




“ 使用docker-compose快速搭建ELK+Filebeat日志系统”
ELK+Filebeat用于日志系统,主要包括四大组件:Elasticsearch、Logstash、Kibana以及Filebeat,也统称为Elastic Stack,官网地址:https://www.elastic.co/cn/。
大体的一个架构流程:
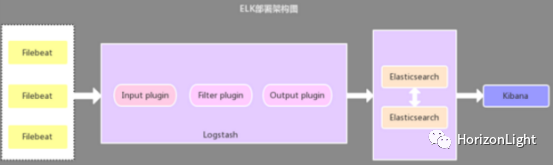
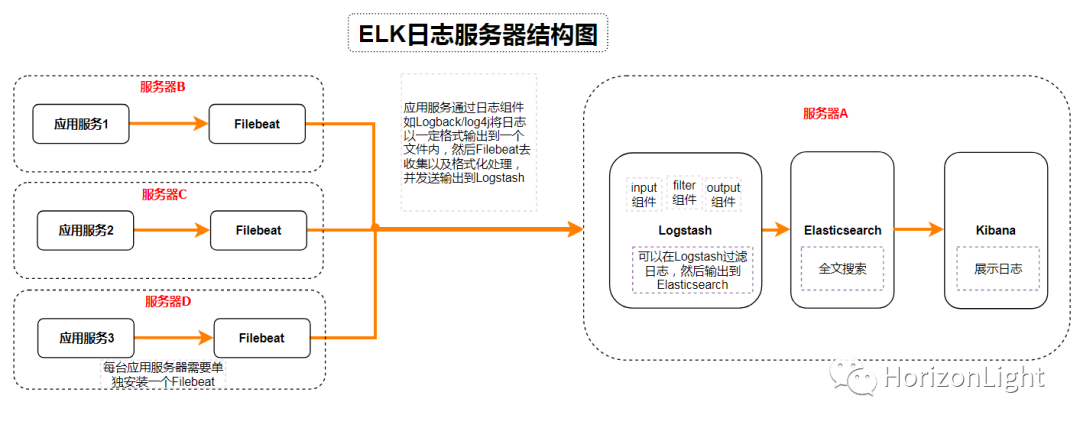
下面详细介绍 docker-compose 安装的过程(单机版),经测试可适用 6.8.1 以及 7.8.0 版本!
系统环境说明:
Linux版本:Ubuntu18.04
docker-compose编排部署,自行了解Docker知识
因资源有限,只在一台服务器操作演示,实际生产环境应该做到日志服务器与应用服务器分离
(一)创建相关目录路径
先上整体的一个目录结构:

创建一个elk目录:
mkdir elk
执行命令`cd elk`切换到elk目录下,然后在其下分别创建 elasticsearch、logstash、kibana、filebeat 目录以及各目录相关的需要挂载到容器中的配置文件:
mkdir elasticsearch logstash kibana filebeat
1)elasticsearch 配置
切换进去 elasticsearch 目录,创建 conf、data、logs 文件夹用于挂载容器中的数据卷:
mkdir conf data logs
在 conf 文件夹下新建一个 elasticsearch.yml 文件:
touch elasticsearch.yml
编辑并添加以下内容:
# default configuration in dockercluster.name: "elasticsearch" #集群名network.host: 0.0.0.0 #主机ip#network.bind_host: 0.0.0.0#cluster.routing.allocation.disk.threshold_enabled: false#node.name: es-master#node.master: true#node.data: truehttp.cors.enabled: true #允许跨域,集群需要设置http.cors.allow-origin: "*" #跨域设置#http.port: 9200#transport.tcp.port: 9300#discovery.zen.minimum_master_nodes: 1#discovery.zen.ping.unicast.hosts: *.*.*.*:9300, *.*.*.*:9301, *.*.*.*:9302
说明:
conf :用于挂载 elasticsearch 相关配置
data:用于挂载 elasticsearch 的数据,比如索引;运行一段时间后会存在elasticsearch磁盘占满的问题,所以可自行了解清除数据策略
logs:用于挂载 elasticsearch 的日志信息
2)logstash 配置
切换进去 logstash 目录,创建 conf 文件夹用于挂载容器中的数据卷:
mkdir conf
在 conf 文件夹下分别新建一个 logstash.yml 文件:
touch logstash.yml
编辑并添加以下内容:
## 和kibana的host一样,也需要设置成0.0.0.0才能启动成功http.host: "0.0.0.0"## 除了可以使用docker-compose.yml中elasticsearch的容器名如 "http://elasticsearch:9200"(前提是同属于一个docker network,且类型为bridge),也可以直接改成公网ipxpack.monitoring.elasticsearch.hosts: [ "http://106.52.202.31:9200" ]
以及新建一个 logstash.conf 文件:
touch logstash.conf
编辑并添加以下内容:
##input输入日志 beats用于接收filebeat的插件 codec设置输入日志的格式 port端口为logstash的端口input {beats {port => 5044}}##filter对数据过滤操作filter {}##output配置输出elasticsearch地址 可配多个 index为elasticsearch的索引,通过在kibana中Create index pattern去匹配#hosts 的公网ip,也可以填写docker-compose.yml中logstash的容器名如 "http://elasticsearch:9200"(前提是同属于一个docker network,且类型为bridge)output {elasticsearch {hosts => ["106.52.202.31:9200"]index => "test-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}}
说明:
logstash.yml:用于挂载 logstash 相关配置(可自定义进行拓展,参考官网文档)
logstash.conf:用于挂载 logstash 日志处理配置文件(可自定义进行拓展,参考官网文档)
3)kibana 配置
切换进去 kibana 目录,创建 conf 文件夹用于挂载容器中的数据卷:
mkdir conf
在 conf 文件夹下分别新建一个 kibana.yml 文件:
touch kibana.yml
编辑并添加以下内容:
### ** THIS IS AN AUTO-GENERATED FILE **##### Default Kibana configuration for docker targetserver.name: "kibana"## 必须设置为0.0.0.0才能访问到elasticsearchserver.host: "0.0.0.0"## host的公网ip,也可以填写docker-compose.yml中elasticsearch的容器名如 "http://elasticsearch:9200"(前提是同属于一个docker network,且类型为bridge)elasticsearch.hosts: [ "http://106.52.202.31:9200" ]
说明:
kibana.yml:用于挂载 kibana 相关配置
4)filebeat 配置
切换进去 filebeat 目录,创建 conf 文件夹用于挂载容器中的数据卷:
mkdir conf
在 conf 文件夹下分别新建一个 filebeat.yml 文件:
touch filebeat.yml
编辑并添加以下内容:
filebeat.inputs:- type: log #输入filebeat的类型 这里设置为log(默认),即具体路径的日志 另外属性值还有stdin(键盘输入)、kafka、redis,具体可参考官网enabled: true #开启filebeat采集paths: #配置采集全局路径,后期可根据不同模块去做区分- /var/elk/logs/*.log # 指定需要收集的日志文件的路径(容器内的文件路径,所以我们需要挂载)fields: #可想输出的日志添加额外的信息log_type: syslog## 设置符合同一个格式时多行合并输出multiline.pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}' #正则表达式 用于匹配是否属于同一格式 这里是日期正则表达式,表示如果是以yyyy-MM-dd开头的,则这一行是一条日志的开头行,会以接下来不是这个格式的内容聚合成一条日志输出multiline.negate: true # 是否需要对pattern条件转置使用 不转置设为true,转置为false 理解:假如设置为false,那么[multiline.match: after]表示为匹配pattern后,与前面的内容合并成一条日志multiline.match: after #匹配pattern后,与后面的内容合并成一条日志multiline.max_lines: 10000 #表示如果多行信息的行数超过该数字,则多余的都会被丢弃。默认值为500行multiline.timeout: 10s #超时设置 超时会把已匹配收集到的日志发送出去encoding: utf-8 #用于读取包含国际字符的数据的文件编码tail_files: true #从文件尾开始监控读取新增的内容而不是从文件开始重新读取发送 适用于未处理过的文件,已处理过的需要删除注册表文件output.logstash:hosts: ["106.52.202.31:5044"] #发送输出到logstash;host的公网ip,也可以填写docker-compose.yml中logstash的容器名如 "logstash:5044"(前提是同属于一个docker network,且类型为bridge)
说明:
filebeat.yml:用于挂载 filebeat 相关配置,一些格式配置(如多行合并输出等)可自行了解,参考官网文档)
注意`paths`参数的值,这里配置的是filebeat容器内的一个日志文件路径(自定义),而在服务器部署应用产生的日志路径是我们指定的(比如项目工程用到logback日志包,会在配置文件中指定日志输出路径),因此需要在docker-compose.xml文件中做数据卷挂载才能被filebeat日志采集器采集到并输出到logstash;` /var/elk/logs/*.log`表示该路径下以`.log`结尾的文件都会被当成日志采集
(二)编写docker-compose.yml文件
切换进去 elk 目录创建docker-compose.yml编排文件:
touch docker-compose.yml
编辑并添加以下内容(四大组件的镜像版本号应保持一致,避免出现问题):
version: "3.4" #版本号services:########## elk日志套件(镜像版本最好保持一致) ##########elasticsearch: #服务名称container_name: elasticsearch #容器名称image: docker.elastic.co/elasticsearch/elasticsearch:6.8.1 #使用的镜像 elastisearch:分布式搜索和分析引擎,提供搜索、分析、存储数据三大功能restart: on-failure #重启策略 1)no:默认策略,当docker容器重启时,服务也不重启 2)always:当docker容器重启时,服务也重启 3)on-failure:在容器非正常退出时(退出状态非0),才会重启容器ports: #避免出现端口映射错误,建议采用字符串格式- "9200:9200"- "9300:9300"environment: #环境变量设置 也可在配置文件中设置,environment优先级高- discovery.type=single-node #单节点设置- bootstrap.memory_lock=true #锁住内存 提高性能- "ES_JAVA_OPTS=-Xms512m -Xmx512m" #设置启动内存大小 默认内存/最大内存ulimits:memlock:soft: -1hard: -1volumes: #挂载文件- /media/elk/elasticsearch/data:/usr/share/elasticsearch/data- /media/elk/elasticsearch/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml- /media/elk/elasticsearch/logs:/usr/share/elasticsearch/logsnetworks: #网络命名空间 用于隔离服务- elkkibana:container_name: kibanaimage: docker.elastic.co/kibana/kibana:6.8.1 #kibana:数据分析可视化平台depends_on:- elasticsearchrestart: on-failureports:- "5601:5601"volumes:- /media/elk/kibana/conf/kibana.yml:/usr/share/kibana/config/kibana.ymlnetworks:- elklogstash:container_name: logstashimage: docker.elastic.co/logstash/logstash:6.8.1 #logstash:日志处理command: logstash -f /usr/share/logstash/pipeline/logstash.confdepends_on:- elasticsearchrestart: on-failureports:- "9600:9600"- "5044:5044"volumes: #logstash.conf日志处理配置文件 格式:#输入 input{} #分析、过滤 filter{} #输出 output{}- /media/elk/logstash/conf/logstash.yml:/usr/share/logstash/config/logstash.yml- /media/elk/logstash/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.confnetworks:- elkfilebeat:container_name: filebeatimage: docker.elastic.co/beats/filebeat:6.8.1 #filebeat:轻量级的日志文件数据收集器,属于Beats六大日志采集器之一depends_on:- elasticsearch- logstash- kibanarestart: on-failurevolumes: #filebeat.yml配置.log文件的日志输出到logstash #同时配置挂载需要扫描的日志目录,因为扫描的是filebeat容器内的文件路径- /media/elk/filebeat/conf/filebeat.yml:/usr/share/filebeat/filebeat.yml- /media/elk/logs:/var/elk/logsnetworks:- elknetworks:elk:external: true
说明:
假如配置`environment`环境变量,则会覆盖yml文件中的配置,否则就会读取yml文件配置;因此environment优先级大于yml文件
由于这四个容器间需要互相通信,所以我们需要创建一个名称为 elk 的 network:
docker network create elk
在不设置 driver 属性时,默认是bridge,可自行查看docker network相关内容
查看是否创建成功:
docker network ls
最后启动docker-compose编排:
docker-compose up -d
查看是否成功:
docker-compose ps

或者:
docker ps
假如启动失败或者想查看启动日志,可执行 logs 相关命令:
docker-compose logs -f
(三)测试 ELK+Filebeat 日志采集以及Kibana搜索
启动成功后,我们可以简单测试!
结合docker-compose.yml中 filebeat 容器的 /media/elk/logs:/var/elk/logs 数据卷挂载配置信息,以及 filebeat.yml 文件的 paths 配置信息,我们只要在 /media/elk/logs 路径下创建以 .log 结尾的日志文件,Filebeat就能读取这些文件中的数据并采集输出到Logstash,然后经Logstash进行过滤等操作,发送到Elasticsearch,最后在Kibana控制台创建索引格式进行条件筛查就能找到我们所需的信息。
在 /media/elk/logs 路径下创建一个日志文件 elk-test-2020-07-19.log 文件:
touch elk-test-2020-07-19.log
模拟输出日志信息到该文件中:
echo “2020-07-19 05:50:36,630 [SpringContextShutdownHook] INFO com.zaxxer.hikari.HikariDataSource 350 - 测试===========================================”>> elk-test-2020-07-19.log
然后执行`docker-compose logs`可看到 Logstash格式化日志信息:
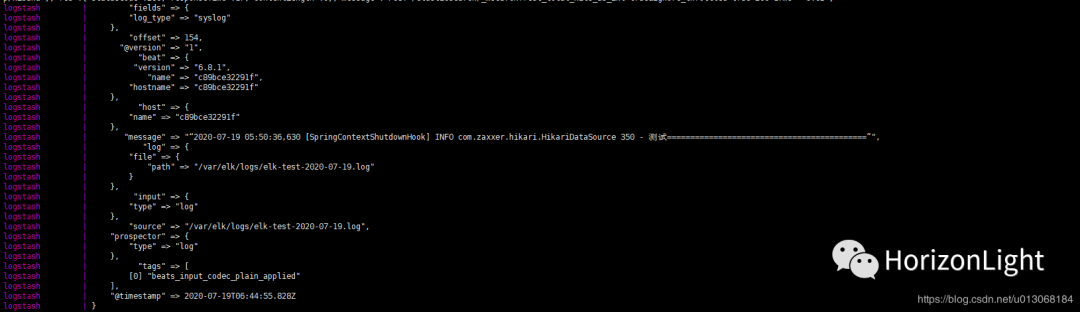
之后访问Kibana控制台(ip+映射的端口,默认是5601,第一次访问可能加载较慢):
创建索引模式:
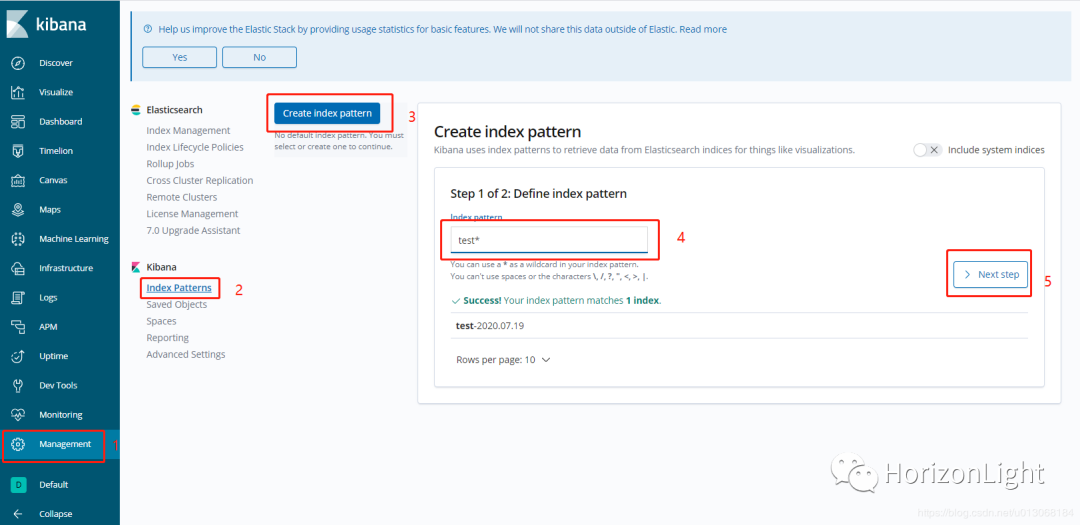
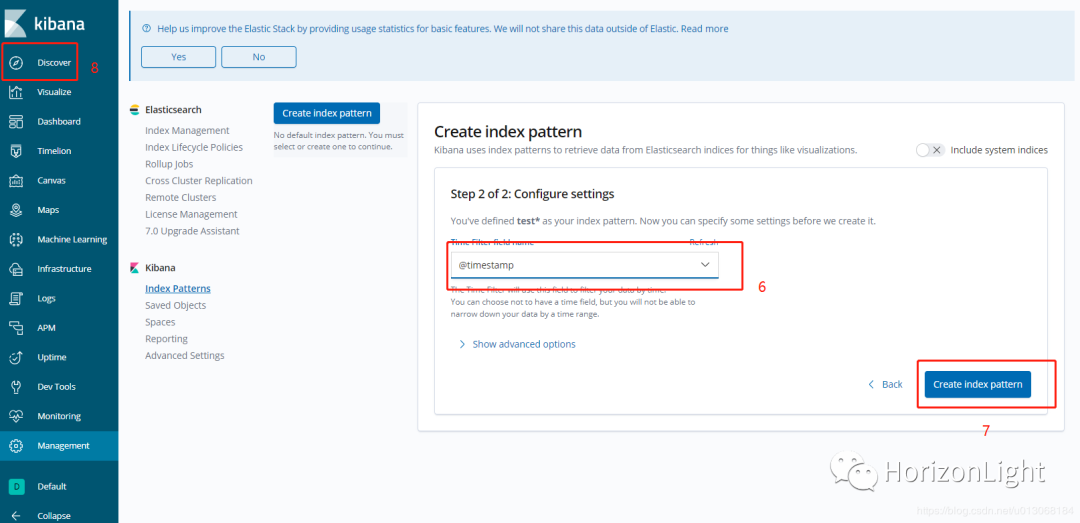
说明:第4步中的输入框,应该输入存在索引或索引通配符,索引已在 logstash.conf 中定义,所以这里输入 test 即可匹配到,然后在 Discover 中就能查找出日志信息(关于怎么使用Kibana,可自行了解)
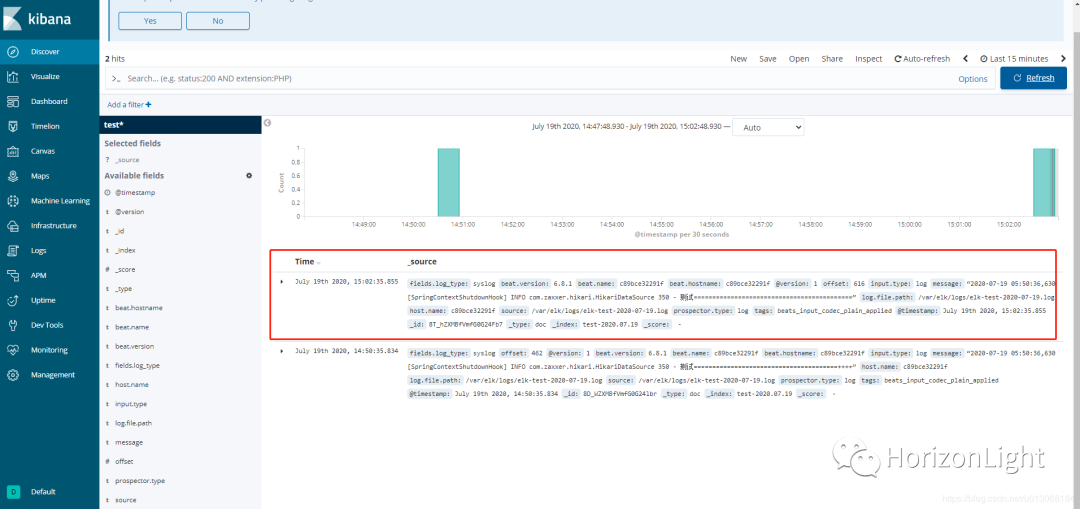
以下是6.8.1版本的,在7.8.0版本中,控制台ui略有改变,但步骤是一样的:
(四)可能会遇到的问题
1. docker-compose启动时Elasticsearch报错:
elasticsearch | Error: Could not create the Java Virtual Machine.elasticsearch | Error: A fatal exception has occurred. Program will exit.elasticsearch | [0.001s][error][logging] Error opening log file 'logs/gc.log': Permission deniedelasticsearch | [0.001s][error][logging] Initialization of output 'file=logs/gc.log' using options 'filecount=32,filesize=64m' failed.``

解决办法:因为挂载卷的访问权限不足,所以我们需要给Elasticsearch挂载卷授权,进入到`/media/elk/elasticsearch`分别给三个挂载卷授权:
chmod 777 conf data logs
2. docker-compose启动时发Elasticsearch或Logstash连接失败:
类似以下报错信息:
logstash | [2020-07-19T05:41:36,488][WARN ][logstash.monitoringextension.pipelineregisterhook] xpack.monitoring.enabled has not been defined, but found elasticsearch configuration. Please explicitly set `xpack.monitoring.enabled: true` in logstash.ymllogstash | [2020-07-19T05:41:37,517][INFO ][logstash.licensechecker.licensereader] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://0.0.0.0:9200/]}}logstash | [2020-07-19T05:41:37,740][WARN ][logstash.licensechecker.licensereader] Attempted to resurrect connection to dead ES instance, but got an error. {:url=>"http://0.0.0.0:9200/", :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>"Elasticsearch Unreachable: [http://0.0.0.0:9200/][Manticore::SocketException] Connection refused (Connection refused)"}logstash | [2020-07-19T05:41:37,808][WARN ][logstash.licensechecker.licensereader] Marking url as dead. Last error: [LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError] Elasticsearch Unreachable: [http://0.0.0.0:9200/][Manticore::SocketException] Connection refused (Connection refused) {:url=>http://0.0.0.0:9200/, :error_message=>"Elasticsearch Unreachable: [http://0.0.0.0:9200/][Manticore::SocketException] Connection refused (Connection refused)", :error_class=>"LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError"}logstash | [2020-07-19T05:41:37,818][ERROR][logstash.licensechecker.licensereader] Unable to retrieve license information from license server {:message=>"Elasticsearch Unreachable: [http://0.0.0.0:9200/][Manticore::SocketException] Connection refused (Connection refused)"}logstash | [2020-07-19T05:41:37,879][ERROR][logstash.monitoring.internalpipelinesource] Failed to fetch X-Pack information from Elasticsearch. This is likely due to failure to reach a live Elasticsearch cluster.

解决办法:因为是在Ubuntu系统公网上部署,所以查看防火墙端口是否开启,或者假如是阿里云或腾讯云服务器,需要在安全组开放Elasticsearch、Logstash、Kibana相关端口
3. docker-compose启动时Elasticsearch报错:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:因为用户拥有的内存权限太小,至少需要262144;切换到root超管,进入到/etc目录,执行编辑vim sysctl.conf,在最末添加属性行vm.max_map_count=262144,保存退出后执行加载系统参数命令sudo sysctl -p,然后输入命令sysctl -a|grep vm.max_map_count即可看到修改后的配置值,最后重新启动即可
4. docker-compose启动时Elasticsearch报错:
java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes/0/node.lock
解决办法:把Elasticsearch的挂载数据卷data路径下的数据删掉
最后线上项目结合ELK输出日志:
贴上一份 Logback日志组件的配置文件 logback-logstash.xml:
<?xml version="1.0" encoding="UTF-8"?><configuration debug="false" scan="true" scanPeriod="60 seconds"><!-- 读取spring容器中的spring.application.name属性 --><springProperty scope="context" name="appName" source="spring.application.name" /><!-- 线上linux环境 docker部署,这里配置的是项目容器内的地址,所以还需要将这个路径挂载到宿主机中filebeat挂载的日志收集路径 --><property name="logback.logDir" value="/project/logs"/><!-- 本地windows开发环境配置 不设置绝对路径时,默认在系统用户路径下 --><!--<property name="logback.logDir" value="E:\\filebeat-6.8.2-windows-x86_64\\filebeat-6.8.2-windows-x86_64\\data"/>--><!-- 日志输出编码格式化 --><property name="charset" value="UTF-8"/><!-- 日志保留时长,设置只保留最近15天的日志 --><property name="maxHistory" value="15"/><!--结合Sleuth自定义日志输出格式:%yellow() 指定颜色,需要用括号把内容括起来%d——日志输出时间 标准年月日时分秒格式%thread——输出日志的进程名字%-5level——日志级别,并且使用5个字符靠左对齐${appName}——spring配置文件的spring.application.name属性值%X{X-B3-TraceId}——Sleuth的traceId为一个请求分配的追踪ID号,用来标识一条请求链路。%X{X-B3-SpanId}——Sleuth的spanId表示一个基本的工作单元,一个请求可以包含多个步骤,每个步骤都拥有自己的spanId。一个请求包含一个TraceId,多个SpanId%X{X-Span-Export}——是否将Sleuth链路信息传输到Zipkin%logger{50}——日志输出者的名字%line——log在代码中埋点的行数%msg——日志消息%n——平台的换行符--><property name="consoleLogPattern"value="%d %yellow(%-5level [${appName},%X{X-B3-TraceId},%X{X-B3-SpanId},%X{X-Span-Export}]) [%thread] %green(%logger{50}) %line : %msg%n"/><!-- 格式化日志输出节点 --><!-- 自定义控制台打印设置 --><appender name="consoleAppender" class="ch.qos.logback.core.ConsoleAppender"><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="ch.qos.logback.classic.PatternLayout"><pattern>${consoleLogPattern}</pattern></layout></encoder></appender><!-- 日志系统设置 --><!-- info级别的日志输出配置 --><appender name="fileInfoLog" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 如果只是想要 Info 级别的日志,只是过滤 info 还是会输出 Error 日志,因为 Error 的级别高,所以我们使用下面的策略,可以避免输出 Error 的日志 --><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 过滤 Error --><level>ERROR</level><!-- 匹配到就禁止 --><onMatch>DENY</onMatch><!-- 没有匹配到就允许 --><onMismatch>ACCEPT</onMismatch></filter><!-- 日志名称,如果没有File 属性,那么只会使用FileNamePattern的文件路径规则如果同时有<File>和<FileNamePattern>,那么当天日志是<File>,明天会自动把今天的日志改名为今天的日期。即,<File> 的日志都是当天的。--><File>${logback.logDir}/info.${appName}.log</File><!-- 滚动策略,按照时间滚动 TimeBasedRollingPolicy --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 文件路径,定义了日志的切分方式——把每一天的日志归档到一个文件中,以防止日志填满整个磁盘空间 --><FileNamePattern>${logback.logDir}/info.${appName}.%d{yyyy-MM-dd}.log</FileNamePattern><!-- 日志保留时长 --><maxHistory>${maxHistory}</maxHistory></rollingPolicy><!-- 日志输出编码格式化 --><encoder><charset>${charset}</charset><pattern>${consoleLogPattern}</pattern></encoder></appender><!-- error级别的日志输出配置 --><appender name="fileErrorLog" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 如果只是想要 Error 级别的日志,那么需要过滤一下,默认是 info 级别的,ThresholdFilter --><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>Error</level></filter><!-- 日志名称,如果没有File 属性,那么只会使用FileNamePattern的文件路径规则如果同时有<File>和<FileNamePattern>,那么当天日志是<File>,明天会自动把今天的日志改名为今天的日期。即,<File> 的日志都是当天的。--><File>${logback.logDir}/error.${appName}.log</File><!-- 滚动策略,按照时间滚动 TimeBasedRollingPolicy --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 文件路径,定义了日志的切分方式——把每一天的日志归档到一个文件中,以防止日志填满整个磁盘空间 --><FileNamePattern>${logback.logDir}/error.${appName}.%d{yyyy-MM-dd}.log</FileNamePattern><!-- 日志保留时长 --><maxHistory>${maxHistory}</maxHistory></rollingPolicy><!-- 日志输出编码格式化 --><encoder><charset>${charset}</charset><pattern>${consoleLogPattern}</pattern></encoder></appender><!-- 用来指定最基础的日志输出级别 --><root level="info"><appender-ref ref="consoleAppender" /><appender-ref ref="fileInfoLog"/><appender-ref ref="fileErrorLog"/></root></configuration>
说明:
非容器部署应用项目,一般在 <property name="logback.logDir" value="/project/logs"/> 这个属性配置Filebeat读取的日志文件路径
假如应用项目也是docker部署的,那么需要将上面配置的/project /logs 挂载到服务器的 /media/elk/logs,然后再映射到Fileabeat容器的 /logs 路径下,这样Filebeat才能成功收集到日志数据
