





观摩完今年的CCF国际AIOPS挑战赛,今年的主要活动算是告一段落了,剩下的时间里会静静的在南京完成D-SMART年度版本的封板,然后静待来年了。十分高兴今年南瑞研究院的CheerX代表队不仅晋级决赛,并且拿下了银奖。去年他们排名11,止步决赛,今年从头再来,取得了佳绩。


近距离观摩了决赛答辩阶段,觉得十强队伍确实名至实归,在AIOPS落地应用场景方面都亮出了绝活和高招。
今年挑战赛的主题中加入了大模型的内容,组委会也提供了GPU资源,多支代表队在其解决方案中都加入了大模型的成分,这也是本届大赛的亮点之一。
谈到大模型在AIOPS中的应用,就免不了讨论到大模型在AIOPS落地所遇到的最大阻碍是什么。这也是周六下午两场圆桌论坛的议论焦点,我也有幸参加了其中一场,和现场的几位AIOPS领域的领先企业的朋友一起探讨了这个话题。虽然议题是提前预知的,不过我觉得很多嘉宾,包括我在内的很多发言都不是预先准备好的,而是在这次大会的氛围中思考后的感受。
与会的嘉宾都觉得大模型的质量是决定大模型在AIOPS领域落地的关键要素,运维领域因为某些安全方面的原因,无法直接接入目前水平最高的GPT4等公有云大模型,一般只能私有化部署模型,受限于GPU资源,模型的规模也受到一定的影响。因此哪个模型在运维领域具有较好的性能是大家都比较关注的问题。通识大模型在运维领域的表现不尽如人意,准确性不足,甚至幻觉问题严重都会影响大模型在AIOPS领域的落地。本次大会也首发了OpsEval运维大模型评测基准。通过该基准测试,可以为想落地基于大模型的AIOPS的组织提供了一个可参考的基准。
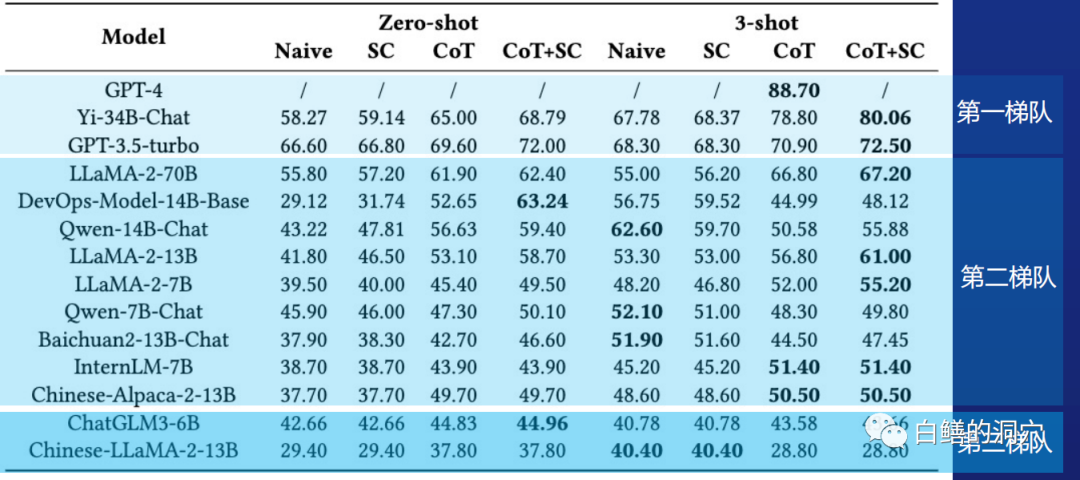
在会上,裴丹老师也发布了基于OpsEval的首次评测基准数据。可以看出,在Zero-shot领域,目前的一些开源大模型的性能都存在较大的问题,这会严重影响大模型的应用落地效果。

基础模型水平不足,就必然需要通过自己训练或者微调的方式来提高模型的性能。开源大模型大多数只是开源了参数,并没有开源数据集,因此微调工作的难度也不小,在微调训练中跷跷板问题也是大家常见的问题,也就是说训练后,可能在某方面性能确实提高了,不过在另外一方面可能会变傻了,这个问题以前我也遇到过。另外在微调训练中所需要的高质量的小数据集也不是一般企业能够简单获得的,因此十分有必要建立一个开放的联盟,使大家的数据集和知识能够共享。

针对这个问题,裴丹老师也提出了建立Open AIOps Alliance社区的建议,构建一个AIOps领域的Hugging Face。这个倡议十分诱人,任何从事AIOPS的企业或者想利用AIOPS解决自身运维问题的组织,都会从中受益。我们也会积极参与,不过知易行难,想要把这个联盟真正搞起来,难度还是相当大的。

在大会的圆桌环节,我提出了另外一个方面的落地障碍,那就是我们企业的主管对于大模型落地AIOPS的期望过高,认为大模型一出,以前遇到的所有棘手的问题都迎刃而解了。这样的话,很可能在落地路径选择上过于简单,走上邪路,如果短期不出成果,就会走向另外一个极端,认为这玩意不靠谱,不值得搞。
通识大模型好像是一个百晓生,虽然知道的比较多,但是它并不是运维领域的专家,在没有被输入专业领域的知识之前,他们不可能直接成为具体的运维领域专家。无论是采用预训练、微调、向量嵌入等方式,都需要实施AIOPS的组织准备好大量的数据。在本次AIOPS挑战赛中,很多实用大模型的团队都使用了通过AGENT调用API来进行分析和扫描的方法。这个API我们称之为“知识点”,每个知识点都是基于基础原理或者专家经验编制出来的工具,正是这些工具弥补了通识大模型在专业领域的不足。而积累这些“知识点”实际上就是很多组织以前在AIOPS领域的最大弱点。
虽然大模型在AIOPS落地还有巨大的挑战,不过我和很多嘉宾对此的前景是乐观的,未来3-5年里,肯定会 涌现出大量的KILLER APP出来,未来已来,无需等待,准备下场吧。
