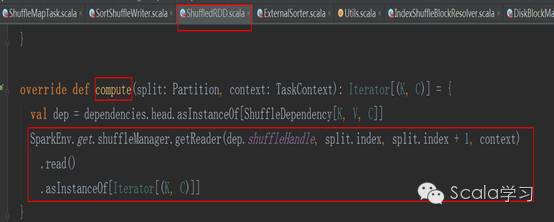
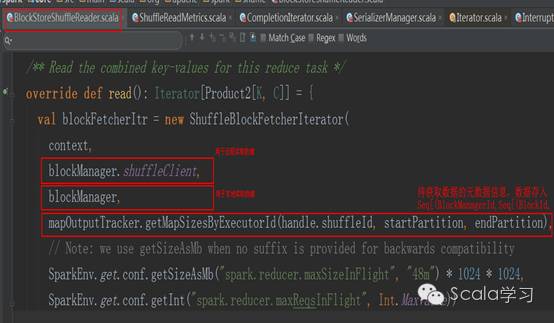
可以看到,读取将调用ShuffleManager#getReader方法,目前Spark只有一种ShuffleReader,那就是org.apache.spark.shuffle.BlockStoreShuffleReader,也即无论对于是SortShuffleWriter还是HashShuffleWriter的Shuffle文件,采用的都是BlockStoreShuffleReader。调用BlockStoreShuffleReader#read()方法读取Shuffle文件中的数据,该方法依赖于org.apache.spark.storage. ShuffleBlockFetcherIterator类,读取时如果待读取的数据在本地机器,则直接通过BlockManager获取,如果不在本地,在远程其它机器上,则通过ShuffleClient读取,具体代码如下:
本文通过Spark Shuffle程序示例引入Spark Shuffle机制并对Shuffle如何影响程序调度运行进行了分析,最后对Spark Shuffle内核原理进行介绍。通过本文,读者们应该明白什么是Spark Shuffle及一个典型的带有Spark Shuffle的程序是怎么运行的并掌握Spark Shuffle内核原理。本文在介绍Spark Shuffle内核原理时只给出了脉络,并未深入代码细节,为方便读者们更进一步地理解Spark Shuffle,图8最后给出了Spark整体运行框架图。
参考文献
张安站,《Spark技术内幕:深入解析Spark内核架构设计与实现原理》,机械工业出版社,2015.09
