




在生产环境中,除了会用到日志系统查看日志排查问题外,还需要针对整个系统的运行进行监控,比如监控到数据库出现异常,那么触发报警通知运维去紧急处理。目前比较流行使用Prometheus+Alertmanager+Grafana+Exporter搭建监控报警系统,以下是从官网截取的生态图:
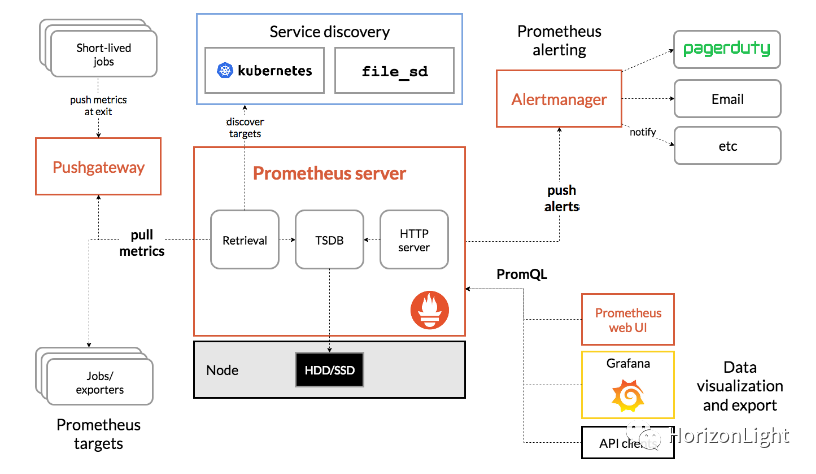
介绍:
Prometheus:中文译普罗米修斯,是一套开源的监控&报警&时间序列数据库的组合,包含Alertmanager报警组件和各类Exporter;
Grafana:根据定义的模板图形化展示metrics指标数据;
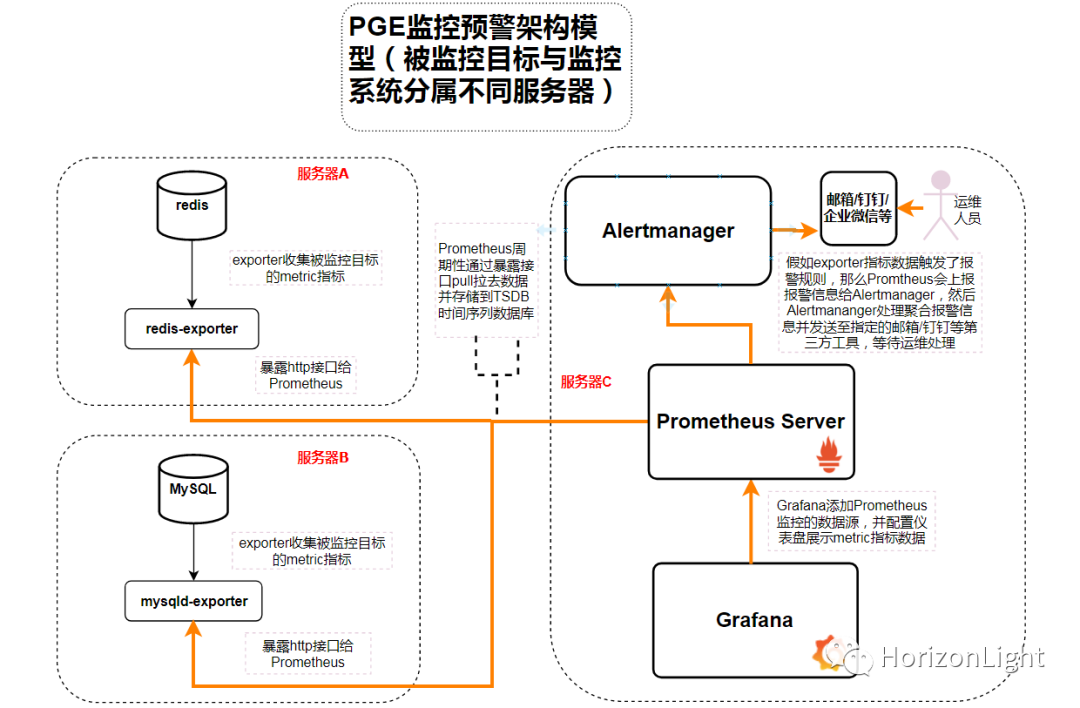
这里贴上本人做的一个流程图加以说明其具体步骤:
可阅官网了解更多细节:
Prometheus/Alertmanager/Exporter官网地址:`https://prometheus.io/`
Granfana官网地址:`https://grafana.com/`
(一)部署安装
系统环境说明:
Linux版本:Ubuntu18.04
docker-compose编排部署,自行了解Docker知识
因资源有限,只在一台服务器操作演示,实际生产环境应该实现被监控目标与监控系统分离
1)添加docker-compose.yml文件
version: '3.4'services: #PGE监控报警系统prometheus:image: prom/prometheus:master #prometheus镜像,用于拉取指标数据container_name: prometheus #容器名restart: on-failureports:- "9090:9090" #映射端口为9090command:- "--config.file=/etc/prometheus/prometheus.yml" #以配置文件的方式启动- "--web.enable-lifecycle" #允许热更新配置和规则文件 通过post/put请求 /-/reload 端点- "--storage.tsdb.retention.time=7d" #数据保存时长,默认15天volumes:#数据挂载- /media/pge/prometheus/data:/prometheus/data#配置挂载- /media/pge/prometheus/conf/prometheus.yml:/etc/prometheus/prometheus.yml- /media/pge/prometheus/conf/rules.yml:/etc/prometheus/rules.ymlnetworks: #网络命名空间 用于隔离服务- pgealertmanager:image: prom/alertmanager:master #alertmanager镜像,报警组件container_name: alertmanager #容器名restart: on-failureports:- "9093:9093" #映射端口为9093command:- "--config.file=/etc/alertmanager/alertmanager.yml"volumes:#数据挂载- /media/pge/prometheus/alertmanager/data:/alertmanager/data#配置挂载- /media/pge/prometheus/alertmanager/conf/alertmanager.yml:/etc/alertmanager/alertmanager.ymlnetworks: #网络命名空间 用于隔离服务- pgegrafana:image: grafana/grafana:master #grafana镜像,用于图形化展示指标数据container_name: grafana #容器名restart: on-failureenvironment:#设置用户密码 默认是admin/admin- "GF_SECURITY_ADMIN_USER=admin"- "GF_SECURITY_ADMIN_PASSWORD=123456"#引入插件 不建议设置(可登录控制台配置),因为启动时需要下载,比较缓慢,造成服务启动十分钟左右后才能访问grafana控制台#- "GF_INSTALL_PLUGINS=alexanderzobnin-zabbix-app"ports:- "3000:3000" #映射端口为3000volumes:#挂载数据(模板信息等)- /media/blog/pge/grafana/data:/var/lib/grafananetworks: #网络命名空间 用于隔离服务- pge#############exporter相关镜像,用于收集指标数据#############node-exporter:image: prom/node-exporter:master #node-exporter用于收集本机cpu、内存等指标数据并暴露http接口给Prometheus拉取数据(Prometheus官方的exporter)container_name: node-exporter #容器名restart: on-failureports:- "9100:9100" #映射端口为9100networks: #网络命名空间 用于隔离服务- pgemysqld-exporter:image: prom/mysqld-exporter:master #mysqld-exporter用于收集mysql数据库的指标数据并暴露http接口给Prometheus拉取数据(Prometheus官方的exporter)container_name: mysqld-exporter #容器名restart: on-failureenvironment:#mysql数据库连接地址- DATA_SOURCE_NAME=root:123456@(106.52.202.31:3306)/ports:- "9104:9104" #映射端口为9104networks: #网络命名空间 用于隔离服务- pgeredis-exporter:image: oliver006/redis_exporter:v1.13.1 #redis-exporter用于收集redis数据库的指标数据并暴露http接口给Prometheus拉取数据(第三方的exporter)container_name: redis-exporter #容器名restart: on-failureenvironment:#redis地址以及用户密码- REDIS_ADDR=redis://106.52.202.31:6379- REDIS_PASSWORD=123456ports:- "9121:9121" #映射端口为9121networks: #网络命名空间 用于隔离服务- pgenetworks:pge:external: true
说明:
需要做好数据卷挂载,参照文件中的路径挂载
`/media/pge/prometheus/data`、`/media/blog/pge/grafana/data `和`/media/pge/prometheus/alertmanager/data`这三个文件夹涉及写操作,所以需要授权,执行如下命令:
chmod 777 /media/pge/prometheus/data
可以创建 pge 网络以隔离服务,执行创建命令:
docker network create pge
2)添加Prometheus相关配置文件
Prometheus配置文件prometheus.yml:
############## Promethus Config ####################全局配置global:scrape_interval: 15s #默认抓取目标的采集数据周期为15秒#和外部系统(例如AlertManager)通信时为时间序列或者警情(Alert)强制添加的标签列表,比如以下的minitor定义值会在收到的报警邮件信息中出现external_labels:monitor: 'gpe-monitor'#引入触发报警条件的文件(注意路径应为容器内的路径)rule_files:- "./rules.yml"#Promethus 抓取目标的配置列表#exporter可理解为各种数据指标收集器(比如mysql-exporter、redis-exporter等),然后Promethus会定时主动请求对应的exporter拉取数据,然后在Grafana作数据展示分析scrape_configs:#node-exporter用于收集本机cpu等系统资源的指标数据- job_name: 'node-exporter' #抓取目标名#这里配置的采集数据周期会覆盖全局配置,优先级最高scrape_interval: 5s#抓取目标的访问urlstatic_configs:- targets: ['106.52.202.31:9100']#mysqld-exporter用于收集mysql数据库的指标数据- job_name: 'mysqld-exporter' #抓取目标名#这里配置的采集数据周期会覆盖全局配置,优先级最高scrape_interval: 5s#抓取目标的访问urlstatic_configs:- targets: ['106.52.202.31:9104']#redis-exporter用于收集redis数据库的指标数据- job_name: 'redis-exporter' #抓取目标名#这里配置的采集数据周期会覆盖全局配置,优先级最高scrape_interval: 5s#抓取目标的访问urlstatic_configs:- targets: ['106.52.202.30:9121']#alertmanager报警设置alerting:alertmanagers:- static_configs:- targets: ["106.52.202.31:9093"]
Prometheus报警规则配置文件rules.yml:
#############alert rule config##############groups:- name: redis-downline-rulerules:- alert: "离线报警" #alertname 可在分发策略定义alertname进行分组expr: sum(up{job="redis-exporter"}) == 0 #触发条件:统计在线节点数量,当在线数量等于0时触发for: 1m #持续多长时间才触发报警labels: #附加标签severity: warningannotations: #附加信息summary: "redis-{{ $labels.instance }} has been down" #获取labels标签的instance值description: "redis服务离线报警"value: "{{ $labels.job }}在线服务数量:{{ $value }}" #value为expr表达式值- name: memory-rulerules:- alert: "内存开销过高报警"expr: (sum(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / sum(node_memory_MemTotal_bytes))*100 > 70 #node_memory_MemAvailable_bytes可通过Grafana面板查看metrics名称for: 1mlabels:severity: warningannotations:summary: "memory:{{ $labels.alertname }}"description: "内存超额使用报警"value: "已用内存/总内存: {{ $value }}%"
说明:
当在 `docker-compose.yml` 配置了Prometheus的 `--web.enable-lifecycle` 环境参数,可通过 put/post 请求 `/-/reload` 接口实现服务热更新配置文件
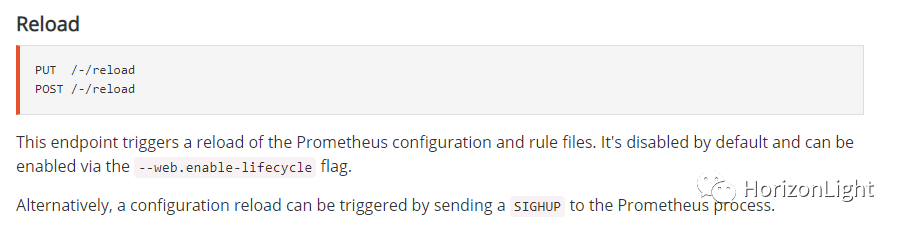
3)添加alertmanager配置文件:
配置文件alertmanager.yml:
############alertmanager config#############全局配置global:#配置邮箱信息smtp_smarthost: 'smtp.163.com:465' #163邮箱的SMTP服务器地址+端口 使用25端口会报错email-receiver/email[0]: notify retry canceled after 2 attempts: establish connection to server: dial tcp 220.181.12.18:25: i/o timeoutsmtp_from: 'xxx@163.com' #写信人邮箱smtp_auth_username: 'xxx@163.com' #邮箱授权用户smtp_auth_password: 'xxxxxx' #邮箱授权码,需要登录邮箱开启POP3/SMTP/IMAP服务获取smtp_require_tls: false #不使用tls协议#定义报警的分发策略route:#分组规则 根据rules.yml的触发规则的alertname进行分组,同一组的会聚合再发送group_by: ['alertname']group_wait: 30s #组报警等待时间 默认30秒group_interval: 5s #组报警间隔时间 默认5分钟repeat_interval: 1h #重复报警间隔时间 默认3小时receiver: email-receiver ## 默认发送的接收器#定义报警接受者信息receivers:- name: 'email-receiver' #接收器名称email_configs: #邮箱配置,还可以选择配置钉钉、微信等,自行看官方文档了解- to: 'xxx@163.com' #收信人邮箱
说明:
可直接通过 put/post 请求 `/-/reload` 接口实现服务热更新配置文件

按步骤开启163邮箱SMTP服务:
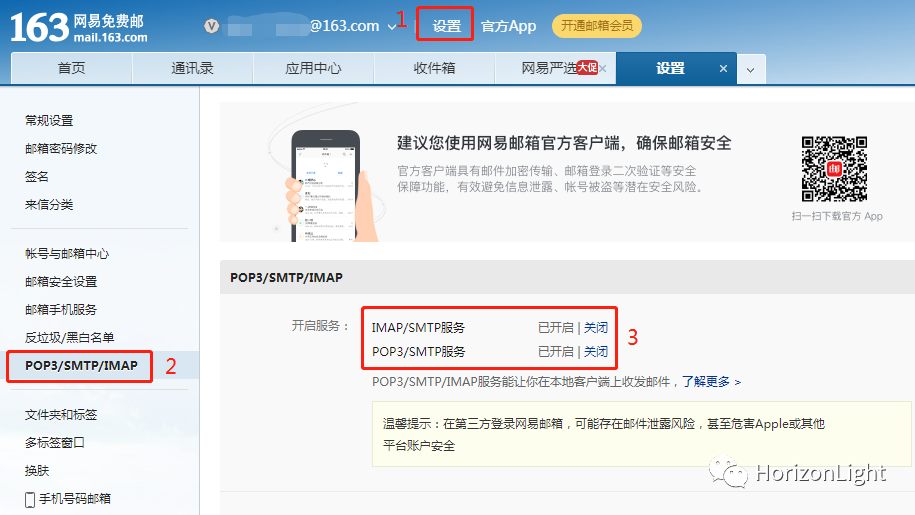
(三)启动服务并访问测试
切换到 `docker-compose.yml` 文件的路径下,执行启动命令:
docker-compose up -d
可通过以下命令查看服务状态:
docker-compose ps
以及查看输出日志:
docker-compose logs
成功启动后,访问Prometheus控制台(ip+映射的端口,默认是9090),可看到监控的节点信息、报警规则以及报警触发详情等等:
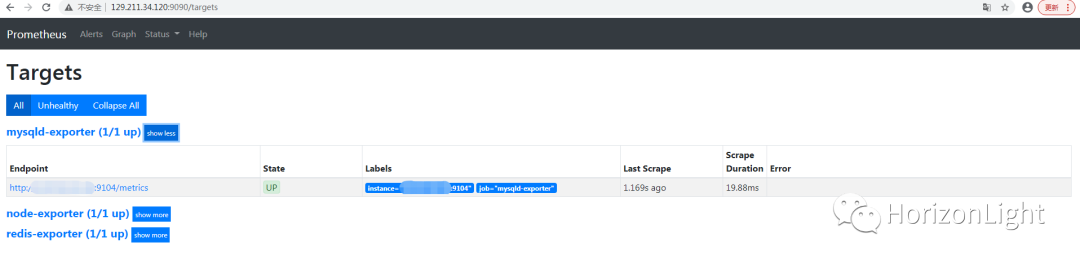
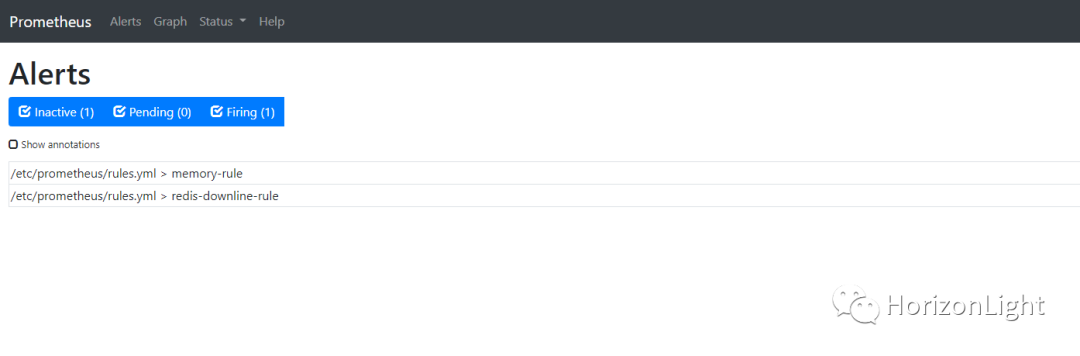
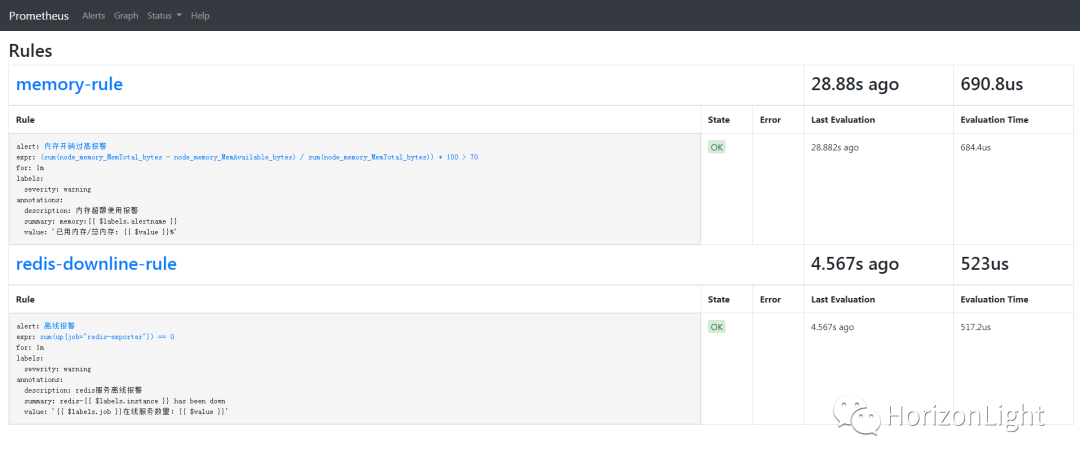
为了测试报警,可以停止 redis-exporter 服务,执行命令:
docker-compose stop redis-exporter
根据设定的值,在停掉服务的一分钟内,redis-exporter对应的redis-downline-rule会变成Pending状态
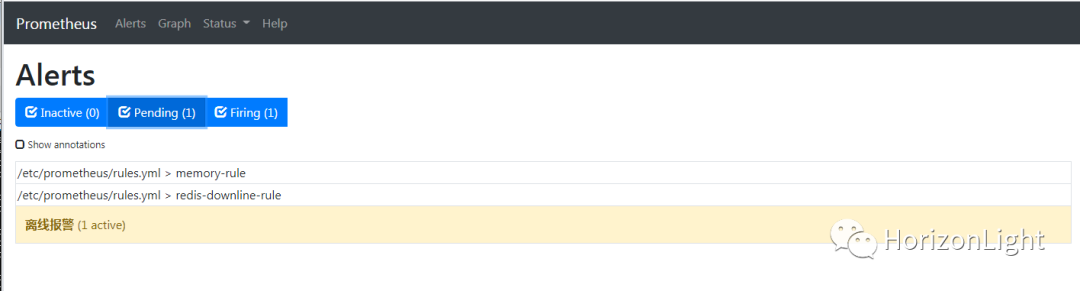
说明:
Alerts可看到三种状态,分别为 Inactive(服务正常,非触发状态)、Pengding(服务出现异常,但在触发规则的for值时间内,待定状态)以及 Firing(服务异常,触发状态,发送报警)
当服务恢复正常,又会回到 Inactive 状态
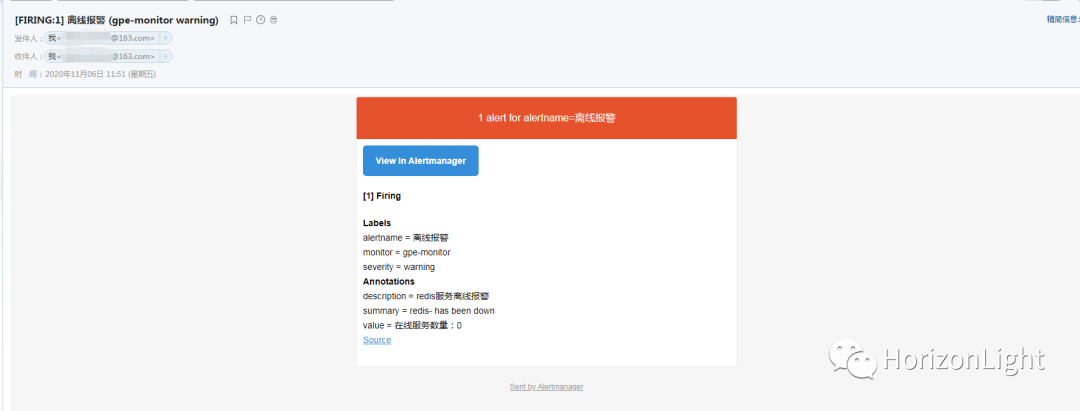
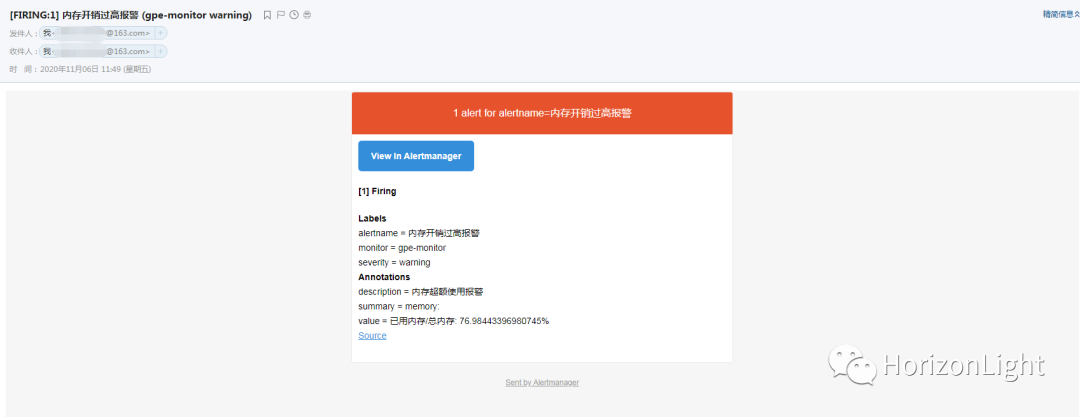
当报警条件触发后,会上报信息给Alertmanager处理并发送到指定邮箱:
访问Grafana控制台(ip+映射的端口,默认是3000,账号密码可在 `docker-compose.yml` 配置,默认为admin/admin):
下面示例如何添加一个Prometheus面板展示数据:
添加Prometheus数据源:

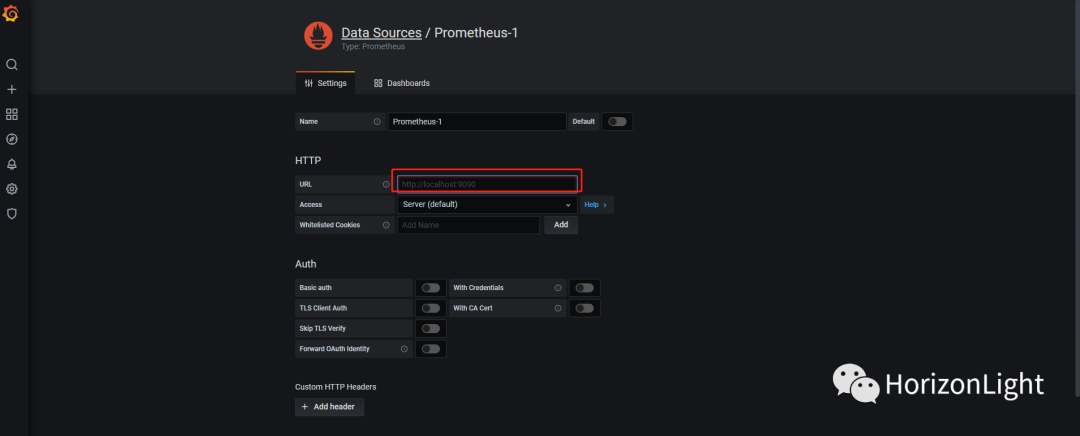
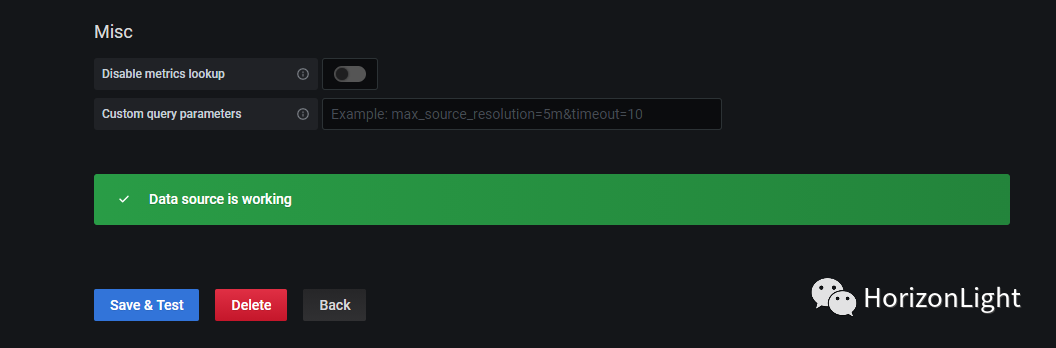
输入Prometheus的访问地址并保存:
导入Prometheus仪表盘:
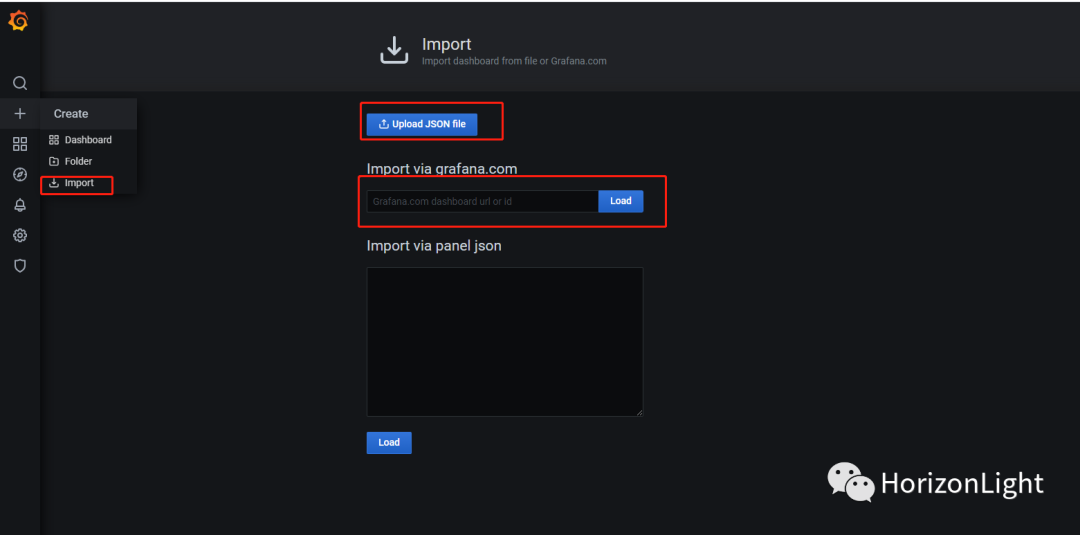
说明:
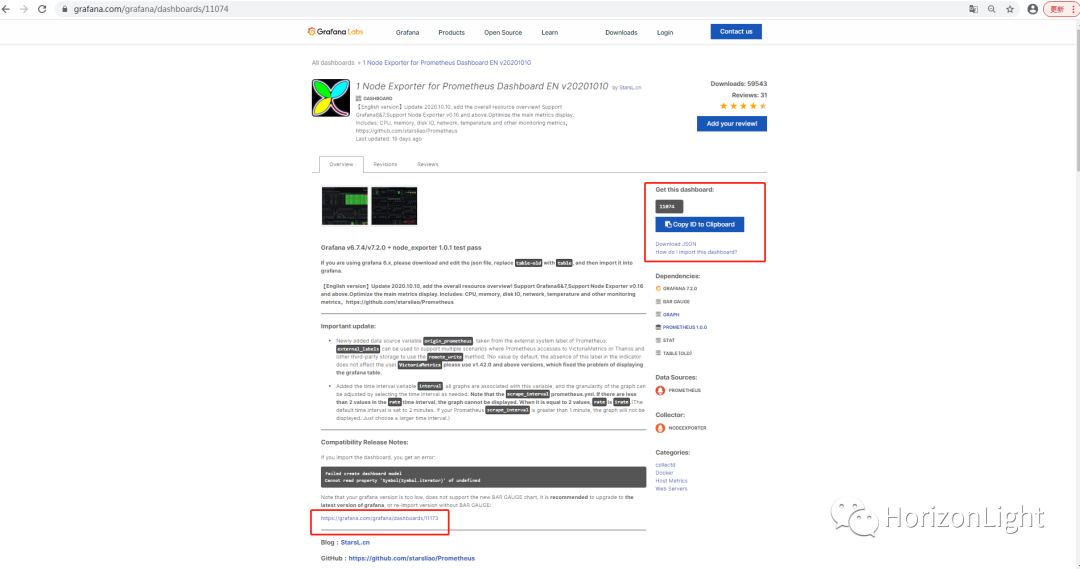
导入仪表盘的方式有三种,一个是到Grafana的官网找到合适的仪表盘下载对应的json文件导进去;第二种是贴对应的链接加载,如`https://grafana.com/grafana/dashboards/11173`;第三种是直接贴json格式的数据结构体。
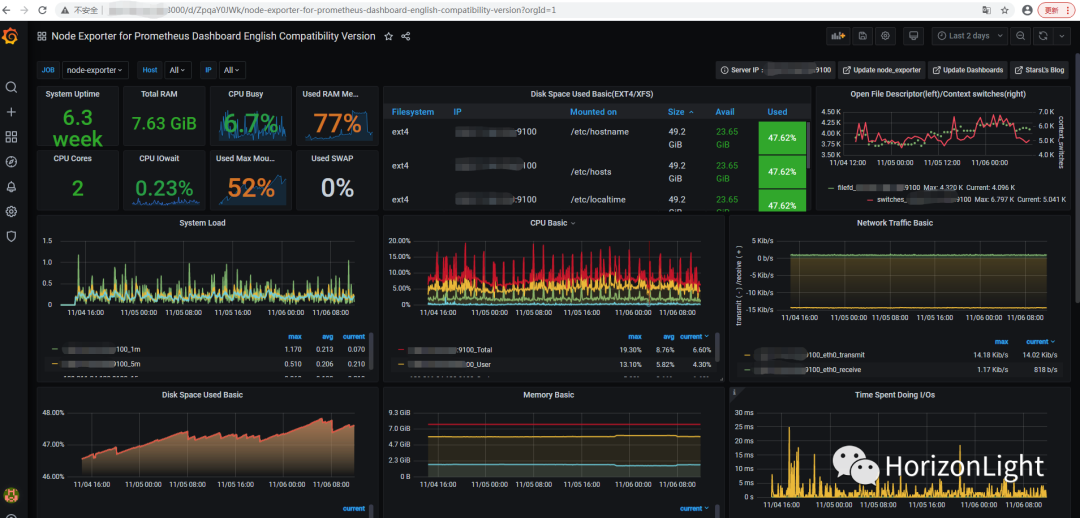
最后就能展示出 node-exporter 监控的系统指标数据:
其他如MySQL和Redis的仪表盘,可自行了解!
