




论文链接:https://arxiv.org/pdf/2312.01712.pdf
摘要
Vector Search
01
近似最近邻居搜索(Approximate Nearest Neighbor Search,ANNS)作为重要的组件目前被广泛应用于如推荐系统、大模型等各种智能应用中。这一任务主要的目的为在某种距离度量下(一般为欧几里得距离或内积距离),在大量的向量(Database)中寻找与查询(Query)最近的若干向量,这些向量的维度从点云任务中的三维到大模型 Embedding 中的数千维不等。
本文对分析乘积量化搜索方法的特点,并找出了效率低下的一个重要原因,即不必要的成对距离计算和累加。为了提高效率,本文提出了端到端 ANN 搜索系统 JUNO,它采用了精心设计的稀疏性和局部感知搜索算法。本文还提出了一种高效的硬件映射,利用现代 GPU 中的RayTrace Core和pipeline执行的Tensor Core来执行 ANN 搜索算法。在从 1 到 1 亿个搜索点的四个数据集上进行的评估表明,搜索吞吐量提高了 2.2 倍到 8.5 倍。此外,在没有 RT 内核加速的情况下,仅算法改进就在硬件上实现了最大 2.6 倍的改进。
乘积量化
Vector Search
02
目前为了优化ANNS的性能,乘积量化(Product Quantization)被广泛应用。在乘积量化中,Database中每一个高维向量首先被等分为若干段低维向量;对于某一段低维向量,在对应编码本(codebook)中计算所有codebook entries与这段低维向量的距离;最后直接用最近的codebook entries的ID编码这段低维向量。在 Query 到来后,Query 也进行分段操作;而后每一段低维向量与对应编码本中的每个 codebook entries 计算距离,汇总成距离查找表;最后遍历编码后的 Database,根据 ID 查找距离查找表并累加多段低维向量的距离,对最后总距离排序获得最后的最近邻居。在这一过程中 codebook 由 Database 中的点训练而来,其质量直接影响到编码质量。
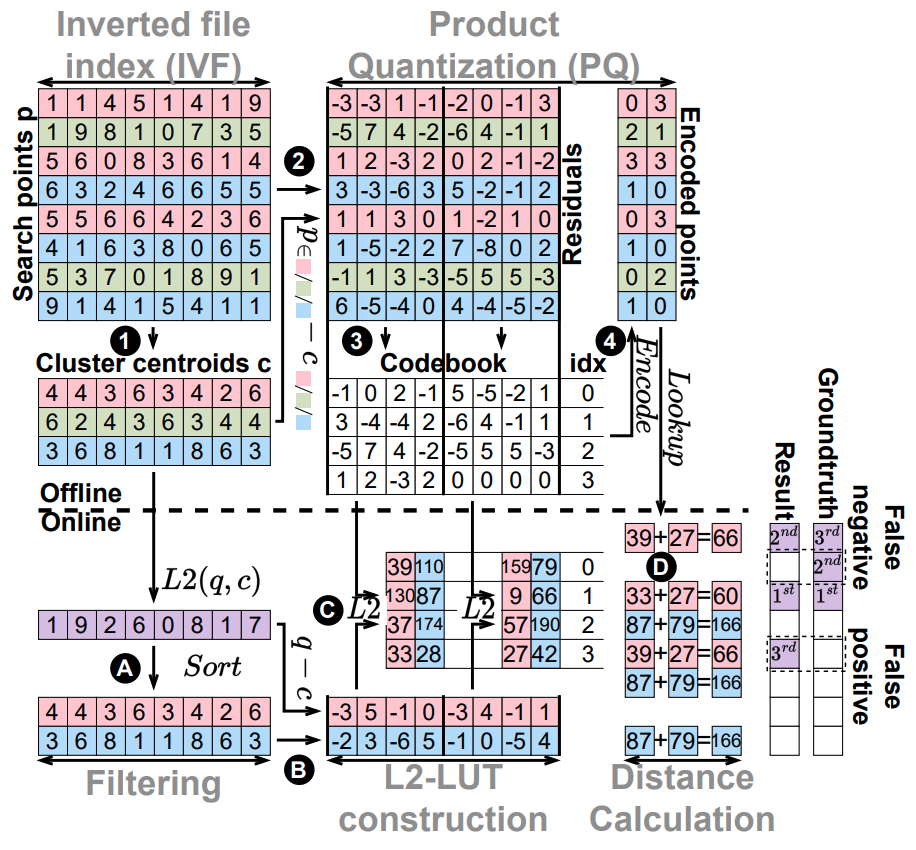
图1
优化思路
Vector Search
03
如果将 IVFPQ 的搜索过程如图1所示划分成三个阶段为别为 Filter、L2-LUT、DistanceCalculation 后,可以通过分别统计每个阶段的计算时间来确定哪部分为时间瓶颈。实验结果如图2所示,可以发现在不同的 nprobe 下,Filter 阶段时间不会发生变化,而其他两阶段的时间消耗随着 nprobe 参数线性增加。且约占总时间的90%~99.9%。
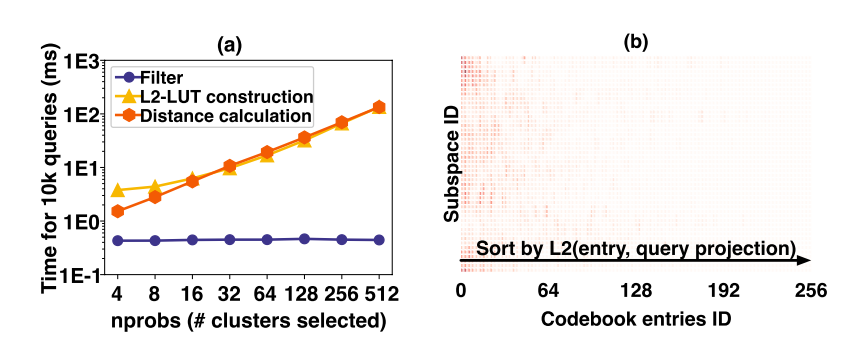
图2
作者发现在 PQ 的搜索过程中,对于某个 Query 真正的Top-100 Nearest 结果,在某一段低维向量的空间中被用到的 codebookcodebook entries 少且集中。少于25%的 codebook entries 会被 Top-100 Nearest 使用,集中被使用到的codebook entries都在空间距离上离 Query 这段低维向量很近。本文的其中一个思路便是利用这一 codebook entries 的稀疏性和空间局部性,仅计算离 Query 这段低维向量近的 codebook entries 的距离。
Codebook entries的空间稀疏性
作者通过对 Faiss 的 PQ48 索引对 Deep1M 进行 Top100 查询,发现平均仅利用了25%(至多30%)的 codebook entries 即可完成计算。同样对 SIFT1M(PQ 64)、TTI1M(PQ 40) 数据集进行测试,这些数据集表现出小于30%的 codebook entries 利用率。那么如果可以利用这种稀疏性,可以避免70%的浮点运算时间,从而减少 L2-LUT 的构造距离表的时间。
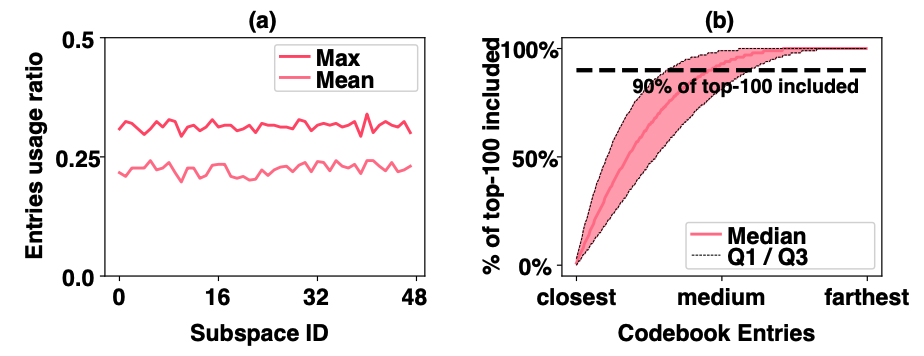
图3
Codebook entries的空间局限性
仅仅是具备空间稀疏性也很难将其转化为实际的性能提升,因为稀疏性往往会导致不规则的访问。即如果这些稀疏的点在空间中分布不均匀,仍然很难加速 L2-LUT 的计算时间。然而作者通过对实验数据进行分析,如图 2-b,可以发现使用到的 codebook entries 更密集的集中于频率热图的前半部分。这表明被选择的 codebook entries 都分布在查询向量附近。这个结论也很好理解,每个子空间的 codebook entries 都是聚类得到的簇中心,那么距离查询更近的簇一定是热点簇。
RayTrace技术
那么可以很自然的想到,如果可以筛选这些距离查询向量更近的簇即可以完成对构建时间的优化。若使用传统的计算方法,仍然需要计算每个条目的距离进行筛选,然而光线追踪硬件给了新的优化空间。光线追踪硬件目前广泛使用 BVH 树 + AABB 包围盒的算法,以 LogE 的复杂度对光线和 E 个实体进行相交检测。而相交检测就蕴含了距离筛选。故作者将这一想法映射到 NVIDIA 光线追踪核心上进行加速。使用光线追踪核心计算离 Query 这段低维向量近的条目的距离,并进行后续的距离累加、排序。为了提高计算效率以及距离度量覆盖率,作者提出了若干优化,诸如基于相交时间的相交距离计算及距离阈值调节,基于实体半径的距离度量切换以及 Tensor - RT Core 并行等。JUNO 系统在多个1,000,000和100,000,000规模数据集上取得相比基线系统 FAISS 2x-9x 的提升。
注:NVIDIA 在2018年9月首次发布了带有 RT Core 的显卡2080。光追技术本质上是发射多条虚拟的光线,然后追踪并记录这些光线与场景中的物体之间碰撞的信息来生成画面的技术。在 RT Core 中使用基于 BVH 的光追算法可以有效地在三维欧几里得空间中找到线和面之间的交点。相比于在 Cuda Core 中执行光追算法效率得到了更大的提升。
之前的一些方法可以利用 RT Core 来加速 NN 检索,但只限于低维(2、3)空间,从而限制了实用性。而本文会更关注更通用的 NN 搜索任务与 RT Core 的结合。
BVH树
摘自 BVH 维基百科:在 BVH 中,所有的几何物体都会被包在 bounding volume 的叶子节点里面,bounding volume 外面继续包着一个更大的 bounding volume,递归地包裹下去,最终形成的根节点会包裹着整个场景。常用于碰撞检测和光线追踪的加速,能够将时间复杂度降低到关于物体数量的对数级别。
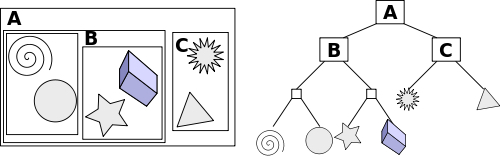
图4
AABB轴对称包围盒
如果可以使用一个包围盒包住物体。那么在光追计算中,我们可以根据这条光线是否与包围盒相交,如果不相交那更不可能与物体相交了。那么自然也没有必要去遍历该物体的所有三角形面。而所谓 AABB 也是一种包围盒,也是由三对平面的交集构成,只不过 AABB 的任意一对平面都与 x-axis,y-axis 或者 z-axis 垂直,所以称之为轴对齐包围盒。如图5所示。
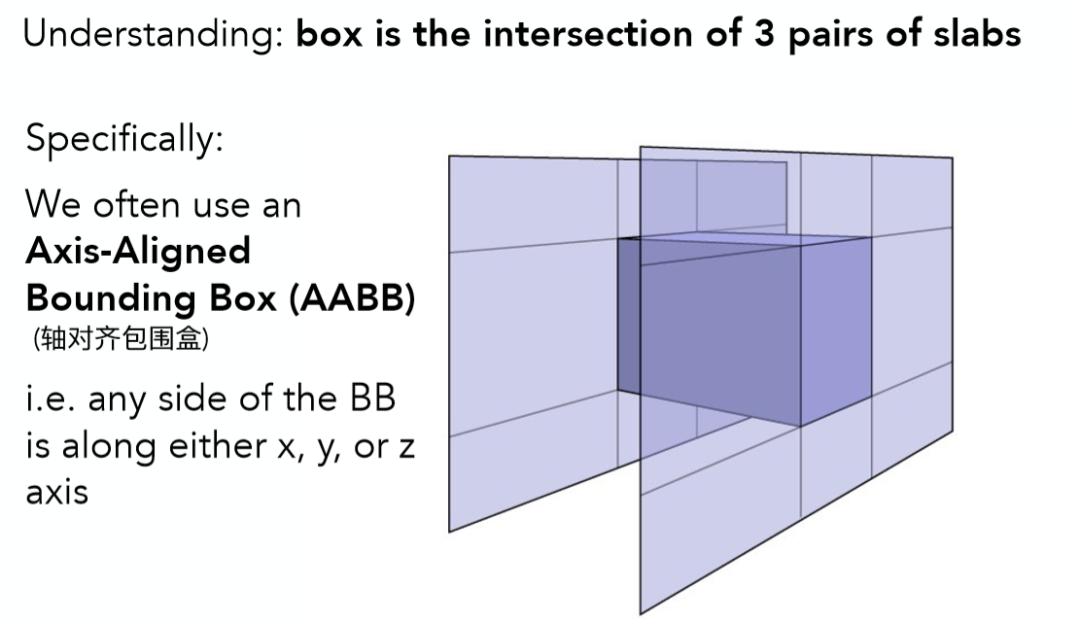
图5
以2维的 AABB 包围盒为例(可以扩展到3维),我们可以用图6的例子来演示如何判断光线t是否与包围盒相交。我们可以发现 t enter=max(t min),t exit = min(t max)。当 t enter < t exit && t exit > 0 时,说明光线与包围盒相交。
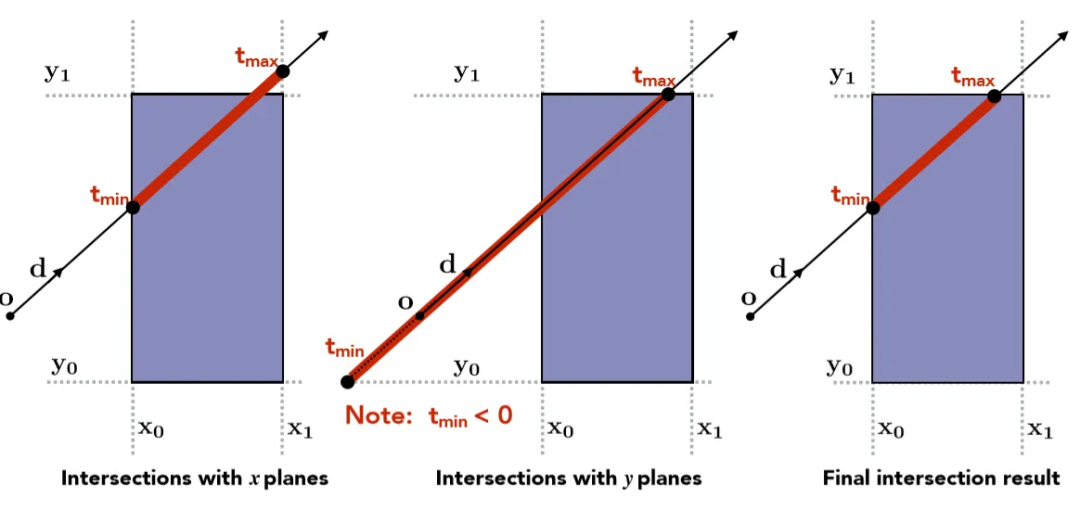
图6
LUT与RT Core的映射
那我们可以发现,LUT 阶段如果对每个 codebook entities 为中心预先生成一个半径为r的球体,再将查询视为一条射线,如果射线相交于球体,则判断这个 codebook entities 是相对于查询来说感兴趣的区域。如图7所示。
图7
先前的研究通过基于 BVH 树的算法证明了 RT 内核高效的内部/外部检查能力。有了这种能力,本文的方法在确定 code entities 是否位于子空间中查询投影的感兴趣区域内时,就有可能节省计算资源。为了实现这一点,我们在查询投影的坐标处放置了一个半径设定为距离阈值的球体,从而使我们的距离检查方法与 RT 核心保持一致。这个球体自然就定义了感兴趣的区域。随后,射线从 codebook entities 投向 RT Core 中的感兴趣区域,从而快速确定条目是否位于感兴趣区域内。
在以上的方法中,利用一个球体来描绘查询投影中的感兴趣区域。但是,这种方法在线计算时添加球体,从而导致过多的开销。为了缓解这个问题,本文利用 L2 距离度量的交换性。具体来说,在离线处理阶段在每个 codebook entities 的中心预生成球体,并在运行时将查询投影投射到这些球体。这与在线球体构造会有相同的效果。
距离计算
L2-LUT 的构造需要计算每个命中的 entity 和球心之间的距离,简单的方法是直接使用存储在全局存储器中的坐标。由于命中的 entities 有稀疏性,全局存储器可能具有不规则的存储器访问。为了解决这个问题,作者提出的方案是利用 RT Core 的结果来计算距离,从而避免全局内存访问。
RT Core 在光追过程中加入了时间的概念,表示光线传播的持续时间。默认情况下,光线在一个单位的时间间隔内遍历一个单位的空间。这里会涉及两个确定的时间点: t hit 和 t max (上文中提到的 t enter 和 t exit)。前者表示从射线开始传播到它与物体相交的时间间隔,而后者表示射线可以传播的最大持续时间。我们可以命中光追计算过程中获得这两个时间,而不是通过全局内存访问的方式。为了精准计算出距离,我们利用光线的 t hit 和被击中的球体的半径 R 快速确定击中点与球心之间的距离。如图8左所示。
动态阈值
这里的阈值可以理解成当查询射线与 codebook entities 距离为多少时才认为两者更接近。实际上,构造的球体的半径 R 即为阈值。虽然对于不同的查询不同的 codebook entities 来说,不同的阈值设置更合理。但为了消除在线创建球体的需要,作者将动态距离阈值转换为射线的动态最大移动时间。对于较小的区域,设置了相应较小的 tmax 值,如图8右所示。例如,如果原始阈值为 0.6,则 tmax = 0.64 的值对应缩放因子为 0.8(用户预设)。因此,我们只需调整 tmax 即可同时支持动态距离阈值和缩放因子,并且可以设置所有球体的半径相同,这将大大简化上述距离计算和进一步处理。
注:以上是作者原文中对动态阈值的解释。简单理解一下即因为球体是离线阶段构造的,只能给固定的半径 R。但通过控制在线搜索阶段的 tmax 来约束半径 R。例如图8右侧最左面的射线,实际命中了球体,但超过了设定的 t max 所以判断为 miss。
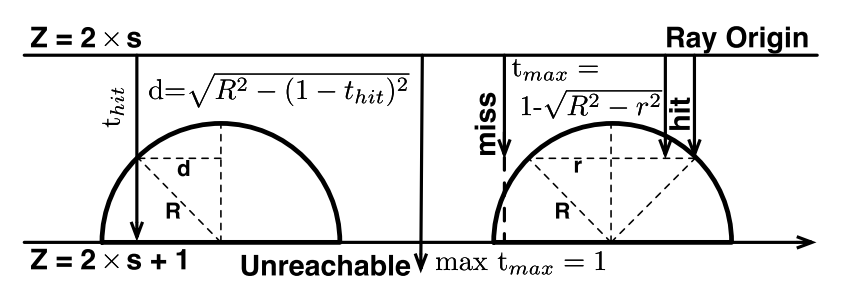
图8
内积计算支持
本文的方法同样适用于最大内积相似度计算。以前的方法依赖于引入额外的维度,以便通过最小化转换后的查询和搜索点之间的 L2 距离来最大化内积。本文提出了更友好的方式来做转换。
用thit来计算机 2D 空间中的 L2 距离,其中 e 时 codebook entities。xe、ye 需要在运行时访问全局存储器查找坐标,以计算内积距离。而对于 RT Core,可以通过将 R 代替为R'的形式来避免引入额外的维度。
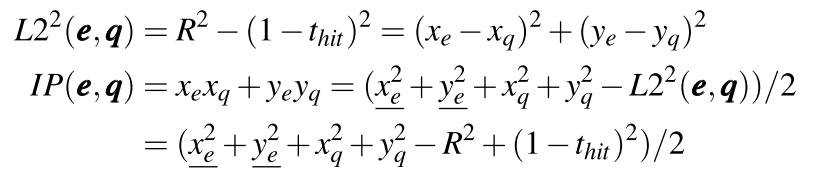
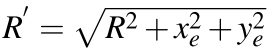
其中 xq、yq、R 均为单个查询的常量。因此内积 IP(e,q) 可以直接用 tnewhit 直接计算,而无需访问任何球面坐标。此外项x2q +y2q可以忽略不计,因为它在所有 codebook entities 中都保持不变。因此,在 L2 距离度量中,只需从 R 中调整球的半径为R'即可。注意还需要在 Filter 时将簇的度量从 L2 距离改为内积。
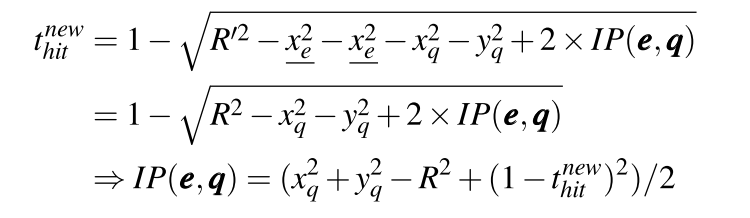
基于命中计数的方法
上述 L2-LUT 构造仍然需要进行若干浮点运算来计算命中球体的半径和射线的命中距离。作者提出了一种更积极的近似 ANN 搜索,该搜索使用来自 RT Core 的命中/未命中结果。
作者首先研究命中计数和精确距离之间的关系,其中所有球体都设置有包含前100个搜索点的半径阈值。如图 9(B) 所示,这两个因素之间存在很强的相关性。原因是较高的命中计数意味着在更多的子空间中接近查询投影。这一发现启发了基于命中计数的 ANN 搜索方法。
具体来说,作者采用了一个基于奖励/惩罚的模型,它涉及到每个原始球体半径的一半的额外球体,如图9(B)所示。命中计数仅在射线成功地与内部球体相交时递增1,并且在射线错过两个球体时递减1作为惩罚。如图 9(B) 所示,使用该方法计算的命中计数(蓝色三角点)与原始命中计数(黄色六方形点)相比表现出更强的相关性。虽然这种近似可能导致假阳性/假阴性(在图 9(B) 中分别标记为“-”和“+”区域),但它为用户提供了新的参数以在合理的搜索质量降级和提升的吞吐量之间进行权衡。
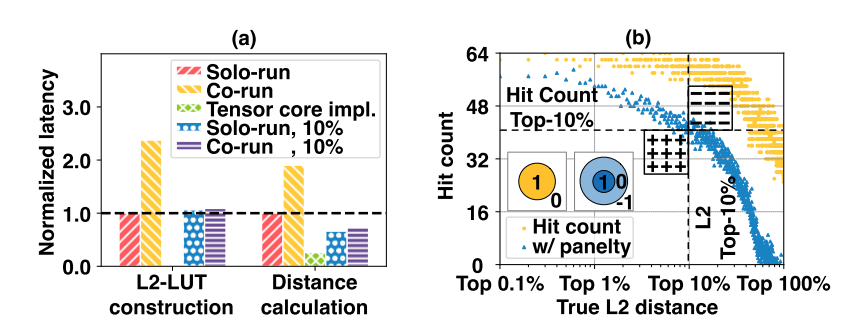
图9
实验
Vector Search
04
JUNO 系统中使用的 RT 算法通过 Nvidia Optix7.6 实现。使用到的 Nvidia GPU 为 RTX 4090 (16384/128),A100 (6912/0),NVIDIA Tesla A40(10752/84)。如果 GPU 没有 RT 内核(A100),OptiX 会将 RT 计算下放到 CUDA 内核。这使得 JUNO 也兼容没有 RT 内核的 GPU。使用到的数据集为 SIFT1M/SIFT100M、DEEP1M/100M、TTI1M。维度分别为128、96、200。
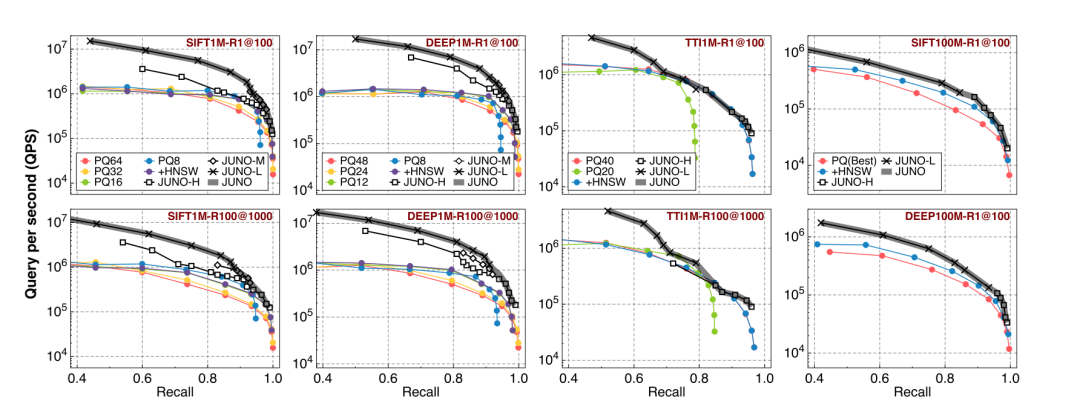
图10
图10展示了不同数据集上的整体搜索质量和吞吐量。JUNO-L/M/H 的各种配置汇总到图中的灰色粗线中,L、M、H 版本是因为 JUNO 允许用户在搜索质量和吞吐量之间进行权衡。标有 PQx 的线来自 FAISS baseline,表示将整个空间划分为 x 个子空间。标有 +HNSW 的线表示将 HNSW 优化添加到性能最佳的 PQ 配置的性能。请注意,HNSW 配置为性能最佳的参数。
JUNO-H:采用基于命中时间的精确命中距离计算,以满足高质量要求。
JUNO-M:采用更细粒度的基于命中计数的选择,具有多个球体以满足中等质量要求。
JUNO-L:仅在低质量要求时使用基于点击数的选择。
在低搜索质量场景中,JUNO 实现了比 baseline 高7.8倍的 QPS,即 JUNO-L,R1@100≤ 0.95。这些优化来自于稀疏性和局限性的特征。首先,通过设置一个更严格的阈值,我们可以放弃更多的搜索点,从而提高过滤效果。其次,我们执行基于命中计数的选择,而不需要实际的距离计算。此外,由于球体的尺寸减小,使用更严格的阈值导致更少的命中事件。因此,JUNO 能够充分利用数据的稀疏性和空间局部性,这在处理低搜索质量要求时特别有利。
在高搜索质量场景中,例如 R1@100=0.99,导致增加了选择的搜索点的数量。此外,有必要计算实际距离以满足此严格的精度要求。这两个因素限制了利用稀疏性的优势。然而,尽管有这些限制,JUNO 方法仍然实现了与 baseline 相比2.4倍的吞吐量提高,这是由于 RT 核心中采用了基于树的搜索方法。
TTI1M 数据集使用内积度量(即 MIPS)。由于 JUNO-H 会计算每个子空间中的精确距离,因此其性能提高了 2.04 倍,与前两个使用 L2 指标的数据集类似。FAISS 的 baseline 也只能达到 0.96 的召回率。而基于命中计数的方法放弃了t hit信息,相交只意味着在 L2 距离方面接近,而不是在内积方面相似。因此,在具有内积相似性的数据集中,搜索质量会迅速下降。因此,代表 JUNO-L 的直线向左移动。
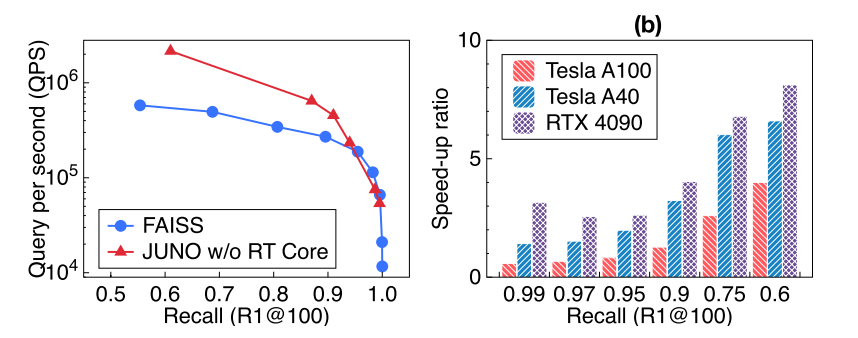
图11
最后,作者使用不同的 GPU 评估了 JUNO 在有 RT 内核加速和没有 RT 内核加速时的性能。图 11(a) 显示了 JUNO 和 baseline 在不带 RT Core的 GPU Tesla A100 上的详细性能。使用 SIFT1M 数据集上进行了评估。baseline 配置为 PQ16+HNSW(其他配置中性能最好的)。我们发现,在 Tesla A100 上,JUNO 在搜索质量要求较低的情况下仍有显著提升,这意味着优势完全来自基于阈值的选择算法。这一结果也验证了在典型的 IVFPQ 流程中利用稀疏性和空间相似性是合理的。在搜索质量要求较高的情况下,JUNO 的性能会逐渐低于基线,因为使用 CUDA 内核模拟光线跟踪的开销会抑制稀疏性带来的微小积极效果。
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

