




今天给大家分享下 Kubernetes 批调度(Batch Scheduler),文章内容也在鹅厂团队内部分享过,有理解不对的地方,欢迎大家留言指正。文章内容较长,看完预计需要15分钟。
初次接触批调度还是在百度工作的时候。那会儿为了解决分布式任务调度问题,就引入了批调度组件,并基于批调度写了个 Kubernetes webhook。不过,写完后我就离职了,后来也不清楚具体的使用效果。接触批调度后,感觉确实是个好东西。特别是看完 Volcano 源码后,感觉人家代码写的还是挺好的。
进入正题,本文主要是为了介绍 Kubernetes 的批调度,文章分为以下几个部分:
Kubernetes 架构以及概念简介
Kubernetes 默认调度器介绍
Kubernetes 批调度开源服务 Kube Batch 以及 Volcano 介绍
首先,进入第一部分“Kubernetes 架构以及概念简介”,已经对 Kubernetes 较为了解的同学可以跳过这部分。写第一部分的目的是为了让不了解 Kubernetes 的同学对 Kubernetes 有个大致了解,从而对阅读本文内容有个基本的概念认识。
Kubernetes 架构
Kubernetes 从物理架构上分为 Master 节点以及 Worker 节点,如下图所示。
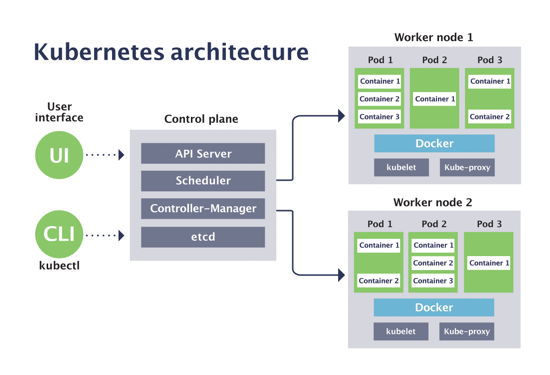
图1 Kubernetes 架构(图片来源:https://blog.sensu.io/how-kubernetes-works)
Master 节点用于运行控制面的服务,包括:
API Server:提供 Kubernetes 所有 API 接口的服务
Scheduler:用于调度 Kubernetes Pod 的服务
Controller Manager:用于管理 Kubernetes 基本负载的服务
etcd:用于存储 Kubernetes 的元数据信息,需要注意 etcd 是一个单独的开源项目(参考:https://github.com/etcd-io/etcd)
Worker 节点用于运行实际的负载任务,包括:
Kubelet:用于管理运行在节点上的负载任务,以及收集节点信息
Kube-proxy:用于管理 Kubernetes Service 网络,并作为节点间服务(Service)通信的代理
Kubernetes 基本概念
Kubernetes 上的概念有很多,本文只介绍一些基本的概念,或者说对理解本文够用的概念。为了便于理解,我将一些基本概念画到了一张图上,如下图所示。
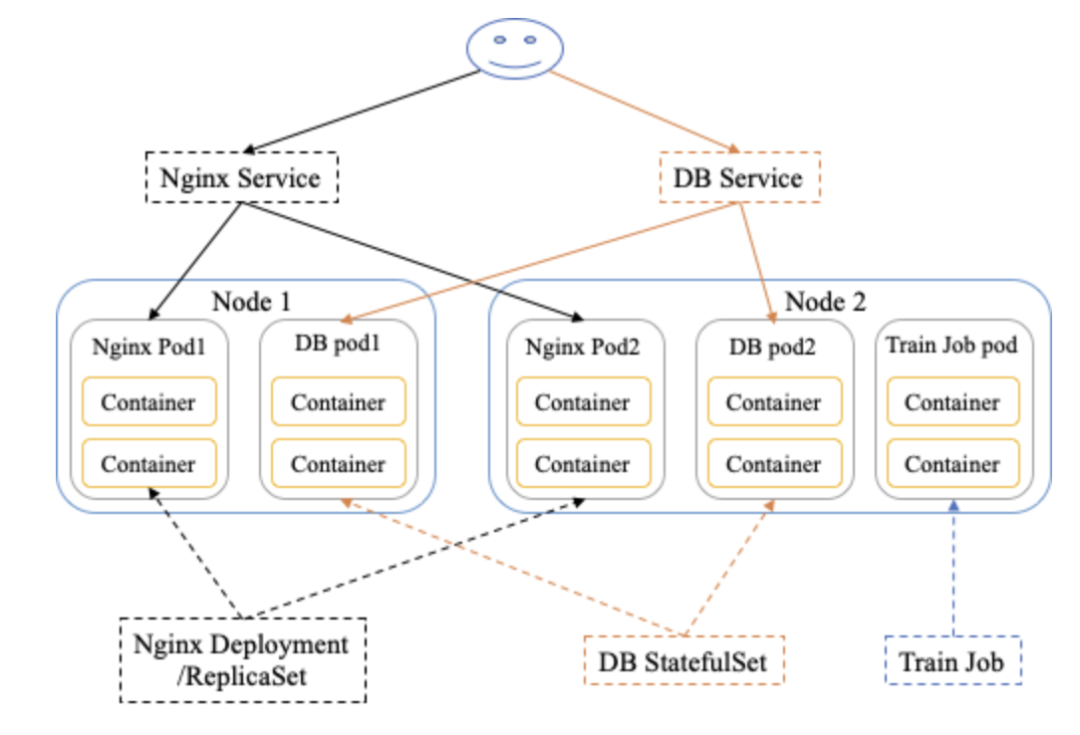
图2 Kubernetes 基本概念图(自己画的,太丑别见怪)
了解 Kubernetes 概念可以从节点、负载任务、网络这几个方面入手。
节点上,包括如下基本概念:
Node:工作节点基本单位,对应一台物理服务器(或者虚拟机)
Pod:工作负载基本单位,Pod 是一组容器的集合,这组容器共享网络命名空间和存储
负载任务上,包括如下基本概念:
Job:用于运行短周期任务的负载,对应任务结束,Job 即结束
Deployment/ReplicaSet:用于运行 Long Running 无状态服务的负载,特点在于多副本控制,可以进行水平扩展,所以适合运行无状态服务。Deployment 与 ReplicaSet 的区别在于,ReplicaSet 只负责多副本控制,Deployment 多了滚动升级与版本控制的能力
StatefulSet:用于运行 Long Running 有状态服务的负载,与 Deployment 的不同之处就在于“有状态”,它会为每个 Pod 生成唯一的序号标识,Pod 之间无法进行替换
网络上,包括如下基本概念:
Service:为负载任务提供一个稳定的访问IP,由于 Pod 异常/重建后,IP 地址会进行更换,所以在需要为访问端提供一个稳定 IP 时,可以使用 Service
Ingress:用于管理集群外部对集群内部负载任务的访问,需要注意 Ingress 只支持 HTTP 或者 HTTPS
接下来,进入第二部分“Kubernetes 默认调度器介绍”。本文在这部分将讲述 Kubernetes 默认调度器的调度流程以及一些基本策略。
Kubernetes 默认调度器
Kubernetes 调度器的目的就是将未调度的 Pod 按照调度策略绑定到合适的 Node。我们先来看下一个 Job 从创建到运行的整体流程,如下图所示。
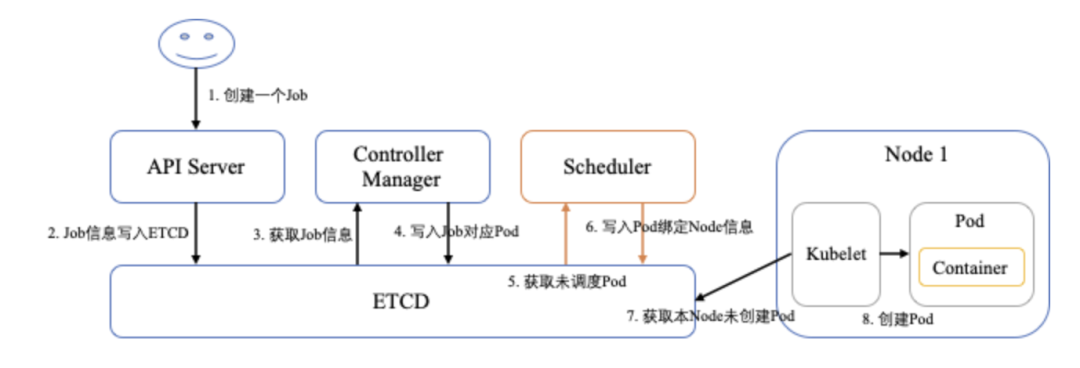
图3 Job 从创建到运行的流程(注意:为了便于理解,图中箭头直连 ETCD,实际上只有 API Server 会访问 ETCD)
整体流程如下:
客户端访问 API Server 创建一个 Kubernetes Job 任务,API Server 将 Job 信息写入 ETCD
Job Controller 监听 API Server 发现 ETCD 中还有未处理的 Job 任务,于是获取 Job 任务信息并根据任务信息生成对应的 Pod,然后将 Pod 信息通过 API Server 写入 ETCD
Kube Scheduler 监听 API Server 发现 ETCD 中还有未调度的 Pod,于是获取未调度的 Pod 信息并根据调度策略计算出合适的 Node,然后通过 API Server 将 Pod 绑定到 Node 上
Node 上的 Kubelet 监听 API Server 发现 ETCD 中还有本 Node 未启动的 Pod,于是获取未启动的 Pod 信息并创建 Pod 对应的容器,然后将启动结果通过 API Server 写入 ETCD
从上述一个 Job 的运行过程可以看出,第三步 Kube Scheduler 会将未调度的 Pod 绑定到合适的 Node 上,那具体的调度过程是什么呢?接下来将介绍下 Kubernetes 默认调度器的计算过程,如下图所示。
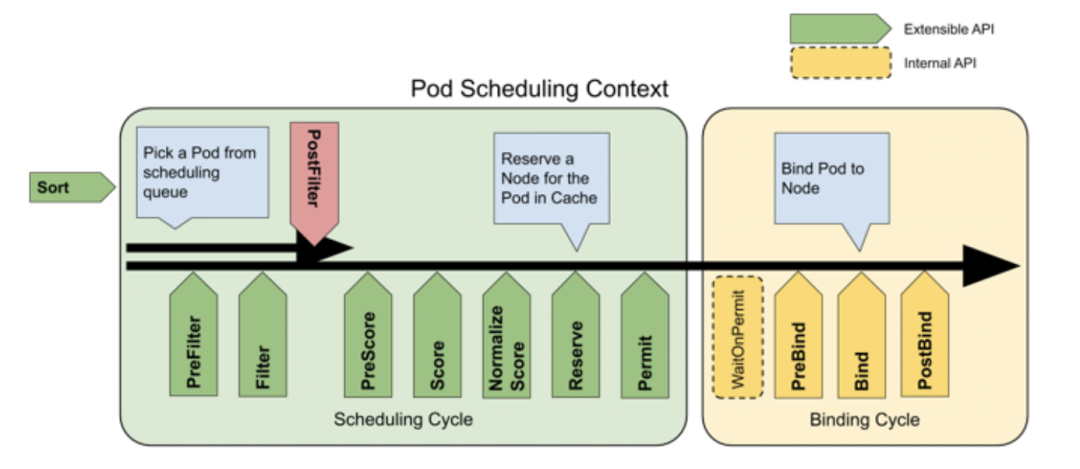
图4 Kubernetes 调度器框架(图片来源于官网)
Kubernetes 默认调度器的计算过程分为“预选”和“优选”两个步骤:
预选(Predicates):根据预选策略过滤掉不合适的节点集
优选(Priorities):在预选后的节点集中,根据优选策略计算每个节点的分数,选择分数最高的节点,将 Pod 绑定到该节点
Kubernetes 的预选和优选策略有很多,本文就不做详细描述,感兴趣的同学可以查看:https://kubernetes.io/docs/reference/scheduling/policies/。
接下来进入第三部分“Kubernetes 批调度开源服务 Kube Batch 以及 Volcano 介绍”,本文在这部分将介绍为什么需要使用批调度,以及介绍 Kube Batch 和 Volcano 这两个开源组件。
Kubernetes 默认调度器的限制
从上述 Kubernetes 默认调度器的介绍可以看到,Kube Scheduler 在每次调度过程都会从调度队列中选择一个 Pod 进行调度计算,所以它的调度过程是一个 Pod 一个 Pod 调度。这种调度方式对大数据分布式任务或者 AI 分布式训练任务的支持不够友好,如下图所示。
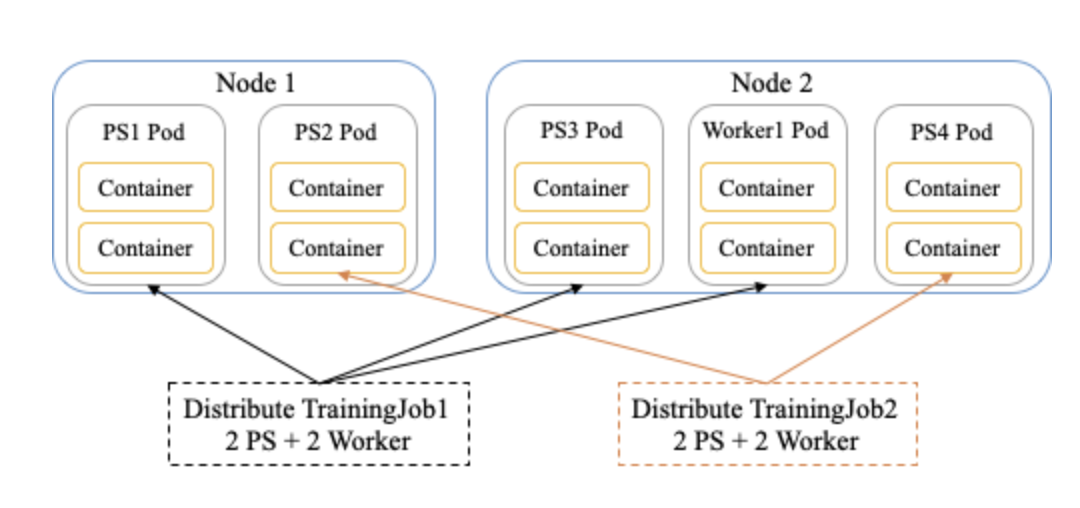
图5 Kube Scheduler 对分布式任务支持不够友好的解释
假设目前集群有 2 个 Worker Node,需要运行 2 个分布式训练任务,每个训练任务需要运行 2 个 PS(Parameter Server) 任务和两个 Worker 任务。从图中可以看出,经过调度后,TrainingJob1 起了 2 个 PS 和 1 个 Worker,TrainingJob2 起了 2 个 PS。此时,只有 TrainingJob1 开始训练,而 TrainingJob2 占着 2 个 PS 任务的资源,却无法进行训练。同时,由于 TrainingJob2 占着资源,TrainingJob1 无法启动第二个 Worker,训练速度也受到了影响。
那针对于这种分布式任务的场景,有什么比较好的解决方法?接下来要介绍的两个 Kubernetes 批调度开源组件就能够较好地解决这个问题。
在正式介绍 Kubernetes 批调度之前,先夸夸 Kubernetes。Kubernetes 是一个具备灵活性和可扩展性的开源服务,体现在:
支持自定义资源,通过 Kubernetes CRD(Custom Resource Definitions),使用 YAML 文件定义并向 API Server 注册一个资源对象,你就可以通过 API Server 进行 CURD 操作。如果你定义的对象有控制需求,可以通过实现对应的 Controller 来控制自定义对象的生命周期。现在各种开源的 Operator 就是基于 Kubernetes CRD 以及 Controller,例如 TFOperator、Spark Operator、MPI Operator、Prometheus Operator 等等。
支持自定义调度器,你可以自己实现一个 Pod 调度器注册到 Kubernetes,在创建 Pod 时,只需要指定 schedulerName = <自定义调度器>,该 Pod 即可通过你的自定义调度器进行调度。下面要介绍的 Kubernetes 批调度开源组件,就是通过这种方式实现。需要提醒的是,如果在 Kubernetes 内运行多个调度器,这些调度器最好根据不同计算资源进行调度。否则,有可能发生调度后无法运行或者资源竞争的情况。
丰富的插件机制,针对网络的 Network Plugin,针对存储的 Volume Plugin,针对硬件层的 Device Plugin 等等,你可以根据自己的需求场景,使用插件机制进行定制化开发。
Kubernetes 的灵活性和可扩展性体现在很多方面,本文只举了几个个人觉得能够体现的点进行描述,感兴趣的同学可以多调研学习下。接下来将介绍 Kube Batch 和 Volcano 这两个 Kubernetes 批调度开源组件。
Kube Batch
Kube Batch 是 Kubernetes 的一个调度子项目,该开源项目创建于 2017 年 7 月份。它的主要目的就是为了解决上述的大数据或者 AI 分布式任务场景,如下图所示。
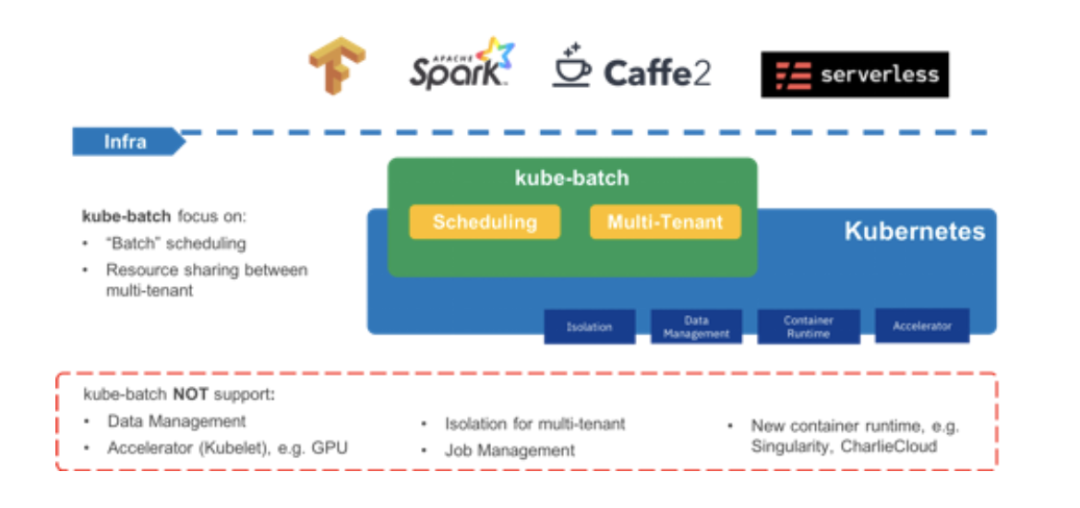
图6 Kube Batch 架构图(图片来源于官网)
从图中能够看出,Kube Batch 专注于 “Batch” Scheduling,所以它是一款增强型的 Kubernetes 调度器。目前的使用者(参考官网:https://github.com/kubernetes-sigs/kube-batch)有:
Kubeflow
Volcano
Baidu Inc
TuSimple
MOGU Inc
Vivo
那 Kube Batch 是怎么解决上述 Kubernetes 默认调度在分布式任务场景的限制?如下图所示。
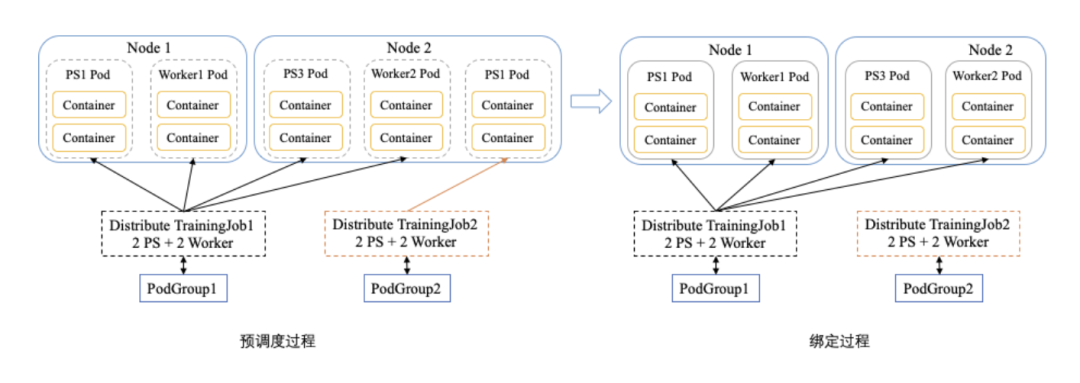
图7 Kube Batch 解决分布式任务场景解释
Kube Batch 定义了 PodGroup 资源对象,它是一组 Pod 的集合。在创建过程,只需要将 Pod 与 PodGroup 挂钩,Kube Batch 在调度时会计算与 PodGroup 挂钩的一组 Pod 资源是否满足创建需求。如果满足,则会一起创建,如果不满足,则都不创建。如图中,还是 2 个 Worker Node 和 2 个 TrainingJob。在预调度过程,Kube Batch 计算 TrainingJob1 所需资源,发现能够满足需求,而 TrainingJob2 不满足需求,则在绑定过程,只有 TrainingJob1 对应的 Pod 绑定到 Node 上进行创建。这种算法有个术语叫 Gang Scheduling,参考:https://en.wikipedia.org/wiki/Gang_scheduling。
我们再来看下 Kube Batch 内部调度流程如何实现,如下图所示:
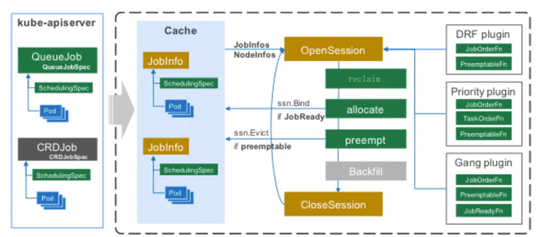
图8 Kube Batch 调度流程(图片来源于官网)
Kube Batch 内部包含如下几个模块:
Cache,该模块与 Kube APIServer 进行同步,缓存 Kubernetes 集群内的 Node、Pod、PodGroup、Queue 等资源对象信息。因此,通过 Cache 模块能够获取 Kubernetes 集群的资源情况与运行任务情况。
Session,该模块用于管理 Kube Batch 的调度过程,每次调度称为一次 Session 过程。Session 在启动调度时,会从 Cache 中复制集群信息,根据所复制的集群信息进行调度计算。
Action,一次调度包括多个 Action 操作,每个 Action 会根据当前配置的插件内容进行具体调度操作。Action 包括 reclaim、allocate、preempt 和 backfill。reclaim 用于队列间的资源分配,allocate 用于 Pod 调度计算,preempt 根据优先级决定队列内的资源抢占,backfill 用于回填具备资源运行的 Pod。
Plugin,用于实现不同调度策略,例如 DRF、Gang Scheduling,详细可参考:https://github.com/kubernetes-sigs/kube-batch/blob/master/doc/usage/tutorial.md
Volcano
Volcano 是华为的开源项目,该开源项目创建于 2019 年 3 月,在 2020 年 4 月被纳入 CNCF 官方项目,如下图所示。
图9 Volcano 概览(图片来源于官网)
通过 Volcano 在 GitHub 上的介绍语:“Volcano is a batch system built on Kubernetes”,可以看出相对于 Kube Batch 只专注于做调度器,Volcano 的目标是做一个 batch system。目前的生态(参考官网:https://github.com/volcano-sh/volcano)包括:
Horovod/MPI
kubeflow/tf-operator
kubeflow/arena
paddlepaddle
spark-operator
cromwell
相对于 Kube Batch,Volcano 除了实现批调度之外,还提供了 Batch Job 管理、易用客户端等模块,如下图所示。
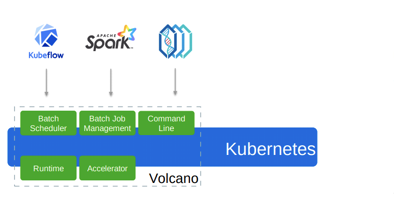
图10 Volcano 架构(图片来源于官网)
Volcano 中的模块包括:
Batch Scheduler:与 Kube Batch 类似,用于处理批调度
Batch Job Management:用于管理 Volcano 提供的 Batch Job
Command Line:提供了 vkctl 客户端工具
下面分别介绍下 Volcano 调度器与 Volcano Job。
Volcano 实现的调度器实际上是基于 Kube Batch 进行扩展,因此其调度流程不再重复描述。由于 Gang Scheduling 在介绍 Kube Batch 时已经完成介绍,所以在此只介绍 Volcano 另外两个调度策略,即 DRF(Dominant Resource Fairness) 和 Binpack。
DRF 调度策略其实在 Yarn 和 Mesos 这些大数据组件中较为常见,但在 Kubernetes 内没有实现,所以 Volcano 进行了补充。如下图所示。
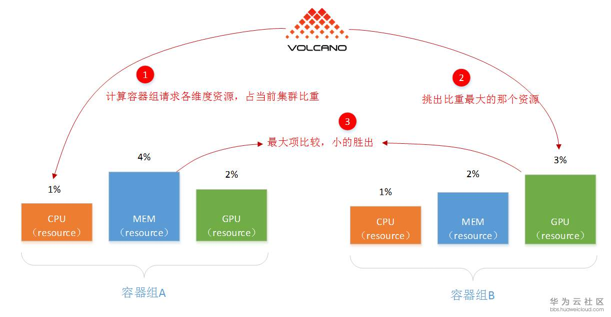
图11 DRF 调度策略解释(图片来源:https://bbs.huaweicloud.com/blogs/118181)
DRF 调度策略的主要目的就是不会因为大任务,饿死小任务。它的核心算法就是:谁用的资源少,谁的优先级就更高。如图中,容器组 A 相对于容器组 B 使用的资源更多,所以容器组 B 的优先级更高。
Binpack 调度策略是一种贪心策略,其目的是为了尽量占满单节点资源,减少碎片化问题。它的核心算法就是:哪个节点资源使用的多,哪个节点的优先级就更高。这种策略在 Kubernetes 中实际上是有的,对应的策略为:LeastRequestedPriority。如下图所示。
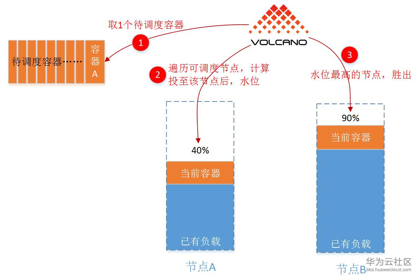
图12 Binpack 调度策略解释(图片来源:https://bbs.huaweicloud.com/blogs/118181)
从图中可以看出,分配后节点 B 的资源占用要比节点 A 更高,所以节点 B 的优先级更高。
Volcano 除了提供调度能力之外,还提供了 Batch Job 的管理。它是基于 Kubernetes CRD 实现的一种自定义负载,目的是为了兼容大多数主流的分布式任务,例如 TF-Operator 提供的 TFJob、Spark Operator 提供的 Spark Job 等。Volcano Job 支持如下特性:
Multiple Pod Template,支持配置多个 Pod 模板,为了对接分布式任务不同节点角色,例如 TFJob 中的 PS Pod 和 Worker Pod
Error Handling,支持根据 Pod 失败事件,触发不同的操作(重跑或者释放)。这项功能个人觉得比较有意思,更贴近于实际使用场景
Co-Scheduling,与 Kube Batch 中的 PodGroup 类似,支持一批 Pod 同时调度
Plugins for Job,为 Pod 提供一些可选的插件配置,包括:env、svc 以及 ssh。env 会在每个 Pod 内生成 VK_TASK_INDEX 环境变量;svc 为每个 Pod 创建 Kubernetes Service 以及生成 *.host 文件,用于通信;ssh 为每个 Pod 配置 ssh 免密,用于 ssh 免密访问。
一个 Volcano Job 的运行流程,如下图所示。
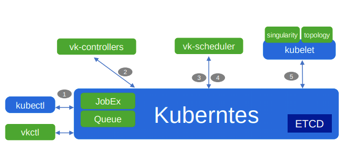
图13 Volcano Job 运行流程(图片来源于官网)
其实,步骤与上述 Kubernetes Job 基本一致,区别在于通过 vk-controllers 模块服务进行生命周期控制,通过 vk-scheduler 模块服务进行任务调度。
总结
本文旨在介绍 Kubernetes 批调度,包括三部分内容:
Kubernetes 架构以及概念简介,为大家更好地理解 Kubernetes 批调度建立一些基本概念
Kubernetes 默认调度器介绍,介绍了 Kubernetes 默认调度器以及存在的局限性
Kubernetes 批调度开源服务 Kube Batch 以及 Volcano 介绍,介绍了 Kubernetes 批调度需要解决的问题以及 Kube Batch、Volcano 两个开源组件
本文只是简单介绍了 Kubernetes 批调度,未深入探索 Kube Batch 或者 Volcano 的内部实现逻辑,希望能给大家建立一些初步概念。如果有描述不清或者描述不正确的地方,欢迎大家一起交流指正。
参考
Kubernetes调度器
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/kube-scheduler/
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/scheduling-framework/
https://kubernetes.io/docs/reference/scheduling/policies/
https://blog.sensu.io/how-kubernetes-works
Kube Batch
https://github.com/kubernetes-sigs/kube-batch
https://www.jianshu.com/p/042692685cf4
https://www.infoq.cn/article/PH7xwdf-qAUE3yTADsrV
Volcano
https://volcano.sh/
https://github.com/volcano-sh/volcano
https://bbs.huaweicloud.com/blogs/118181
https://zhuanlan.zhihu.com/p/77048090
https://www.infoq.cn/article/KWS04BcEdpqhOwE*4Mci
Volcano 目前应用范围比较广,感兴趣的同学可以深入学习下,并看看 Volcano 源码,确实代码写的挺好。一起加油吧,各位。
相关文章:Kubernetes 的学习路线
上一篇文章:整理的收获
