赛题名称:表格结构识别挑战赛 赛题类型:计算机视觉、版面分析 赛题任务:识别单元格框和行列信息
比赛地址:https://challenge.xfyun.cn/topic/info?type=structure
视频答辩地址:https://www.bilibili.com/video/BV1nb4y1T7kr?p=3
赛事背景
在这个知识信息时代,文档是知识数据库创建、光学字符识别(OCR)、文档检索等众多认知过程的重要信息来源。表格作为一种特殊的实体,以简洁的形式传达重要信息,在金融、行政、档案文件等领域非常普遍。利用计算机对表格结构进行识别还原,能够辅助人类更高效地处理表格信息,具有非常重要的应用价值。
随着深度学习的迅猛发展,表格结构识别技术也取得了许多新的进展。为全面评估表格结构识别系统的性能,本次赛题收集了来源不同场景下的表格图像数据(包含有线表格和无线表格),如电子文档、拍照表格图像等。部分表格图像存在复杂背景、图像形变等,使得该任务极具挑战性。我们非常欢迎学术界和工业界的研究人员加入挑战,一起深入探讨表格结构识别技术。
赛事任务
本竞赛关注解决表格结构识别,而非表格识别(考虑表格单元格的文本内容)。
在数据标注部分,提供表格图像内所有文本行的检测框,以及文本检测框间的行列信息标注,对于部分有线表格和少线表格,还会额外提供表格单元格框标注。
参赛者需利用训练集中的图像和标注数据训练模型;在测试阶段仅提供表格图像,参赛者须给出表格单元格框和行列信息。
评测指标采用F1-Measure和TEDS-Struct进行综合评测。训练阶段允许附加使用公开的表格数据,但不允许使用除竞赛数据外的任何私有数据。
评审规则
本次比赛为参赛选手提供了12104份训练表格数据,每份表格数据都提供了全面的人工标注文本行检测框,以及文本行检测框间的行列信息,对于部分有线表和少线表,还额外提供表格单元检测框,如下图1所示。
评估指标
评价方式采用F1-Measure和TEDS-Struct进行综合评价,以此衡量预测结果跟标注结果的结构相似度。每张图像将得到一个score,范围0-1,1代表完全预测准确。最终结果取所有图像得分的平均分。排名按得分从高到低排序。(主办方提供评测代码)。
优胜方案
第一名
人们可能会好奇为什么要关注表格结构识别这个问题,尤其是在与药物研发等看似无关领域。然而,表格中包含的化合物结构信息和生物活性数据对于药物研发者而言是宝贵的构架关系数据。这种数据可以在后续药物设计中提供重要参考。参与过分子图像识别比赛并获得第一的经验,以及在文献中自动提取化合物结构的系统的开发,为我对表格结构识别问题的兴趣提供了基础。

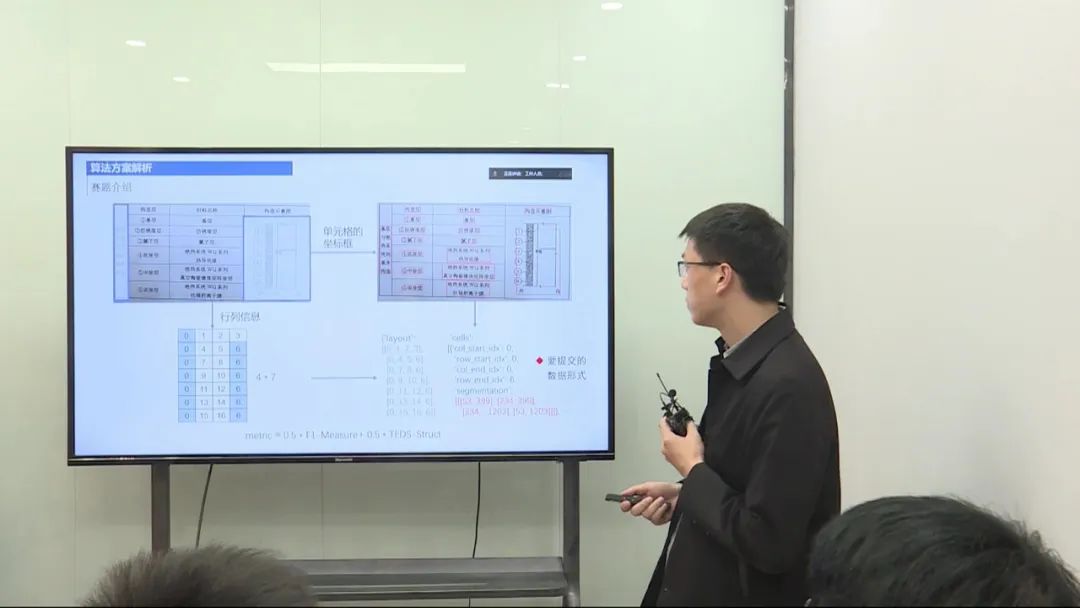


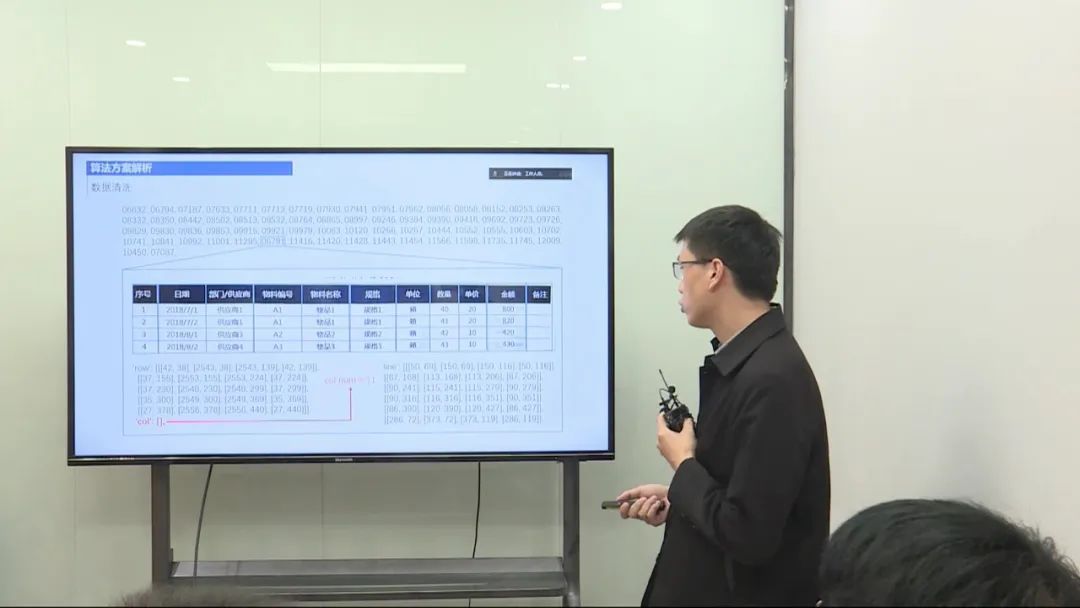

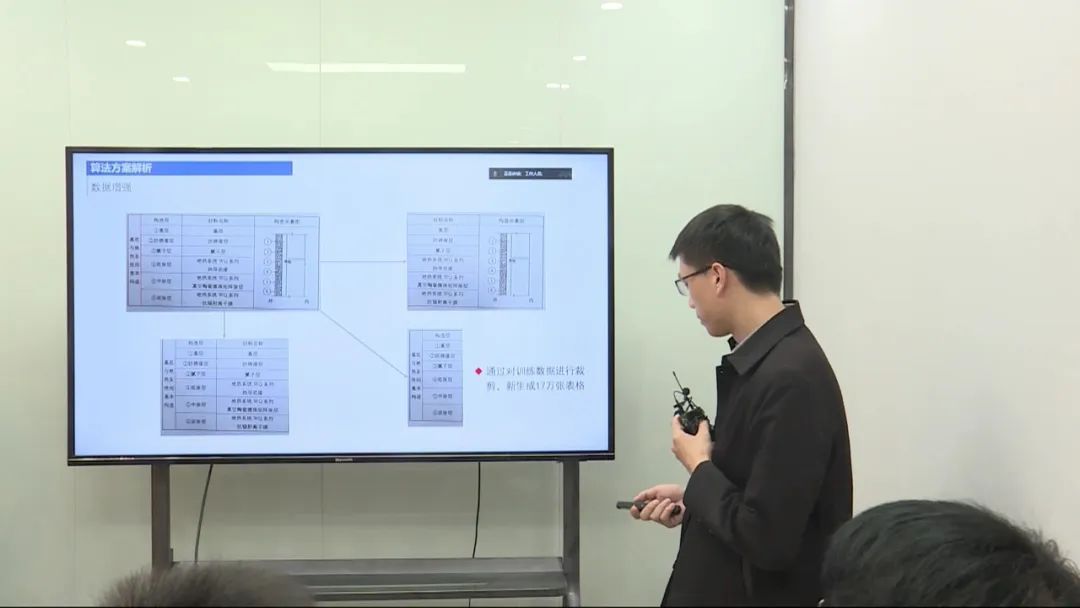
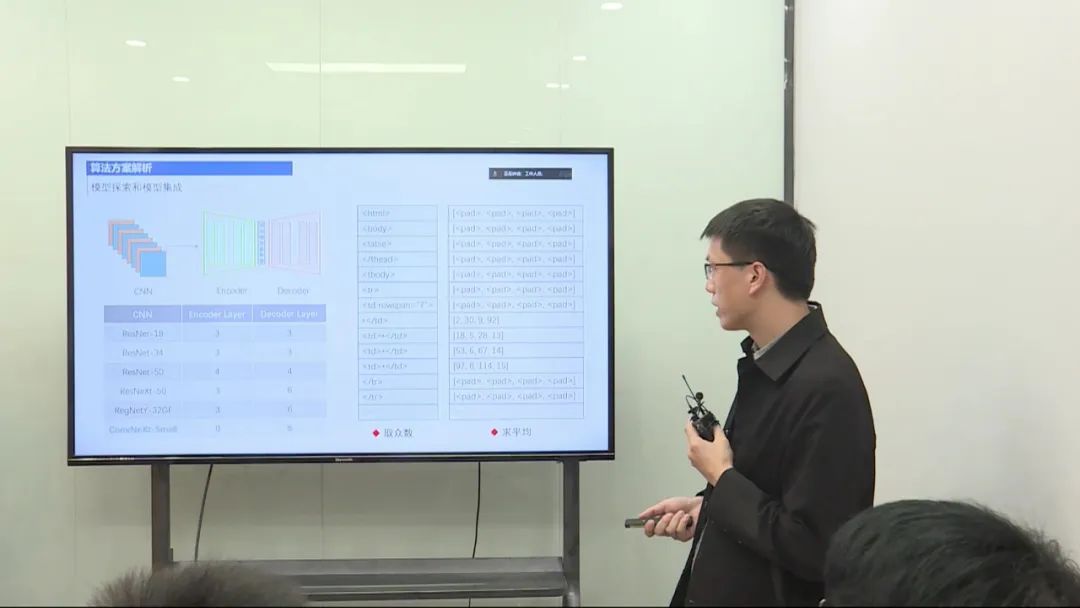

算法设计
表格结构识别任务要求预测表格的行列信息和单元格的合并情况,同时确定每个单元格的坐标框。我将问题转化为一个图像生成任务,使用CNN和Transformer结合的模型结构。生成的序列包括文本序列(描述表格的行列信息)和坐标框序列(用于记录单元格的坐标)。进行了数据清洗,使用了额外的公共表格数据进行预训练,以及采用了数据增强策略。
模型优化过程
在优化过程中,尝试了不同的网络结构,发现参数量越大性能越好,而采用ConverLess网络搭配六层串行Transformer的结构效果最佳。使用了多个checkpoint进行推理,并对预测结果进行集成。最后,对模型的预测结果进行后处理,解决了一些不合法的表格预测问题。
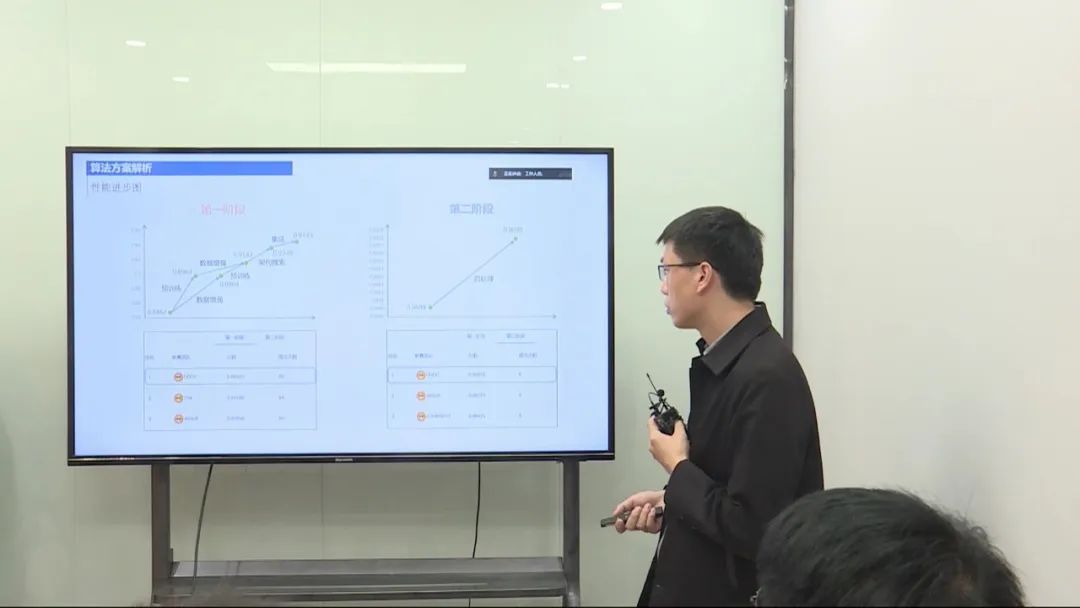
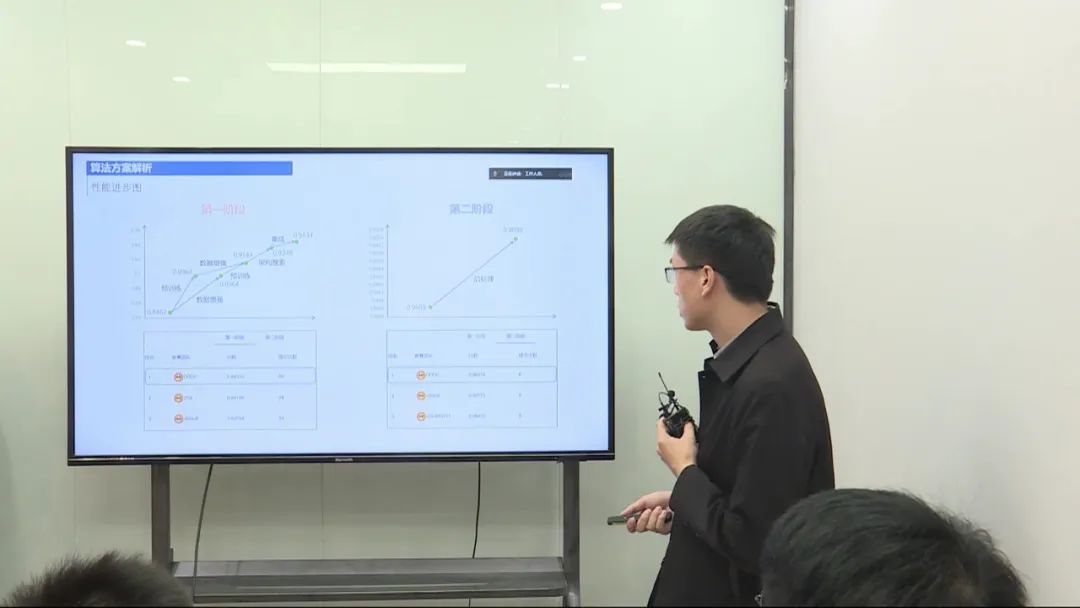
比赛阶段及成绩
比赛分为两个阶段,使用A榜和B榜数据进行开发和测试。在经过模型的不断优化和集成后,A榜阶段模型得分从0.84提升到0.94。在B榜测试阶段,初始得分为0.9689,加入后处理后提升至0.9698。最终,与其他分赛道的冠军一起,在国际图像图形学会上获得季军。
模型缺陷和未来工作
模型存在一些明显的缺陷,尤其是对于跨多行的单元格的预测。提出了三种可能的解决方案,包括合成数据以增强模型性能、使用强化学习通过验证结果反馈给模型、以及尝试新的表征语言来描述表格结构。这些方案为未来进一步优化和发展提供了方向。
第二名
任务描述: 本次任务的主要目标是提高表格自动转录的效率,实现文档的正规化。我们的团队将提供表格图像,要求在给定单元格框和行列信息的情况下进行处理。


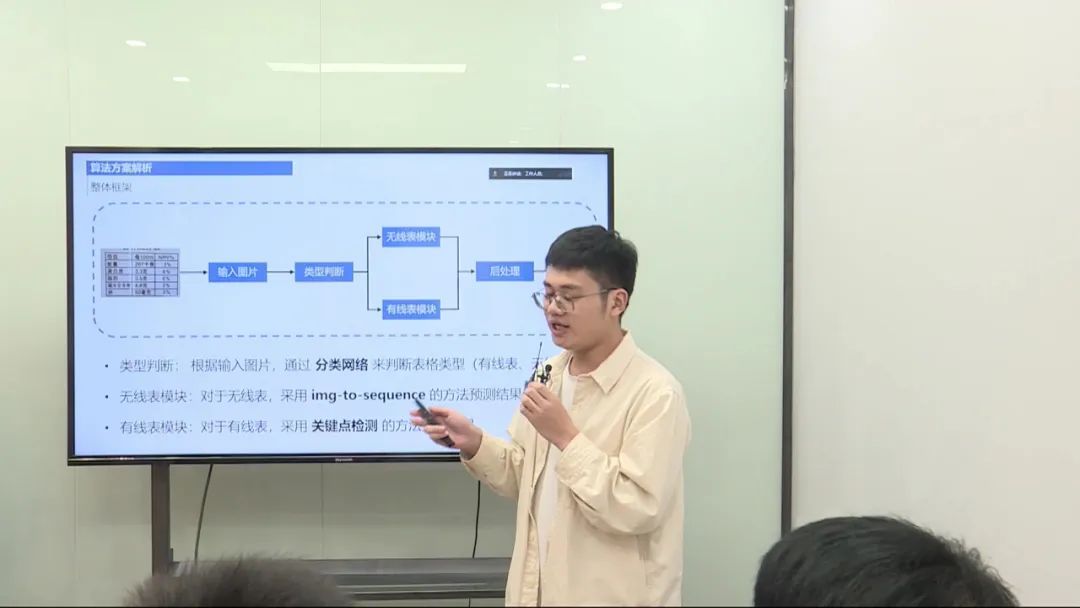







难点分析: 任务难点主要包括表格类型的丰富性(有线表、无线表、拍摄表、电子表)、复杂的表格结构(跨行跨列较多、存在空单元格)、图像中的干扰信息等因素。
解决方案概述
表格类型判断
背景与动机: 有线表和无线表在特征上存在显著差异,因此我们采用一个类型判断模块,将表格分为有线表和无线表进行单独处理。
流程: 使用一个backbone和池化层,通过得到的分数将表格划分为两类。对于无线表,采用Image to Sequence方法进行预测,得到HM序列和文本框坐标;对于有线表,采用观点 to Sequence方法进行预测,通过关键点检测获取单元格顶点。
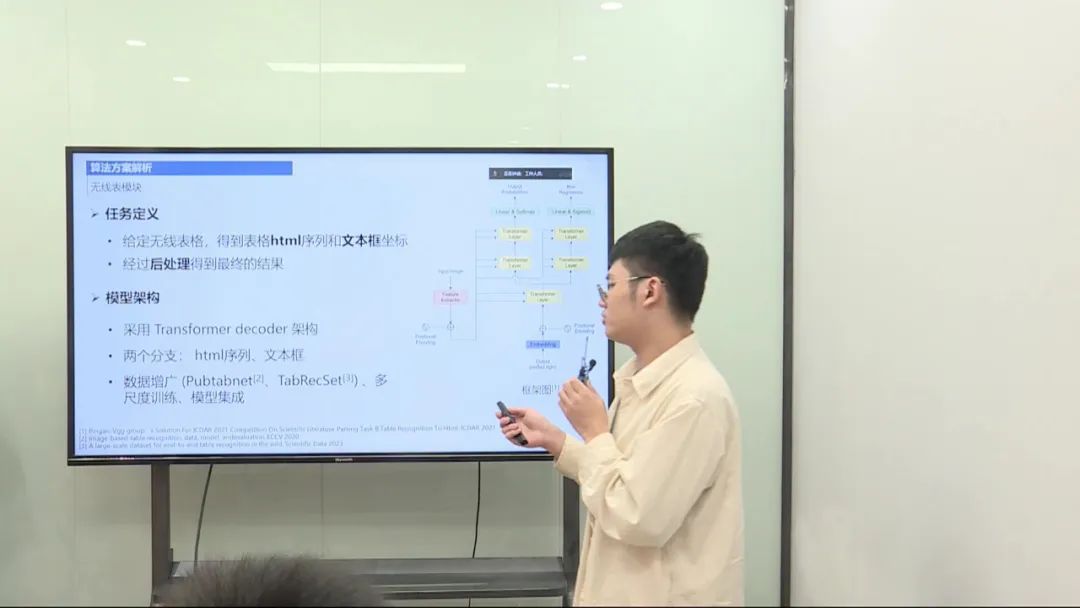
无线表处理
模型: 采用Transformer decoder结构,包含HM序列和文本框坐标两个分支。
数据增广: 在PubTimeNet和TypeRECSet数据集上进行数据增广,包括多尺度、trigger等。
模型集成: 考虑多尺度的模型集成策略。
有线表处理
模型: 使用HRNet进行表格观点检测,从而得到单元格的顶点。
模型特点: HRNet保持高分辨率,适用于密集点表格点检测任务。
后处理: 对于检测到的顶点,进行后处理,包括点的分类(左上角、右下角、交叉点、其他点)以及结构化的输出。
实验结果
比赛表现: 在A榜上获得第三名,在B榜上获得第二名,证明我们的模型和算法相对强大。
后续优化思路
问题与改进: 针对基于回归的预测方法中单元格漂移的问题,可以考虑将坐标看作序列,采用自回归方式进行预测。对于有线表的顶点漏检问题,可以综合考虑同时检测单元格,以提升准确性。
未来方向: 探索将坐标视为序列的自回归方式,同时继续优化有线表的观点检测,结合单元格检测来提高综合效果。
第三名
在我们的解决方案中,主要任务是对表格图像进行理解,包括有线表格和无线表格的处理。有线表格指的是具有清晰边界的表格,而无线表格可能是自然场景下存在形变的表格。我们采用了两个不同的网络结构,一个用于有线表格,另一个用于无线表格。


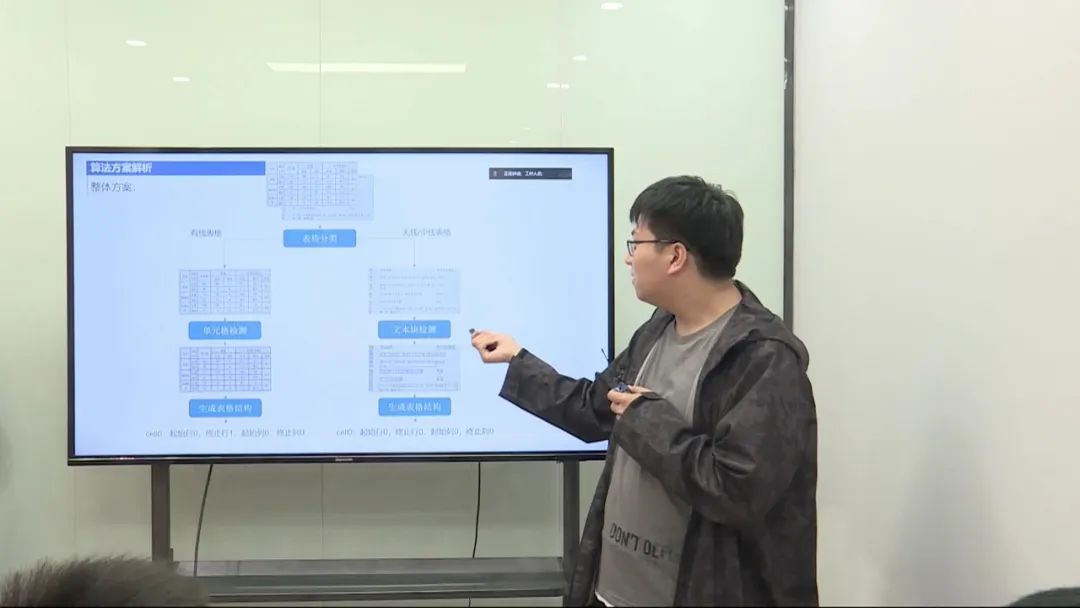
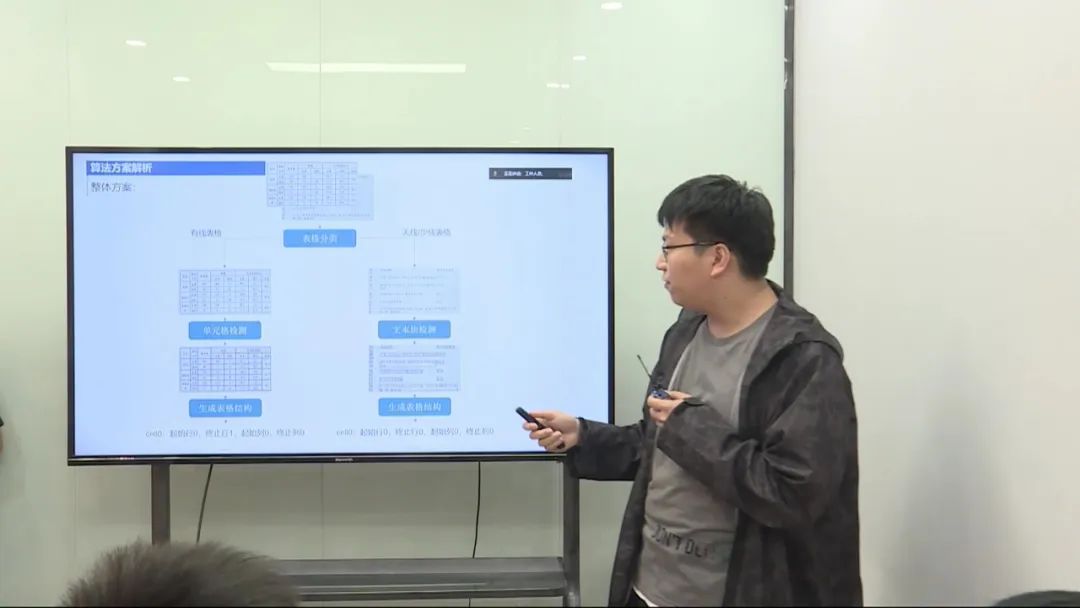



有线表格处理
我们首先对输入的表格图片进行分类,将其分为有线表格和无线表格两类。如果是有线表格,我们采用单元格检测网络,用于检测每个单元格的真实位置。
有线表格结构生成
有线表格结构生成相对较简单,因为这类表格一般是横平竖直的。我们采用了一个四点检测网络,通过检测单元格的四个角点来推测表格的轮廓。接着,我们利用检测到的轮廓进行表格的矫正,以获得规整的表格结构。矫正过程包括单元格检测、脚点推测、轮廓估算和TPL矫正。
无线表格处理
对于无线表格,由于其形变和缺少明显线条,我们采用了深度学习方案。我们使用了阿里开源的LORE模块,该模块通过端到端学习,可以自动预测表格中每个单元格的位置、行列号。
结果和优化思路
在比赛结果中,我们获得了第三名。对于表格分类部分,我们认为无需过度优化,因为简单的网络已经能够取得很好的进展。然而,在单元格检测和文本块检测方面,仍存在较大的优化空间。一些先进的方法,如W7W,可以在这方面发挥作用。由于比赛要求提供代码,部分算法暂时无法开源,但这并不妨碍我们使用基本的MAS SN等算法。
总结与展望
综合而言,我们的解决方案在有线表格和无线表格处理上采用了不同的网络结构,并取得了令人满意的比赛成绩。未来,可以考虑结合一些编解码的方案,如IBM的Typo Formal,以进一步提高文本识别和表格结构的准确性。这样的方法可以通过将表格结构转化为HTML序列,实现联合训练文本识别和表格结构的两个分支。